Tidsseriedatabaser, som navnet antyder, er designet til at gemme data, der ændrer sig med tiden. Dette kan være enhver form for data, som er blevet indsamlet over tid. Det kan være metrics indsamlet fra nogle systemer, og faktisk er alle trendsystemer eksempler på tidsseriedata.
Vi har forskellige typer af tidsseriedatabaser, hvilke skal vi bruge?
I denne blog vil vi se, hvad der er de vigtigste forskelle mellem to af hovedmulighederne, TimescaleDB og InfluxDB.
InfluxDB
InfluxDB er blevet skabt af InfluxData. Det er en brugerdefineret, open source, NoSQL-tidsseriedatabase skrevet i Go. Datalageret leverer et SQL-lignende sprog til at forespørge på dataene, kaldet InfluxQL, hvilket gør det nemt for udviklerne at integrere i deres applikationer. Det har også et nyt brugerdefineret forespørgselssprog kaldet Flux, dette sprog kan gøre nogle opgaver nemmere, men der er altid en indlæringskurve, når du bruger et brugerdefineret forespørgselssprog.
Dette er et eksempel på en Flux-forespørgsel:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()I denne database har hver måling et tidsstempel og et tilhørende sæt tags og sæt felter. Feltet repræsenterer de faktiske måleaflæsningsværdier, mens tagget repræsenterer metadataene til at beskrive målingerne. Feltdatatyperne er begrænset til floats, ints, strenge og booleaner og kan ikke ændres uden at omskrive dataene. Tagværdierne er indekseret. De er repræsenteret som strenge og kan ikke opdateres.
InfluxDB er ret let at komme i gang, da du ikke behøver at bekymre dig om at oprette skemaer eller indekser. Den er dog ret stiv og begrænset, uden mulighed for at oprette yderligere indekser, indekser på kontinuerlige felter, opdatere metadata efter kendsgerningen, gennemtvinge datavalidering osv.
Det er ikke skemaløst. Der er et underliggende skema, der er automatisk oprettet ud fra inputdataene.
InfluxDB skal implementere fra bunden adskillige værktøjer til fejltolerance, såsom replikering, høj tilgængelighed og backup/gendannelse, og det er ansvarligt for dets pålidelighed på disken. Vi er begrænset til at bruge disse værktøjer, og mange af disse funktioner, såsom HA, er kun tilgængelige i virksomhedsversionen.
InfluxDB-sikkerhedskopieringsværktøjet kan udføre en fuld eller trinvis sikkerhedskopiering, og det kan bruges til punkt-i-tids-gendannelse.
InfluxDB tilbyder også markant bedre komprimering på disken end PostgreSQL og TimescaleDB.
TidsskalaDB
TimescaleDB er en open source tidsseriedatabase optimeret til hurtig indlæsning og komplekse forespørgsler, der understøtter fuld SQL. Det er baseret på PostgreSQL, og det tilbyder det bedste fra NoSQL og Relationelle verdener til tidsseriedata.
Dette er et TimescaleDB-forespørgselseksempel:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, som en PostgreSQL-udvidelse, er en relationel database. Dette giver mulighed for at have en kort indlæringskurve for nye brugere og at arve værktøjer som pg_dump eller pg_backup til sikkerhedskopiering og værktøjer med høj tilgængelighed, hvilket er en fordel foran andre tidsseriedatabaser. Det understøtter også streaming replikering som den primære metode til replikering, som kan bruges i en opsætning med høj tilgængelighed. Med hensyn til failover og sikkerhedskopier kan du automatisere denne proces ved at bruge et eksternt system som ClusterControl.
I TimescaleDB registreres hver tidsseriemåling i sin egen række med et tidsfelt efterfulgt af et hvilket som helst antal andre felter, som kan være float, ints, strenge, booleaner, arrays, JSON-blobs, geospatiale dimensioner, dato/tid/ tidsstempler, valutaer, binære data og mere.
Du kan oprette indekser på ethvert felt (standardindekser) eller flere felter (sammensatte indekser), eller på udtryk som funktioner, eller endda begrænse et indeks til en delmængde af rækker (delvis indeks). Ethvert af disse felter kan bruges som en fremmednøgle til sekundære tabeller, som derefter kan gemme yderligere metadata.
På denne måde skal du vælge et skema og beslutte, hvilke indekser du skal bruge til dit system.
Ydeevne
Hvis vi taler om ydeevne, kan vi tjekke den fantastiske TimescaleDB sammenligning blog. Der har du en detaljeret sammenligning for ydeevne mellem begge databaser med diagrammer og metrikker. Lad os se nogle af de vigtigste oplysninger fra denne blog.
Indsæt
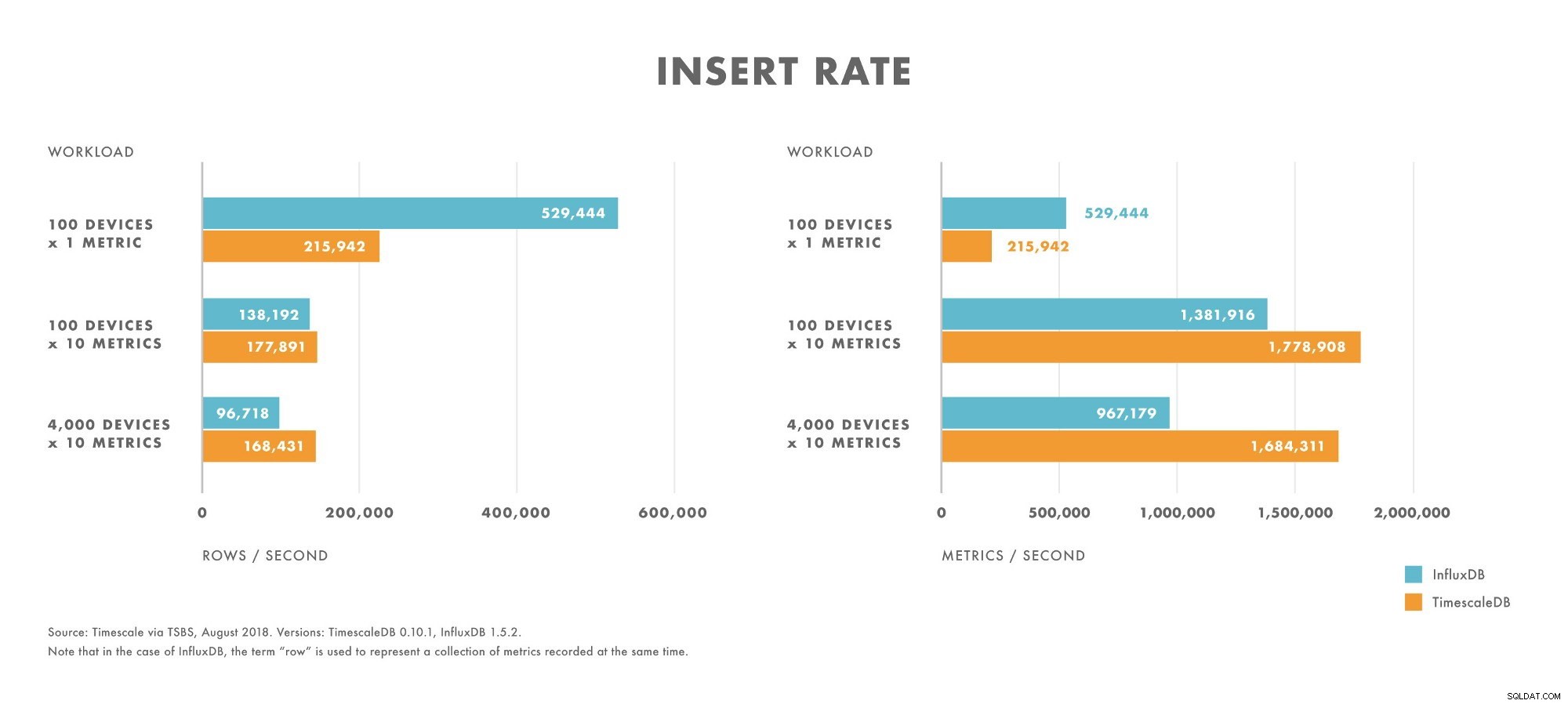
- For arbejdsbelastninger med meget lav kardinalitet (f.eks. 100 enheder), overgår InfluxDB TimescaleDB.
- Når kardinaliteten øges, falder InfluxDB-indsætningsydelsen hurtigere end på TimescaleDB.
- For arbejdsbelastninger med moderat til høj kardinalitet (f.eks. 100 enheder, der sender 10 metrics), overgår TimescaleDB InfluxDB.

Læseforsinkelse
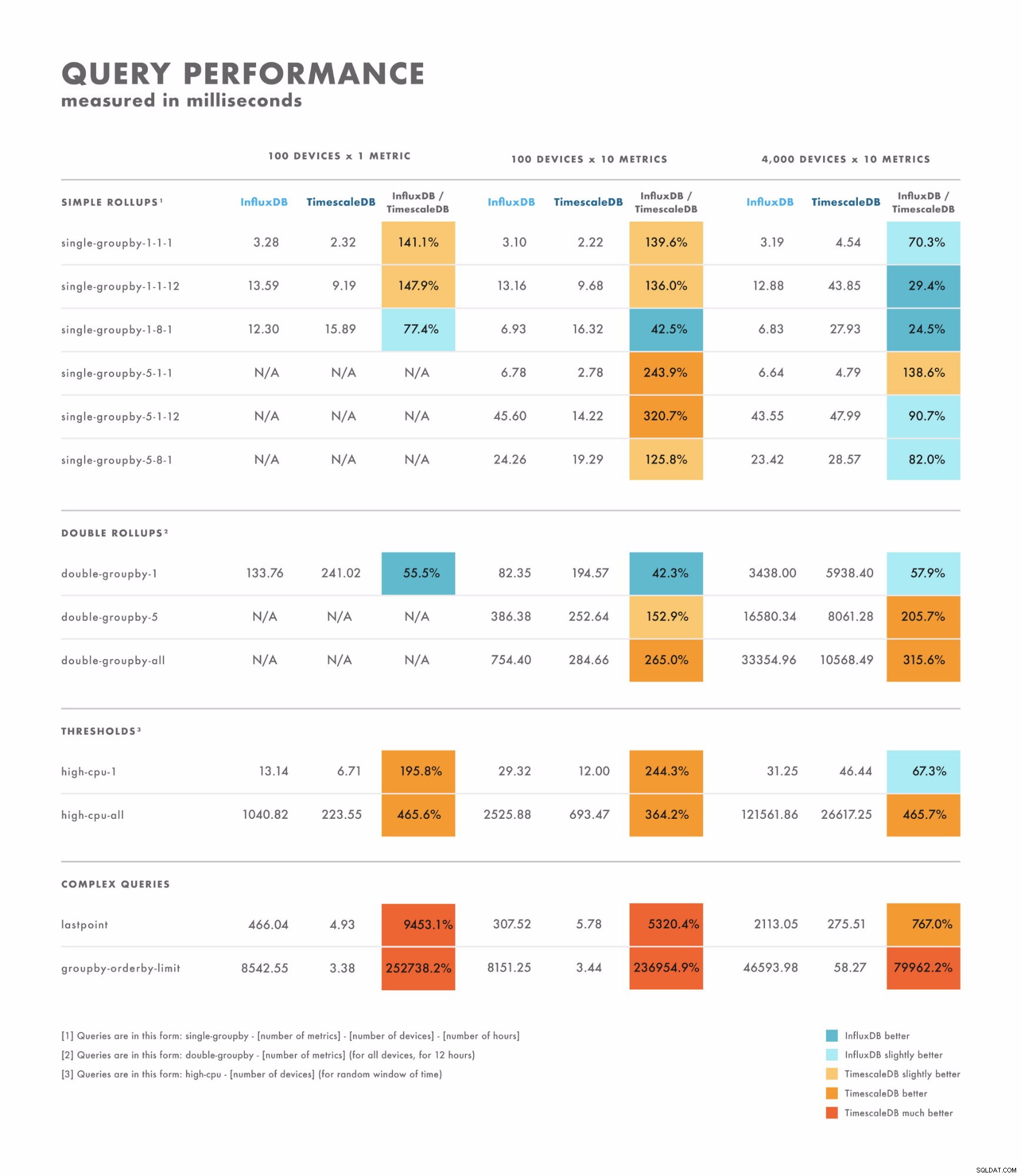
- For simple forespørgsler varierer resultaterne en del:Der er nogle, hvor den ene database er klart bedre end den anden, mens andre afhænger af dit datasæts kardinalitet. Forskellen her ligger ofte i intervallet fra enkeltcifrede til tocifrede millisekunder.
- For komplekse forespørgsler overgår TimescaleDB betydeligt InfluxDB og understøtter en bredere række af forespørgselstyper. Forskellen her er ofte i området fra sekunder til titusinder af sekunder.
- Med det i tankerne er den bedste måde at teste korrekt på at benchmarke ved hjælp af de forespørgsler, du planlægger at udføre.
Stabilitetsproblemer
- InfluxDB har problemer med stabilitet og ydeevne ved høje (100K+) kardinaliteter.
Konklusion
Hvis dine data passer ind i InfluxDB datamodellen, og du ikke forventer at ændre sig i fremtiden, så bør du overveje at bruge InfluxDB, da denne model er nemmere at komme i gang med, og ligesom de fleste databaser, der bruger en kolonneorienteret tilgang, tilbyder bedre komprimering på disken end PostgreSQL og TimescaleDB.
Den relationelle model er dog mere alsidig og tilbyder mere funktionalitet, fleksibilitet og kontrol end InfluxDB-modellen. Dette er især vigtigt, da din applikation udvikler sig. Og når du planlægger dit system, bør du overveje både dets nuværende og fremtidige behov.
I denne blog kunne vi se en kort sammenligning mellem TimescaleDB og InfluxDB, og vi kunne sige, at TimescaleDB som en PostgreSQL-udvidelse ser ret moden og funktionsrig ud, da den arver meget fra PostgreSQL. Men du kan tage din egen beslutning baseret på de fordele og ulemper, der er nævnt tidligere i denne blog, og sørge for at benchmarke din egen arbejdsbyrde. Held og lykke i denne nye tidsseriedatabaseverden!