Overvågning er en af de grundlæggende opgaver i ethvert system. Det kan hjælpe os med at opdage problemer og handle, eller blot at kende vores systemers aktuelle tilstand. Brug af visuelle skærme kan gøre os mere effektive, da vi nemmere kan opdage ydeevneproblemer.
I denne blog vil vi se, hvordan du bruger SCUMM til at overvåge vores PostgreSQL-databaser, og hvilke målinger vi kan bruge til denne opgave. Vi vil også gennemgå de tilgængelige dashboards, så du nemt kan finde ud af, hvad der virkelig sker med dine PostgreSQL-instanser.
Hvad er SCUMM?
Lad os først og fremmest se, hvad der er SCUMM (Severalnines ClusterControl Unified Monitoring and Management).
Det er en ny agentbaseret løsning med agenter installeret på databasenoderne.
SCUMM-agenterne er Prometheus-eksportører, der eksporterer metrics fra tjenester som PostgreSQL som Prometheus-metrics.
En Prometheus-server bruges til at skrabe og gemme tidsseriedata fra SCUMM-agenterne.
Prometheus er et open source-systemovervågnings- og alarmeringsværktøj, der oprindeligt blev bygget hos SoundCloud. Det er nu et selvstændigt open source-projekt og vedligeholdes uafhængigt.
Prometheus er designet til pålidelighed, for at være det system, du går til under en strømafbrydelse, så du hurtigt kan diagnosticere problemer.
Hvordan bruger man SCUMM?
Når vi bruger ClusterControl, når vi vælger en klynge, kan vi se en oversigt over vores databaser, samt nogle grundlæggende metrics, der kan bruges til at identificere et problem. I nedenstående dashboard kan vi se en master-slave-opsætning med en master og 2 slaver med HAProxy og Keepalved.
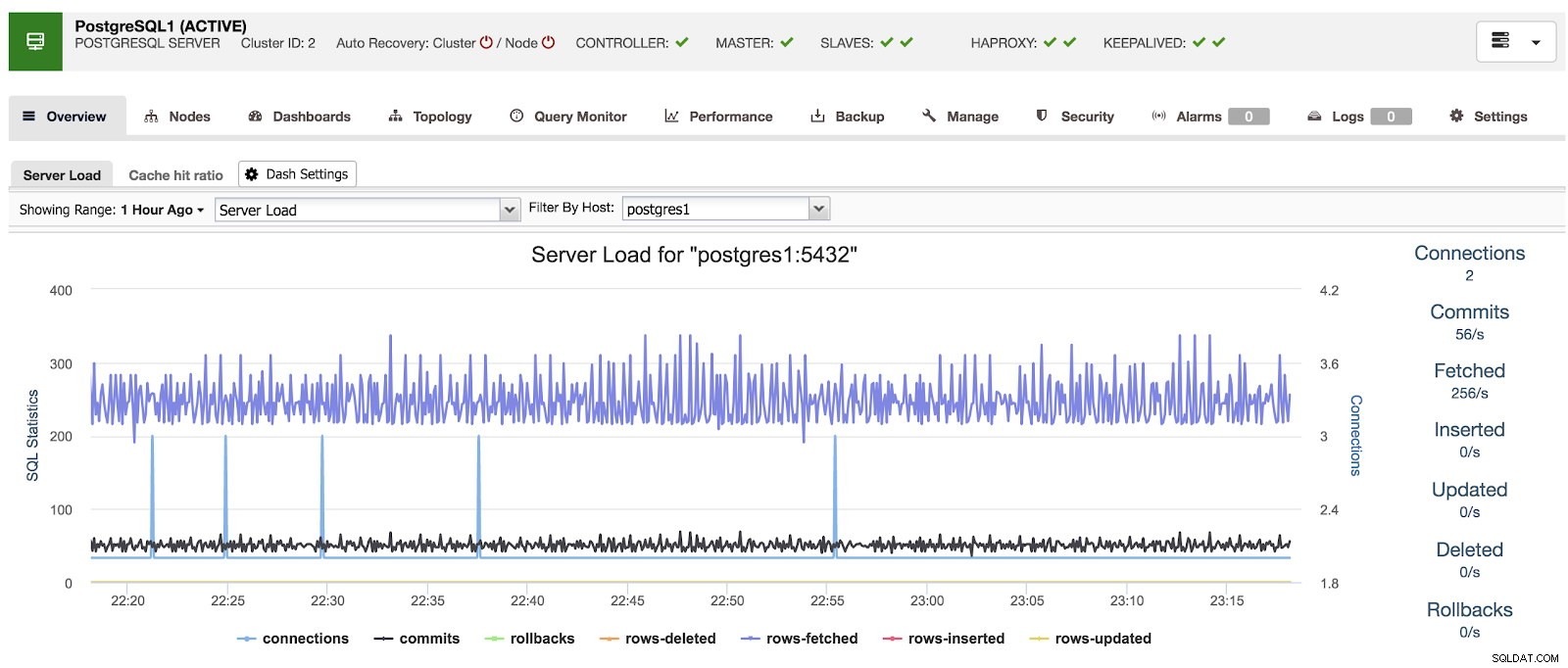 ClusterControl Oversigt
ClusterControl Oversigt Hvis vi går til "Dashboards", kan vi se en meddelelse som følgende.
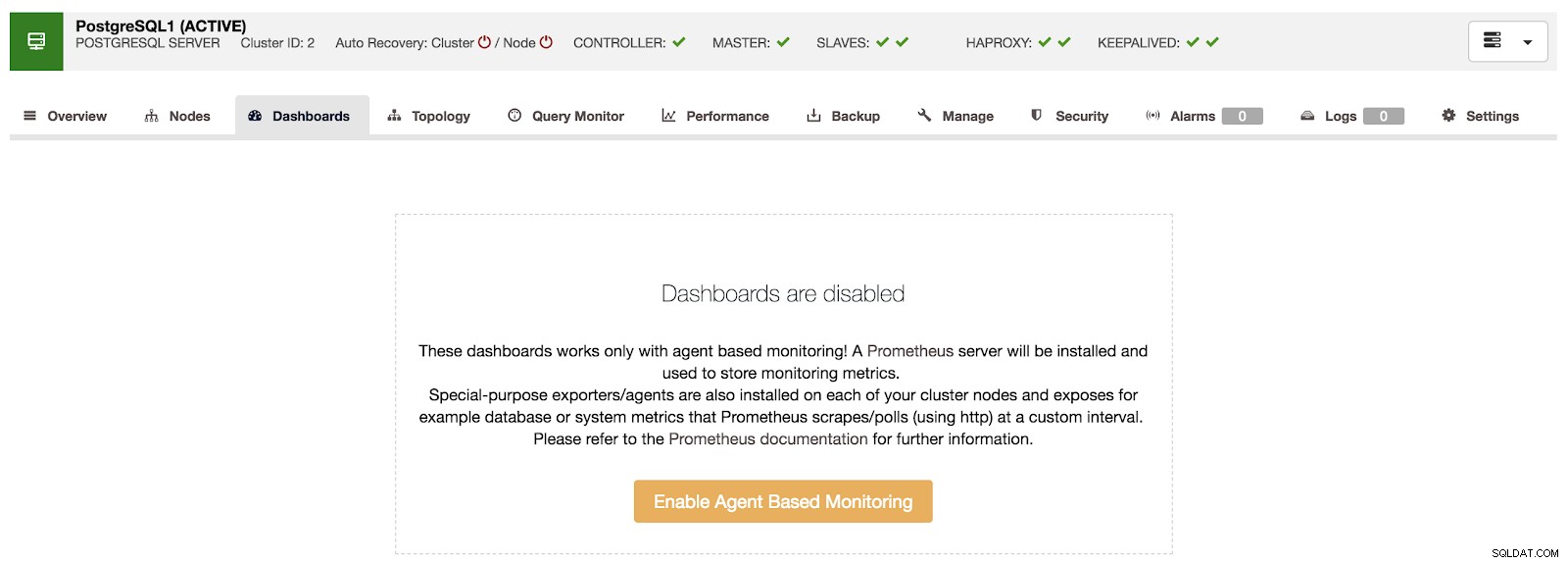 ClusterControl Dashboards deaktiveret
ClusterControl Dashboards deaktiveret For at bruge denne funktion skal vi aktivere agenten nævnt ovenfor. Til dette skal vi kun trykke på knappen "Aktiver agentbaseret overvågning" i dette afsnit.
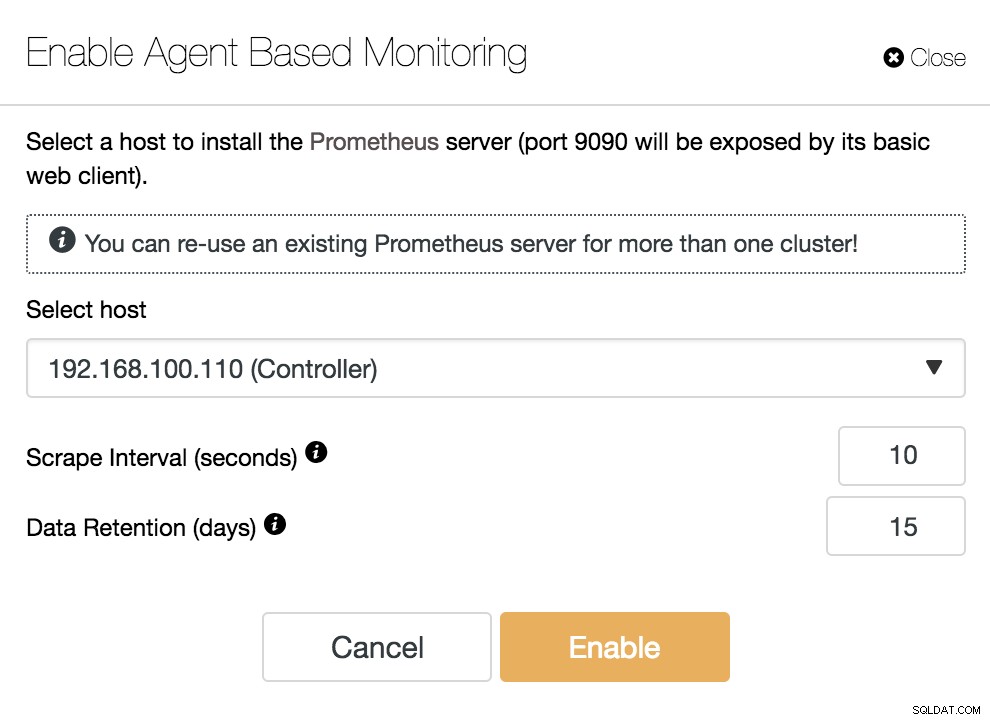 ClusterControl Aktiver agentbaseret overvågning
ClusterControl Aktiver agentbaseret overvågning For at aktivere vores agent skal vi angive værten, hvor vi vil installere vores Prometheus-server, som, som vi kan se i eksemplet, kan være vores ClusterControl-server.
Vi skal også specificere:
- Scrape-interval (sekunder):Indstil, hvor ofte noderne skal skrabes for metrics. Standard er 10 sekunder.
- Dataopbevaring (dage):Indstil, hvor længe metrics opbevares, før de fjernes. Standard er 15 dage.
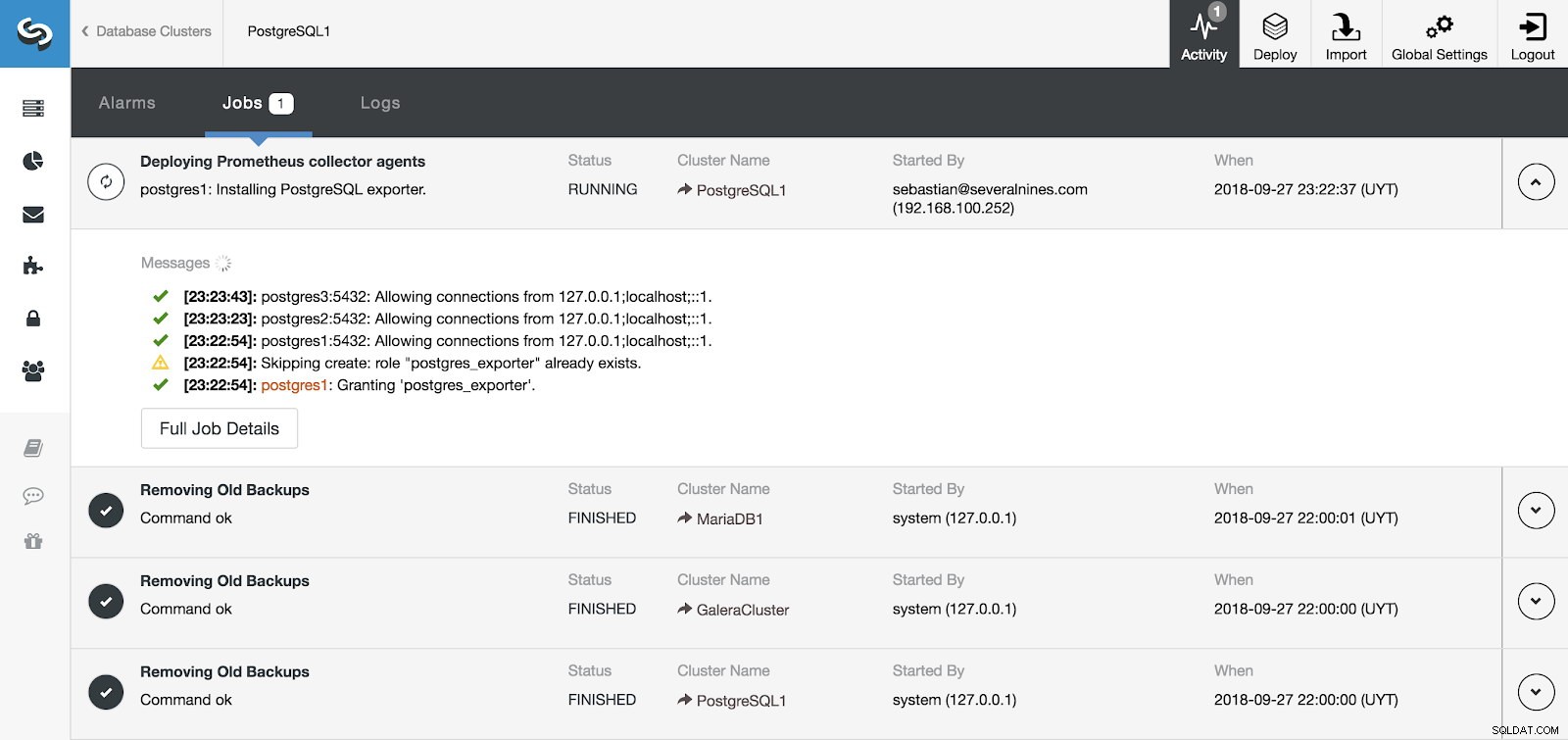 ClusterControl Activity Section
ClusterControl Activity Section Vi kan overvåge installationen af vores server og agenter fra aktivitetssektionen i ClusterControl, og når den er færdig, kan vi se vores klynge med agenterne aktiveret fra hovedskærmen for ClusterControl.
 ClusterControl Agents aktiveret
ClusterControl Agents aktiveret Dashboards
Når vores agenter er aktiveret, vil vi se noget som dette, hvis vi går til sektionen Dashboards:
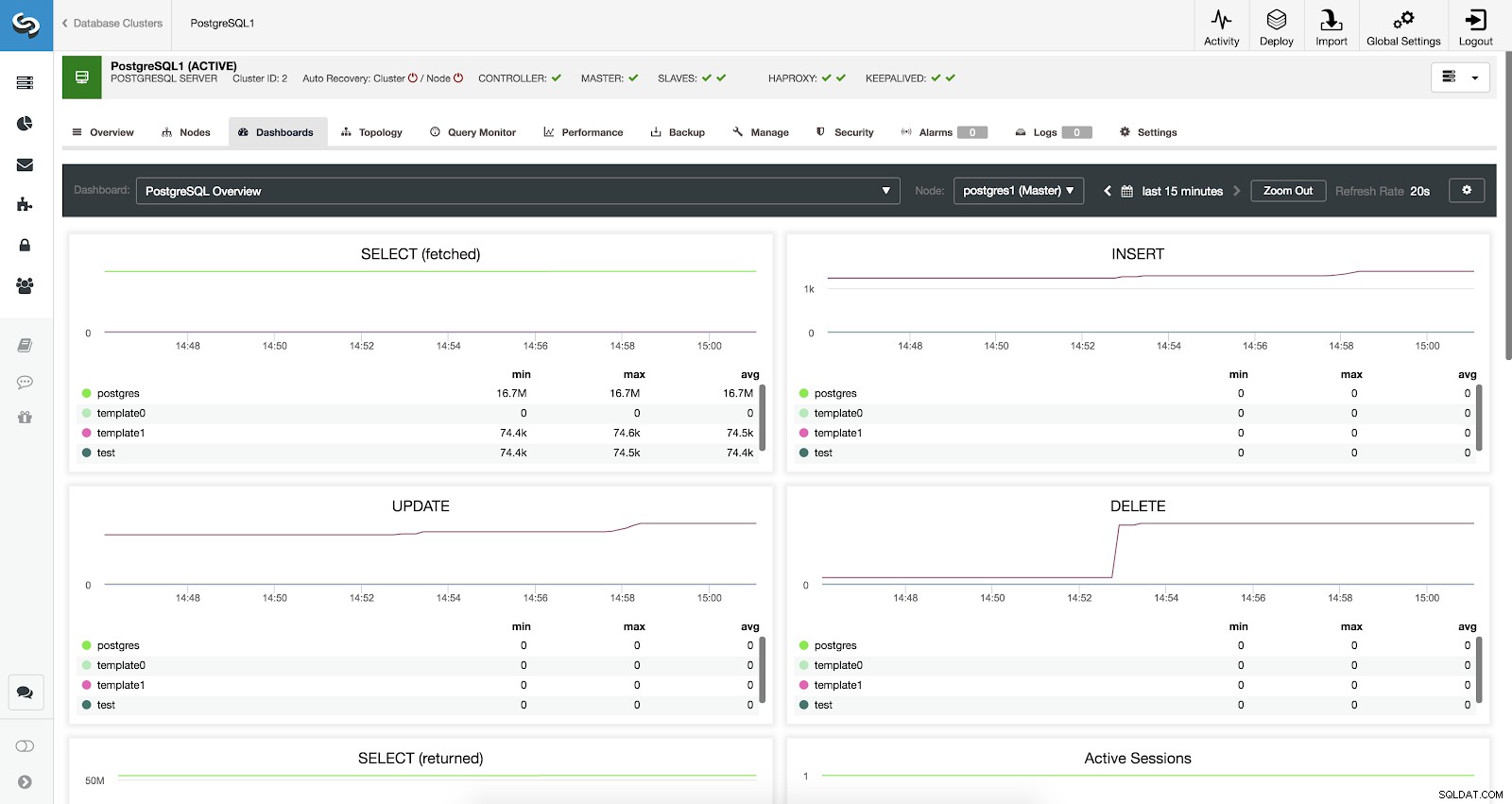 ClusterControl Dashboards aktiveret
ClusterControl Dashboards aktiveret Vi har tre forskellige slags dashboards tilgængelige, System Overview, Cross Server Graphs og PostgreSQL Overview. Den sidste er, hvad vi ser som standard, når vi går ind i denne sektion.
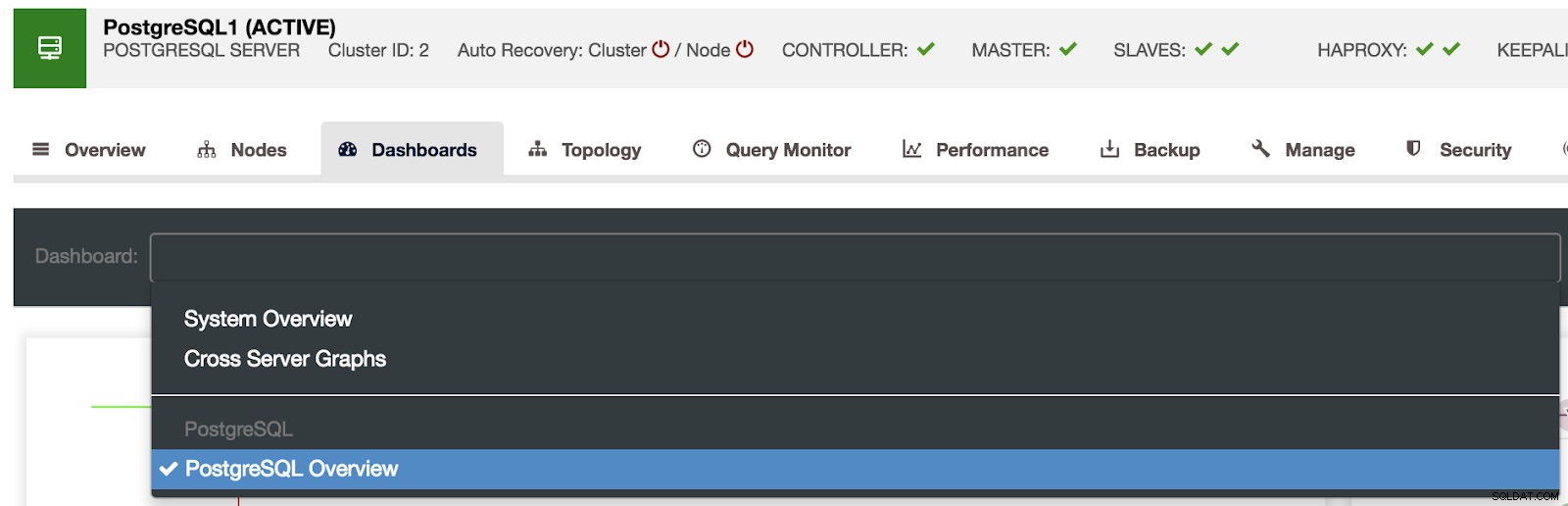 Valg af ClusterControl Dashboards
Valg af ClusterControl Dashboards Her kan vi også angive, hvilken node der skal overvåges, tidsintervallet og opdateringshastigheden.
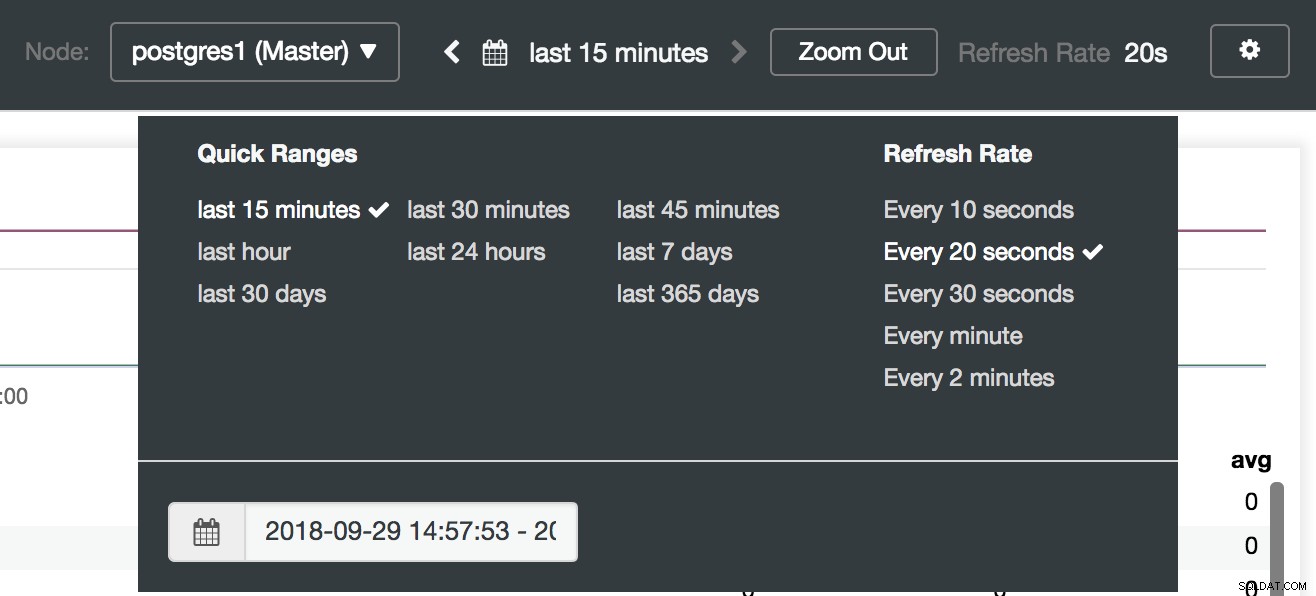 Indstillinger for ClusterControl Dashboard
Indstillinger for ClusterControl Dashboard I konfigurationssektionen kan vi aktivere eller deaktivere vores agenter (eksportører), kontrollere agentstatus og verificere versionen af vores Prometheus-server.
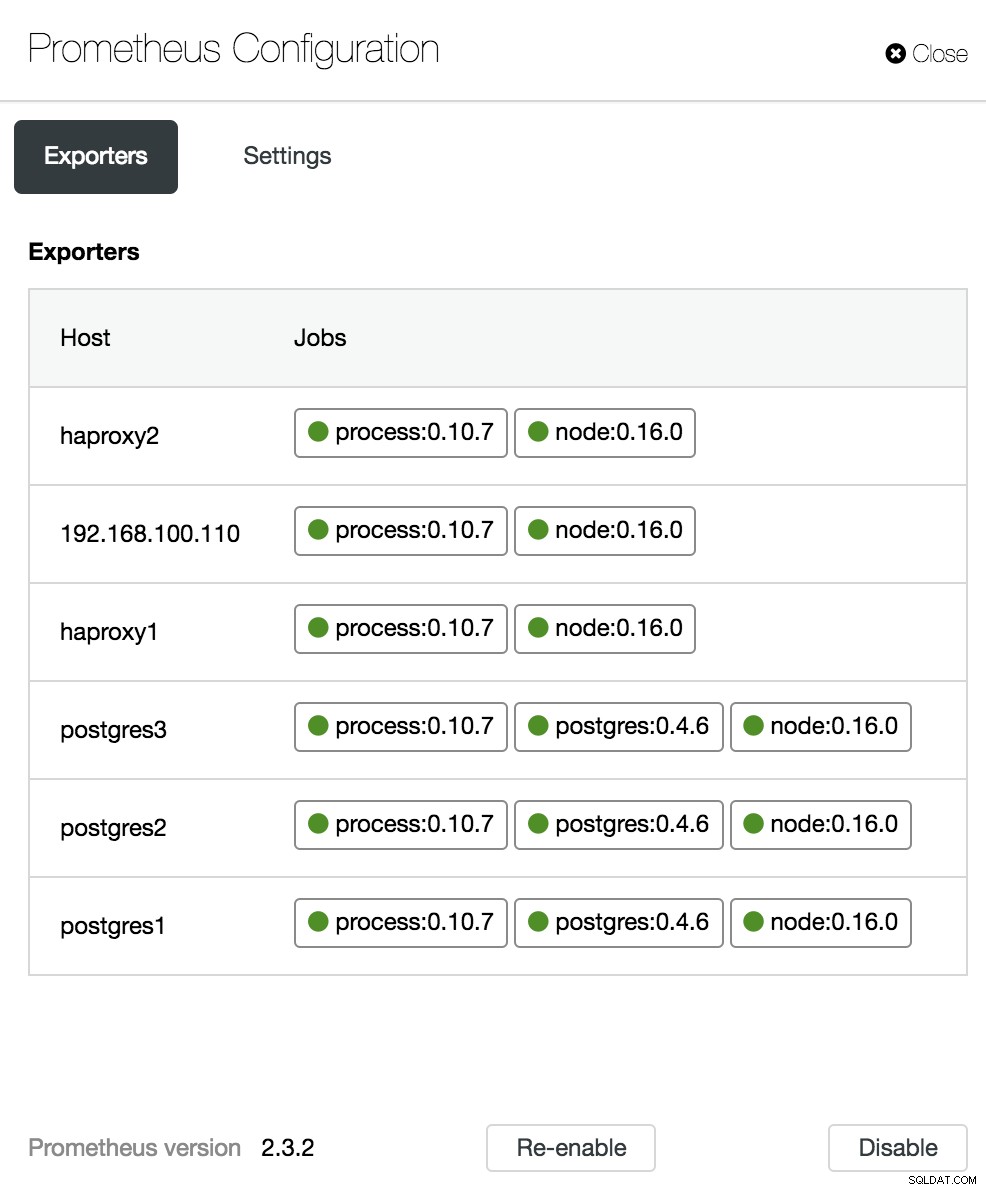 Konfiguration af ClusterControl Dashboard
Konfiguration af ClusterControl Dashboard PostgreSQL-oversigtsmålinger
Lad os nu se, hvilke metrics vi har tilgængelige for hver af vores PostgreSQL-databaser (alle for den valgte node).
- VÆLG (hentet):Antal valgte rækker (hentet) for hver database. De hentede rækker refererer til live rækker hentet fra tabellen.
- VÆLG (returneret):Antal valgte rækker (returneret) for hver database. De returnerede rækker refererer til alle rækker, der er læst fra tabellen, som inkluderer døde rækker og endnu ikke-forpligtede rækker (i modsætning til de hentede rækker, der kun tæller de levende tupler).
- INDSÆT:Antal rækker, der er indsat for hver database.
- OPDATERING:Antal rækker opdateret for hver database.
- SLET:Antal slettede rækker for hver database.
- Aktive sessioner:Antal aktive sessioner (min., maks. og gennemsnit) for hver database.
- Inaktive sessioner:Antal inaktive sessioner (min., maks. og gennemsnit) for hver database.
- Låsetabeller:Antal låse (min, maks og gennemsnit) adskilt efter type for hver database.
- Disk IO-anvendelse:Serverdisk IO-anvendelse.
- Diskforbrug:Procentvis brug af serverdisk (min, maks og gennemsnit).
- Diskforsinkelse:Serverens diskforsinkelse.
ClusterControl PostgreSQL-oversigtsmålinger Systemoversigts-metrics
For at overvåge vores system har vi følgende metrics til rådighed for hver server (alle for den valgte node):
- Systemoppetid:Tid siden serveren er oppe.
- CPU'er:Antal CPU'er.
- RAM:Mængden af RAM-hukommelse.
- Hukommelse tilgængelig:Procentdel af tilgængelig RAM-hukommelse.
- Belastningsgennemsnit:Min., maks. og gennemsnitlig serverbelastning.
- Hukommelse:Tilgængelig, samlet og brugt serverhukommelse.
- CPU-brug:Min., maks. og gennemsnitlig server-CPU-brug.
- Hukommelsesdistribution:Hukommelsesfordeling (buffer, cache, gratis og brugt) på den valgte node.
- Mætningsmålinger:Min., maks. og gennemsnit af IO-belastning og CPU-belastning på den valgte node.
- Memory Advanced Details:Hukommelsesbrugsdetaljer som sider, buffer og mere på den valgte node.
- Gafler:Mængden af gaffelprocesser. Fork er en operation, hvorved en proces skaber en kopi af sig selv. Det er normalt et systemkald, implementeret i kernen.
- Processer:Mængden af processer, der kører eller venter på operativsystemet.
- Kontekstskift:Et kontekstskift er handlingen til at gemme tilstanden af en proces eller en tråd.
- Afbrydelser:Mængden af afbrydelser. En interrupt er en hændelse, der ændrer det normale udførelsesflow for et program og kan genereres af hardwareenheder eller endda af CPU'en selv.
- Netværkstrafik:Indgående og udgående netværkstrafik i KBytes pr. sekund på den valgte node.
- Netværksbrug pr. time:Trafik sendt og modtaget inden for det sidste døgn.
- Swap:Skift brug (gratis og brugt) på den valgte node.
- Swap-aktivitet:Læser og skriver data om swap.
- I/O-aktivitet:Blad ind og blad ud på IO.
- Filbeskrivelser:Tildelte og begrænsede filbeskrivelser.
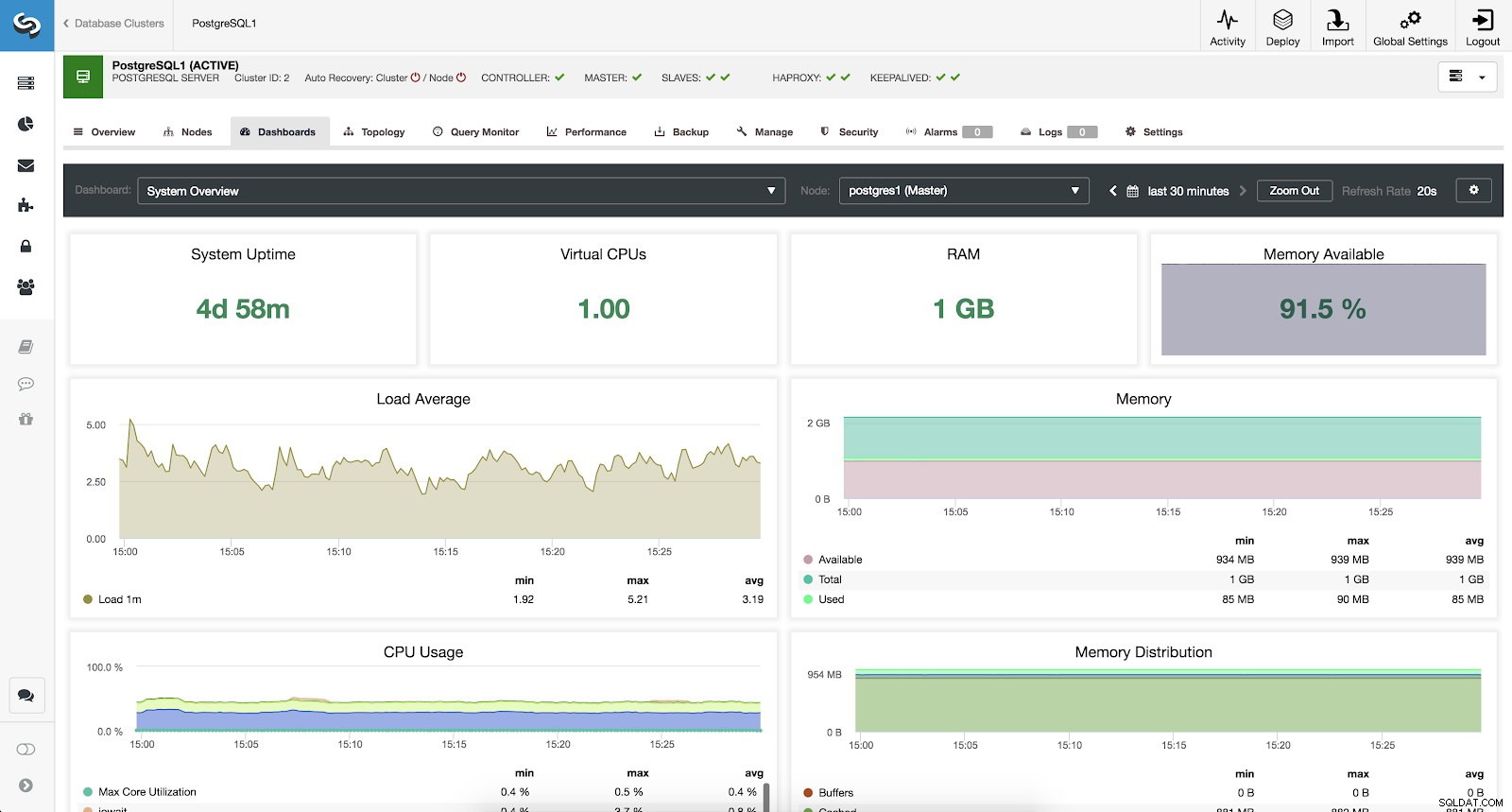 ClusterControl System Oversigt Metrics
ClusterControl System Oversigt Metrics Cross Server Graphs Metrics
Hvis vi ønsker at se den generelle tilstand for alle vores servere, kan vi bruge dette dashboard med følgende metrics:
- Belastningsgennemsnit:Servere indlæser gennemsnit for hver server.
- Hukommelsesbrug:Procentdel af hukommelsesforbrug for hver server.
- Netværkstrafik:Min., maks. og gennemsnitlige kBytes netværkstrafik pr. sekund.
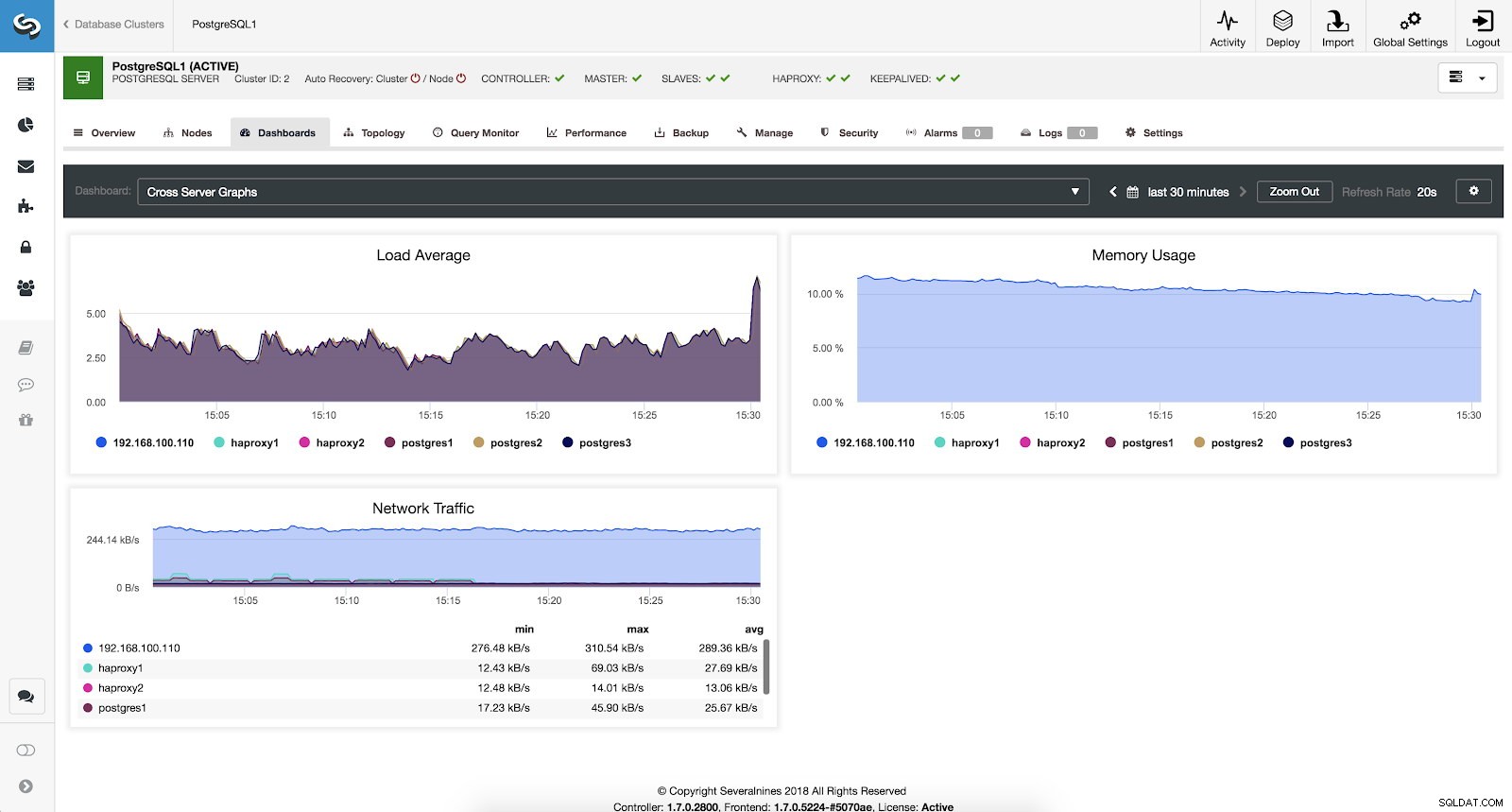 ClusterControl Cross Server Graphs Metrics
ClusterControl Cross Server Graphs Metrics Konklusion
Der er flere måder at overvåge PostgreSQL på. ClusterControl giver både agentfri og nu agentbaseret overvågning gennem Prometheus. Det giver overvågningsdata i højere opløsning samt forskellige dashboards for at forstå databasens ydeevne. ClusterControl kan også integreres med eksterne værktøjer som Slack eller PagerDuty til alarmering.