
Det er den tirsdag i måneden – du ved, den, hvor bloggerblokfesten kendt som T-SQL Tuesday finder sted. I denne måned er den vært af Russ Thomas (@SQLJudo), og emnet er "Calling All Tuners and Gear Heads." Jeg har tænkt mig at behandle et præstationsrelateret problem her, selvom jeg undskylder, at det måske ikke er helt i overensstemmelse med de retningslinjer, Russ har angivet i hans invitation (jeg vil ikke bruge tip, sporingsflag eller planvejledninger) .
På SQLBits i sidste uge holdt jeg et oplæg om triggere, og min gode ven og kollega MVP Erland Sommarskog deltog tilfældigvis. På et tidspunkt foreslog jeg, at før du opretter en ny trigger på en tabel, skal du tjekke om der allerede findes nogen triggere, og overveje at kombinere logikken i stedet for at tilføje en ekstra trigger. Mine årsager var primært for kodevedligeholdelse, men også for ydeevne. Erland spurgte, om jeg nogensinde havde testet for at se, om der var ekstra overhead i at få flere triggere i gang for den samme handling, og jeg måtte indrømme, at nej, jeg havde ikke gjort noget omfattende. Så det vil jeg gøre nu.
I AdventureWorks2014 oprettede jeg et simpelt sæt tabeller, der grundlæggende repræsenterer sys.all_objects (~2.700 rækker) og sys.all_columns (~9.500 rækker). Jeg ønskede at måle effekten på arbejdsbyrden af forskellige tilgange til opdatering af begge tabeller - i det væsentlige har du brugere, der opdaterer kolonnetabellen, og du bruger en trigger til at opdatere en anden kolonne i den samme tabel og et par kolonner i objekttabellen.
- T1:Grundlinje :Antag, at du kan kontrollere al dataadgang gennem en lagret procedure; i dette tilfælde kan opdateringerne til begge tabeller udføres direkte uden behov for triggere. (Dette er ikke praktisk i den virkelige verden, fordi du ikke pålideligt kan forbyde direkte adgang til bordene.)
- T2:Enkelt trigger mod anden tabel :Antag, at du kan styre opdateringssætningen mod den berørte tabel og tilføje andre kolonner, men opdateringerne til den sekundære tabel skal implementeres med en trigger. Vi opdaterer alle tre kolonner med én erklæring.
- T3:Enkelt trigger mod begge tabeller :I dette tilfælde har vi en trigger med to sætninger, en der opdaterer den anden kolonne i den berørte tabel, og en der opdaterer alle tre kolonner i den sekundære tabel.
- T4:Enkelt trigger mod begge tabeller :Ligesom T3, men denne gang har vi en trigger med fire sætninger, en der opdaterer den anden kolonne i den berørte tabel, og en sætning for hver kolonne opdateret i den sekundære tabel. Dette kan være måden, det håndteres på, hvis kravene tilføjes over tid, og en separat erklæring anses for at være mere sikker med hensyn til regressionstestning.
- T5:To udløsere :En trigger opdaterer kun den berørte tabel; den anden bruger en enkelt sætning til at opdatere de tre kolonner i den sekundære tabel. Dette kan være måden, det gøres på, hvis de andre udløsere ikke bemærkes, eller hvis det er forbudt at ændre dem.
- T6:Fire udløsere :En trigger opdaterer kun den berørte tabel; de tre andre opdaterer hver kolonne i den sekundære tabel. Igen, dette kan være måden, det gøres på, hvis du ikke ved, at de andre triggere eksisterer, eller hvis du er bange for at røre ved de andre triggere på grund af regressionsproblemer.
Her er de kildedata, vi har med at gøre:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Nu, for hver af de 6 tests, vil vi køre vores opdateringer 1.000 gange og måle længden af tid
T1:Baseline
Dette er scenariet, hvor vi er heldige nok til at undgå triggere (igen, ikke særlig realistisk). I dette tilfælde vil vi måle aflæsningerne og varigheden af denne batch. Jeg sætter /*real*/ ind i forespørgselsteksten, så jeg nemt kan trække statistikken for netop disse udsagn, og ikke nogen udsagn inde fra triggerne, da metrics i sidste ende ruller op til de udsagn, der påkalder triggerne. Bemærk også, at de faktiske opdateringer, jeg laver, ikke rigtig giver nogen mening, så ignorer, at jeg indstiller sorteringen til server-/instansnavnet og objektets principal_id til den aktuelle sessions session_id .
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:Enkelt udløser
Til dette har vi brug for følgende simple trigger, som kun opdaterer dbo.src :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Så mangler vores batch kun at opdatere de to kolonner i den primære tabel:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:Enkelt trigger mod begge tabeller
Til denne test ser vores trigger sådan ud:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Og nu skal den batch, vi tester, blot opdatere den oprindelige kolonne i den primære tabel; den anden håndteres af triggeren:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:Enkelt trigger mod begge tabeller
Dette er ligesom T3, men nu har triggeren fire udsagn:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Testbatchen er uændret:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:To triggere
Her har vi en trigger til at opdatere den primære tabel, og en trigger til at opdatere den sekundære tabel:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Testbatchen er igen meget grundlæggende:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:Fire udløsere
Denne gang har vi en trigger for hver kolonne, der er påvirket; en i den primære tabel og tre i de sekundære tabeller.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Og testbatchen:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
Måling af arbejdsbelastningspåvirkning
Til sidst skrev jeg en simpel forespørgsel mod sys.dm_exec_query_stats for at måle aflæsninger og varighed for hver test:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Resultater
Jeg kørte testene 10 gange, indsamlede resultaterne og tog gennemsnittet af alt. Sådan gik det i stykker:
| Test/batch | Gennemsnitlig varighed (mikrosekunder) | Læsninger i alt (8.000 sider) |
|---|---|---|
| T1 :OPDATERING /*real*/ dbo.tr1 … | 22.608 | 205.134 |
| T2 :OPDATERING /*real*/ dbo.tr2 … | 32.749 | 11.331.628 |
| T3 :OPDATERING /*real*/ dbo.tr3 … | 72.899 | 22.838.308 |
| T4 :OPDATERING /*real*/ dbo.tr4 … | 78.372 | 44.463.275 |
| T5 :OPDATERING /*real*/ dbo.tr5 … | 88.563 | 41.514.778 |
| T6 :OPDATERING /*real*/ dbo.tr6 … | 127.079 | 100.330.753 |
Og her er en grafisk fremstilling af varigheden:
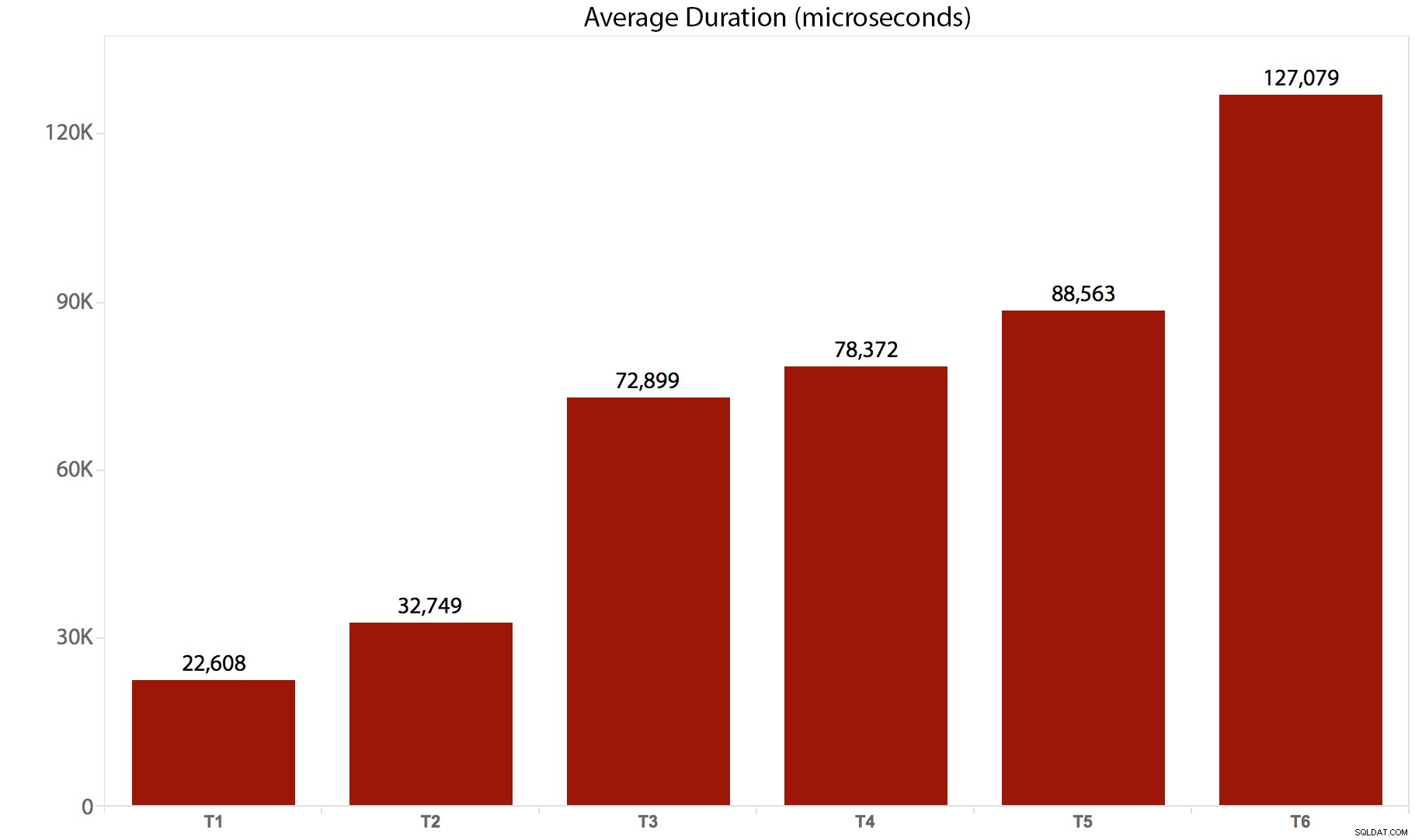
Konklusion
Det er klart, at der i dette tilfælde er nogle betydelige overhead for hver trigger, der bliver påkaldt – alle disse batches påvirkede i sidste ende det samme antal rækker, men i nogle tilfælde blev de samme rækker berørt flere gange. Jeg vil sandsynligvis udføre yderligere opfølgningstest for at måle forskellen, når den samme række aldrig berøres mere end én gang – et mere kompliceret skema, måske, hvor 5 eller 10 andre tabeller skal røres hver gang, og disse forskellige udsagn kunne være i en enkelt trigger eller i flere. Mit gæt er, at overhead-forskellene i højere grad vil blive drevet af ting som samtidighed og antallet af rækker, der påvirkes, end af selve udløserens overhead - men vi må se.
Vil du selv prøve demoen? Download scriptet her.