I en afvigelse fra min 'knee-jerk performance tuning'-serie, vil jeg gerne diskutere, hvordan indeksfragmentering kan snige sig ind på dig under nogle omstændigheder.
Hvad er indeksfragmentering?
De fleste mennesker tænker på 'indeksfragmentering' som ensbetydende med problemet, hvor indeksbladssiderne er ude af drift – indeksbladssiden med den næste nøgleværdi er ikke den, der er fysisk sammenhængende i datafilen til den indeksbladsside, der i øjeblikket undersøges . Dette kaldes logisk fragmentering (og nogle mennesker omtaler det som ekstern fragmentering – et forvirrende udtryk, som jeg ikke kan lide).
Logisk fragmentering sker, når en indeksbladsside er fuld, og der kræves plads på den, enten til en indsættelse eller for at gøre en eksisterende post længere (fra opdatering af en kolonne med variabel længde). I så fald opretter Storage Engine en ny, tom side og flytter 50 % af rækkerne (normalt, men ikke altid) fra hele siden til den nye side. Denne handling skaber plads på begge sider, så indsættelsen eller opdateringen kan fortsætte, og kaldes en sideopdeling. Der er interessante patologiske tilfælde, der involverer gentagne sideopdelinger fra en enkelt operation og sideopdelinger, der kaskade op i indeksniveauerne, men de ligger uden for dette indlægs rammer.
Når en sideopdeling opstår, forårsager det normalt logisk fragmentering, fordi den nye side, der er tildelt, er højst usandsynligt, at den fysisk støder op til den, der bliver opdelt. Når et indeks har masser af logisk fragmentering, bliver indeksscanninger langsommere, fordi de fysiske læsninger af de nødvendige sider ikke kan udføres så effektivt (ved at bruge flere siders 'readahead'-læsninger), når bladsiderne ikke er lagret i rækkefølge i datafilen .
Det er den grundlæggende definition af indeksfragmentering, men der er en anden form for indeksfragmentering, som de fleste mennesker ikke overvejer:lav sidetæthed (kalder nogle gange intern fragmentering igen, et forvirrende udtryk, jeg ikke kan lide).
Sidetæthed er et mål for, hvor meget data der er gemt på en indeksbladside. Når der sker en sideopdeling med det sædvanlige 50/50 tilfælde, efterlades hver bladside (den delte og den nye) med en sidetæthed på kun 50 %. Jo lavere sidetætheden er, jo mere tom plads er der i indekset, og jo mere diskplads og bufferpuljehukommelse kan du tænke på at være spildt. Jeg bloggede om dette problem for nogle år siden, og du kan læse om det her.
Nu hvor jeg har givet en grundlæggende definition af de to former for indeksfragmentering, vil jeg henvise til dem samlet som blot 'fragmentering'.
I resten af dette indlæg vil jeg gerne diskutere tre tilfælde, hvor klyngede indekser kan blive fragmenterede, selvom du undgår operationer, der åbenlyst ville forårsage fragmentering (dvs. tilfældige indsættelser og opdatering af poster bliver længere).
Fragmentering fra sletninger
"Hvordan kan en sletning fra en klynget indeksbladsside forårsage en sideopdeling?" spørger du måske. Det vil det ikke, under normale omstændigheder (og jeg sad og tænkte over det i et par minutter for at sikre mig, at der ikke var nogle mærkelige patologiske tilfælde! Men se afsnittet nedenfor...) Sletninger kan dog få sidetætheden til at blive gradvist lavere.
Forestil dig det tilfælde, hvor det klyngede indeks har en bigint-identitetsnøgleværdi, så indsættelser altid vil gå til højre side af indekset og aldrig nogensinde vil blive indsat i en tidligere del af indekset (uden at nogen genseer identitetsværdien – potentielt meget problematisk!). Forestil dig nu, at arbejdsbelastningen sletter poster fra tabellen, som ikke længere er nødvendige, hvorefter baggrundsspøgelsesoprydningsopgaven vil genvinde pladsen på siden, og den bliver ledig plads.
I mangel af tilfældige indsættelser (umuligt i vores scenarie, medmindre nogen gensøger identiteten eller angiver en nøgleværdi, der skal bruges efter aktivering af SET IDENTITY INSERT for tabellen), vil ingen nye poster nogensinde bruge den plads, der blev frigjort fra de slettede poster. Dette betyder, at den gennemsnitlige sidetæthed for de tidligere dele af det klyngede indeks vil falde støt, hvilket fører til en stigende mængde spildt diskplads og bufferpuljehukommelse, som jeg beskrev tidligere.
Sletninger kan forårsage fragmentering, så længe du betragter sidetæthed som en del af "fragmentering".
Fragmentering fra Snapshot Isolation
SQL Server 2005 introducerede to nye isolationsniveauer:snapshot isolation og read-committed snapshot isolation. Disse to har lidt forskellig semantik, men tillader dybest set forespørgsler for at se et punkt-i-tidsvisning af en database og for låse-kollisionsfrie valg. Det er en stor forenkling, men det er nok til mine formål.
For at lette disse isolationsniveauer implementerede udviklingsteamet hos Microsoft, som jeg ledede, en mekanisme kaldet versionering. Den måde, versionering fungerer på, er, at hver gang en post ændres, kopieres pre-change-versionen af posten til versionslagret i tempdb, og den ændrede optagede får et 14-byte versionstag tilføjet i slutningen af det. Tagget indeholder en pointer til den tidligere version af posten plus et tidsstempel, der kan bruges til at bestemme, hvad der er den korrekte version af en post for en bestemt forespørgsel at læse. Igen, enormt forenklet, men det er kun tilføjelsen af de 14-bytes, vi er interesserede i.
Så hver gang en post ændres, når et af disse isolationsniveauer er i kraft, kan den udvides med 14 bytes, hvis der ikke allerede er et versioneringstag for posten. Hvad hvis der ikke er plads nok til de ekstra 14 bytes på indeksbladet? Det er rigtigt, en sideopdeling vil forekomme, hvilket forårsager fragmentering.
Big deal, tænker du måske, da posten alligevel ændrer sig, så hvis den alligevel ændrede størrelse, ville der sandsynligvis være sket en sideopdeling. Nej – den logik holder kun, hvis rekordændringen skulle øge størrelsen af en kolonne med variabel længde. Et versioneringsmærke vil blive tilføjet, selvom en kolonne med fast længde er opdateret!
Det er rigtigt - når versionering er i spil, kan opdateringer til kolonner med fast længde få en post til at udvide, hvilket potentielt kan forårsage en sideopdeling og fragmentering. Hvad der er endnu mere interessant er, at en sletning også vil tilføje 14-byte-tagget, så en sletning i et klynget indeks kan forårsage en sideopdeling, når versionsstyring er i brug!
Den nederste linje her er, at aktivering af begge former for snapshot-isolering kan føre til, at fragmentering pludselig begynder at forekomme i klyngede indekser, hvor der tidligere ikke var mulighed for fragmentering.
Fragmentering fra læsbare sekundærer
Det sidste tilfælde, jeg vil diskutere, er at bruge læsbare sekundære, en del af tilgængelighedsgruppefunktionen, der blev tilføjet i SQL Server 2012.
Når du aktiverer en læsbar sekundær, konverteres alle forespørgsler, du laver mod den sekundære replika, til brug af snapshot-isolering under dækslerne. Dette forhindrer forespørgslerne i at blokere den konstante genafspilning af logposter fra den primære replika, da gendannelseskoden får låse, efterhånden som den går.
For at gøre dette skal der være 14-byte versioneringsmærker på poster på den sekundære replika. Der er et problem, fordi alle replikaer skal være identiske, så loggenafspilningen fungerer. Nå, ikke helt. Indholdet af versioneringstagget er ikke relevant, da det kun bruges på den instans, der oprettede dem. Men den sekundære replika kan ikke tilføje versioneringstags, hvilket gør registreringerne længere, da det ville ændre det fysiske layout af poster på en side og ødelægge loggenafspilning. Hvis versioneringsmærkerne dog allerede var der, kunne den bruge pladsen uden at ødelægge noget.
Så det er præcis, hvad der sker. Storage Engine sørger for, at eventuelle nødvendige versioneringstags for den sekundære replika allerede er der ved at tilføje dem på den primære replika!
Så snart en læsbar sekundær replika af en database er oprettet, bevirker enhver opdatering af en post i den primære replika, at posten får tilføjet et tomt 14-byte-tag, så der tages korrekt højde for 14-bytes i alle logposterne . Tagget bruges ikke til noget (medmindre snapshot-isolering er aktiveret på selve den primære replika), men det faktum, at det er oprettet, får posten til at udvide sig, og hvis siden allerede er fuld, så...
Ja, aktivering af en læsbar sekundær medfører den samme effekt på den primære replika, som hvis du aktiverede snapshot-isolering på den – fragmentering.
Oversigt
Tro ikke, at fordi du undgår at bruge GUID'er som klyngenøgler og undgår at opdatere kolonner med variabel længde i dine tabeller, så vil dine klyngede indekser være immune over for fragmentering. Som jeg har beskrevet ovenfor, er der andre arbejdsbelastninger og miljøfaktorer, der kan forårsage fragmenteringsproblemer i dine klyngede indekser, som du skal være opmærksom på.
Nu skal du ikke gå i knæ og tro, at du ikke skal slette poster, ikke skal bruge snapshot-isolering og ikke bruge læsbare sekundære. Du skal bare være opmærksom på, at de alle kan forårsage fragmentering og vide, hvordan man opdager, fjerner og afbøder den.
SQL Sentry har et sejt værktøj, Fragmentation Manager, som du kan bruge som en tilføjelse til Performance Advisor for at hjælpe med at finde ud af, hvor fragmenteringsproblemer er, og derefter løse dem. Du kan blive overrasket over den fragmentering, du finder, når du tjekker! Som et hurtigt eksempel kan jeg her visuelt se – ned til det individuelle partitionsniveau – hvor meget fragmentering der findes, hvor hurtigt det kom på den måde, eventuelle mønstre der eksisterer, og den faktiske indvirkning det har på spildt hukommelse i systemet:
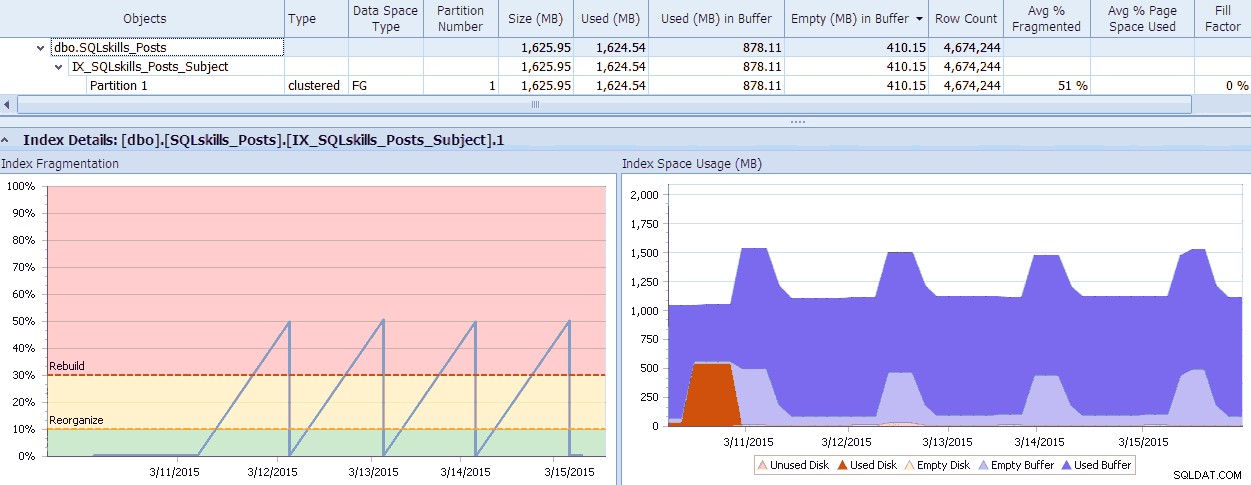 SQL Sentry Fragmentation Manager-data (klik for at forstørre)
SQL Sentry Fragmentation Manager-data (klik for at forstørre)
I mit næste indlæg vil jeg diskutere mere om fragmentering og hvordan man kan afbøde det for at gøre det mindre problematisk.