Data er sandsynligvis et af de mest værdifulde aktiver i en virksomhed. På grund af dette bør vi altid have en Disaster Recovery Plan (DRP) for at forhindre tab af data i tilfælde af en ulykke eller hardwarefejl.
En backup er den enkleste form for DR, men det er måske ikke altid nok til at garantere et acceptabelt Recovery Point Objective (RPO). Det anbefales, at du har mindst tre sikkerhedskopier gemt forskellige fysiske steder.
Bedste praksis dikterer, at sikkerhedskopieringsfiler skal have én gemt lokalt på databaseserveren (for en hurtigere gendannelse), en anden på en centraliseret backupserver og den sidste i skyen.
Til denne blog tager vi et kig på, hvilke muligheder Amazon AWS giver for lagring af PostgreSQL-sikkerhedskopier i skyen, og vi viser nogle eksempler på, hvordan man gør det.
Om Amazon AWS
Amazon AWS er en af verdens mest avancerede cloud-udbydere med hensyn til funktioner og tjenester med millioner af kunder. Hvis vi ønsker at køre vores PostgreSQL-databaser på Amazon AWS, har vi nogle muligheder...
-
Amazon RDS:Det giver os mulighed for at oprette, administrere og skalere en PostgreSQL-database (eller forskellige databaseteknologier) i skyen på en nem og hurtig måde.
-
Amazon Aurora:Det er en PostgreSQL-kompatibel database bygget til skyen. Ifølge AWS-webstedet er det tre gange hurtigere end standard PostgreSQL-databaser.
-
Amazon EC2:Det er en webtjeneste, der giver computerkapacitet, der kan ændres størrelse, i skyen. Det giver dig fuld kontrol over dine computerressourcer og giver dig mulighed for at opsætte og konfigurere alt om dine instanser fra dit operativsystem til dine applikationer.
Men faktisk behøver vi ikke have vores databaser kørende på Amazon for at gemme vores sikkerhedskopier her.
Lagring af sikkerhedskopier på Amazon AWS
Der er forskellige muligheder for at gemme vores PostgreSQL-sikkerhedskopi på AWS. Hvis vi kører vores PostgreSQL-database på AWS, har vi flere muligheder, og (da vi er i samme netværk) kan det også være hurtigere. Lad os se, hvordan AWS kan hjælpe os med at gemme vores sikkerhedskopier.
AWS CLI
Lad os først forberede vores miljø til at teste de forskellige AWS-muligheder. Til vores eksempler bruger vi en On-prem PostgreSQL 11-server, der kører på CentOS 7. Her skal vi installere AWS CLI ved at følge instruktionerne fra dette websted.
Når vi har vores AWS CLI installeret, kan vi teste det fra kommandolinjen:
[example@sqldat.com ~]# aws --version
aws-cli/1.16.225 Python/2.7.5 Linux/4.15.18-14-pve botocore/1.12.215Næste trin er nu at konfigurere vores nye klient, der kører aws-kommandoen med indstillingsmuligheden.
[example@sqldat.com ~]# aws configure
AWS Access Key ID [None]: AKIA7TMEO21BEBR1A7HR
AWS Secret Access Key [None]: SxrCECrW/RGaKh2FTYTyca7SsQGNUW4uQ1JB8hRp
Default region name [None]: us-east-1
Default output format [None]:For at få disse oplysninger kan du gå til IAM AWS-sektionen og kontrollere den aktuelle bruger, eller hvis du foretrækker det, kan du oprette en ny til denne opgave.
Herefter er vi klar til at bruge AWS CLI til at få adgang til vores Amazon AWS-tjenester.
Amazon S3
Dette er sandsynligvis den mest brugte mulighed for at gemme sikkerhedskopier i skyen. Amazon S3 kan gemme og hente enhver mængde data fra hvor som helst på internettet. Det er en simpel lagringstjeneste, der tilbyder en ekstremt holdbar, meget tilgængelig og uendeligt skalerbar datalagringsinfrastruktur til lave omkostninger.
Amazon S3 giver en simpel webservicegrænseflade, som du kan bruge til at gemme og hente enhver mængde data, til enhver tid, fra hvor som helst på nettet, og (med AWS CLI eller AWS SDK) kan integrere det med forskellige systemer og programmeringssprog.
Sådan bruges det
Amazon S3 bruger Buckets. De er unikke beholdere til alt, hvad du gemmer i Amazon S3. Så det første skridt er at få adgang til Amazon S3 Management Console og oprette en ny Bucket.
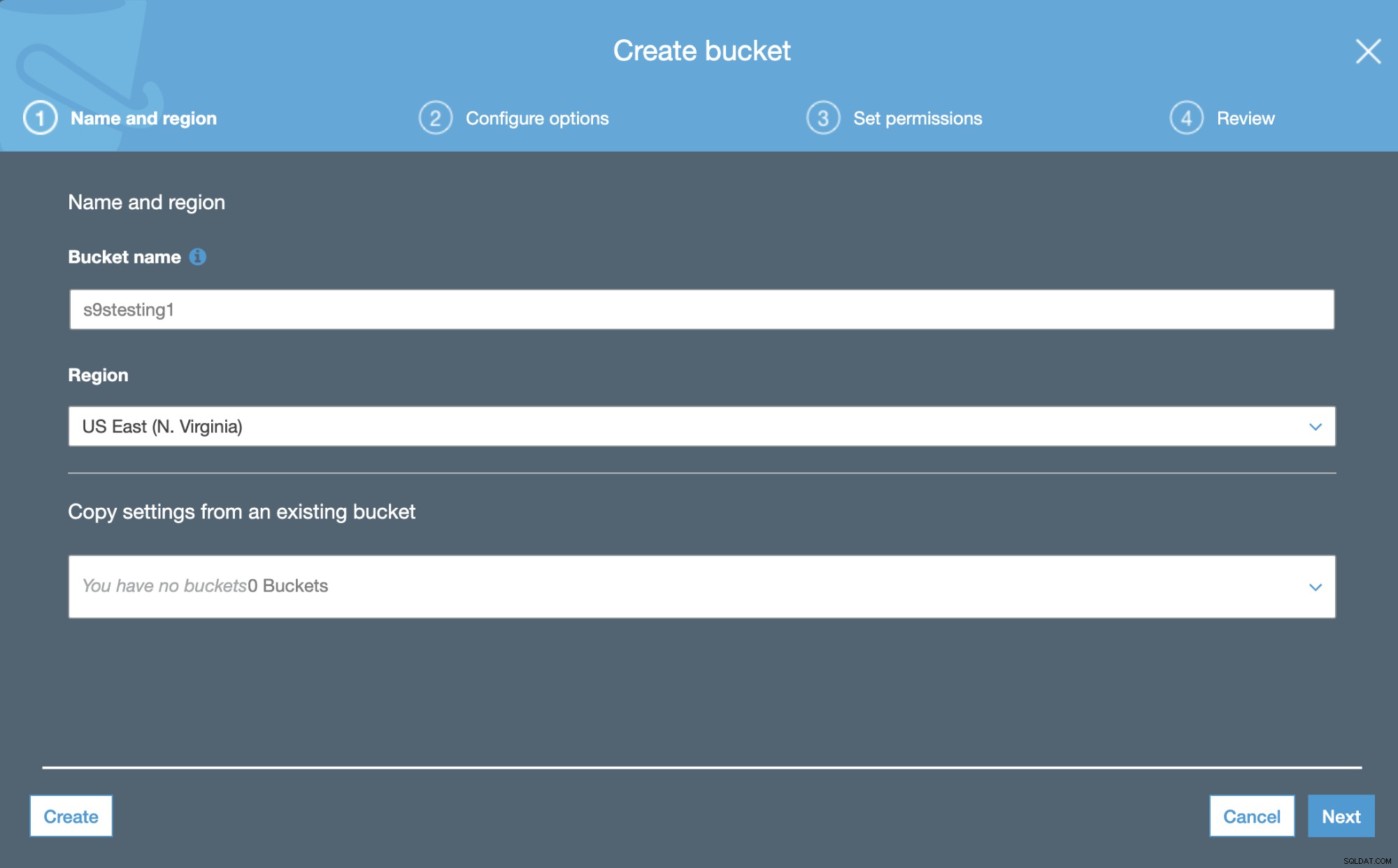
I det første trin skal vi blot tilføje Bucket-navnet og AWS-region.
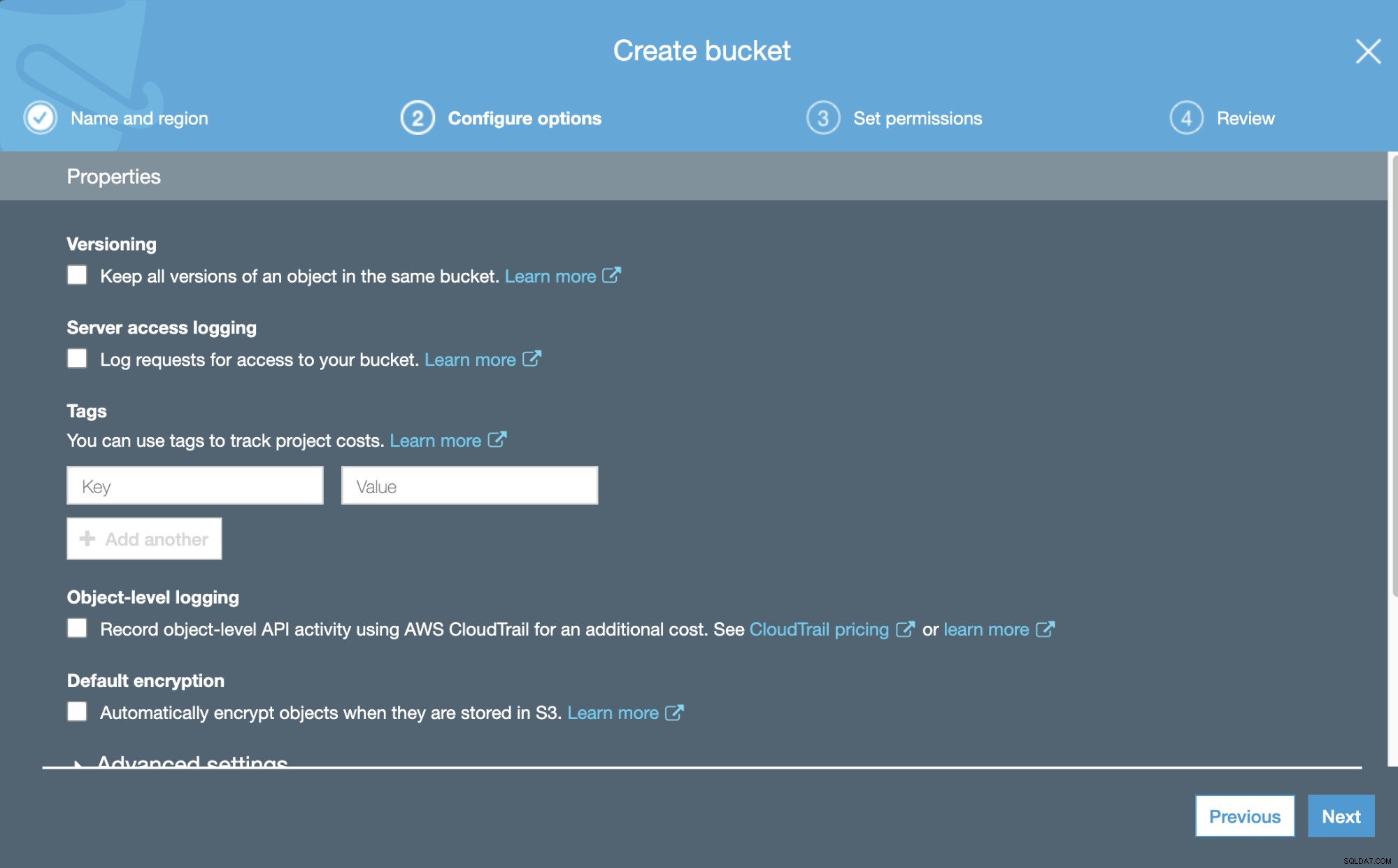
Nu kan vi konfigurere nogle detaljer om vores nye Bucket, såsom versionering og logning.

Og så kan vi angive tilladelserne for denne nye Bucket.
Nu har vi lavet vores Bucket, lad os se, hvordan vi kan bruge den til at gemme vores PostgreSQL-sikkerhedskopier.
Lad os først teste vores klient, der forbinder den til S3.
[example@sqldat.com ~]# aws s3 ls
2019-08-23 19:29:02 s9stesting1Det virker! Med den forrige kommando viser vi de aktuelle Buckets, der er oprettet.
Så nu kan vi bare uploade sikkerhedskopien til S3-tjenesten. Til dette kan vi bruge aws sync eller aws cp kommando.
[example@sqldat.com ~]# aws s3 sync /root/backups/BACKUP-5/ s3://s9stesting1/backups/
upload: backups/BACKUP-5/cmon_backup.metadata to s3://s9stesting1/backups/cmon_backup.metadata
upload: backups/BACKUP-5/cmon_backup.log to s3://s9stesting1/backups/cmon_backup.log
upload: backups/BACKUP-5/base.tar.gz to s3://s9stesting1/backups/base.tar.gz
[example@sqldat.com ~]#
[example@sqldat.com ~]# aws s3 cp /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz s3://s9stesting1/backups/
upload: backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz to s3://s9stesting1/backups/pg_dump_2019-08-23_205919.sql.gz
[example@sqldat.com ~]# Vi kan tjekke Bucket-indholdet fra AWS-webstedet.
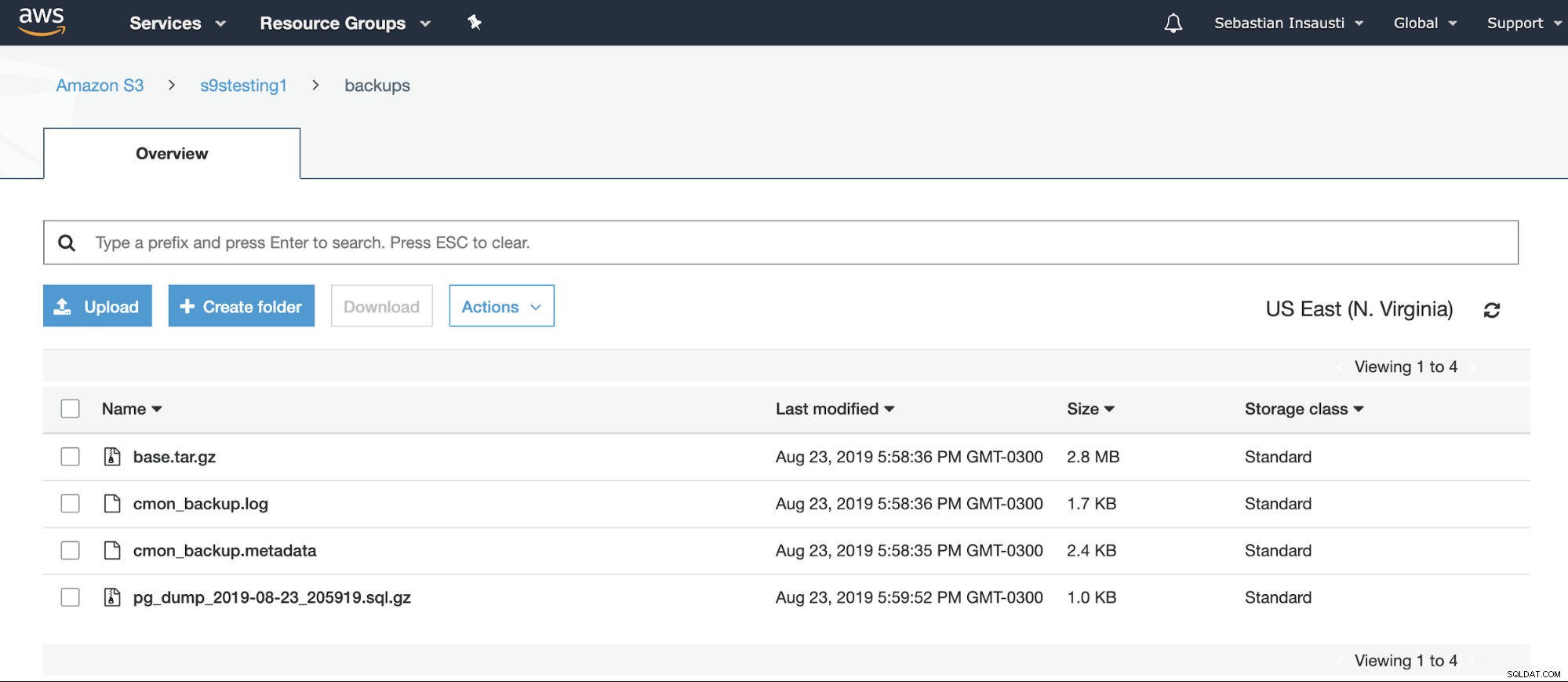
Eller endda ved at bruge AWS CLI.
[example@sqldat.com ~]# aws s3 ls s3://s9stesting1/backups/
2019-08-23 19:29:31 0
2019-08-23 20:58:36 2974633 base.tar.gz
2019-08-23 20:58:36 1742 cmon_backup.log
2019-08-23 20:58:35 2419 cmon_backup.metadata
2019-08-23 20:59:52 1028 pg_dump_2019-08-23_205919.sql.gzFor mere information om AWS S3 CLI, kan du tjekke den officielle AWS-dokumentation.
Amazon S3 Glacier
Dette er den billigere version af Amazon S3. Den største forskel mellem dem er hastighed og tilgængelighed. Du kan bruge Amazon S3 Glacier, hvis lageromkostningerne skal forblive lave, og du ikke har brug for millisekundadgang til dine data. Brug er en anden vigtig forskel mellem dem.
Sådan bruges det
I stedet for Buckets bruger Amazon S3 Glacier Vaults. Det er en beholder til opbevaring af enhver genstand. Så det første skridt er at få adgang til Amazon S3 Glacier Management Console og oprette en ny Vault.
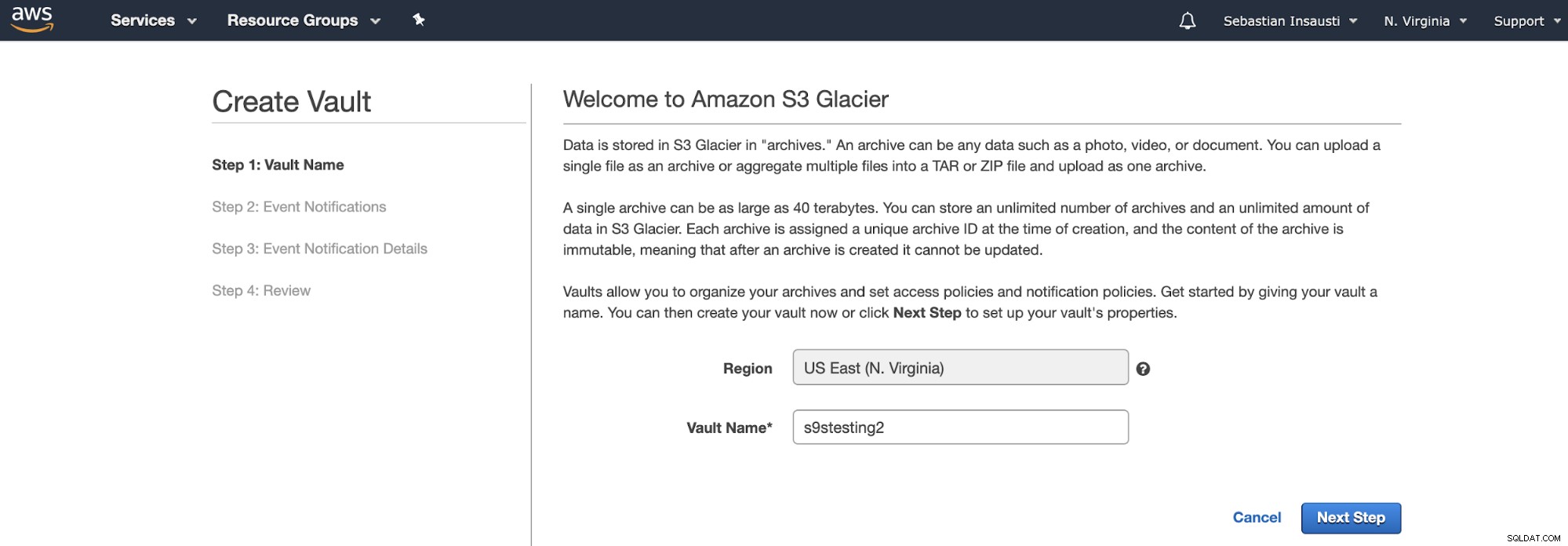
Her skal vi tilføje Vault-navnet og regionen og i det næste trin, vi kan aktivere begivenhedsmeddelelser, der bruger Amazon Simple Notification Service (Amazon SNS).
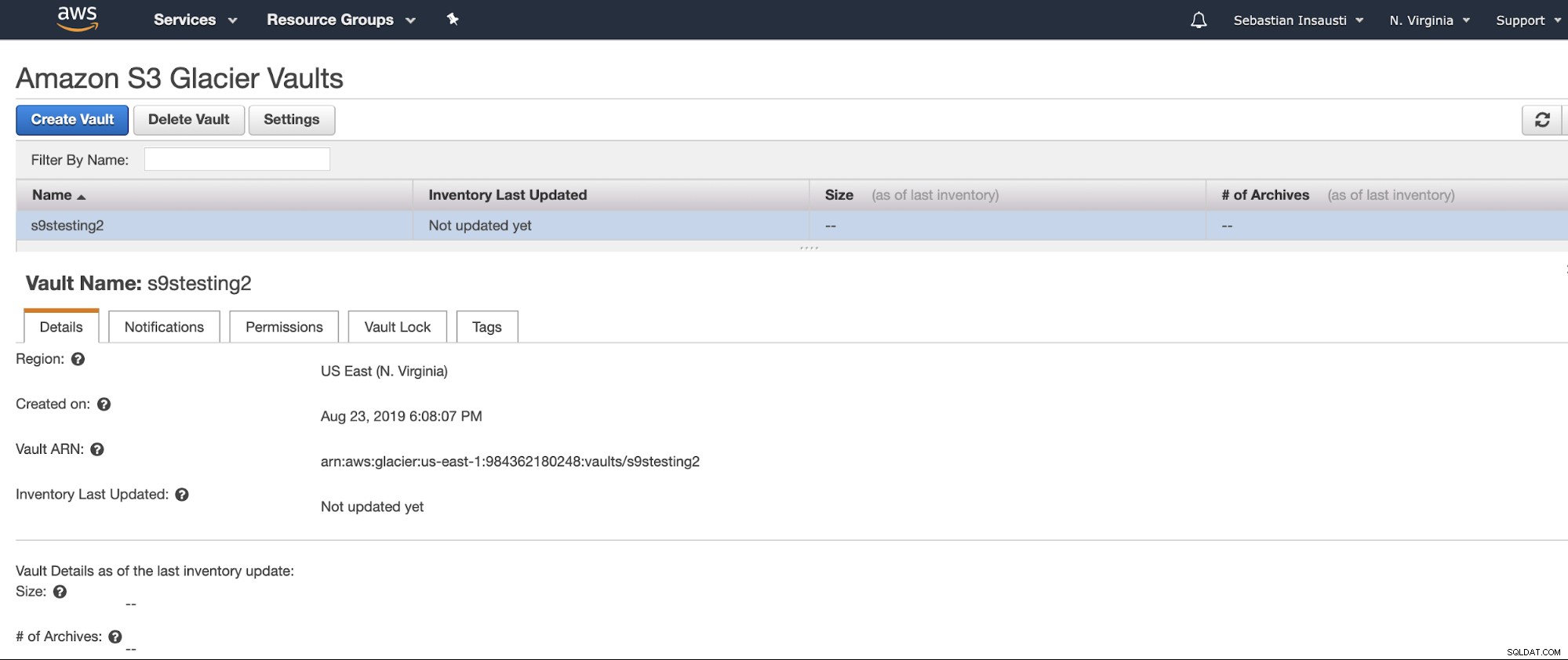
Nu har vi vores Vault oprettet, vi kan få adgang til den fra AWS CLI .
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 0,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"NumberOfArchives": 0,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Det virker. Så nu kan vi uploade vores backup her.
[example@sqldat.com ~]# aws glacier upload-archive --body /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz --account-id - --archive-description "Backup upload test" --vault-name s9stesting2
{
"archiveId": "ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg",
"checksum": "258faaa90b5139cfdd2fb06cb904fe8b0c0f0f80cba9bb6f39f0d7dd2566a9aa",
"location": "/984227183428/vaults/s9stesting2/archives/ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg"
}En vigtig ting er, at Vault-statussen opdateres cirka én gang om dagen, så vi bør vente med at se filen uploadet.
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 33796,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"LastInventoryDate": "2019-08-24T06:37:02.598Z",
"NumberOfArchives": 1,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Her har vi vores fil uploadet til vores S3 Glacier Vault.
For mere information om AWS Glacier CLI, kan du tjekke den officielle AWS-dokumentation.
EC2
Denne mulighed for backuplager er den dyrere og mere tidskrævende, men den er nyttig, hvis du vil have fuld kontrol over backuplagermiljøet og ønsker at udføre tilpassede opgaver på sikkerhedskopierne (f.eks. Backup Verification .)
Amazon EC2 (Elastic Compute Cloud) er en webtjeneste, der giver kapacitet til at tilpasse størrelsen i skyen. Det giver dig fuld kontrol over dine computerressourcer og giver dig mulighed for at opsætte og konfigurere alt om dine instanser fra dit operativsystem til dine applikationer. Det giver dig også mulighed for hurtigt at skalere kapacitet, både op og ned, efterhånden som dine computerkrav ændrer sig.
Amazon EC2 understøtter forskellige operativsystemer som Amazon Linux, Ubuntu, Windows Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Fedora, Debian, CentOS, Gentoo Linux, Oracle Linux og FreeBSD.
Sådan bruges det
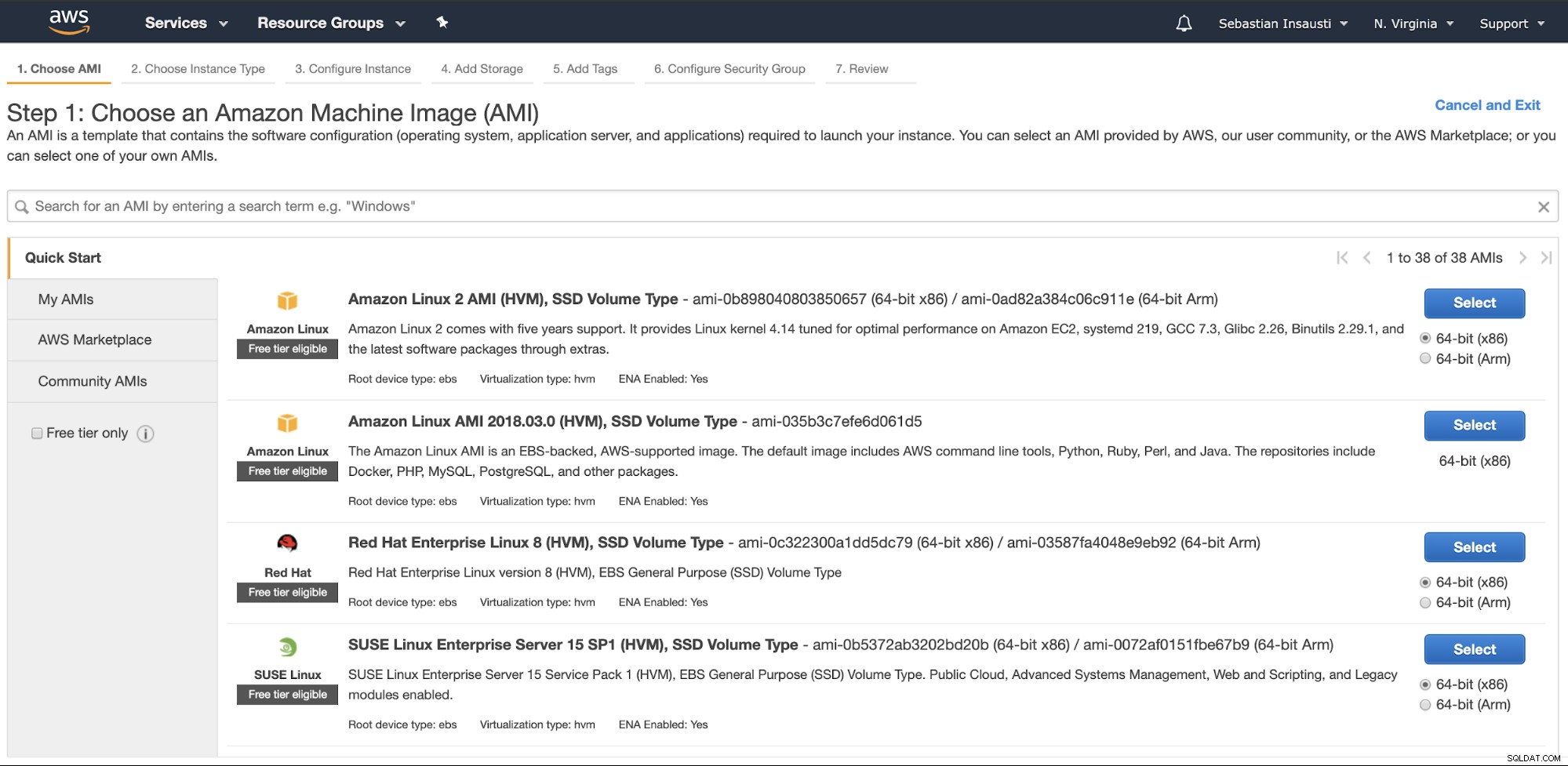
Gå til Amazon EC2-sektionen, og tryk på Launch Instance. I det første trin skal du vælge EC2-instansens operativsystem.
I næste trin skal du vælge ressourcerne til den nye instans.
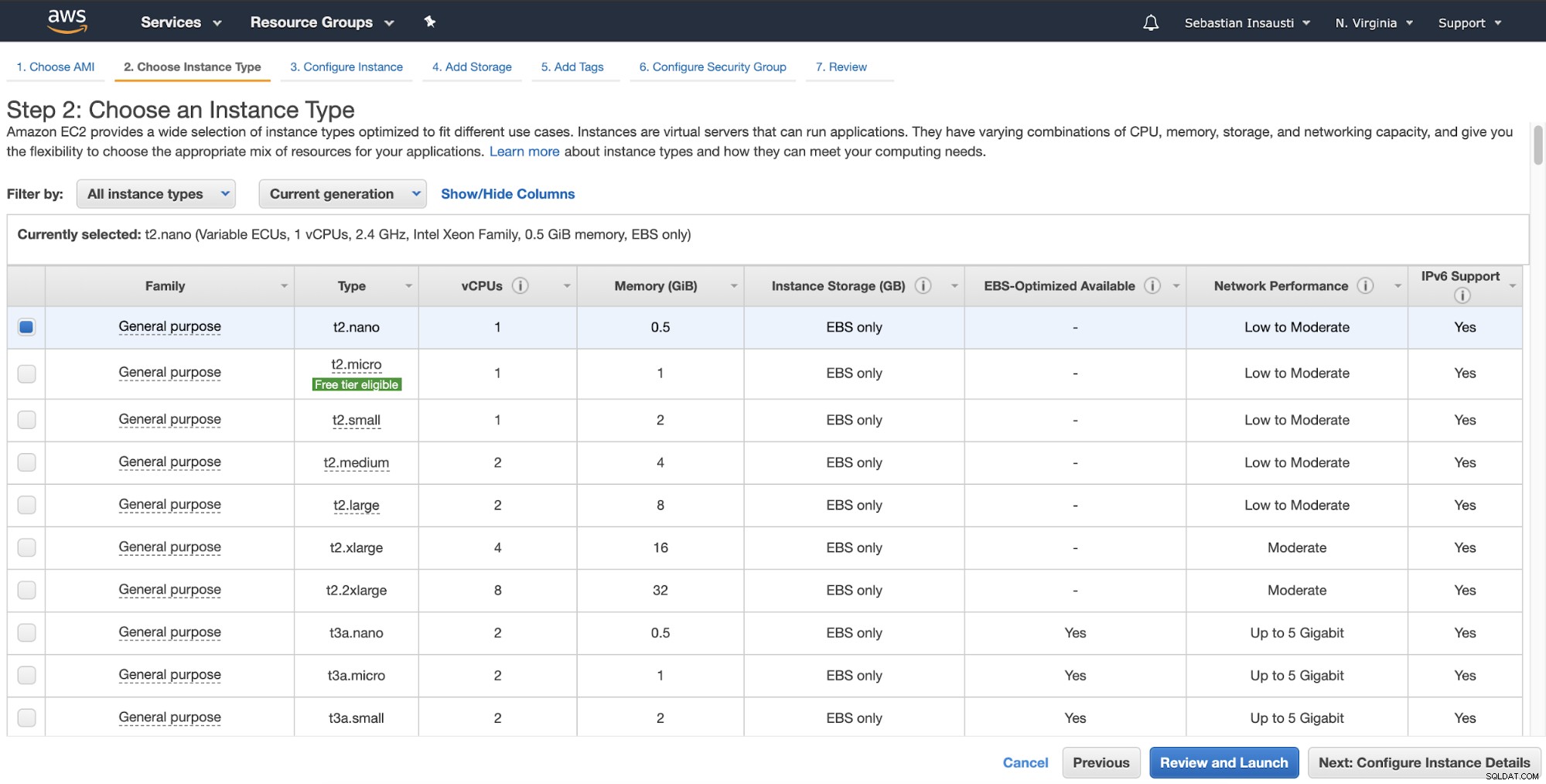
Derefter kan du angive mere detaljeret konfiguration som netværk, undernet og mere .
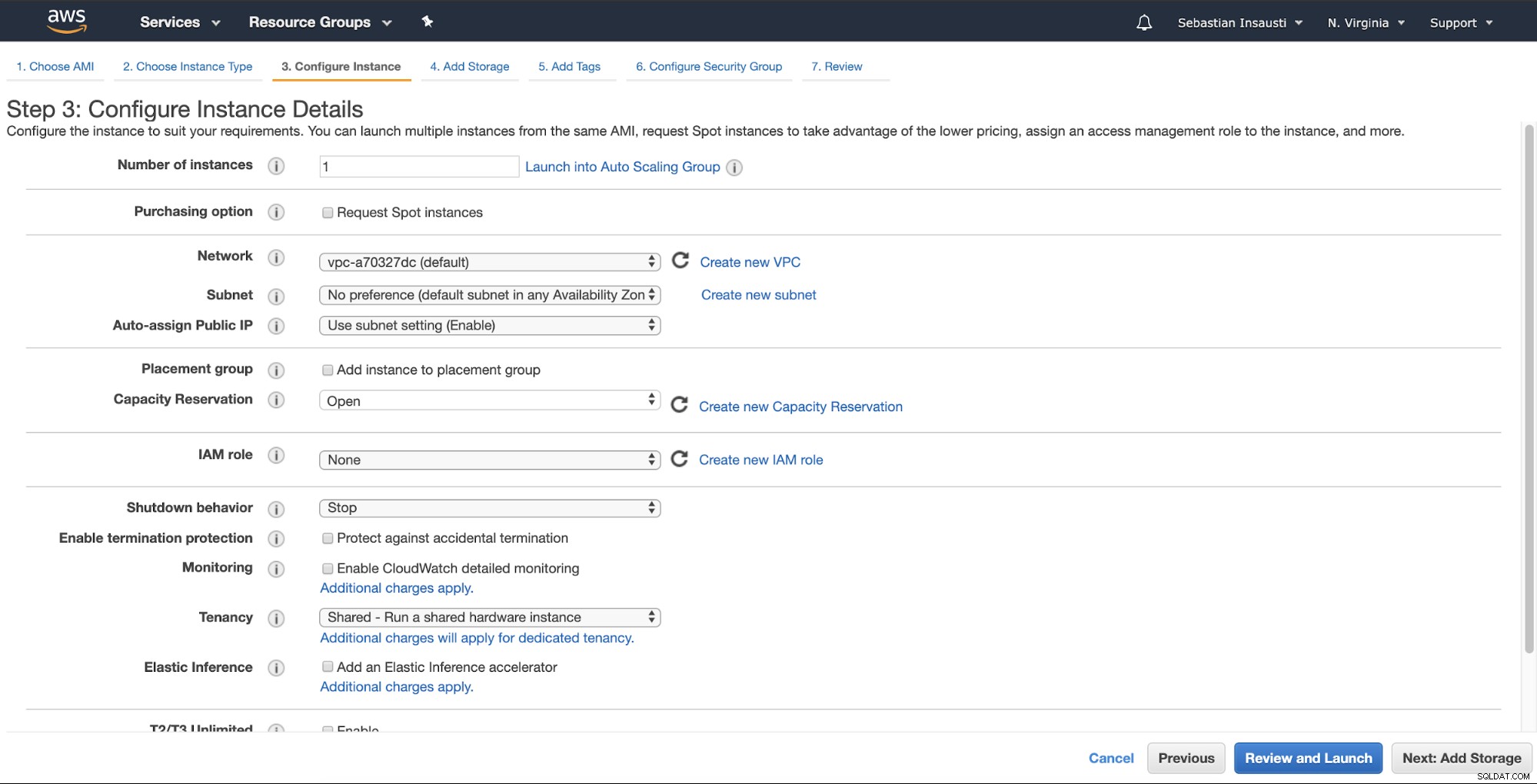
Nu kan vi tilføje mere lagerkapacitet på denne nye instans, og som en backup-server, bør vi gøre det.
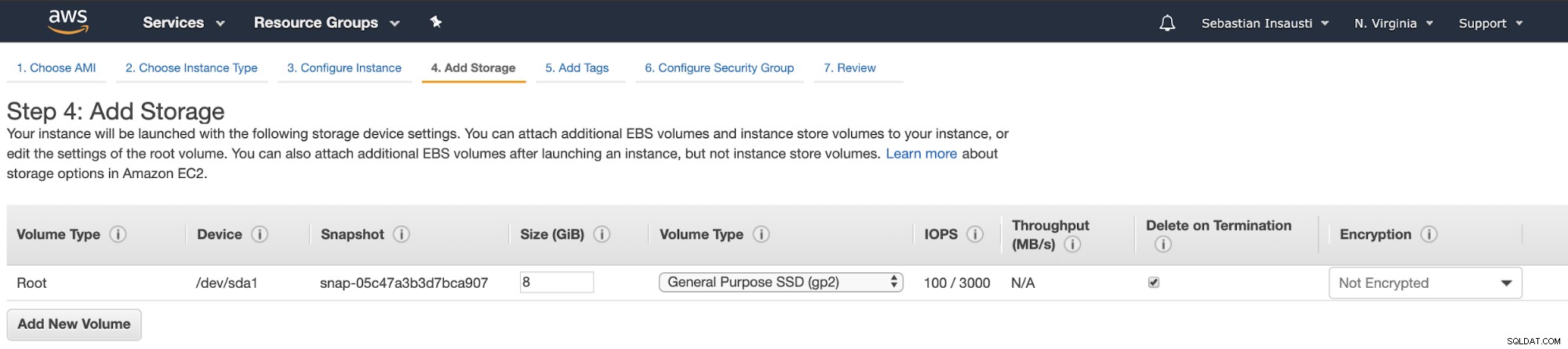
Når vi er færdige med oprettelsesopgaven, kan vi gå til sektionen Forekomster for at se vores nye EC2-instans.
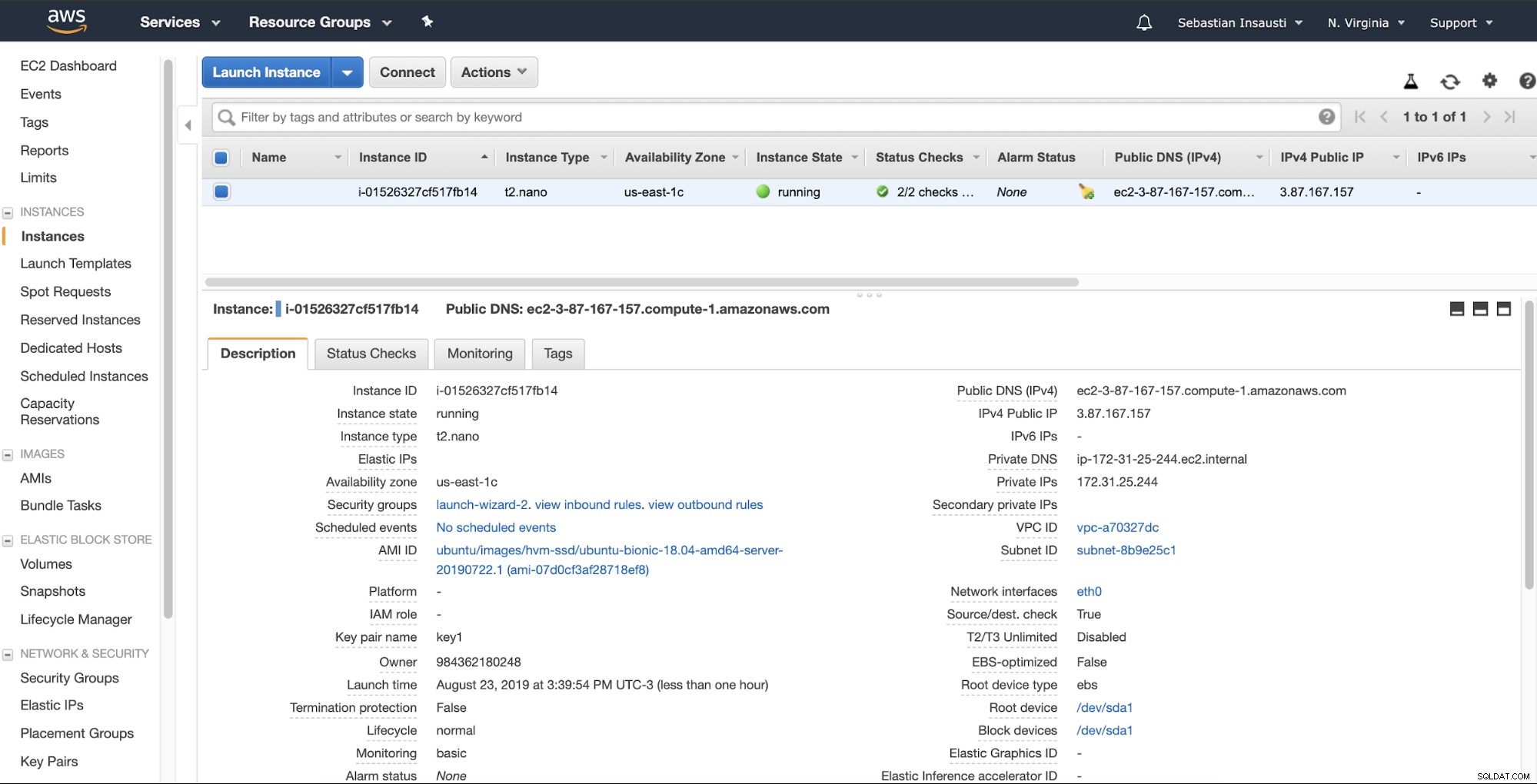
Når forekomsten er klar (forekomsttilstand kører), kan du gemme sikkerhedskopier her, for eksempel ved at sende det via SSH eller FTP ved hjælp af den offentlige DNS oprettet af AWS. Lad os se et eksempel med Rsync og et andet med SCP Linux-kommando.
[example@sqldat.com ~]# rsync -avzP -e "ssh -i /home/user/key1.pem" /root/backups/BACKUP-11/base.tar.gz example@sqldat.com:/backups/20190823/
sending incremental file list
base.tar.gz
4,091,563 100% 2.18MB/s 0:00:01 (xfr#1, to-chk=0/1)
sent 3,735,675 bytes received 35 bytes 574,724.62 bytes/sec
total size is 4,091,563 speedup is 1.10
[example@sqldat.com ~]#
[example@sqldat.com ~]# scp -i /tmp/key1.pem /root/backups/BACKUP-12/pg_dump_2019-08-25_211903.sql.gz example@sqldat.com:/backups/20190823/
pg_dump_2019-08-25_211903.sql.gz 100% 24KB 76.4KB/s 00:00AWS Backup
AWS Backup er en centraliseret backup-tjeneste, der giver dig backup-administrationsfunktioner, såsom backup-planlægning, opbevaringsstyring og backup-overvågning, samt yderligere funktioner, såsom lifecycle backups til en lav pris lagerniveau, sikkerhedskopieringslager og kryptering, der er uafhængigt af dets kildedata og sikkerhedskopieringsadgangspolitikker.
Du kan bruge AWS Backup til at administrere sikkerhedskopier af EBS-volumener, RDS-databaser, DynamoDB-tabeller, EFS-filsystemer og Storage Gateway-volumener.
Sådan bruges det
Gå til afsnittet AWS Backup på AWS Management Console.
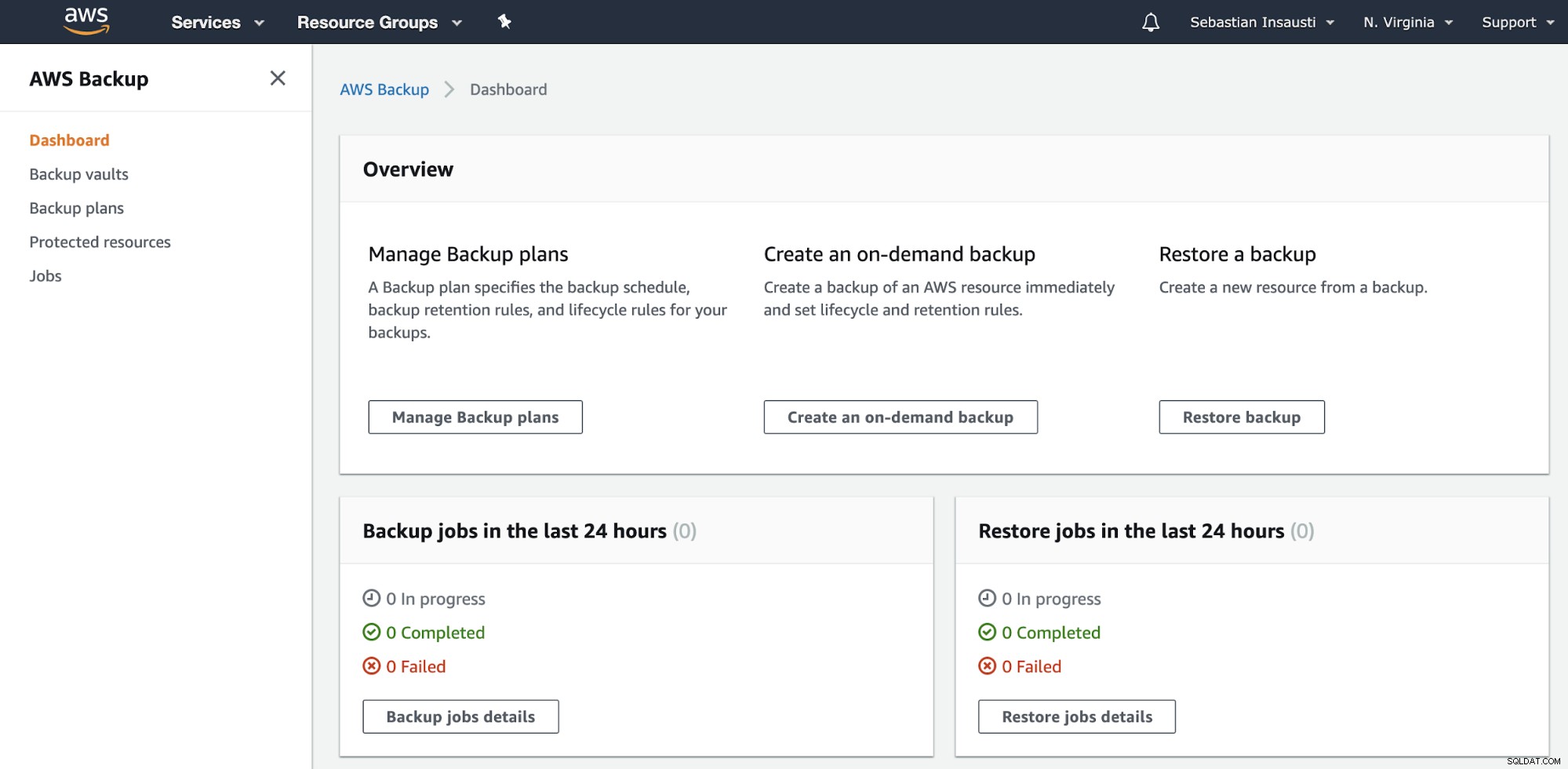
Her har du forskellige muligheder, såsom Planlæg, Opret eller Gendan en sikkerhedskopi . Lad os se, hvordan du opretter en ny sikkerhedskopi.
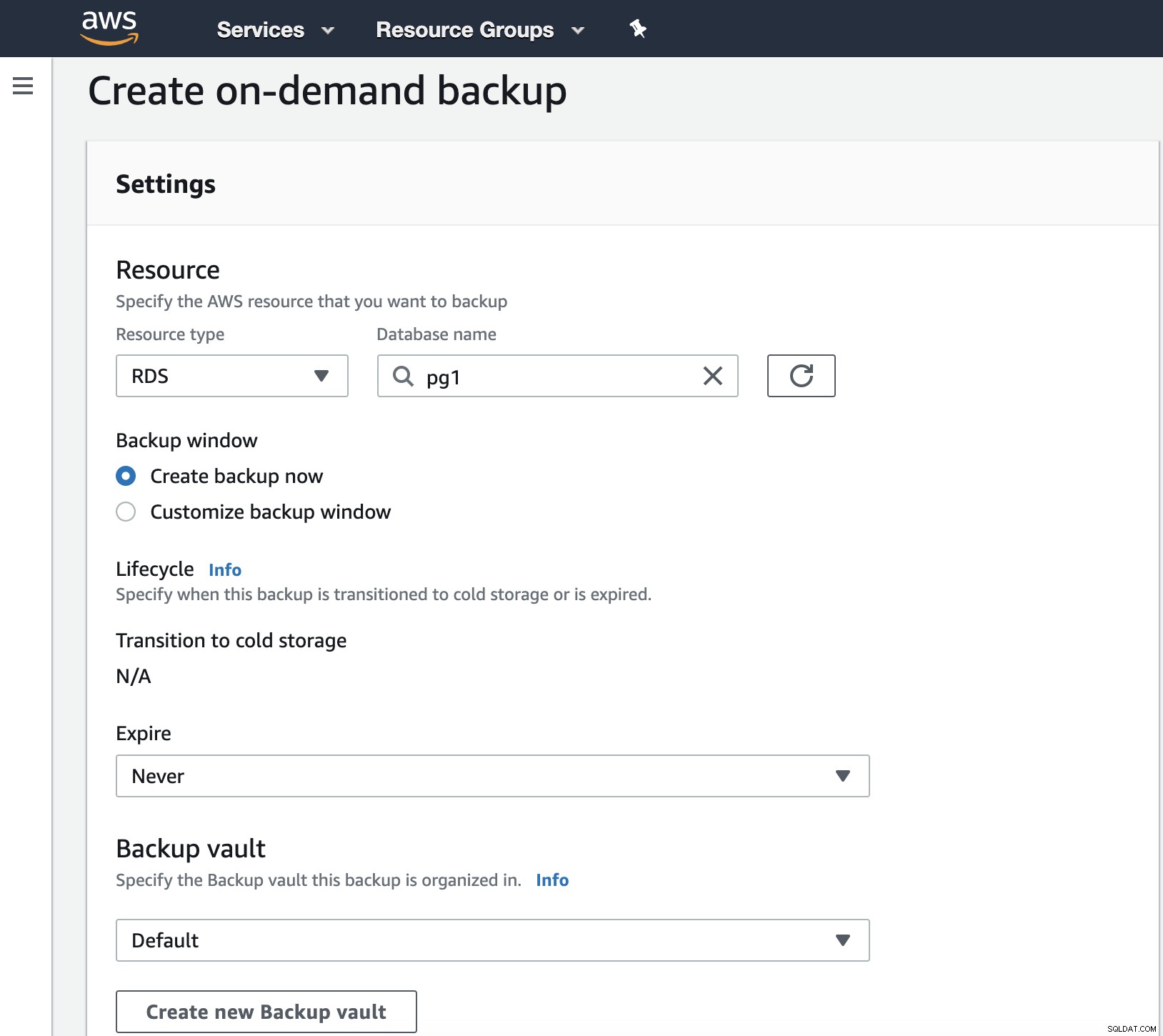
I dette trin skal vi vælge den ressourcetype, der kan være DynamoDB, RDS, EBS, EFS eller Storage Gateway og flere detaljer som udløbsdato, backup-hvælving og IAM-rollen.
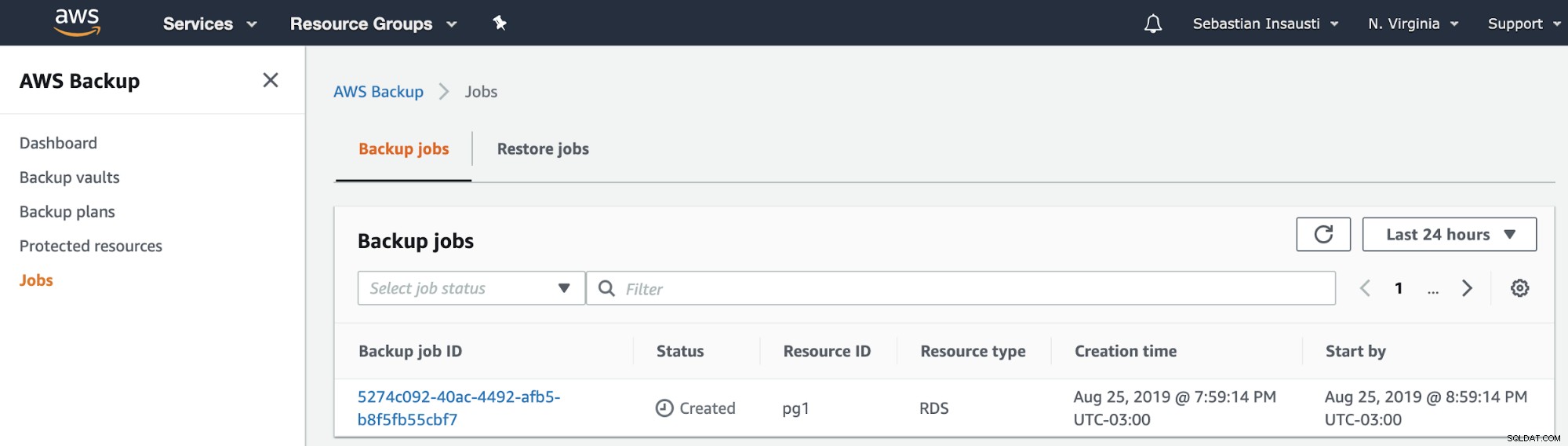
Derefter kan vi se det nye job, der er oprettet i afsnittet AWS Backup Jobs .
Snapshot
Nu kan vi nævne denne kendte mulighed i alle virtualiseringsmiljøer. Snapshottet er en sikkerhedskopi taget på et bestemt tidspunkt, og AWS giver os mulighed for at bruge det til AWS-produkterne. Lad os et eksempel på et RDS-øjebliksbillede.
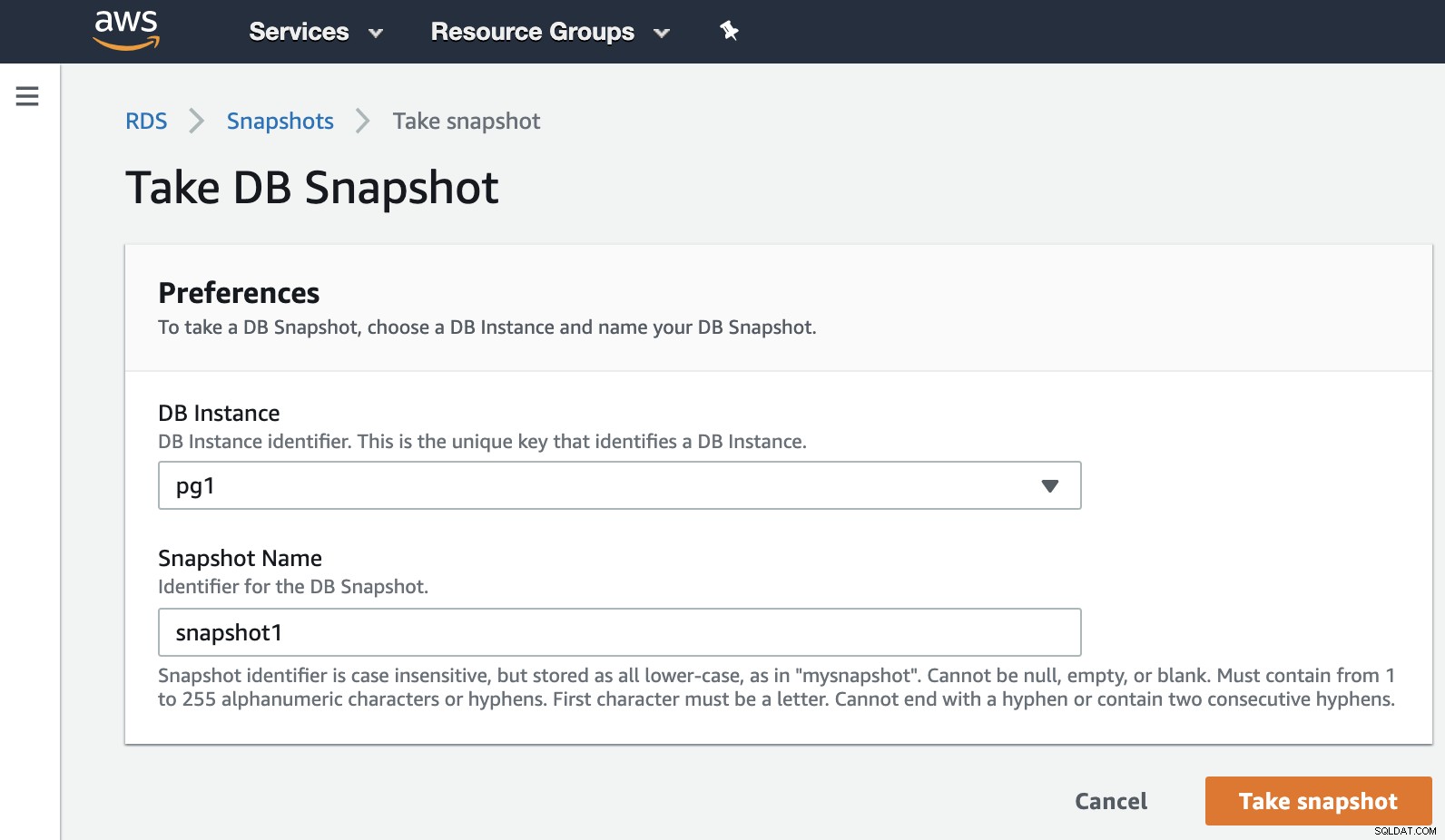
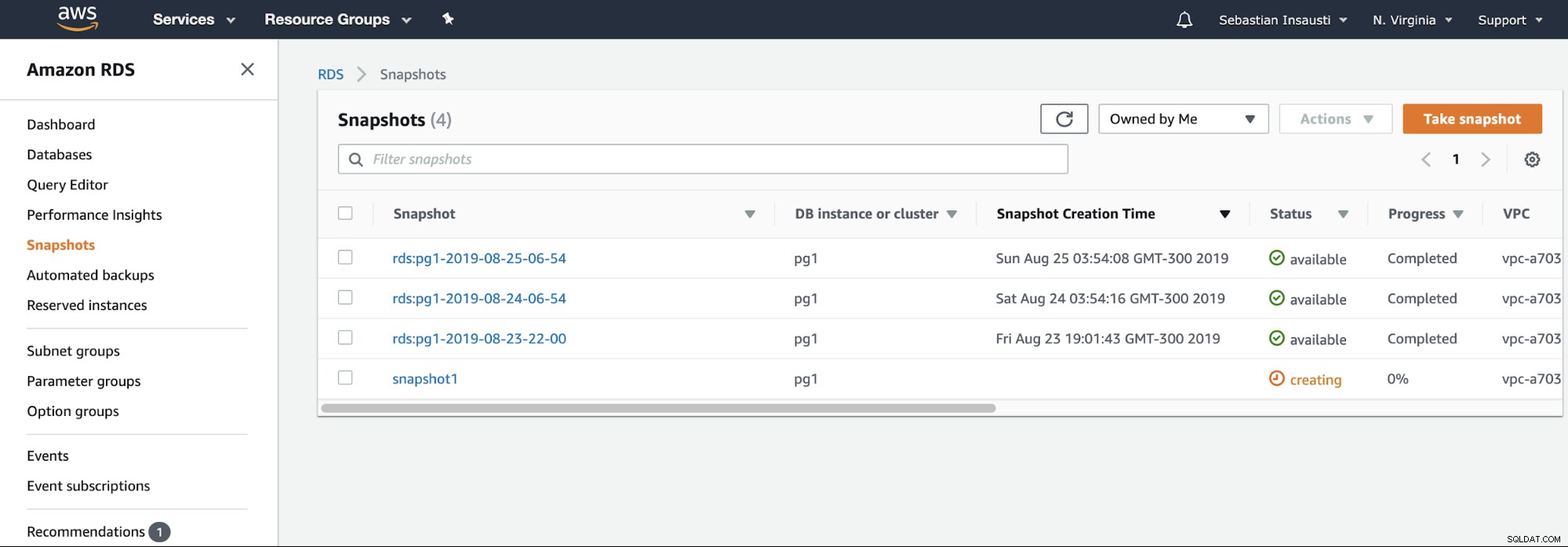
Vi behøver kun at vælge forekomsten og tilføje snapshot-navnet, og det er det. Vi kan se dette og det forrige øjebliksbillede i RDS Snapshot-sektionen.
Administration af dine sikkerhedskopier med ClusterControl
ClusterControl er et omfattende administrationssystem til open source-databaser, der automatiserer implementerings- og administrationsfunktioner samt sundheds- og ydeevneovervågning. ClusterControl understøtter implementering, styring, overvågning og skalering for forskellige databaseteknologier og -miljøer, inklusive EC2. Så vi kan for eksempel oprette vores EC2-instans på AWS og implementere/importere vores databasetjeneste med ClusterControl.

Oprettelse af en sikkerhedskopi
For denne opgave skal du gå til ClusterControl -> Vælg Cluster -> Backup -> Create Backup.
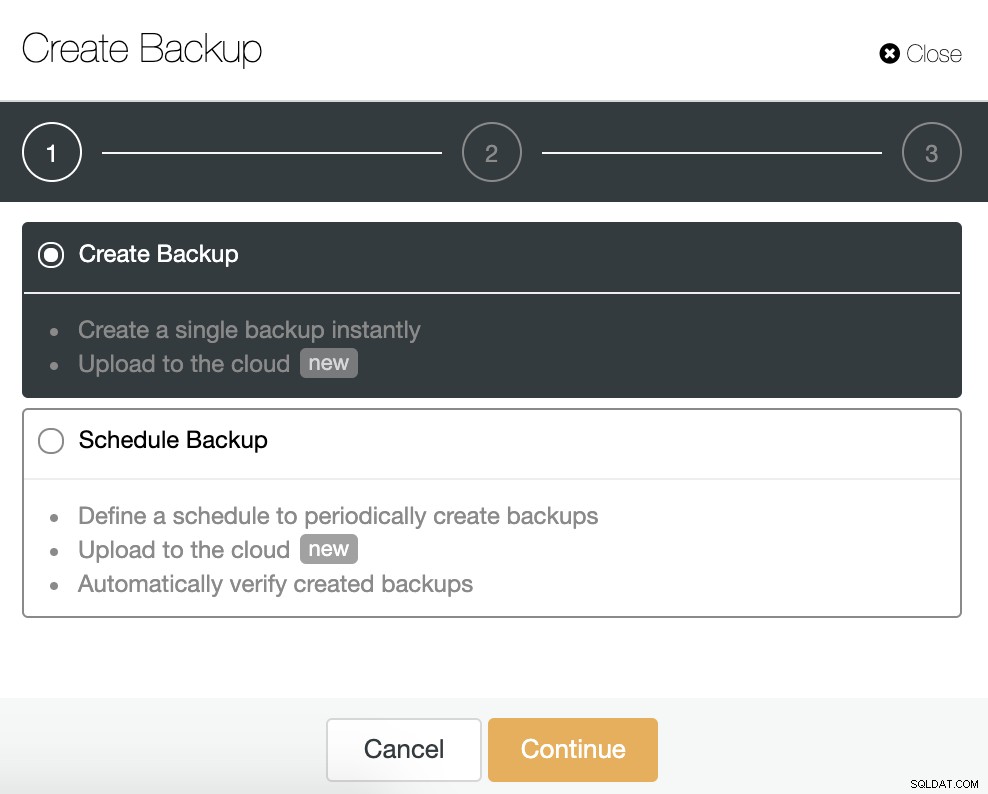
Vi kan oprette en ny sikkerhedskopi eller konfigurere en planlagt. For vores eksempel opretter vi en enkelt sikkerhedskopi med det samme.
Vi skal vælge én metode, den server, hvorfra sikkerhedskopieringen vil blive taget , og hvor vi ønsker at gemme sikkerhedskopien. Vi kan også uploade vores backup til skyen (AWS, Google eller Azure) ved at aktivere den tilsvarende knap.
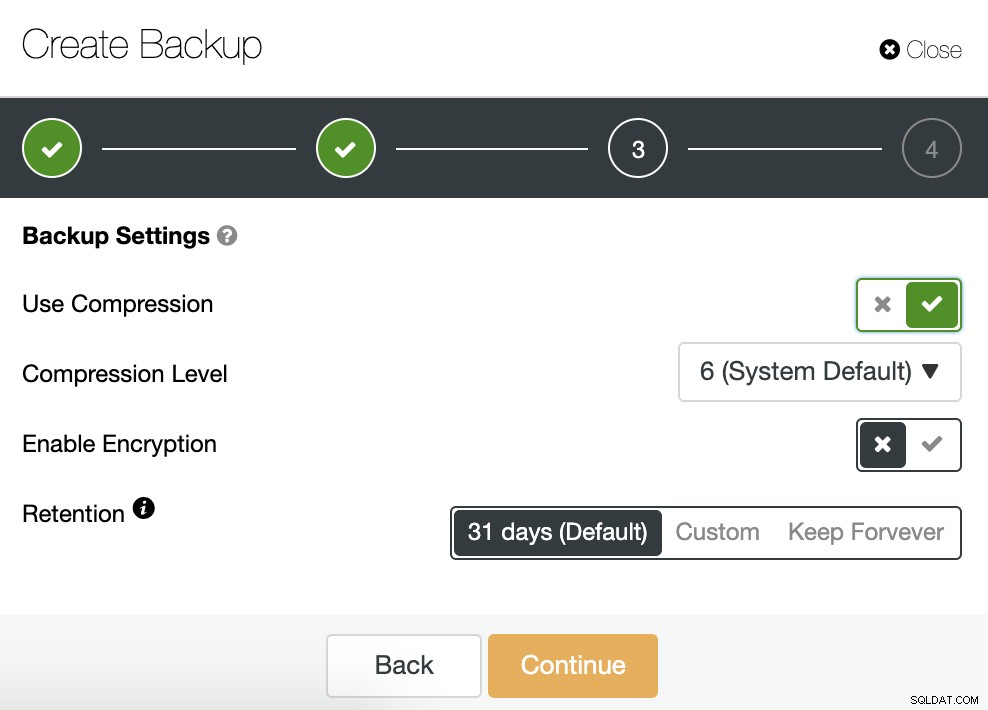
Derefter specificerer vi brugen af komprimering, komprimeringsniveauet, kryptering og opbevaring periode for vores backup.
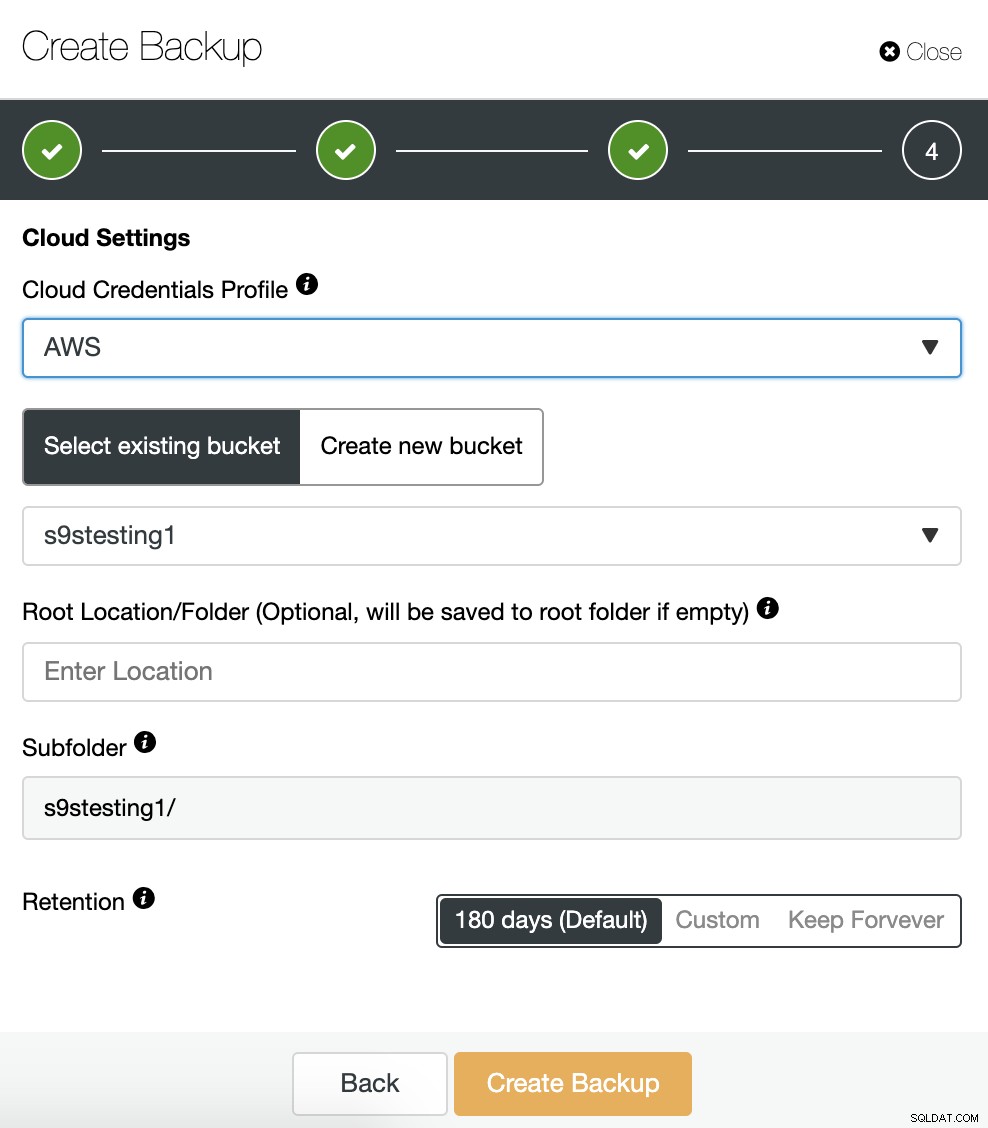
Hvis vi aktiverede muligheden for upload backup til skyen, vil vi se en sektion for at specificere cloud-udbyderen (i dette tilfælde AWS) og legitimationsoplysningerne (ClusterControl -> Integrationer -> Cloud Providers). Til AWS bruger den S3-tjenesten, så vi skal vælge en Bucket eller endda oprette en ny til at gemme vores sikkerhedskopier.
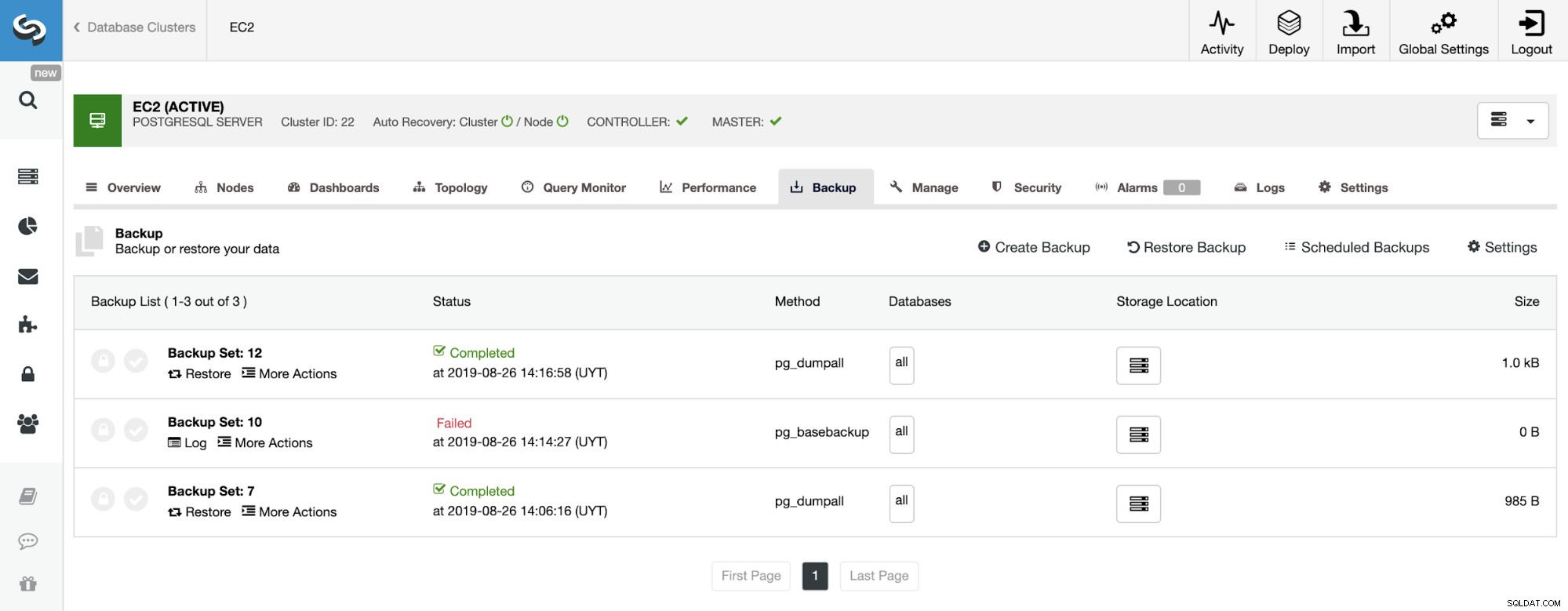
På sikkerhedskopieringssektionen kan vi se sikkerhedskopieringens fremskridt, og oplysninger som metode, størrelse, placering og mere.
Konklusion
Amazon AWS giver os mulighed for at gemme vores PostgreSQL-sikkerhedskopier, uanset om vi bruger det som en databaseskyudbyder eller ej. For at have en effektiv backup-plan bør du overveje at gemme mindst én database-sikkerhedskopi i skyen for at undgå datatab i tilfælde af hardwarefejl i en anden backup-butik. Skyen lader dig gemme så mange sikkerhedskopier, som du vil gemme eller betale for.