Efterhånden som 2014 slutter, starter jeg en række indlæg om proaktive SQL Server-sundhedstjek, baseret på et jeg skrev tilbage i begyndelsen af dette år – Performance Issues:The First Encounter. I det indlæg diskuterede jeg, hvad jeg kigger efter først, når jeg fejlfinder et præstationsproblem i et ukendt miljø. I denne serie af indlæg vil jeg fortælle om, hvad jeg ser efter, når jeg tjekker ind hos mine langsigtede kunder. Vi leverer en Remote DBA service, og en af vores faste opgaver er en månedlig "mini" sundhedsrevision af deres miljø. Vi har overvågning på plads, og jeg arbejder typisk på projekter, så jeg er i miljøet regelmæssigt. Men som et ekstra trin for at sikre, at vi ikke går glip af noget, gennemgår vi en gang om måneden de samme data, som vi indsamler i vores standard sundhedsaudit, og leder efter noget ud over det sædvanlige. Det kan være mange ting, ikke? Ja! Så lad os starte med plads.
Hov, plads? Ja, plads. Bare rolig, jeg kommer til andre emner. ☺
Hvad skal du tjekke
Hvorfor skulle jeg starte med plads? For det er noget, jeg ofte ser forsømt, og hvis du løber tør for diskplads til dine databasefiler, bliver du ekstremt begrænset i, hvad du kan gøre i din database. Har du brug for at tilføje data, men kan ikke udvide filen, fordi disken er fuld? Beklager, nu kan brugere ikke tilføje data. Tager du ikke log backup af en eller anden grund, så transaktionsloggen fylder drevet? Beklager, nu kan du ikke ændre nogen data. Pladsen er kritisk. Vi har job, der overvåger ledig plads på disken og i filerne, men jeg bekræfter stadig følgende for hver revision og sammenligner værdierne med værdierne fra den foregående måned:
- Størrelse af hver logfil
- Størrelsen af hver datafil
- Ledig plads i hver datafil
- Fri plads på hvert drev med databasefiler
- Fri plads på hvert drev med backupfiler
Logfilvækst
De fleste problemer, jeg ser relateret til diskplads, er på grund af vækst i logfiler. Væksten sker typisk af en af to årsager:
- Databasen er i FULD gendannelse, og sikkerhedskopier af transaktionslogfiler tages af en eller anden grund ikke
- Nogen kører en enkelt, meget stor transaktion, som bruger al eksisterende logplads, hvilket tvinger filen til at vokse
Jeg har også set logfilen vokse som en del af indeksvedligeholdelse. For genopbygninger logges hver allokering, og for store indekser kan det generere en betydelig mængde log. Selv med almindelige transaktionslog backups, kan loggen stadig vokse hurtigere, end backups kan forekomme. For at administrere loggen skal du justere backupfrekvensen eller ændre din indeksvedligeholdelsesmetodologi.
Du skal afgøre, hvorfor logfilen voksede, hvilket kan være vanskeligt, medmindre du sporer det. Jeg har et job, der kører hver time til snapshot-logfilstørrelse og -brug:
USE [Baselines];
GO
IF (NOT EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'dbo'
AND TABLE_NAME = 'SQLskills_TrackLogSpace'))
BEGIN
CREATE TABLE [dbo].[SQLskills_TrackLogSpace](
[DatabaseName] [VARCHAR](250) NULL,
[LogSizeMB] [DECIMAL](38, 0) NULL,
[LogSpaceUsed] [DECIMAL](38, 0) NULL,
[LogStatus] [TINYINT] NULL,
[CaptureDate] [DATETIME2](7) NULL
) ON [PRIMARY];
ALTER TABLE [dbo].[SQLskills_TrackLogSpace] ADD DEFAULT (SYSDATETIME()) FOR [CaptureDate];
END
CREATE TABLE #LogSpace_Temp (
DatabaseName VARCHAR(100),
LogSizeMB DECIMAL(10,2),
LogSpaceUsed DECIMAL(10,2),
LogStatus VARCHAR(1)
);
INSERT INTO #LogSpace_Temp EXEC('dbcc sqlperf(logspace)');
INSERT INTO Baselines.dbo.SQLskills_TrackLogSpace
(DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus)
SELECT DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus
FROM #LogSpace_Temp;
DROP TABLE #LogSpace_Temp; Jeg bruger disse oplysninger til at bestemme, hvornår logfilen begyndte at vokse, og jeg begynder at kigge gennem logfilerne og jobhistorikken for at se, hvilke yderligere oplysninger jeg kan finde. Logvækst bør være statisk – loggen skal have passende størrelse og administreres gennem sikkerhedskopier (hvis den kører i FULD gendannelse), og hvis filen skal være større, skal jeg forstå hvorfor og ændre størrelsen på den i overensstemmelse hermed.
Hvis du har at gøre med dette problem, og du ikke allerede proaktivt sporede filvæksthændelser, kan du muligvis stadig finde ud af, hvad der skete. Automatisk væksthændelser fanges af SQL Server; SQL Sentrys Aaron Bertrand bloggede om dette tilbage i 2007, hvor han viser, hvordan man opdager, hvornår disse hændelser skete (så længe de var nylige nok til stadig at eksistere i standardsporet).
Størrelse og ledig plads i datafiler
Du har sikkert allerede hørt, at dine datafiler skal have en forhåndsstørrelse, så de ikke behøver at vokse automatisk. Hvis du følger denne vejledning, har du sandsynligvis ikke oplevet den begivenhed, hvor datafilen vokser uventet. Men hvis du ikke administrerer dine datafiler, så har du sandsynligvis vækst, der forekommer regelmæssigt - uanset om du er klar over det eller ej (især med standard vækstindstillinger på 10 % og 1 MB).
Der er et trick til at foruddefinere datafiler – du ønsker ikke at dimensionere en database for stor, for husk, hvis du skal gendanne til f.eks. et dev- eller QA-miljø, har filerne samme størrelse, selvom de er ikke fuld af data. Men du ønsker stadig at styre væksten manuelt. Jeg oplever, at DBA'er har det sværest med nye databaser. Erhvervsbrugerne har ingen idé om vækstrater og hvor meget data der tilføjes, og den database er lidt af en løs kanon i dit miljø. Du skal være meget opmærksom på disse filer, indtil du har styr på størrelse og forventet vækst. Jeg bruger en forespørgsel, der giver oplysninger om størrelse og ledig plads:
SELECT
[file_id] AS [File ID],
[type] AS [File Type],
substring([physical_name],1,1) AS [Drive],
[name] AS [Logical Name],
[physical_name] AS [Physical Name],
CAST([size] as DECIMAL(38,0))/128. AS [File Size MB],
CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128. AS [Space Used MB],
(CAST([size] AS DECIMAL(38,0))/128) - (CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128.) AS [Free Space],
[max_size] AS [Max Size],
[is_percent_growth] AS [Percent Growth Enabled],
[growth] AS [Growth Rate],
SYSDATETIME() AS [Current Date]
FROM sys.database_files; Hver måned tjekker jeg størrelsen på datafilerne og den brugte plads, og beslutter derefter, om størrelsen skal øges. Jeg overvåger også standardsporet for væksthændelser, da dette fortæller mig præcis, hvornår væksten opstår. Med undtagelse af nye databaser kan jeg altid være på forkant med automatisk filvækst og håndtere det manuelt. Ok, næsten altid. Lige før ferien sidste år fik jeg besked af en kundes IT-afdeling om lav ledig plads på et drev (hold den tanke til næste afsnit). Nu er meddelelsen baseret på en tærskel på mindre end 20 % gratis. Dette drev var over 1 TB, så der var omkring 150 GB ledigt, da jeg tjekkede drevet. Det var ikke en nødsituation endnu, men jeg havde brug for at forstå, hvor pladsen var blevet af.
Da jeg tjekkede databasefilerne for en database, kunne jeg se, at de var fulde - og den foregående måned havde hver fil over 50 GB ledigt. Jeg gravede derefter i tabelstørrelser og fandt ud af, at der i én tabel var blevet tilføjet over 270 millioner rækker inden for de seneste 16 dage – i alt over 100 GB data. Det viste sig, at der havde været en kodeændring, og den nye kode loggede flere oplysninger end beregnet. Vi satte hurtigt et job op for at rense rækkerne og gendanne den ledige plads i filerne (og de fiksede koden). Jeg kunne dog ikke gendanne diskplads - jeg ville være nødt til at formindske filerne, og det var ikke en mulighed. Jeg skulle derefter bestemme, hvor meget plads der var tilbage på disken og beslutte, om det var et beløb, jeg var tryg ved eller ej. Mit komfortniveau afhænger af at vide, hvor meget data der tilføjes om måneden – den typiske vækstrate. Og jeg ved kun, hvor meget data der tilføjes, fordi jeg overvåger filbrug og kan estimere, hvor meget plads der vil være behov for denne måned, for dette år og for de næste to år.
Kør plads
Jeg nævnte tidligere, at vi har job til at overvåge ledig plads på disken. Dette er baseret på en procentdel, ikke et fast beløb. Min generelle tommelfingerregel har været at sende meddelelser, når mindre end 10% af disken er ledig, men for nogle drev skal du muligvis indstille det højere. For eksempel, med et 1 TB-drev, får jeg besked, når der er mindre end 100 GB ledigt. Med et 100 GB-drev får jeg besked, når der er mindre end 10 GB ledigt. Med et 20 GB-drev... ja, du kan se, hvor jeg vil hen med dette. Denne tærskel skal advare dig, før der er et problem. Hvis jeg kun har 10 GB ledigt på et drev, der er vært for en logfil, har jeg måske ikke tid nok til at reagere, før det dukker op som et problem for brugerne – afhængigt af hvor ofte jeg tjekker den ledige plads og hvad problemet er. er.
Det er meget nemt at bruge xp_fixeddrives til at tjekke ledig plads, men jeg vil ikke anbefale dette, da det er udokumenteret, og brugen af udvidede lagrede procedurer generelt er blevet forældet. Den rapporterer heller ikke den samlede størrelse af hvert drev og rapporterer muligvis ikke om alle drevtyper, som dine databaser muligvis bruger. Så længe du kører SQL Server 2008R2 SP1 eller højere, kan du bruge den meget mere praktiske sys.dm_os_volume_stats til at få de oplysninger, du har brug for, i det mindste om de drev, hvor databasefiler findes:
SELECT DISTINCT vs.volume_mount_point AS [Drive], vs.logical_volume_name AS [Drive Name], vs.total_bytes/1024/1024 AS [Drive Size MB], vs.available_bytes/1024/1024 AS [Drive Free Space MB] FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) AS vs ORDER BY vs.volume_mount_point;
Jeg ser ofte et problem med drevplads på diskenheder, der hoster tempdb. Jeg har mistet tællingen af de gange, jeg har haft klienter med uforklarlig tempdb vækst. Nogle gange er det kun et par GB; senest var det 200GB. Tempdb er et vanskeligt udyr – der er ingen formel at følge, når den skal dimensioneres, og alt for ofte placeres den på et drev med lidt ledig plads, der ikke kan håndtere den skøre begivenhed forårsaget af rookie-udvikleren eller DBA. Størrelse af tempdb-datafiler kræver, at du kører din arbejdsbyrde i en "normal" forretningscyklus for at bestemme, hvor meget den bruger tempdb, og derefter størrelser den i overensstemmelse hermed.
Jeg hørte for nylig et forslag til en måde at undgå at løbe tør for plads på et drev:Opret en database uden data, og størrelse filerne, så de bruger lige meget plads, du vil "afsætte". Så, hvis du støder på et problem, skal du bare slippe databasen og bratsch, du har ledig plads igen. Personligt synes jeg, at dette skaber alle slags andre problemer og vil ikke anbefale det. Men hvis du har lageradministratorer, der ikke kan lide at se hundredvis af ubrugte GB'er på et drev, ville dette være en måde at få et drev til at "se" fuldt ud. Det minder mig om noget, jeg har hørt en god ven sige:"Hvis jeg ikke kan arbejde sammen med dig, vil jeg arbejde omkring dig."
Sikkerhedskopier
En af DBA's primære opgaver er at beskytte dataene. Sikkerhedskopier er en metode, der bruges til at beskytte det, og som sådan er de drev, der holder disse sikkerhedskopier, en integreret del af en DBAs liv. Formentlig holder du en eller flere sikkerhedskopier online, for at gendanne straks, hvis det er nødvendigt. Din SLA- og DR-runbog hjælper med at diktere, hvor mange sikkerhedskopier du holder online, og du skal sikre dig, at du har den plads til rådighed. Jeg går ind for, at du heller ikke sletter gamle sikkerhedskopier, før den nuværende sikkerhedskopiering er gennemført. Det er alt for nemt at falde i fælden med at slette gamle sikkerhedskopier og derefter køre den nuværende backup. Men hvad sker der, hvis den nuværende backup fejler? Og hvad sker der, hvis du bruger komprimering? Vent et øjeblik ... komprimerede sikkerhedskopier er mindre ikke? De er mindre i sidste ende. Men vidste du, at .bak-filstørrelsen normalt starter større end slutstørrelsen? Du kan bruge sporingsflag 3042 til at ændre denne adfærd, men du bør tænke på, at med sikkerhedskopier har du brug for masser af plads. Hvis din backup er på 100 GB, og du beholder 3 dages værdi online, har du brug for 300 GB for de 3 dages backup, og så sandsynligvis en sund mængde (2X den nuværende databasestørrelse) gratis til næste backup. Ja, det betyder, at du til enhver tid vil have mere end 100 GB ledigt på dette drev. Det er ok. Det er bedre end at få sletteopgaven til at lykkes, og sikkerhedskopieringsjobbet mislykkes, og finde ud af tre dage senere, at du slet ikke har nogen sikkerhedskopier (det skete for en kunde på mit tidligere job).
De fleste databaser bliver bare større med tiden, hvilket betyder, at backups også bliver større. Glem ikke regelmæssigt at tjekke størrelsen af backupfilerne og allokere ekstra plads efter behov - at have en "200 GB gratis" politik for en database, der er vokset til 350 GB, vil ikke være særlig nyttig. Hvis pladskravene ændres, skal du også sørge for at ændre eventuelle tilknyttede advarsler.
Brug af Performance Advisor
Der er flere forespørgsler inkluderet i dette indlæg, som du kan bruge til at overvåge plads, hvis du har brug for at rulle din egen proces. Men hvis du tilfældigvis har SQL Sentry Performance Advisor i dit miljø, bliver dette meget nemmere med brugerdefinerede betingelser. Der er flere lagerbetingelser inkluderet som standard, men du kan også oprette dine egne.
I SQL Sentry-klienten skal du åbne Navigator, højreklikke på Shared Groups (Global), og vælge Tilføj brugerdefineret betingelse → SQL Sentry. Angiv et navn og en beskrivelse af betingelsen, tilføj derefter en numerisk sammenligning, og skift typen til Repository Query. Indtast forespørgslen:
SELECT MIN(FreeSpace*100.0/Size) FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk;
Skift Er lig med Er mindre end, og indstil en eksplicit værdi på 10. Til sidst skal du ændre standardevalueringsfrekvensen til noget mindre hyppigt end hvert 10. sekund. En gang om dagen eller en gang hver 12. time er sandsynligvis en god værdi - du bør ikke have behov for at tjekke ledig plads oftere end én gang om dagen, men du kan tjekke det så ofte, du vil. Skærmbilledet nedenfor viser den endelige konfiguration:
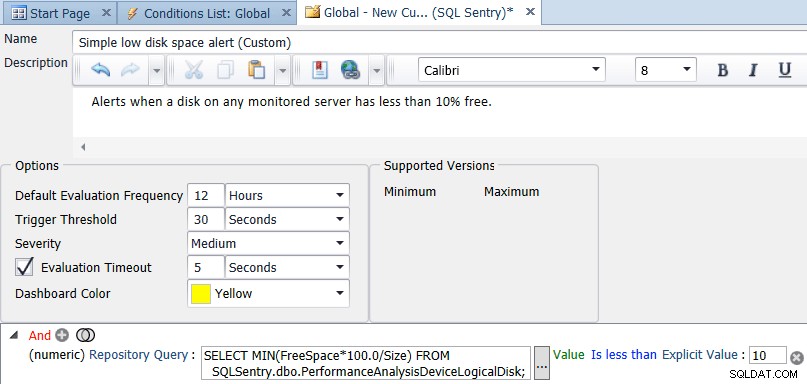
Når du klikker på Gem for betingelsen, bliver du spurgt, om du vil tildele handlinger for den brugerdefinerede betingelse. Indstillingen for at sende til alarmeringskanaler er valgt som standard, men du ønsker måske at udføre andre opgaver, såsom Udfør et job – for eksempel at kopiere gamle sikkerhedskopier til en anden placering (hvis det er drevet med lav plads).
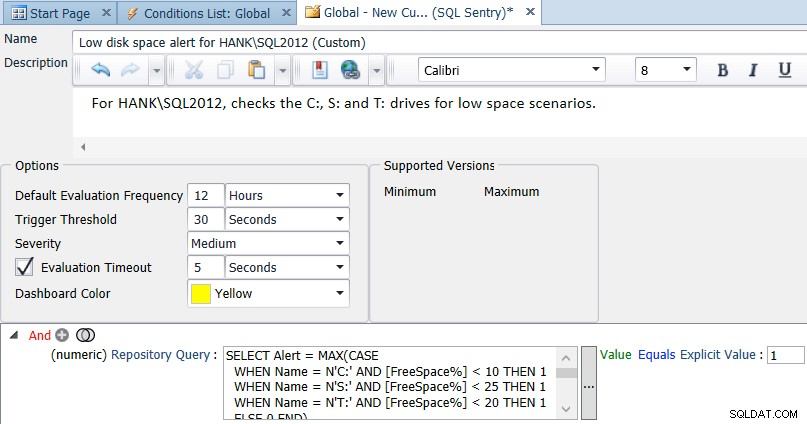
Som jeg nævnte tidligere, er en standard på 10% ledig plads til alle drev sandsynligvis ikke passende for hvert drev i dit miljø. Du kan tilpasse forespørgslen til forskellige forekomster og drev, for eksempel:
SELECT Alert = MAX(CASE WHEN Name = N'C:' AND [FreeSpace%] < 10 THEN 1 WHEN Name = N'S:' AND [FreeSpace%] < 25 THEN 1 WHEN Name = N'T:' AND [FreeSpace%] < 20 THEN 1 ELSE 0 END) FROM ( SELECT d.Name, d.FreeSpace * 100.0/d.Size AS [FreeSpace%] FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk AS d INNER JOIN SQLSentry.dbo.EventSourceConnection AS c ON d.DeviceID = c.DeviceID WHERE c.ObjectName = N'HANK\SQL2012' -- replace with your server/instance ) AS s;
Du kan ændre og udvide denne forespørgsel efter behov for dit miljø, og derefter ændre sammenligningen i tilstanden i overensstemmelse hermed (grundlæggende evalueres til sand, hvis resultatet nogensinde er 1):
Hvis du vil se Performance Advisor i aktion, er du velkommen til at downloade en prøveversion.
Bemærk, at for begge disse forhold vil du kun blive advaret én gang, selvom flere drev falder under din tærskel. I komplekse miljøer vil du måske læne dig mod et større antal mere specifikke forhold for at give mere fleksible og tilpassede advarsler i stedet for færre "catch-all"-betingelser.
Oversigt
Der er mange kritiske komponenter i et SQL Server-miljø, og diskplads er en, der skal overvåges og vedligeholdes proaktivt. Med bare en lille smule planlægning er dette nemt at gøre, og det afhjælper mange ubekendte og reaktiv problemløsning. Uanset om du bruger dine egne scripts eller et tredjepartsværktøj, er det et problem, der er let at løse og besværet værd at sørge for, at der er masser af ledig plads til databasefiler og sikkerhedskopier.