Opdatering:Q2’16 :Ud over guiden til databaseprofilering i menugruppen til dataopdagelse i IRI Workbench, der er beskrevet nedenfor, har IRI introduceret robust dataklassificering der muliggør anvendelse af feltregler for multi-source datatransformation og beskyttelse gennem dataklassebiblioteker. Opdatering Q2’18 :IRI har også introduceret en skemadækkende mønstersøgningsguide til at finde PII-matchende RegEx eller bogstavelige værdier i flere tabeller på én gang. Opdater Q2'19 :IRI tilbyder nu også inter/intra-skema dataklassesøgning ogmaskering for brugere IRI FieldShield eller Voracity. Og IRI har netop offentliggjort denne artikel for at vise, hvordan DB-profileringsresultaterne nedenfor vises i Splunk.
Med flere data, der indsamles fra flere aspekter af virksomheden i dag, er let bevidsthed om indholdet og arten afgørende for at sikre kvaliteten, kvantiteten og sikkerheden af disse samlinger. Dataprofilering er den væsentlige opdagelsesproces, der hjælper dig med at analysere, klassificere, rense, integrere, maskere og rapportere om data i dine depoter.
Ud over mørke og strukturerede dataopdagelsesguider (og metadatadefinitioner) sammen med cross-DB E-R diagrammering i Eclipse giver det nye cross-DB profileringsværktøj i IRI Workbench brugere mulighed for at undersøge strukturen og fuldstændigheden af databasedata og validere det de korrekte data bliver gemt de rigtige steder. I denne artikel vil vi undersøge dette værktøj og vise, hvordan det leverer tabelværdisøgeresultater og statistiske metadata.
For at få adgang til Database Profiler skal du navigere til den tabel, du vil have adgang til, i Data Source Explorer. Højreklik på bordet, og hold musen over IRI-indstillingen. I menuen, der vises, skal du vælge Ny databaseprofil .
På den første guideside skal du konfigurere jobbets placering og destination og vælge output fra profilrapporten som .csv eller en .txt-fil eller begge dele.
- .csv-formatet er nyttigt til import til nye tabeller og databaser, hvorimod
- .txt-formatet er en forudformateret rapport, som er nyttig til hurtigt at gennemgå resultater.
Statistiske profiloplysninger
Den næste del af guiden vises med to tabeller:
- Den øverste tabel er en liste over alle tabeller i databasen, med den tabel, der startede guiden, fremhævet som standard.
- Dette afkrydsningsfelt giver dig mulighed for et enkelt klik til at scanne hver tabel og række i din database.

- Den nederste tabel viser profileringsmulighederne efterfulgt af kolonnerne i den fremhævede tabel, hvor du vælger at udføre indstillingerne.

Klik på et hvilket som helst bord på listen, du ønsker at se og profilere. Indstillingsmatrixen ændrer automatisk for at repræsentere kolonnerne i den valgte tabel. Der er flere måder at håndtere visningsmulighederne på:
- For alle muligheder skal du klikke på det øverste afkrydsningsfelt i tabellen, mærket Alle, og alle metadataene vil blive rapporteret.
- Kun for grundlæggende muligheder (optælling og værdier), skal du markere afkrydsningsfeltet med navnet Basics.
- Kun for længdemuligheder (værdilængder) skal du markere afkrydsningsfeltet mærket Længder.
Hvis du har mange kolonner i din tabel og ønsker at vælge den samme mulighed for dem alle, skal du klikke på selve indstillingsnavnet, og alle kolonnerne vil have denne mulighed valgt. Du kan fravælge kolonner i indstillingen.
Når alt er indstillet, skal du klikke på Udfør og så vil profilen blive genereret for dig.
Udtrykssøgning
Et unikt valg i indstillingstabellen er -Expression Search-. Denne mulighed giver dig mulighed for at søge i kolonner mod en række søgemuligheder. Disse muligheder er:
- Regulære udtryk (mønstersøgning). Dette lokaliserer og tæller det antal gange, en værdi matcher formatet af et søgemønster.
- Uklar streng. Denne indstilling giver dig mulighed for at søge efter strenge, der ligner dem, du indtaster, og at vælge eller angive søgebetingelser.
- Værdifil. Denne mulighed giver dig mulighed for at sammenligne en streng med hver streng i en sætfil og tælle hver streng, der matcher.
Udtrykssøgningssiden har 6 vigtige sektioner
- En søgetype-kombinationsboks til at vælge den type søgning, der skal udføres.
- Den valggruppe, der ændres afhængigt af den valgte søgetype
- Regulært udtryk:har to knapper; browse, som gennemser de eksisterende regulære udtryk, og Create... som tillader oprettelse af nye regulære udtryk.
- Fuzzy String:har et tællefelt, der specificerer tærsklen for den fuzzy søgning (hvor tæt strengene skal være for at blive betragtet som et match), og en kombinationsboks til at vælge den fuzzy søgealgoritme, der skal bruges.
- Værdifil:har en knap Gennemse... der lader dig søge efter den indstillede fil, der skal bruges til værdisøgningen.
- Et tekstfelt, hvor du skal indtaste dataene til din søgning.
- En rulleliste over de tabeller, som du kan anvende udtrykssøgningen på.
- En rulleliste over de kolonner, som du kan anvende udtrykssøgningen på.
- En tabel, der viser de søgninger, du har oprettet, og som vil blive udført af profileren.
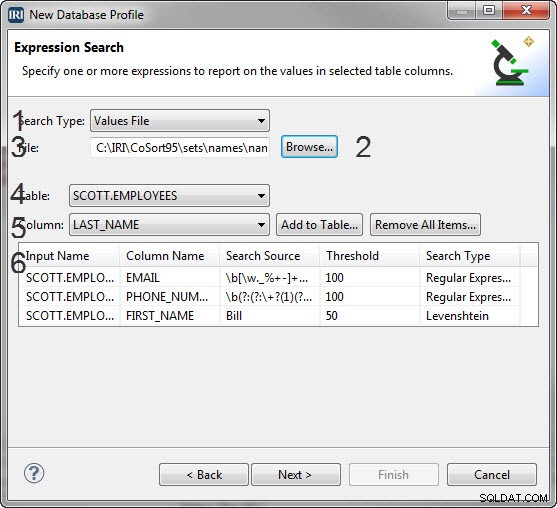
Sådan opretter du et regulært udtryksfilter:
- Vælg Regulært udtryk i kombinationen Søgetype .
- Klik på Gennemse til (dit bibliotek med gemte udtryk), eller klik på Opret for at angive et regulært udtryk, der skal bruges til at søge efter kolonneværdier.
- I menuen Tabel skal du vælge den tabel, der indeholder den kolonne, der skal filtreres.
- I kolonnemenuen skal du vælge den kolonne, som det regulære udtryk skal anvendes på.
- Klik på Tilføj til tabel , og der vises et element i tabellen nedenfor, der indeholder filnavnet, kolonnenavnet, søgekilden, tærskelværdien og det regulære udtryks-etiket, der udgør filteret.
- Gentag denne proces for hver kolonne, som du vil tilføje et filter til. Hvis du har for mange kolonner til at gøre denne proces praktisk, kan du stadig scanne flere kolonner og tabeller automatisk - for data, der matcher dine mønstre på tværs af et helt databaseskema - ved at bruge denne guide i stedet for.
Sådan opretter du en fuzzy strengsøgning:
- Vælg Fuzzy String fra søgetypekombinationen .
- Skriv den streng, der skal bruges til søgning.
- Vælg antallet af resultater, der skal returneres (denne mulighed vises, når Fuzzy Search er valgt).
- Vælg den Fuzzy Search Type, der skal bruges (denne mulighed vises, når Fuzzy String er valgt).
- I menuen Tabel skal du vælge den fil , der indeholder kolonnen for at fuzzy søgning.
- I kolonnemenuen skal du vælge den kolonne, som den uklare søgning skal udføres til.
- Klik på Tilføj til tabel , og der vises et element i tabellen nedenfor, der indeholder filnavnet, kolonnenavnet, søgekilden, tærskelværdien og søgetypen for den uklare søgning, der skal udføres.
- Gentag denne proces for hver kolonne, hvor du vil udføre en fuzzy strengsøgning.
Sådan oprettes en værdifilsøgning:
- Vælg Værdifil fra kombinationen Søgetype .
- Klik på Gennemse for at vælge en sæt fil, som kolonnen skal kontrolleres mod.
- I menuen Tabel skal du vælge den tabel, der indeholder den kolonne, der skal filtreres.
- I kolonnemenuen skal du vælge den kolonne, som det regulære udtryk skal anvendes på.
- Klik på Tilføj til tabel , og der vises et element i tabellen nedenfor, der indeholder filnavnet, kolonnenavnet, søgekilden, tærskelværdien og værdilistens søgeetiket, som udgør filteret.
Tjek af referenceintegritet
Et andet valg i indstillingstabellen er -Check Reference Integrity-. Denne indstilling gør det muligt for profileren at sammenligne en eller flere kolonner med en anden kolonne og afgøre, om kolonnerne har referenceintegritet. For at bruge denne funktion skal du markere afkrydsningsfelterne -Check Reference Integrity- på kolonnerne for at sammenligne for referenceintegritet. Næste-knappen aktiveres og giver dig mulighed for at specificere parametrene for referenceintegritetskontrollen (se nedenfor for detaljer).
Hvis du valgte indstillingen Tjek referenceintegritet for en af dine kolonner, skal du klikke på Næste for at gå til siden Referenceintegritetstjek. Denne side har følgende funktioner:
- To kombinationsbokse, den ene til at vælge den tabel, den primære nøgle er i, den anden er til at angive den primære nøglekolonne.
- To kombinationsbokse, den ene til at vælge den tabel, hvori den fremmede nøgle er, den anden til at angive kolonnen med den fremmede nøgle. Der er også en knap til at tilføje den fremmede nøgle til en liste over fremmednøgler for at sammenligne med den primære nøgle.
- En knap til Opret integritetskontrol for at tilføje de primære og fremmede kolonner til listen nedenfor.
- En liste, der gemmer alle de referenceintegritetstjek, som vil blive udført af profileren.

Sådan opretter du et referentielt integritetstjek:
- Vælg den tabel, som den primære nøgle er i, i tabelkombinationsfeltet under Primærnøglekolonne.
- Vælg den primære nøgle i kolonnekombinationsfeltet under Primary Key Column.
- Vælg den tabel, som fremmednøglen er i, i tabelkombinationsfeltet under Kolonnen udenlandsk nøgle.
- Vælg fremmednøglen i kolonnekombinationsfeltet under Kolonne udenlandsk nøgle.
- Klik på knappen Tilføj til liste over fremmede nøgler...
- Gentag trin 3-5 for hver fremmednøgle, der skal kontrolleres mod den primære nøgle
- Klik på knappen Opret integritetstjek...
- Gentag ovenstående processer for hver kontrol af referenceintegritet, der skal udføres.
Eksempel på profiloutput

.csv vist i LibreOffice / .txt vist i EditPad Lite