Dette indlæg er en del af en serie om rækkemål. Du kan finde de andre dele her:
- Del 1:Indstilling og identifikation af rækkemål
- Del 2:Semi-joins
- Del 3:Anti Joins
Anvend Anti Join med en topoperatør
Du vil ofte se en inderside Top (1) operator i anvend anti join udførelsesplaner. For eksempel ved at bruge AdventureWorks-databasen:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Planen viser en øverste (1) operatør på indersiden af applikationen (ydre referencer) anti join:
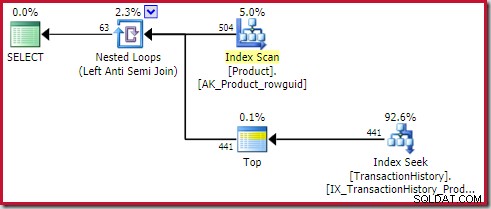
Denne Top-operatør er fuldstændig overflødig . Det er ikke påkrævet for korrekthed, effektivitet eller for at sikre, at et rækkemål er sat.
Anvend anti-sammenføjningsoperatøren stopper med at tjekke for rækker på indersiden (for den aktuelle iteration), så snart en række ses ved sammenføjningen. Det er fuldt ud muligt at generere en applicerings-anti-sammenføjningsplan uden toppen. Så hvorfor er der en topoperatør i denne plan?
Kilde til topoperatøren
For at forstå, hvor denne meningsløse Top-operatør kommer fra, er vi nødt til at følge de vigtigste skridt, der er taget under kompileringen og optimeringen af vores eksempelforespørgsel.
Som sædvanlig parses forespørgslen først ind i et træ. Dette har en logisk "eksisterer ikke"-operator med en underforespørgsel, som nøje matcher den skrevne form af forespørgslen i dette tilfælde:

Underforespørgslen ikke eksisterer rulles ud i en anvende anti join:

Dette omdannes derefter yderligere til en logisk venstre anti-semi join. Det resulterende træ, der overføres til omkostningsbaseret optimering, ser sådan ud:

Den første udforskning udført af den omkostningsbaserede optimizer er at introducere en logisk distinkt operation på det nederste anti-sammenføjningsinput for at producere unikke værdier for anti-sammenføjningsnøglen. Den generelle idé er, at i stedet for at teste duplikerede værdier ved joinforbindelsen, kan planen drage fordel af at gruppere disse værdier på forhånd.
Den ansvarlige udforskningsregel kaldes LASJNtoLASJNonDist (venstre anti semi join til venstre anti semi join på distinkt). Ingen fysisk implementering eller omkostningsberegning er blevet udført endnu, så dette er kun optimeringsværktøjet, der udforsker en logisk ækvivalens, baseret på tilstedeværelsen af dublet ProductID værdier. Det nye træ med tilføjet grupperingsoperation er vist nedenfor:

Den næste logiske transformation, der overvejes, er at omskrive joinforbindelsen som en anvend . Dette udforskes ved hjælp af reglen LASJNtoApply (venstre anti semi join for at anvende med relationelt valg). Som nævnt tidligere i serien, var den tidligere transformation fra anvende til join at muliggøre transformationer, der arbejder specifikt på joins. Det er altid muligt at omskrive en joinforbindelse som en ansøgning, så dette udvider rækken af tilgængelige optimeringer.
Nu gør optimeringsværktøjet ikke altid overveje en anvende omskrivning som en del af omkostningsbaseret optimering. Der skal være noget i det logiske træ for at gøre det umagen værd at skubbe sammenføjningsprædikatet ned ad indersiden. Typisk vil dette være eksistensen af et matchende indeks, men der er andre lovende mål. I dette tilfælde er det den logiske nøgle på ProductID oprettet af den samlede operation.
Resultatet af denne regel er en korreleret anti-sammenføjning med markering på indersiden:

Dernæst overvejer optimeringsværktøjet at flytte den relationelle udvælgelse (det korrelerede sammenføjningsprædikat) længere ned på indersiden, forbi det distinkte (gruppe for aggregat), som tidligere blev introduceret af optimeringsværktøjet. Dette gøres ved reglen SelOnGbAgg , som flytter så meget af et udvalg (prædikat) forbi en passende gruppe efter aggregat, som det kan (en del af udvalget kan blive efterladt). Denne aktivitet hjælper med at skubbe valg så tæt på dataadgangsoperatørerne på bladniveau som muligt for at eliminere rækker tidligere og gøre senere indeksmatchning nemmere.
I dette tilfælde er filteret i samme kolonne som grupperingsoperationen, så transformationen er gyldig. Det resulterer i, at hele udvalget bliver skubbet ind under aggregatet:

Den endelige operation af interesse udføres af reglen GbAggToConstScanOrTop . Denne transformation ser ud til at erstatte en gruppe efter aggregat med en konstant scanning eller Top logisk operation. Denne regel matcher vores træ, fordi grupperingskolonnen er konstant for hver række, der passerer gennem det skubbede valg. Alle rækker har med garanti det samme ProduktID . Gruppering på den enkelte værdi vil altid producere én række. Derfor er det gyldigt at transformere aggregatet til en Top (1). Så det er her toppen kommer fra.
Implementering og omkostningsberegning
Optimizeren kører nu en række implementeringsregler for at finde fysiske operatører for hver af de lovende logiske alternativer, den har overvejet indtil nu (lagret effektivt i en memostruktur). Hash og flet fysiske anti-tilslutningsmuligheder kommer fra det oprindelige træ med indført aggregat (med tilladelse fra rule LASJNtoLASJNonDist Husk). Ansøgningen har brug for lidt mere arbejde for at bygge en fysisk top og matche udvalget til en indekssøgning.
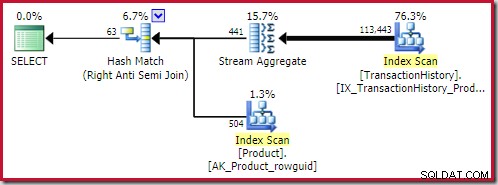
Den bedste hash anti join fundet løsning koster 0,362143 enheder:
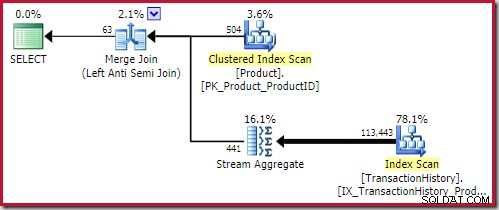
Den bedste fletnings-modtilslutning løsning kommer ind på 0,353479 enheder (lidt billigere):
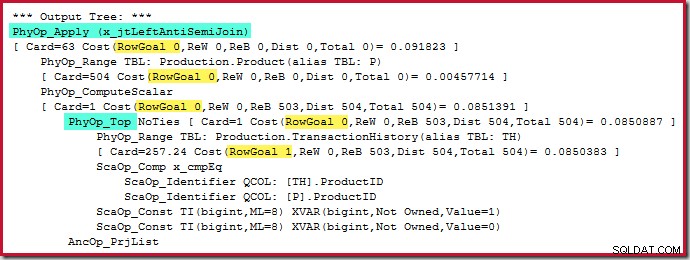
Anvend anti-tilmelding koster 0,091823 enheder (billigst med en bred margin):
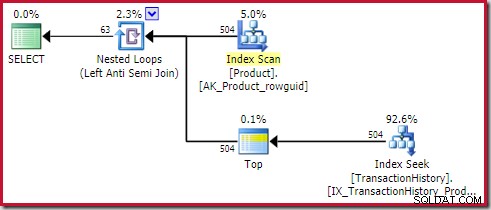
Den kloge læser kan bemærke, at rækketællingerne på indersiden af påførings-antisammenføjningen (504) afviger fra det forrige skærmbillede af samme plan. Dette skyldes, at der er tale om en estimeret plan, mens den tidligere plan var efterudførelse. Når denne plan udføres, findes der kun i alt 441 rækker på indersiden over alle iterationer. Dette fremhæver en af visningsproblemerne med at anvende semi/anti join-planer:Minimumsoptimeringsestimatet er én række, men en semi- eller anti join vil altid finde én række eller ingen rækker på hver iteration. De 504 rækker vist ovenfor repræsenterer 1 række på hver af 504 iterationer. For at få tallene til at matche, skal estimatet være 441/504 =0,875 rækker hver gang, hvilket sandsynligvis ville forvirre folk lige så meget.
Planen ovenfor er i hvert fald "heldig" nok til at kvalificere sig til et rækkemål på indersiden af applicerings-anti-join af to grunde:
- Anti-sammenføjningen omdannes fra en sammenkædning til en anvendelse i den omkostningsbaserede optimering. Dette sætter et rækkemål (som fastsat i del tre).
- Top(1)-operatoren angiver også et rækkemål på sit undertræ.
Selve topoperatøren har ikke et rækkemål (fra anvende), da rækkemålet på 1 ikke er mindre end det almindelige skøn, som også er 1 række (Card=1 for PhyOp_Top nedenfor):
Anti Join Anti Pattern
Følgende generelle planform er en, jeg betragter som et antimønster:
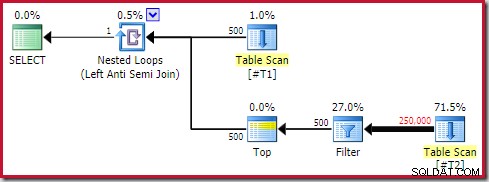
Ikke enhver udførelsesplan, der indeholder en påføringssikring med en top (1) operatør på indersiden, vil være problematisk. Ikke desto mindre er det et mønster at genkende, og som næsten altid kræver yderligere undersøgelse.
De fire hovedelementer, du skal være opmærksom på, er:
- A-korreleret indlejrede sløjfer (anvend ) anti join
- En Top (1) operatør umiddelbart på indersiden
- Et betydeligt antal rækker på det ydre input (så den indvendige side vil blive kørt mange gange)
- En potentielt dyr undertræet under toppen
"$$$"-undertræet er et, der er potentielt dyrt ved kørsel . Dette kan være svært at genkende. Hvis vi er heldige, vil der være noget oplagt som en fuld tabel eller indeksscanning. I mere udfordrende tilfælde vil undertræet se helt uskyldigt ud ved første øjekast, men indeholde noget dyrt, når man ser nærmere på det. For at give et ret almindeligt eksempel kan du måske se en indekssøgning, der forventes at returnere et lille antal rækker, men som indeholder et dyrt restprædikat, der tester et meget stort antal rækker for at finde de få, der kvalificerer sig.
Det foregående AdventureWorks-kodeeksempel havde ikke et "potentielt dyrt" undertræ. Indekssøgningen (uden resterende prædikat) ville være en optimal adgangsmetode uanset rækkemålsovervejelser. Dette er et vigtigt punkt:at give optimeringsværktøjet en altid effektiv dataadgangssti på indersiden af en korreleret join er altid en god idé. Dette er endnu mere sandt, når appliceringen kører i anti-sammenføjningstilstand med en Top (1) operatør på indersiden.
Lad os nu se på et eksempel, der har en temmelig dyster runtime-ydeevne på grund af dette anti-mønster.
Eksempel
Følgende script opretter to heap midlertidige tabeller. Den første har 500 rækker, der indeholder heltal fra 1 til 500 inklusive. Den anden tabel har 500 kopier af hver række i den første tabel, i alt 250.000 rækker. Begge tabeller bruger sql_variant datatype.
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; Ydeevne
Vi kører nu en forespørgsel, der leder efter rækker i den mindre tabel, som ikke er til stede i den større tabel (selvfølgelig er der ingen):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); Denne forespørgsel kører i ca. 20 sekunder , hvilket er frygtelig lang tid at sammenligne 500 rækker med 250.000. Den estimerede SSMS-plan gør det svært at se, hvorfor ydeevnen kan være så dårlig:
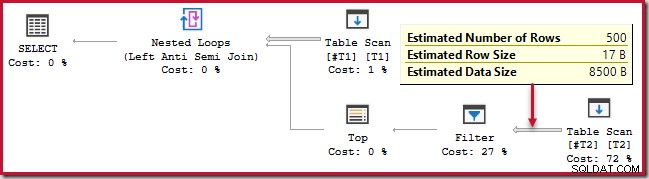
Observatøren skal være opmærksom på, at SSMS-estimerede planer viser indre sideestimater pr. iteration af den indlejrede løkkesammenføjning. Forvirrende nok viser faktiske SSMS-planer antallet af rækker over alle iterationer . Plan Explorer udfører automatisk de simple beregninger, der er nødvendige for, at estimerede planer også viser det samlede antal forventede rækker:
Alligevel er køretidsydelsen meget dårligere end anslået. Efterudførelsen (faktisk) udførelsesplan er:
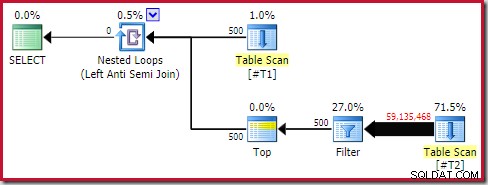
Bemærk det separate filter, som normalt ville blive skubbet ned i scanningen som et resterende prædikat. Dette er grunden til at bruge sql_variant datatype; det forhindrer at skubbe prædikatet, hvilket gør det store antal rækker fra scanningen nemmere at se.
Analyse
Årsagen til uoverensstemmelsen kommer ned til, hvordan optimeringsværktøjet estimerer antallet af rækker, den skal læse fra tabelscanningen for at nå målet med én række, der er fastsat ved filteret. Den simple antagelse er, at værdier er ensartet fordelt i tabellen, så for at støde på 1 af de 500 unikke værdier, der er til stede, skal SQL Server læse 250.000 / 500 =500 rækker. Over 500 iterationer, det kommer til 250.000 rækker.
Optimizerens ensartethedsantagelse er generel, men den fungerer ikke godt her. Du kan læse mere om dette i A Row Goal Request af Joe Obbish og stemme for hans forslag på Connect erstatningsfeedback-forummet på Use More Than Density to Cost a Scan on the Inter Side of a Nested Loop with TOP.
Mit syn på dette specifikke aspekt er, at optimeringsværktøjet hurtigt skal vende tilbage fra en simpel ensartethedsantagelse, når operatøren er på indersiden af en indlejret løkkesammenføjning (dvs. estimerede tilbagespolinger plus genbindinger er større end én). Det er én ting at antage, at vi skal læse 500 rækker for at finde et match på den første iteration af løkken. At antage dette ved hver iteration forekommer meget usandsynligt at være nøjagtigt; det betyder, at de første 500 rækker, der stødes på, skal indeholde en af hver enkelt værdi. Det er højst usandsynligt, at dette er tilfældet i praksis.
En række uheldige hændelser
Uanset måden gentagne Top-operatører er prissat på, forekommer det mig, at hele situationen bør undgås i første omgang . Husk, hvordan toppen i denne plan blev oprettet:
- Optimeringsværktøjet introducerede et særskilt aggregat på indersiden som en ydeevneoptimering .
- Denne aggregat giver per definition en nøgle på join-kolonnen (det producerer unikhed).
- Denne konstruerede nøgle giver et mål for konverteringen fra en joinforbindelse til en application.
- Det prædikat (udvælgelse), der er knyttet til applikationen, skubbes ned forbi aggregatet.
- Aggregationen er nu garanteret at fungere på en enkelt distinkt værdi pr. iteration (da det er en korrelationsværdi).
- Aggregationen erstattes af en Top (1).
Alle disse transformationer er gyldige individuelt. De er en del af normale optimeringsoperationer, da den søger efter en rimelig eksekveringsplan. Desværre er resultatet her, at det spekulative aggregat introduceret af optimeringsværktøjet ender med at blive forvandlet til en Top (1) med et tilhørende rækkemål . Rækkemålet fører til unøjagtige omkostninger baseret på ensartethedsantagelsen og derefter til valg af en plan, der er højst usandsynligt, at den vil fungere godt.
Nu kan man indvende, at den anvende anti-join alligevel ville have et rækkemål – uden ovenstående transformationssekvens. Modargumentet er, at optimeringsværktøjet ikke ville overveje transformation fra anti join til anvend anti join (indstilling af rækkemålet) uden det optimeringsindførte aggregat, der giver LASJNtoApply bestemme noget at binde sig til. Derudover har vi set (i del tre), at hvis anti-join var gået ind i omkostningsbaseret optimering som en application (i stedet for en join), ville der igen være intet rækkemål .
Kort sagt er rækkemålet i den endelige plan helt kunstigt og har intet grundlag i den oprindelige forespørgselsspecifikation. Problemet med top- og rækkemålet er en bivirkning af dette mere grundlæggende aspekt.
Løsninger
Der er mange potentielle løsninger på dette problem. Hvis du fjerner et hvilket som helst af trinene i optimeringssekvensen ovenfor, sikrer du, at optimeringsværktøjet ikke producerer en applicerings-anti-sammenføjningsimplementering med dramatisk (og kunstigt) reducerede omkostninger. Forhåbentlig vil dette problem blive løst i SQL Server før snarere end senere.
I mellemtiden er mit råd at passe på anti join anti-mønsteret. Sørg for, at indersiden af en applicerings-anti-sammenføjning altid har en effektiv adgangssti til alle driftsforhold. Hvis dette ikke er muligt, skal du muligvis bruge tip, deaktivere rækkemål, bruge en planvejledning eller tvinge en forespørgselsbutiksplan for at få stabil ydeevne fra forespørgsler mod deltagelse.
Serieoversigt
Vi har dækket meget over de fire rater, så her er en oversigt på højt niveau:
- Del 1 – Opstilling og identifikation af rækkemål
- Forespørgselssyntaks bestemmer ikke tilstedeværelsen eller fraværet af et rækkemål.
- Et rækkemål angives kun, når målet er mindre end det almindelige estimat.
- Physical Top-operatorer (inklusive dem, der er introduceret af optimeringsværktøjet) tilføjer et rækkemål til deres undertræ.
- En
FASTellerSET ROWCOUNTstatement sætter et rækkemål i roden af planen. - Semi join og anti join kan tilføje et rækkemål.
- SQL Server 2017 CU3 tilføjer showplan-attributten EstimateRowsWithoutRowGoal for operatører, der er påvirket af et rækkemål
- Oplysninger om rækkemål kan afsløres af udokumenterede sporingsflag 8607 og 8612.
- Del 2 – Semi-joins
- Det er ikke muligt at udtrykke en semi join direkte i T-SQL, så vi bruger indirekte syntaks f.eks.
IN,EXISTS, ellerINTERSECT. - Disse syntakser er parset ind i et træ, der indeholder en application (korreleret join).
- Optimeringsværktøjet forsøger at omdanne ansøgningen til en almindelig joinforbindelse (ikke altid muligt).
- Hash, fletning og regulære indlejrede sløjfer semi-sammenføjning angiver ikke et rækkemål.
- Anvend semi-deltagelse sætter altid et rækkemål.
- Anvend semi join kan genkendes ved at have ydre referencer på den indlejrede sløjfer join-operator.
- Anvend semi join bruger ikke en Top (1) operator på indersiden.
- Del 3 – Anti Joins
- Også parset i en ansøgning med et forsøg på at omskrive det som en joinforbindelse (ikke altid muligt).
- Hash, fletning og regulære indlejrede sløjfer mod joinforbindelse angiver ikke et rækkemål.
- Anvend anti-deltagelse sætter ikke altid et rækkemål.
- Kun omkostningsbaserede optimeringsregler (CBO), der omdanner anti joinforbindelse til at anvende, sætter et rækkemål.
- Anti joinforbindelsen skal indtaste CBO som en joinforbindelse (gælder ikke). Ellers kan joinforbindelsen til at anvende transformation ikke forekomme.
- For at indtaste CBO som en joinforbindelse skal pre-CBO-omskrivningen fra ansøg til join være lykkedes.
- CBO undersøger kun omskrivning af en anti-join til en ansøgning i lovende tilfælde.
- Pre-CBO-forenklinger kan ses med udokumenteret sporingsflag 8621.
- Del 4 – Anti Join Anti Pattern
- Optimeringsværktøjet sætter kun et rækkemål for at anvende anti join, hvor der er en lovende grund til at gøre det.
- Desværre tilføjer flere interagerende optimeringstransformationer en Top (1) operator til indersiden af en anvende anti-sammenføjning.
- Topoperatoren er redundant; det er ikke nødvendigt for korrekthed eller effektivitet.
- Toppen sætter altid et rækkemål (i modsætning til anvende, som kræver en god grund).
- Det uberettigede rækkemål kan føre til ekstremt dårlig ydeevne.
- Pas på et potentielt dyrt undertræ under den kunstige Top (1).