Databaser, der betjener forretningsapplikationer, bør ofte understøtte tidsmæssige data. Antag for eksempel, at en kontrakt med en leverandør kun er gyldig i en begrænset periode. Det kan være gyldigt fra et bestemt tidspunkt og frem, eller det kan være gyldigt for et bestemt tidsinterval – fra et starttidspunkt til et sluttidspunkt. Derudover skal du mange gange revidere alle ændringer i en eller flere tabeller. Du skal muligvis også være i stand til at vise tilstanden på et bestemt tidspunkt eller alle ændringer, der er foretaget i en tabel i et bestemt tidsrum. Fra et dataintegritetsperspektiv skal du muligvis implementere mange yderligere tidsmæssige specifikke begrænsninger.
Introduktion af tidsmæssige data
I en tabel med tidsmæssig understøttelse repræsenterer overskriften et prædikat med en mindst engangsparameter, der repræsenterer intervallet når resten af prædikatet er gyldigt - det komplette prædikat er derfor et tidsstemplet prædikat. Rækker repræsenterer tidsstemplede propositioner, og rækkens gyldige tidsperiode udtrykkes typisk med to attributter:fra og til , eller begynd og slut .
Typer af tidsmæssige tabeller
Du har måske bemærket under introduktionsdelen, at der er to slags tidsmæssige problemer. Den første er gyldighedstiden af propositionen – i hvilken periode den proposition, som en tidsstemplet række i en tabel repræsenterer, faktisk var sand. For eksempel var en kontrakt med en leverandør kun gyldig fra tidspunkt 1 til tidspunkt 2. Denne form for gyldighedstid er meningsfuld for mennesker, meningsfuld for virksomheden. Gyldighedstiden kaldes også ansøgningstid eller menneskelig tid . Vi kan have flere gyldige perioder for den samme enhed. For eksempel kan den førnævnte kontrakt, der var gyldig fra tidspunkt 1 til tidspunkt 2, også være gyldig fra tidspunkt 7 til tidspunkt 9.
Det andet tidsmæssige problem er transaktionstiden . En række for kontrakten nævnt ovenfor blev indsat på tidspunkt 1 og var den eneste version af sandheden kendt af databasen, indtil nogen ændrede den, eller endda til slutningen af tiden. Når rækken opdateres på tidspunkt 2, var den oprindelige række kendt for at være tro mod databasen fra tidspunkt 1 til tidspunkt 2. En ny række for samme proposition indsættes med tid gældende for databasen fra tidspunkt 2 til slutningen af tiden. Transaktionstiden er også kendt som systemtid eller databasetid .
Du kan selvfølgelig også implementere både applikations- og systemversionerede tabeller. Sådanne tabeller kaldes bitemporale tabeller.
I SQL Server 2016 får du support til systemet time out of the box med systemversionerede tidstabeller . Hvis du skal implementere ansøgningstid, skal du selv udvikle en løsning.
Allen's Interval Operators
Teorien for de tidsmæssige data i en relationel model begyndte at udvikle sig for mere end tredive år siden. Jeg vil introducere en del nyttige boolske operatorer og et par operatorer, der arbejder på intervaller og returnerer et interval. Disse operatører er kendt som Allens operatører, opkaldt efter J. F. Allen, som definerede en række af dem i et forskningspapir fra 1983 om tidsmæssige intervaller. Alle af dem er stadig accepteret som gyldige og nødvendige. Et databasestyringssystem kan hjælpe dig med at håndtere ansøgningstider ved at implementere disse operatører ud af boksen.
Lad mig først introducere den notation, jeg vil bruge. Jeg vil arbejde med to intervaller, betegnet i1 og i2 . Starttidspunktet for det første interval er b1 , og enden er e1 ; starttidspunktet for det andet interval er b2 og enden er e2 . Allens boolske operatører er defineret i følgende tabel.
[tabel id=2 /]
Ud over booleske operatorer er der Allens tre operatorer, der accepterer intervaller som inputparametre og returnerer et interval. Disse operatorer udgør simpel intervalalgebra . Bemærk, at disse operatorer har samme navn som relationelle operatorer, du sikkert allerede kender:Union, Intersect og Minus. De opfører sig dog ikke nøjagtigt som deres relationelle modstykker. Generelt, ved brug af en af de tre intervaloperatorer, hvis operationen ville resultere i et tomt sæt af tidspunkter eller i et sæt, der ikke kan beskrives med ét interval, så skal operatøren returnere NULL. En forening af to intervaller giver kun mening, hvis intervallerne mødes eller overlapper hinanden. Et kryds giver kun mening, hvis intervallerne overlapper hinanden. Minusintervaloperatoren giver kun mening i nogle tilfælde. For eksempel returnerer (3:10) Minus (5:7) NULL, fordi resultatet ikke kan beskrives med ét interval. Følgende tabel opsummerer definitionen af operatorerne for intervalalgebra.
[tabel id=3 /]
Overlappende forespørgsler Ydeevneproblem En af de mest komplekse operatører at implementere er overlapningerne operatør. Forespørgsler, der skal finde overlappende intervaller, er ikke nemme at optimere. Sådanne forespørgsler er dog ret hyppige på tidsmæssige tabeller. I denne og de næste to artikler vil jeg vise dig et par måder at optimere sådanne forespørgsler på. Men før jeg introducerer løsningerne, så lad mig introducere problemet.
For at forklare problemet har jeg brug for nogle data. Følgende kode viser et eksempel på, hvordan man opretter en tabel med gyldighedsintervaller udtrykt med b og e kolonner, hvor begyndelsen og slutningen af et interval er repræsenteret som heltal. Tabellen er udfyldt med demodata fra tabellen WideWorldImporters.Sales.OrderLines. Bemærk venligst, at der er flere versioner af WideWorldImporters database, så du kan få lidt anderledes resultater. Jeg brugte WideWorldImporters-Standard.bak backup-filen fra https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 til at gendanne denne demodatabase på min SQL Server-instans .
Oprettelse af demodata
Jeg oprettede en demo-tabel dbo.Intervals i tempd database med følgende kode.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Bemærk også indekserne oprettet. De to indekser er optimale til søgninger i begyndelsen af et interval eller i slutningen af et interval. Du kan kontrollere den minimale begyndelse og maksimale slutning af alle intervaller med følgende kode.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
Du kan se i resultaterne, at det minimale begyndelsestidspunkt er 1 og maksimalt sluttidspunkt er 1155.
Giv konteksten til dataene
Du bemærker måske, at jeg repræsenterer begyndelsen og slutningen af tidspunkter som heltal. Nu skal jeg give intervallerne noget tidssammenhæng. I dette tilfælde repræsenterer et enkelt tidspunkt en dag . Følgende kode opretter en datoopslagstabel og befolker den. Bemærk, at startdatoen er den 1. juli 2014.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Nu kan du forbinde tabellen dbo.Intervals med tabellen dbo.DateNums to gange for at give konteksten til de heltal, der repræsenterer begyndelsen og slutningen af intervallerne.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Introduktion af ydeevneproblemet
Problemet med tidsmæssige forespørgsler er, at når man læser fra en tabel, kan SQL Server kun bruge ét indeks og med succes eliminere rækker, der ikke er kandidater til resultatet kun fra den ene side, og derefter scanne resten af dataene. For eksempel skal du finde alle intervaller i tabellen, som overlapper med et givet interval. Husk, at to intervaller overlapper hinanden, når begyndelsen af den første er lavere eller lig med slutningen af den anden, og begyndelsen af den anden er lavere eller lig med slutningen af den første, eller matematisk når (b1 ≤ e2) OG (b2 ≤ el).
Den følgende forespørgsel søgte efter alle de intervaller, der overlapper med intervallet (10, 30). Bemærk, at den anden betingelse (b2 ≤ e1) er vendt om til (e1 ≥ b2) for en enklere aflæsning (begyndelsen og slutningen af intervaller fra tabellen er altid på venstre side af betingelsen). Det givne, eller det søgte interval, er i begyndelsen af tidslinjen for alle intervaller i tabellen.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);>
Forespørgslen brugte 36 logiske læsninger. Hvis du tjekker udførelsesplanen, kan du se, at forespørgslen brugte indekssøgningen i idx_b-indekset med søgeprædikatet [tempdb].[dbo].[Intervals].b <=Scalar Operator((30)) og scan derefter rækkerne, og vælg de resulterende rækker ved hjælp af restprædikatet [tempdb].[dbo].[Intervaller].[e]>=(10). Fordi det søgte interval er i begyndelsen af tidslinjen, eliminerede søgeprædikatet størstedelen af rækkerne. kun nogle få intervaller i tabellen har startpunktet lavere eller lig med 30.
Du ville få en tilsvarende effektiv forespørgsel, hvis det søgte interval ville være i slutningen af tidslinjen, bare at SQL Server ville bruge idx_e-indekset til at søge. Men hvad sker der, hvis det søgte interval er midt på tidslinjen, som den følgende forespørgsel viser?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Denne gang brugte forespørgslen 111 logiske læsninger. Med en større tabel ville forskellen med den første forespørgsel være endnu større. Hvis du tjekker udførelsesplanen, kan du finde ud af, at SQL Server brugte idx_e-indekset med [tempdb].[dbo].[Intervals].e>=Scalar Operator((570)) søgeprædikat og [tempdb].[ dbo].[Intervaller].[b]<=(590) restprædikat. Søgeprædikatet udelukker cirka halvdelen af rækkerne fra den ene side, mens halvdelen af rækkerne fra den anden side scannes, og de resulterende rækker ekstraheres med det resterende prædikat.
Forbedret T-SQL-løsning
Der er en løsning, som ville bruge det indeks til at eliminere rækkerne fra begge sider af det søgte interval ved at bruge et enkelt indeks. Følgende figur viser denne logik.
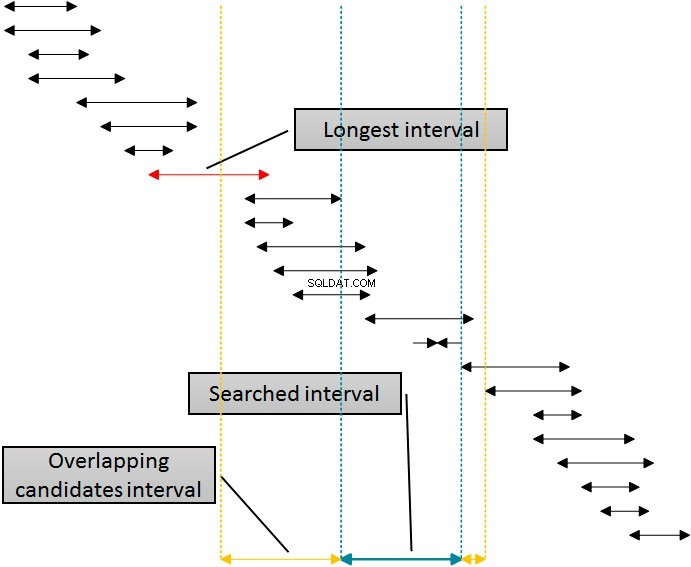
Intervallerne i figuren er sorteret efter den nedre grænse, der repræsenterer SQL Servers brug af idx_b-indekset. Eliminering af intervaller fra højre side af det givne (søgte) interval er enkelt:eliminer blot alle intervaller, hvor begyndelsen er mindst en enhed større (mere til højre) af slutningen af det givne interval. Du kan se denne grænse i figuren med den stiplede linje længst til højre. Det er dog mere komplekst at eliminere fra venstre. For at bruge det samme indeks, idx_b-indekset til at eliminere fra venstre, skal jeg bruge begyndelsen af intervallerne i tabellen i WHERE-sætningen i forespørgslen. Jeg skal gå til venstre side væk fra begyndelsen af det givne (søgte) interval i det mindste for længden af det længste interval i tabellen, som er markeret med en forklaring i figuren. De intervaller, der begynder før den venstre gule linje, kan ikke overlappe det givne (blå) interval.
Da jeg allerede ved, at længden af det længste interval er 20, kan jeg skrive en forbedret forespørgsel på en ganske enkel måde.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Denne forespørgsel henter de samme rækker som den forrige med kun 20 logiske læsninger. Hvis du tjekker udførelsesplanen, kan du se, at idx_b blev brugt, med søgeprædikatet Seek Keys[1]:Start:[tempdb].[dbo].[Intervals].b>=Scalar Operator((550)) , End:[tempdb].[dbo].[Intervals].b <=Scalar Operator((590)), som med succes eliminerede rækker fra begge sider af tidslinjen, og derefter det resterende prædikat [tempdb].[dbo]. [Intervaller].[e]>=(570) OG [tempdb].[dbo].[Intervaller].[e]<=(610) blev brugt til at vælge rækker fra en meget begrænset delvis scanning.
Selvfølgelig kunne figuren vendes for at dække de tilfælde, hvor idx_e-indekset ville være mere nyttigt. Med dette indeks er elimineringen fra venstre enkel – eliminer alle de intervaller, der slutter mindst en enhed før begyndelsen af det givne interval. Denne gang er elimineringen fra højre mere kompleks – slutningen af intervallerne i tabellen kan ikke være mere til højre end slutningen af det givne interval plus den maksimale længde af alle intervaller i tabellen.
Bemærk venligst, at denne præstation er en konsekvens af de specifikke data i tabellen. Den maksimale længde af et interval er 20. På denne måde kan SQL Server meget effektivt eliminere intervaller fra begge sider. Men hvis der kun ville være ét langt interval i tabellen, ville koden blive meget mindre effektiv, fordi SQL Server ikke ville være i stand til at eliminere en masse rækker fra den ene side, hverken venstre eller højre, afhængigt af hvilket indeks den ville bruge . I det virkelige liv varierer intervallængden ikke meget mange gange, så denne optimeringsteknik kan være meget nyttig, især fordi den er enkel.
Konklusion
Bemærk venligst, at dette kun er en mulig løsning. Du kan finde en løsning, der er mere kompleks, men alligevel giver den forudsigelig ydeevne uanset længden af det længste interval i Interval Queries in SQL Server-artiklen af Itzik Ben-Gan (https://sqlmag.com/t-sql/ sql-server-interval-forespørgsler). Jeg kan dog rigtig godt lide den forbedrede T-SQL løsning, jeg præsenterede i denne artikel. Løsningen er meget enkel; alt du skal gøre er at tilføje to prædikater til WHERE-sætningen i dine overlappende forespørgsler. Dette er dog ikke enden på mulighederne. Hold dig opdateret, i de næste to artikler vil jeg vise dig flere løsninger, så du får et rigt sæt muligheder i din optimeringsværktøjskasse.
Nyttigt værktøj:
dbForge Query Builder til SQL Server – giver brugerne mulighed for hurtigt og nemt at bygge komplekse SQL-forespørgsler via en intuitiv visuel grænseflade uden manuel kodeskrivning.