Overvej følgende AdventureWorks-forespørgsel, der returnerer historiktabeltransaktions-id'er for produkt-id 421:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
Forespørgselsoptimeringsværktøjet finder hurtigt en effektiv eksekveringsplan med et kardinalitetsestimat (rækkeantal), der er nøjagtigt korrekt, som vist i SQL Sentry Plan Explorer:

Sig nu, at vi ønsker at finde historiske transaktions-id'er for AdventureWorks-produktet med navnet "Metal Plate 2". Der er mange måder at udtrykke denne forespørgsel på i T-SQL. En naturlig formulering er:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Udførelsesplanen er som følger:
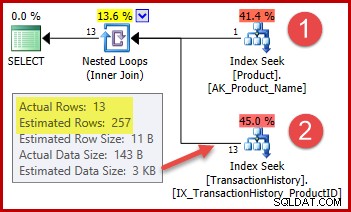
Strategien er:
- Søg produkt-id'et i produkttabellen ud fra det angivne navn
- Find rækker for det pågældende produkt-id i oversigtstabellen
Det estimerede antal rækker for trin 1 er helt korrekt, fordi det anvendte indeks er erklæret som unikt og indtastet alene på produktnavnet. Ligestillingstesten på "Metalplade 2" vil derfor garanteret returnere præcis én række (eller nul rækker, hvis vi angiver et produktnavn, der ikke eksisterer).
Det fremhævede estimat med 257 rækker for trin to er mindre nøjagtigt:Kun 13 rækker er faktisk stødt på. Denne uoverensstemmelse opstår, fordi optimeringsværktøjet ikke ved, hvilket bestemt produkt-id, der er knyttet til produktet med navnet "Metalplade 2". Den behandler værdien som ukendt og genererer et kardinalitetsestimat ved hjælp af information om gennemsnitlig tæthed. Beregningen bruger elementer fra statistikobjektet vist nedenfor:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
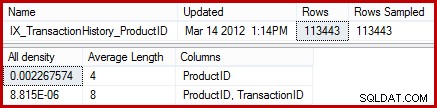
Statistikken viser, at tabellen indeholder 113443 rækker med 441 unikke produkt-id'er (1 / 0,002267574 =441). Forudsat at fordelingen af rækker på tværs af produkt-id'er er ensartet, forventer kardinalitetsestimatet, at et produkt-id matcher (113443 / 441) =257,24 rækker i gennemsnit. Som det viser sig, er fordelingen ikke særlig ensartet; der er kun 13 rækker til "Metal Plate 2" produktet.
En sidebemærkning
Du tænker måske, at estimatet på 257 rækker burde være mere nøjagtigt. For eksempel, da produkt-id'er og navne begge er begrænset til at være unikke, kan SQL Server automatisk vedligeholde oplysninger om denne en-til-en-relation. Den ville så vide, at "Metalplade 2" er forbundet med produkt-ID 479, og bruge denne indsigt til at generere et mere nøjagtigt estimat ved hjælp af ProductID-histogrammet:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
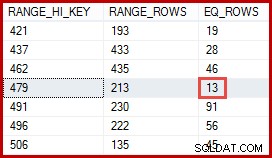
Et estimat på 13 rækker afledt på denne måde ville have været helt korrekt. Ikke desto mindre var estimatet på 257 rækker ikke urimeligt i betragtning af de tilgængelige statistiske oplysninger og de normale forenklingsantagelser (såsom ensartet fordeling) anvendt ved kardinalitetsestimat i dag. Præcise estimater er altid gode, men "rimelige" estimater er også helt acceptable.
Kombinering af de to forespørgsler
Lad os sige, at vi nu vil se alle transaktionshistorik-id'er, hvor produkt-id'et er 421 ELLER produktets navn er "Metalplade 2". En naturlig måde at kombinere de to foregående forespørgsler på er:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
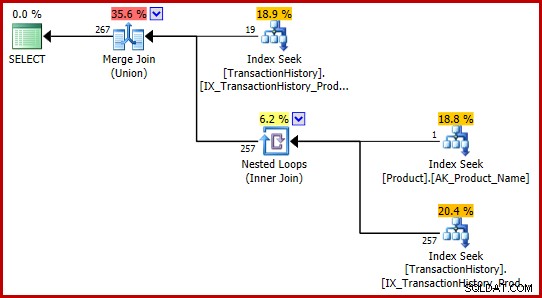
); Udførelsesplanen er lidt mere kompleks nu, men den indeholder stadig genkendelige elementer af enkeltprædikatplanerne:
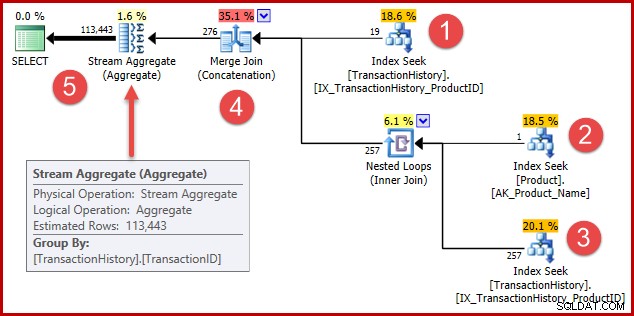
Strategien er:
- Find historieregistreringer for produkt 421
- Søg produkt-id'et for produktet med navnet "Metalplade 2"
- Find historikregistreringer for det produkt-id, der blev fundet i trin 2
- Kombiner rækker fra trin 1 og 3
- Fjern eventuelle dubletter (fordi produkt 421 muligvis også er det, der hedder "Metalplade 2")
Trin 1 til 3 er nøjagtig de samme som før. De samme estimater er fremstillet af de samme årsager. Trin 4 er nyt, men meget enkelt:det sammenkæder forventede 19 rækker med forventede 257 rækker for at give et estimat på 276 rækker.
Trin 5 er det interessante. Streamaggregatet, der fjerner duplikat, har et estimeret input på 276 rækker og et estimeret output på 113443 rækker. Et aggregat, der udsender flere rækker, end det modtager, virker umuligt, ikke?
* Du vil se et estimat på 102099 rækker her, hvis du bruger kardinalitetsestimatmodellen før 2014.
Kardinalitetsvurderingsfejlen
Det umulige Stream Aggregate-estimat i vores eksempel er forårsaget af en fejl i kardinalitetsestimat. Det er et interessant eksempel, så vi vil undersøge det lidt detaljeret.
Fjernelse af underforespørgsler
Det kan overraske dig at lære, at SQL Server-forespørgselsoptimeringsværktøjet ikke virker direkte med underforespørgsler. De fjernes fra det logiske forespørgselstræ tidligt i kompileringsprocessen og erstattes med en tilsvarende konstruktion, som optimizeren er sat op til at arbejde med og ræsonnere omkring. Optimizeren har en række regler, der fjerner underforespørgsler. Disse kan angives efter navn ved hjælp af følgende forespørgsel (den refererede DMV er minimalt dokumenteret, men ikke understøttet):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Resultater (på SQL Server 2014):
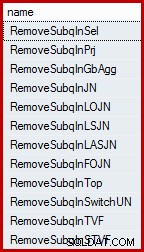
Den kombinerede testforespørgsel har to prædikater ("udvalg" i relationelle termer) på historiktabellen, forbundet med OR . Et af disse prædikater inkluderer en underforespørgsel. Hele undertræet (både prædikater og underforespørgsel) transformeres af den første regel i listen ("fjern underforespørgsel i udvalg") til en semi-join over foreningen af de enkelte prædikater. Selvom det ikke er muligt at repræsentere resultatet af denne interne transformation nøjagtigt ved hjælp af T-SQL-syntaks, er det temmelig tæt på at være:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); Det er lidt uheldigt, at min T-SQL-tilnærmelse af det interne træ efter fjernelse af underforespørgsler indeholder en underforespørgsel, men på sproget for forespørgselsprocessoren gør den det ikke (det er en semi-join). Hvis du foretrækker at se den rå interne form i stedet for mit forsøg på en T-SQL-ækvivalent, kan du være sikker på, at det vil være med et øjeblik.
Det udokumenterede forespørgselstip inkluderet i T-SQL ovenfor er der for at forhindre en efterfølgende transformation for dem af jer, der ønsker at se den transformerede logik i udførelsesplanform. Annoteringerne nedenfor viser positionerne for de to prædikater efter transformation:
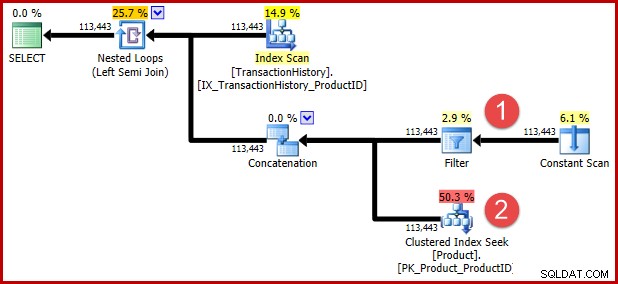
Intuitionen bag transformationen er, at en historierække kvalificerer sig, hvis et af prædikaterne er opfyldt. Uanset hvor hjælpsom du finder min omtrentlige T-SQL- og eksekveringsplanillustration, håber jeg, at det i det mindste er rimeligt klart, at omskrivningen udtrykker det samme krav som den oprindelige forespørgsel.
Jeg bør understrege, at optimizeren ikke bogstaveligt talt genererer alternativ T-SQL-syntaks eller producerer komplette udførelsesplaner på mellemliggende stadier. T-SQL-repræsentationerne og udførelsesplanen ovenfor er udelukkende beregnet til hjælp til forståelsen. Hvis du er interesseret i de rå detaljer, er den lovede interne repræsentation af det transformerede forespørgselstræ (let redigeret for klarhed/mellemrum):
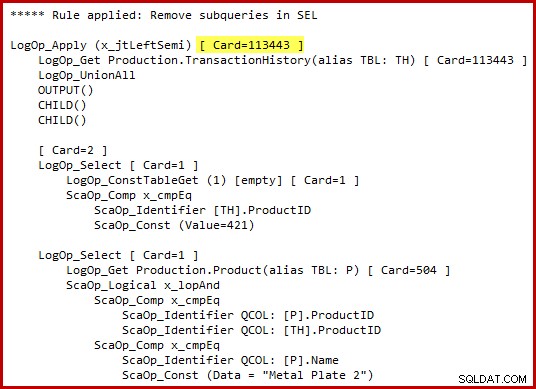
Bemærk det fremhævede anvend semi join-kardinalitetsestimat. Det er 113443 rækker, når du bruger 2014-kardinalitetsestimatoren (102099 rækker, hvis du bruger den gamle CE). Husk, at AdventureWorks historietabellen indeholder 113443 rækker i alt, så dette repræsenterer 100 % selektivitet (90 % for det gamle CE).
Vi så tidligere, at anvendelse af et af disse prædikater alene resulterer i kun et lille antal matches:19 rækker for produkt-ID 421 og 13 rækker (anslået 257) for "Metalplade 2". Estimerer, at disjunktionen (OR) af de to prædikater vil returnere alle rækker i basistabellen, og det virker helt vildt.
Bugdetaljer
Detaljerne for selektivitetsberegningen for semi-join er kun synlige i SQL Server 2014, når du bruger den nye kardinalitetsestimator med (udokumenteret) sporingsflag 2363. Det er sandsynligvis muligt at se noget lignende med Extended Events, men sporingsflagoutputtet er mere praktisk at bruge her. Det relevante afsnit af outputtet er vist nedenfor:
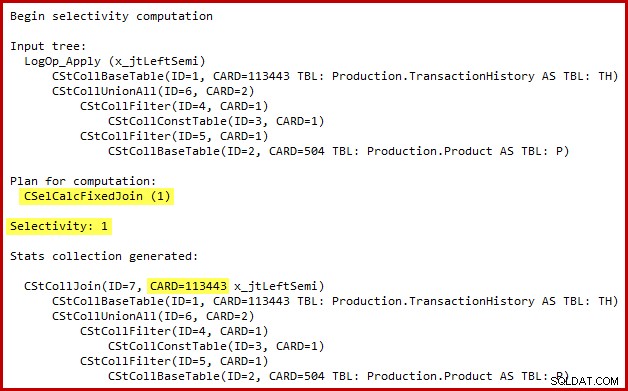
Kardinalitetsestimatoren bruger Fixed Join-beregneren med 100 % selektivitet. Som en konsekvens heraf er den estimerede outputkardinalitet af semi-joiningen den samme som dens input, hvilket betyder, at alle 113443 rækker fra historiktabellen forventes at kvalificere sig.
Den nøjagtige karakter af fejlen er, at semi join-selektivitetsberegningen savner alle prædikater, der er placeret ud over en union, alle i inputtræet. I illustrationen nedenfor opfattes manglen på prædikater på selve semi-sammenføjningen til at betyde, at hver række vil kvalificere sig; den ignorerer virkningen af prædikater under sammenkædningen (union alle).
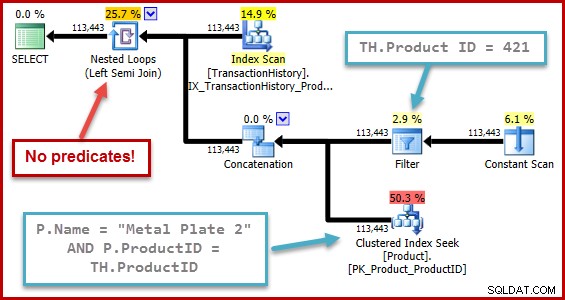
Denne adfærd er så meget desto mere overraskende, når man tænker på, at selektivitetsberegning opererer på en trærepræsentation, som optimeringsværktøjet selv genererede (træets form og prædikaternes placering er resultatet af, at den fjerner underforespørgslen).
Et lignende problem opstår med kardinalitetsestimatoren før 2014, men det endelige estimat er i stedet fastsat til 90 % af det estimerede semi join-input (af underholdende årsager relateret til et omvendt fast 10 % prædikatestimat, der er for meget af en afledning til at få ind).
Eksempler
Som nævnt ovenfor manifesterer denne fejl sig, når estimering udføres for en semi-join med relaterede prædikater placeret ud over en union alle. Hvorvidt dette interne arrangement forekommer under forespørgselsoptimering afhænger af den originale T-SQL-syntaks og den præcise rækkefølge af interne optimeringsoperationer. Følgende eksempler viser nogle tilfælde, hvor fejlen forekommer og ikke forekommer:
Eksempel 1
Dette første eksempel inkorporerer en triviel ændring af testforespørgslen:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Den estimerede udførelsesplan er:
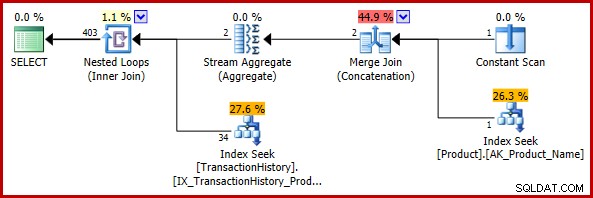
Det endelige estimat på 403 rækker er ikke i overensstemmelse med de indlejrede loops-join's inputestimater, men det er stadig rimeligt (i den forstand, der blev diskuteret tidligere). Hvis fejlen var stødt på, ville det endelige estimat være 113443 rækker (eller 102099 rækker ved brug af CE-modellen før 2014).
Eksempel 2
Hvis du var ved at skynde dig ud og omskrive alle dine konstante sammenligninger som trivielle underforespørgsler for at undgå denne fejl, så se hvad der sker, hvis vi laver endnu en triviel ændring, denne gang erstatter lighedstesten i det andet prædikat med IN. Betydningen af forespørgslen forbliver uændret:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Fejlen returnerer:
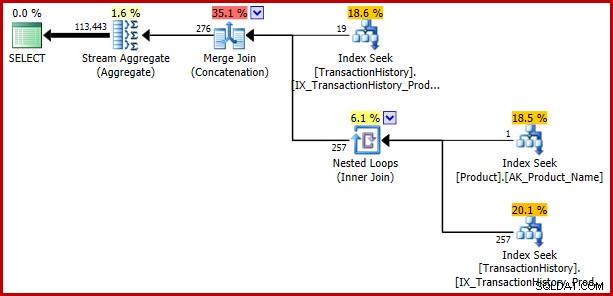
Eksempel 3
Selvom denne artikel hidtil har koncentreret sig om et disjunktivt prædikat, der indeholder en underforespørgsel, viser følgende eksempel, at den samme forespørgselsspecifikation udtrykt ved hjælp af EXISTS og UNION ALL også er sårbar:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Udførelsesplan:
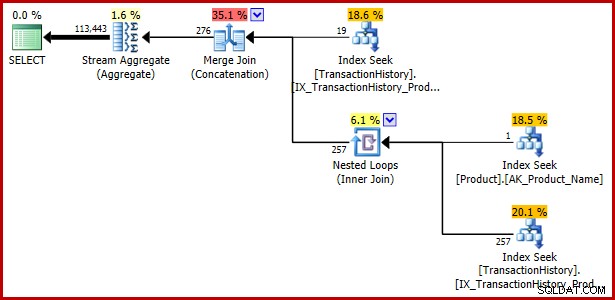
Eksempel 4
Her er yderligere to måder at udtrykke den samme logiske forespørgsel på i T-SQL:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Ingen af forespørgslerne støder på fejlen, og begge producerer den samme eksekveringsplan:
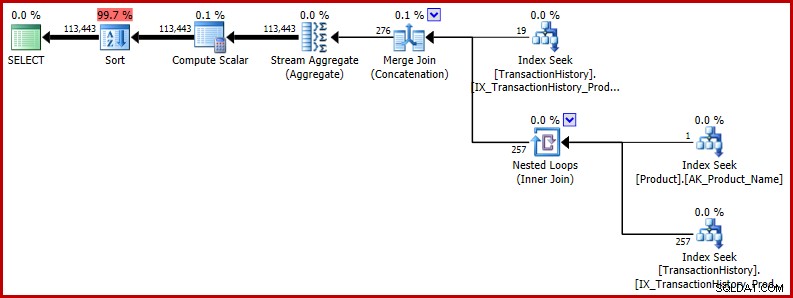
Disse T-SQL-formuleringer producerer tilfældigvis en eksekveringsplan med fuldstændig konsistente (og rimelige) estimater.
Eksempel 5
Du spekulerer måske på, om det unøjagtige skøn er vigtigt. I de hidtil præsenterede sager er det ikke, i hvert fald ikke direkte. Der opstår problemer, når fejlen opstår i en større forespørgsel, og det forkerte estimat påvirker optimeringsbeslutninger andre steder. Som et minimalt udvidet eksempel kan du overveje at returnere resultaterne af vores testforespørgsel i en tilfældig rækkefølge:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New Udførelsesplanen viser, at det forkerte skøn påvirker senere drift. For eksempel er det grundlaget for hukommelsesbevillingen reserveret til sorteringen:
Hvis du gerne vil se et mere virkeligt eksempel på denne fejls potentielle virkning, så tag et kig på dette nylige spørgsmål fra Richard Mansell på SQLPerformance.com Q &A-webstedet answers.SQLPerformance.com.
Opsummering og endelige tanker
Denne fejl udløses, når optimeringsværktøjet udfører kardinalitetsestimat for en semi-join under særlige omstændigheder. Det er en udfordrende fejl at få øje på og omgås af en række årsager:
- Der er ingen eksplicit T-SQL-syntaks til at specificere en semi-join, så det er svært på forhånd at vide, om en bestemt forespørgsel vil være sårbar over for denne fejl.
- Optimeringsværktøjet kan introducere en semi-join under en lang række omstændigheder, som ikke alle er åbenlyse semi join-kandidater.
- Den problematiske semi-join bliver ofte transformeret til noget andet ved senere optimeringsaktivitet, så vi kan ikke engang stole på, at der er en semi join-operation i den endelige udførelsesplan.
- Ikke ethvert mærkeligt udseende kardinalitetsestimat er forårsaget af denne fejl. Faktisk er mange eksempler på denne type en forventet og harmløs bivirkning af normal optimeringsfunktion.
- Det fejlagtige semi join-selektivitetsestimat vil altid være 90 % eller 100 % af dets input, men dette vil normalt ikke svare til kardinaliteten af en tabel, der bruges i planen. Ydermere er den semi join-input-kardinalitet, der bruges i beregningen, muligvis ikke engang synlig i den endelige udførelsesplan.
- Der er typisk mange måder at udtrykke den samme logiske forespørgsel på i T-SQL. Nogle af disse vil udløse fejlen, mens andre ikke vil.
Disse overvejelser gør det vanskeligt at give praktiske råd til at opdage eller omgå denne fejl. Det er bestemt umagen værd at tjekke eksekveringsplaner for "uhyrlige" estimater og undersøge forespørgsler med ydeevne, der er meget dårligere end forventet, men begge disse kan have årsager, der ikke er relateret til denne fejl. Når det er sagt, er det især værd at tjekke forespørgsler, der inkluderer en adskillelse af prædikater og en underforespørgsel. Som eksemplerne i denne artikel viser, er dette ikke den eneste måde at støde på fejlen på, men jeg forventer, at det er en almindelig måde.
Hvis du er så heldig at køre SQL Server 2014, med den nye kardinalitetsestimator aktiveret, kan du muligvis bekræfte fejlen ved manuelt at kontrollere sporingsflag 2363 output for en fast 100 % selektivitetsestimat på en semi join, men dette er næppe praktisk. Du ønsker naturligvis ikke at bruge udokumenterede sporingsflag på et produktionssystem.
User Voice-fejlrapporten for dette problem kan findes her. Stem og kommenter, hvis du gerne vil se dette problem undersøgt (og muligvis løst).