Selvom de kommer med mange begrænsninger og nogle vigtige implementeringsforbehold, er indekserede visninger stadig en meget kraftfuld SQL Server-funktion, når de anvendes korrekt under de rigtige omstændigheder. En almindelig anvendelse er at give et præ-aggregeret overblik over underliggende data, hvilket giver brugerne mulighed for at forespørge resultater direkte uden at pådrage sig omkostningerne ved at behandle de underliggende joinforbindelser, filtre og aggregerede hver gang en forespørgsel udføres.
Selvom nye Enterprise Edition-funktioner som kolonneopbevaring og batchtilstandsbehandling har transformeret ydeevneegenskaberne for mange store forespørgsler af denne type, er der stadig ingen hurtigere måde at opnå et resultat på end at undgå al den underliggende behandling fuldstændigt, uanset hvor effektiv behandlingen er. kunne være blevet.
Før indekserede visninger (og deres mere begrænsede fætre, beregnede kolonner) blev føjet til produktet, ville databaseprofessionelle nogle gange skrive kompleks multi-trigger-kode for at præsentere resultaterne af en vigtig forespørgsel i en rigtig tabel. Denne form for arrangement er notorisk vanskeligt at få rigtigt under alle omstændigheder, især hvor samtidige ændringer af de underliggende data er hyppige.
Funktionen med indekserede visninger gør alt dette meget nemmere, hvor det er fornuftigt og korrekt anvendt. Databasemotoren tager sig af alt det nødvendige for at sikre, at data læst fra en indekseret visning matcher den underliggende forespørgsel og tabeldata til enhver tid.
Inkrementel vedligeholdelse
SQL Server holder indekserede visningsdata synkroniseret med den underliggende forespørgsel ved automatisk at opdatere visningsindekserne korrekt, hver gang data ændres i basistabellerne. Omkostningerne til denne vedligeholdelsesaktivitet afholdes af processen, der ændrer basisdataene. De ekstra operationer, der er nødvendige for at vedligeholde visningsindekserne, føjes stille og roligt til udførelsesplanen for den oprindelige indsættelses-, opdaterings-, slet- eller fletoperation. I baggrunden tager SQL Server sig også af mere subtile spørgsmål vedrørende transaktionsisolering, for eksempel at sikre korrekt håndtering af transaktioner, der kører under snapshot eller read committed snapshot isolation.
At konstruere de ekstra eksekveringsplanoperationer, der er nødvendige for at vedligeholde visningsindekserne korrekt, er ikke en triviel sag, som enhver, der har forsøgt en "resumétabel vedligeholdt af triggerkode"-implementering, vil vide. Kompleksiteten af opgaven er en af grundene til, at indekserede visninger har så mange begrænsninger. Begrænsning af det understøttede overfladeareal til indre sammenføjninger, projektioner, valg (filtre) og SUM- og COUNT_BIG-aggregaterne reducerer implementeringskompleksiteten betydeligt.
Indekserede visninger vedligeholdes trinvist . Dette betyder, at forespørgselsprocessoren bestemmer nettoeffekten af basistabelændringerne på visningen og anvender kun de ændringer, der er nødvendige for at bringe visningen ajour. I simple tilfælde kan den beregne de nødvendige delta'er ud fra blot basistabelændringerne og de data, der i øjeblikket er gemt i visningen. Hvor visningsdefinitionen indeholder joinforbindelser, skal den indekserede visningsvedligeholdelsesdel af eksekveringsplanen også have adgang til de sammenføjede tabeller, men dette kan normalt udføres effektivt, givet passende basistabelindekser.
For at forenkle implementeringen yderligere, bruger SQL Server altid den samme grundlæggende planform (som udgangspunkt) til at implementere indekserede visningsvedligeholdelsesoperationer. De normale faciliteter, der leveres af forespørgselsoptimeringsværktøjet, bruges til at forenkle og optimere standardvedligeholdelsesformen efter behov. Vi vil nu se på et eksempel for at hjælpe med at bringe disse begreber sammen.
Eksempel 1 – Indsæt enkelt række
Antag, at vi har følgende enkle tabel og indekseret visning:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Efter at scriptet er kørt, ser dataene i eksempeltabellen således ud:

Og den indekserede visning indeholder:

Det enkleste eksempel på en vedligeholdelsesplan for indekseret visning for denne opsætning opstår, når vi tilføjer en enkelt række til basistabellen:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); Udførelsesplanen for denne indsats er vist nedenfor:
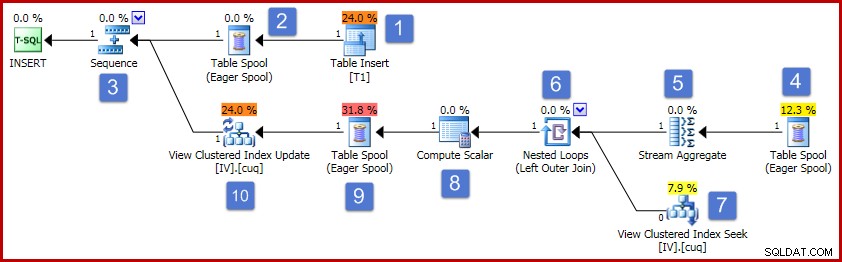
Efter tallene i diagrammet forløber driften af denne udførelsesplan som følger:
- Tabelindsæt-operatoren tilføjer den nye række til basistabellen. Dette er den eneste planoperator, der er knyttet til basistabelindsatsen; alle resterende operatører er optaget af vedligeholdelsen af den indekserede visning.
- Eager Table Spool gemmer de indsatte rækkedata til midlertidig lagring.
- Sekvensoperatoren sikrer, at planens øverste gren kører til fuldførelse, før den næste gren i sekvensen aktiveres. I dette specielle tilfælde (indsættelse af en enkelt række), ville det være gyldigt at fjerne sekvensen (og spolerne ved position 2 og 4), ved direkte at forbinde Stream Aggregate-indgangen til udgangen af tabelindsatsen. Denne mulige optimering er ikke implementeret, så sekvensen og spoolerne forbliver.
- Denne Eager Table Spool er knyttet til spoolen på position 2 (den har en Primær Node ID-egenskab, der eksplicit giver dette link). Spolen afspiller rækker (en række i dette tilfælde) fra det samme midlertidige lager skrevet til af den primære spool. Som nævnt ovenfor er spolerne og positionerne 2 og 4 unødvendige, og de findes simpelthen fordi de findes i den generiske skabelon til vedligeholdelse af indekseret visning.
- Strømaggregatet beregner summen af værdikolonnedata i det indsatte sæt og tæller antallet af tilstedeværende rækker pr. visningsnøglegruppe. Outputtet er de trinvise data, der er nødvendige for at holde visningen synkroniseret med basisdataene. Bemærk, at Stream Aggregate ikke har et Group By-element, fordi forespørgselsoptimeringsværktøjet ved, at kun en enkelt værdi behandles. Optimeringsværktøjet anvender dog ikke lignende logik til at erstatte aggregaterne med projektioner (summen af en enkelt værdi er kun selve værdien, og antallet vil altid være én for en enkelt rækkeindsættelse). At beregne sum og tælleaggregater for en enkelt række data er ikke en dyr operation, så denne manglende optimering er ikke meget at bekymre sig om.
- Forbindelsen relaterer hver beregnet trinvis ændring til en eksisterende nøgle i den indekserede visning. Sammenkædningen er en ydre forbindelse, fordi de nyligt indsatte data muligvis ikke svarer til nogen eksisterende data i visningen.
- Denne operator finder den række, der skal ændres, i visningen.
- Comute Scalar har to vigtige ansvarsområder. Først bestemmer den, om hver trinvis ændring vil påvirke en eksisterende række i visningen, eller om en ny række skal oprettes. Det gør det ved at kontrollere, om den ydre joinforbindelse producerede et nul fra visningssiden af sammenføjningen. Vores prøveindlæg er til gruppe 3, som ikke findes i visningen i øjeblikket, så en ny række vil blive oprettet. Den anden funktion af Compute Scalar er at beregne nye værdier for visningskolonnerne. Hvis en ny række skal tilføjes til visningen, er dette blot resultatet af den trinvise sum fra strømaggregatet. Hvis en eksisterende række i visningen skal opdateres, er den nye værdi den eksisterende værdi i visningsrækken plus den trinvise sum fra strømaggregatet.
- Denne ivrige bordspole er til Halloween-beskyttelse. Det er påkrævet for korrekthed, når en indsættelseshandling påvirker en tabel, der også refereres til på dataadgangssiden af forespørgslen. Det er teknisk set ikke påkrævet, hvis enkeltrækkens vedligeholdelsesoperation resulterer i en opdatering af en eksisterende visningsrække, men den forbliver i planen alligevel.
- Den sidste operator i planen er mærket som en Update-operator, men den udfører enten en Insert eller en Update for hver række, den modtager, afhængigt af værdien af "action code"-kolonnen tilføjet af Compute Scalar ved node 8 Mere generelt er denne opdateringsoperatør i stand til at indsætte, opdatere og slette.
Der er en del detaljer der, så for at opsummere:
- Den samlede gruppedata ændres med den unikke klyngenøgle til visningen. Den beregner nettoeffekten af basistabelændringerne på hver kolonne pr. nøgle.
- Den ydre joinforbindelse forbinder de trinvise ændringer pr. nøgle til eksisterende rækker i visningen.
- Beregningsskalaren beregner, om en ny række skal tilføjes til visningen, eller en eksisterende række skal opdateres. Den beregner de endelige kolonneværdier for visningsindsættelses- eller opdateringsoperationen.
- Visningsopdateringsoperatøren indsætter en ny række eller opdaterer en eksisterende som anvist af handlingskoden.
Eksempel 2 – Multi-row Insert
Tro det eller ej, udførelsesplanen for enkelt-rækket basistabelindsætning, der er diskuteret ovenfor, var genstand for en række forenklinger. Selvom nogle mulige yderligere optimeringer blev overset (som nævnt), formåede forespørgselsoptimeringsværktøjet stadig at fjerne nogle handlinger fra den generelle indekserede visningsvedligeholdelsesskabelon og reducere kompleksiteten af andre.
Flere af disse optimeringer blev tilladt, fordi vi kun indsatte en enkelt række, men andre blev aktiveret, fordi optimeringsværktøjet var i stand til at se de bogstavelige værdier, der blev tilføjet til basistabellen. For eksempel kunne optimeringsværktøjet se, at den indsatte gruppeværdi ville passere prædikatet i WHERE-sætningen i visningen.
Hvis vi nu indsætter to rækker, med værdierne "skjult" i lokale variabler, får vi en lidt mere kompleks plan:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
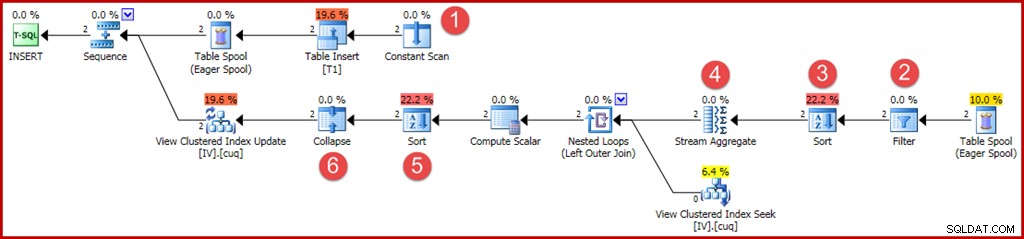
De nye eller ændrede operatorer er kommenteret som før:
- Konstant scanning giver de værdier, der skal indsættes. Tidligere har en optimering for enkeltrækkes skær gjort det muligt at udelade denne operator.
- En eksplicit filteroperator er nu påkrævet for at kontrollere, at grupperne indsat i basistabellen matcher WHERE-udtrykket i visningen. Som det sker, vil begge nye rækker bestå testen, men optimeringsværktøjet kan ikke se værdierne i variablerne for at vide dette på forhånd. Derudover ville det ikke være sikkert at cache en plan, der sprang dette filter over, fordi en fremtidig genbrug af planen kan have forskellige værdier i variablerne.
- En sortering er nu påkrævet for at sikre, at rækkerne ankommer til strømaggregatet i grupperækkefølge. Sorteringen blev tidligere fjernet, fordi det er meningsløst at sortere én række.
- Strømaggregatet har nu en egenskab "gruppe efter", der matcher visningens unikke klyngenøgle.
- Denne sortering er påkrævet for at præsentere rækker i view-key, handlingskoderækkefølge, som er påkrævet for korrekt betjening af Collapse-operatoren. Sort er en fuldt blokerende operatør, så der er ikke længere behov for en ivrig bordspole til Halloween-beskyttelse.
- Den nye Collapse-operator kombinerer en tilstødende indsættelse og sletning på den samme nøgleværdi i en enkelt opdateringshandling. Denne operatør er faktisk ikke påkrævet i dette tilfælde, fordi der ikke kan genereres sletningshandlingskoder (kun indsættelser og opdateringer). Dette ser ud til at være en forglemmelse, eller måske noget, der er efterladt af sikkerhedsmæssige årsager. De automatisk genererede dele af en opdateringsforespørgselsplan kan blive ekstremt komplekse, så det er svært at vide med sikkerhed.
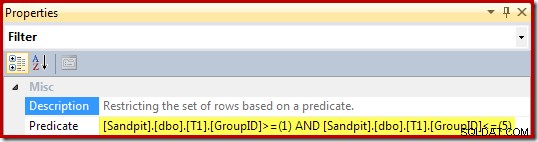
Egenskaberne for filteret (afledt af visningens WHERE-sætning) er:
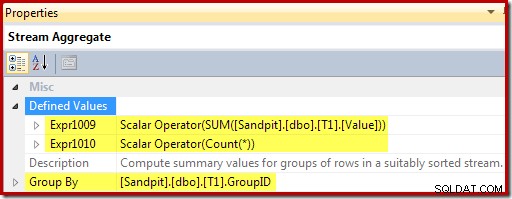
Streamaggregatet grupperer efter visningsnøglen og beregner summen og optællingsaggregaterne pr. gruppe:
Compute Scalar identificerer den handling, der skal udføres pr. række (indsæt eller opdatering i dette tilfælde), og beregner værdien, der skal indsættes eller opdatere i visningen:
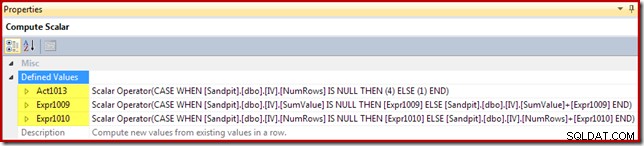
Handlingskoden får et udtryksmærke på [Act1xxx]. Gyldige værdier er 1 for en opdatering, 3 for en sletning og 4 for en indsættelse. Dette handlingsudtryk resulterer i en indsættelse (kode 4), hvis der ikke blev fundet en matchende række i visningen (dvs. den ydre joinforbindelse returnerede et nul for kolonnen NumRows). Hvis en matchende række blev fundet, er handlingskoden 1 (opdatering).
Bemærk, at NumRows er navnet på den påkrævede COUNT_BIG(*) kolonne i visningen. I en plan, der kunne resultere i sletninger fra visningen, ville Compute Scalar registrere, hvornår denne værdi ville blive nul (ingen rækker for den aktuelle gruppe) og generere en slettehandlingskode (3).
De resterende udtryk bevarer summen og tæller aggregater i visningen. Bemærk dog, at udtryksetiketterne [Expr1009] og [Expr1010] ikke er nye; de henviser til de etiketter, der er oprettet af Stream Aggregate. Logikken er ligetil:Hvis en matchende række ikke blev fundet, er den nye værdi, der skal indsættes, kun den værdi, der er beregnet ved aggregatet. Hvis der blev fundet en matchende række i visningen, er den opdaterede værdi den aktuelle værdi i rækken plus stigningen beregnet af aggregatet.
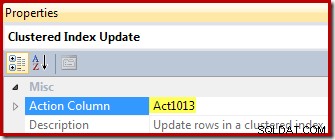
Endelig viser visningsopdateringsoperatøren (vist som en Clustered Index Update i SSMS) handlingskolonnens reference ([Act1013] defineret af Compute Scalar):
Eksempel 3 – Opdatering med flere rækker
Indtil videre har vi kun set på indsatser til bundbordet. Udførelsesplanerne for en sletning er meget ens, med kun få mindre forskelle i de detaljerede beregninger. Dette næste eksempel går derfor videre til at se på vedligeholdelsesplanen for en basistabelopdatering:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Som før bruger denne forespørgsel variabler til at skjule bogstavelige værdier fra optimeringsværktøjet, hvilket forhindrer nogle forenklinger i at blive anvendt. Det er også omhyggeligt at opdatere to separate grupper, hvilket forhindrer optimeringer, der kan anvendes, når optimeringsværktøjet ved, at kun en enkelt gruppe (en enkelt række i den indekserede visning) vil blive påvirket. Den kommenterede udførelsesplan for opdateringsforespørgslen er nedenfor:
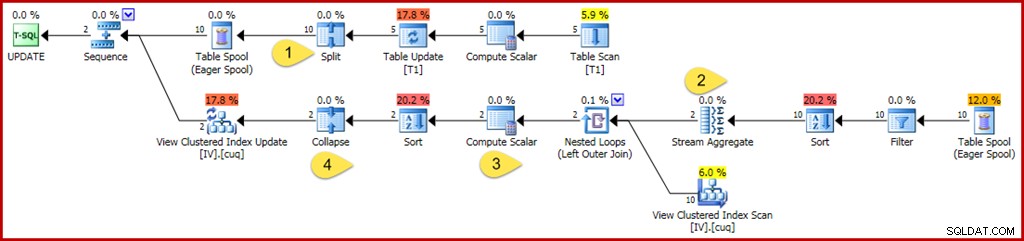
Ændringerne og interessepunktet er:
- Den nye Split-operator gør hver opdatering af basistabelrækken til en separat slet- og indsæt-handling. Hver opdateringsrække er opdelt i to separate rækker, hvilket fordobler antallet af rækker efter dette punkt i planen. Split er en del af split-sort-kollaps-mønsteret, der er nødvendigt for at beskytte mod ukorrekte forbigående unikke nøgleovertrædelsesfejl.
- Strømaggregatet er ændret til at tage højde for indgående rækker, der kan angive enten en sletning eller en indsættelse (på grund af opdelingen og bestemt af en handlingskodekolonne i rækken). En indsæt række bidrager med den oprindelige værdi i sumaggregater; tegnet er vendt for slet handlingsrækker. På samme måde tæller rækkeantallet her indsæt rækker som +1 og slet rækker som -1.
- Compute Scalar-logikken er også modificeret for at afspejle, at nettoeffekten af ændringerne pr. gruppe kan kræve en eventuel indsættelse, opdatering eller sletning af den materialiserede visning. Det er faktisk ikke muligt for denne særlige opdateringsforespørgsel at resultere i, at en række indsættes eller slettes mod denne visning, men den logik, der kræves for at udlede det, ligger uden for optimizerens nuværende ræsonnement. En lidt anderledes opdateringsforespørgsel eller visningsdefinition kunne faktisk resultere i en blanding af indsæt-, slet- og opdateringsvisningshandlinger.
- Skjul-operatoren fremhæves udelukkende for sin rolle i split-sort-kollaps-mønsteret nævnt ovenfor. Bemærk, at den kun skjuler sletninger og indsættelser på den samme tast; uovertrufne sletninger og indsættelser efter Collapsen er helt mulige (og ganske sædvanlige).
Som før er de nøgleoperatøregenskaber, der skal ses på for at forstå vedligeholdelsesarbejdet med indekseret visning, Filter, Stream Aggregate, Outer Join og Compute Scalar.
Eksempel 4 – Opdatering med flere rækker med joinforbindelser
For at fuldende oversigten over udførelsesplaner for indekseret visningsvedligeholdelse skal vi bruge en ny eksempelvisning, der forbinder flere tabeller og inkluderer en projektion i udvalgslisten:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); For at sikre korrekthed er et af de indekserede visningskrav, at en summen ikke kan fungere på et udtryk, der kan evalueres til null. Visningsdefinitionen ovenfor bruger ISNULL til at opfylde dette krav. Et eksempel på opdateringsforespørgsel, der producerer en ret omfattende indeksvedligeholdelsesplankomponent, er vist nedenfor sammen med den udførelsesplan, den producerer:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
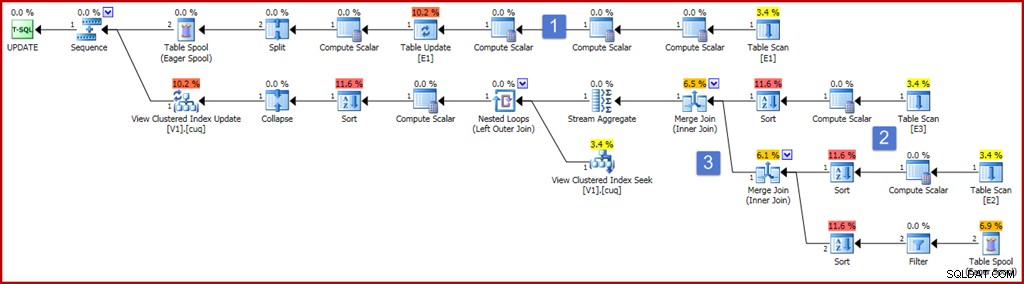
Planen ser ret stor og kompliceret ud nu, men de fleste af elementerne er præcis, som vi allerede har set. De vigtigste forskelle er:
- Den øverste gren af planen inkluderer et antal ekstra Compute Scalar-operatører. Disse kunne være mere kompakt arrangeret, men i det væsentlige er de til stede for at fange præ-opdateringsværdierne for de ikke-grupperende kolonner. Compute Scalar til venstre for tabelopdateringen fanger post-opdateringsværdien af kolonne "a", med ISNULL-projektionen anvendt.
- De nye Compute Scalars i dette område af planen beregner værdien produceret af ISNULL-udtrykket på hver kildetabel. Generelt vil projektioner på de sammenføjede tabeller i visningen blive repræsenteret af Compute Scalars her. Sorteringerne i dette område af planen er til stede, udelukkende fordi optimeringsværktøjet valgte en flette-sammenføjningsstrategi af omkostningsgrunde (husk, fletning kræver sammenføjningsnøglesorteret input).
- De to join-operatorer er nye og implementerer simpelthen joins i visningsdefinitionen. Disse joinforbindelser vises altid før Stream Aggregate, der beregner den trinvise effekt af ændringerne på visningen. Bemærk, at en ændring af en basistabel kan resultere i, at en række, der plejede at opfylde sammenføjningskriterierne, ikke længere slutter sig, og omvendt. Alle disse potentielle kompleksiteter håndteres korrekt (i betragtning af de indekserede visningsbegrænsninger) ved at Stream Aggregate producerer en oversigt over ændringerne pr. visningsnøgle, efter at joinforbindelserne er blevet udført.
Sidste tanker
Den sidste plan repræsenterer stort set den fulde skabelon til at vedligeholde en indekseret visning, selvom tilføjelsen af ikke-klyngede indekser til visningen også ville tilføje yderligere operatører, der er spoolet fra outputtet fra visningsopdateringsoperatøren. Bortset fra en ekstra Split (og en Sort og Collapse-kombination, hvis visningens ikke-klyngede indeks er unikt), er der ikke noget særligt ved denne mulighed. Tilføjelse af en output-klausul til basistabelforespørgslen kan også producere nogle interessante ekstra operatorer, men igen, disse er ikke særlige for indekseret visningsvedligeholdelse i sig selv.
For at opsummere den komplette overordnede strategi:
- Ændringer i basistabel anvendes som normalt; præ-opdateringsværdier kan blive fanget.
- En split-operator kan bruges til at transformere opdateringer til delete/insert-par.
- En ivrig spool gemmer basistabelændringsoplysninger til midlertidig lagring.
- Alle tabeller i visningen er tilgængelige, undtagen den opdaterede basistabel (som læses fra spoolen).
- Projektioner i visningen er repræsenteret af Compute Scalars.
- Filtre i visningen anvendes. Filtre kan skubbes ind i scanninger eller søges som rester.
- Joins, der er angivet i visningen, udføres.
- Et aggregat beregner trinvise nettoændringer grupperet efter klynget visningsnøgle.
- Det trinvise ændringssæt er udvendigt forbundet med visningen.
- En Compute Scalar beregner en handlingskode (indsæt/opdater/slet mod visningen) for hver ændring og beregner de faktiske værdier, der skal indsættes eller opdateres. Beregningslogikken er baseret på outputtet af aggregatet og resultatet af den ydre sammenføjning til visningen.
- Ændringer sorteres i visningsnøgle- og handlingskoderækkefølge og skjules til opdateringer efter behov.
- Til sidst anvendes de trinvise ændringer på selve visningen.
Som vi har set, anvendes det normale sæt værktøjer, der er til rådighed for forespørgselsoptimeringsværktøjet, stadig på de automatisk genererede dele af planen, hvilket betyder, at et eller flere af trinene ovenfor kan forenkles, transformeres eller fjernes helt. Planens grundlæggende form og funktion forbliver dog intakt.
Hvis du har fulgt med i kodeeksemplerne, kan du bruge følgende script til at rydde op:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;