I enhver af relationsdatabasemotorerne er det nødvendigt at generere en bedst mulig plan, der svarer til udførelsen af forespørgslen med mindst tid og ressourcer. Generelt genererer alle databaser planer i et træstrukturformat, hvor bladknudepunktet for hvert plantræ kaldes tabelscanningsknude. Denne særlige node i planen svarer til den algoritme, der skal bruges til at hente data fra basistabellen.
Betragt f.eks. et simpelt forespørgselseksempel som SELECT * FROM TBL1, TBL2 hvor TBL2.ID>1000; og antag, at den genererede plan er som nedenfor:
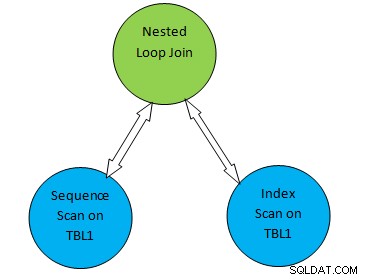
Så i ovenstående plantræ, “Sekventiel scanning på TBL1” og “ Indeksscanning på TBL2” svarer til tabelscanningsmetoden på henholdsvis tabel TBL1 og TBL2. Så i henhold til denne plan vil TBL1 blive hentet sekventielt fra de tilsvarende sider, og TBL2 kan tilgås ved hjælp af INDEX Scan.
Valg af den rigtige scanningsmetode som en del af planen er meget vigtigt med hensyn til den overordnede forespørgselsydeevne.
Før vi går ind i alle typer scanningsmetoder, der understøttes af PostgreSQL, lad os revidere nogle af de vigtigste nøglepunkter, som vil blive brugt hyppigt, når vi går gennem bloggen.
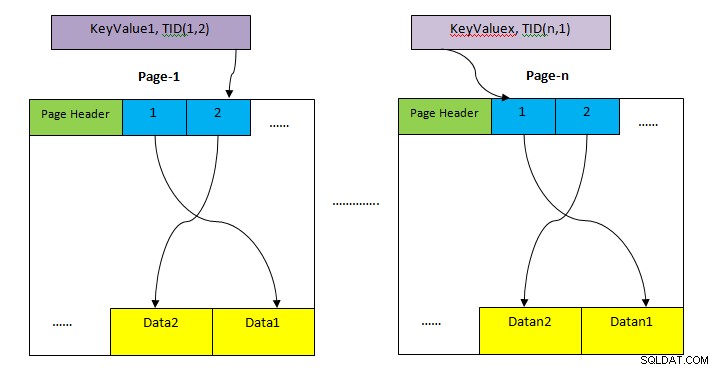
- HEAP: Opbevaringsområde til opbevaring af hele bordets række. Dette er opdelt i flere sider (som vist på billedet ovenfor), og hver sidestørrelse er som standard 8KB. På hver side peger hver punktmarkør (f.eks. 1, 2, ….) på data på siden.
- Indekslagring: Dette lager gemmer kun nøgleværdier, dvs. kolonneværdier indeholdt af indeks. Dette er også opdelt i flere sider, og hver sidestørrelse er som standard 8KB.
- Tuple Identifier (TID): TID er 6 bytes tal, som består af to dele. Den første del er 4-byte sidetal og resterende 2 bytes tuple indeks inde på siden. Kombinationen af disse to tal peger entydigt på opbevaringsstedet for en bestemt tupel.
I øjeblikket understøtter PostgreSQL nedenstående scanningsmetoder, hvorved alle nødvendige data kan læses fra tabellen:
- Sekventiel scanning
- Indeksscanning
- Kun indeksscanning
- Bitmap-scanning
- TID-scanning
Hver af disse scanningsmetoder er lige nyttige afhængigt af forespørgslen og andre parametre, f.eks. tabelkardinalitet, tabelselektivitet, disk I/O-omkostninger, tilfældige I/O-omkostninger, sekvens I/O-omkostninger osv. Lad os lave en forudindstillet tabel og udfylde nogle data, som ofte vil blive brugt til bedre at forklare disse scanningsmetoder .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZESå i dette eksempel er en million poster indsat, og derefter analyseres tabellen, så al statistik er opdateret.
Sekventiel scanning
Som navnet antyder, udføres en sekventiel scanning af en tabel ved sekventielt at scanne alle punktpointere på alle sider i de tilsvarende tabeller. Så hvis der er 100 sider for en bestemt tabel, og så er der 1000 poster på hver side, vil den som en del af sekventiel scanning hente 100*1000 poster og kontrollere, om den matcher i henhold til isolationsniveau og også i henhold til prædikatklausulen. Så selvom kun 1 post er valgt som en del af hele tabelscanningen, bliver den nødt til at scanne 100.000 poster for at finde en kvalificeret post i henhold til betingelsen.
I henhold til ovenstående tabel og data vil følgende forespørgsel resultere i en sekventiel scanning, da størstedelen af data bliver valgt.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)BEMÆRK
Selv uden at beregne og sammenligne planomkostninger, er det næsten umuligt at sige, hvilken slags scanninger der vil blive brugt. Men for at den sekventielle scanning kan bruges, skal mindst nedenstående kriterier matche:
- Intet indeks tilgængeligt på nøglen, som er en del af prædikatet.
- Størstedelen af rækker hentes som en del af SQL-forespørgslen.
TIPS
Hvis kun meget få % af rækkerne bliver hentet, og prædikatet er i en (eller flere) kolonner, så prøv at evaluere ydeevnen med eller uden indeks.
Indeksscanning
I modsætning til sekventiel scanning henter indeksscanning ikke alle poster sekventielt. I stedet bruger den en anden datastruktur (afhængigt af indekstypen) svarende til det indeks, der er involveret i forespørgslen, og lokaliser nødvendige data (i henhold til prædikat) klausul med meget minimale scanninger. Derefter peger posten fundet ved hjælp af indeksscanningen direkte på data i heap-området (som vist i ovenstående figur), som derefter hentes for at kontrollere synlighed i henhold til isolationsniveauet. Så der er to trin til indeksscanning:
- Hent data fra indeksrelateret datastruktur. Det returnerer TID for tilsvarende data i heap.
- Derefter tilgås den tilsvarende heap-side direkte for at få hele data. Dette yderligere trin er påkrævet af nedenstående årsager:
- Forespørgsel kan have anmodet om at hente flere kolonner end det, der er tilgængeligt i det tilsvarende indeks.
- Synlighedsoplysninger vedligeholdes ikke sammen med indeksdata. Så for at kontrollere synligheden af data i henhold til isolationsniveau, skal den have adgang til heap-data.
Nu kan vi undre os over, hvorfor ikke altid bruge Index Scan, hvis det er så effektivt. Så som vi ved kommer alting med nogle omkostninger. Her er omkostningerne forbundet med den type I/O, vi laver. I tilfælde af indeksscanning er tilfældig I/O involveret, da for hver post fundet i indekslager skal den hente tilsvarende data fra HEAP-lager, mens i tilfælde af sekventiel scanning er sekvens-I/O involveret, hvilket kun tager omkring 25 % af tilfældig I/O-timing.
Så indeksscanning bør kun vælges, hvis den samlede gevinst overgår de overhead, der påløber på grund af tilfældige I/O-omkostninger.
I henhold til ovenstående tabel og data vil følgende forespørgsel resultere i en indeksscanning, da kun én post bliver valgt. Så tilfældig I/O er mindre, ligesom søgning af den tilsvarende post er hurtig.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Scan kun indeks
Index Only Scan svarer til Index Scan bortset fra det andet trin, dvs. som navnet antyder, scanner det kun indeksdatastrukturen. Der er yderligere to forudsætninger for at vælge kun indeksscanning sammenlignet med indeksscanning:
- Forespørgslen skal kun hente nøglekolonner, som er en del af indekset.
- Alle tupler (poster) på den valgte heap-side skal være synlige. Som diskuteret i det foregående afsnit opretholder indeksdatastrukturen ikke synlighedsoplysninger, så for kun at vælge data fra indekset bør vi undgå at tjekke for synlighed, og dette kan ske, hvis alle data på den side anses for at være synlige.
Følgende forespørgsel vil resultere i en kun indeksscanning. Selvom denne forespørgsel er næsten ens med hensyn til valg af antal poster, men da kun nøglefelt (dvs. "num") bliver valgt, vil den vælge kun indeksscanning.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Bitmap-scanning
Bitmapscanning er en blanding af indeksscanning og sekventiel scanning. Det forsøger at løse ulempen ved Index-scanning, men bevarer stadig sin fulde fordel. Som diskuteret ovenfor for hver data, der findes i indeksdatastrukturen, skal den finde tilsvarende data på heap-siden. Så alternativt skal den hente indekssiden én gang og derefter efterfulgt af heap-side, hvilket forårsager en masse tilfældig I/O. Så bitmap-scanningsmetoden udnytter fordelen ved indeksscanning uden tilfældig I/O. Dette fungerer i to niveauer som nedenfor:
- Bitmap Index Scan:Først henter den alle indeksdata fra indeksdatastrukturen og opretter et bitmap over alle TID. For en nem forståelse kan du overveje, at denne bitmap indeholder en hash af alle sider (hashed baseret på side nr.), og hver sideindgang indeholder en matrix af alle forskydninger på denne side.
- Bitmap Heap Scan:Som navnet antyder, læser den gennem bitmap af sider og scanner derefter data fra heap svarende til lagret side og offset. Til sidst tjekker den for synlighed og prædikat osv. og returnerer tuple baseret på resultatet af alle disse kontroller.
Nedenstående forespørgsel vil resultere i Bitmap-scanning, da den ikke vælger meget få poster (dvs. for meget til indeksscanning) og samtidig ikke vælger et stort antal poster (dvs. for lidt til en sekventiel scan).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Overvej nu nedenstående forespørgsel, som vælger det samme antal poster, men kun nøglefelter (dvs. kun indekskolonner). Da den kun vælger nøgle, behøver den ikke at henvise til heap-sider for andre dele af data, og der er derfor ingen tilfældig I/O involveret. Så denne forespørgsel vil vælge kun indeksscanning i stedet for bitmapscanning.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)TID-scanning
TID, som nævnt ovenfor, er 6 bytes tal, som består af 4-bytes sidetal og resterende 2 bytes tupelindeks inde på siden. TID-scanning er en meget specifik form for scanning i PostgreSQL og bliver kun valgt, hvis der er TID i forespørgselsprædikatet. Overvej nedenstående forespørgsel, der demonstrerer TID-scanningen:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Så her i prædikatet, i stedet for at angive en nøjagtig værdi af kolonnen som betingelse, er TID angivet. Dette er noget, der ligner ROWID-baseret søgning i Oracle.
Bonus
Alle scanningsmetoderne er meget udbredte og berømte. Disse scanningsmetoder er også tilgængelige i næsten alle relationelle databaser. Men der er en anden scanningsmetode for nylig i diskussion i PostgreSQL-fællesskabet og også for nylig tilføjet i andre relationelle databaser. Det hedder "Loose IndexScan" i MySQL, "Index Skip Scan" i Oracle og "Jump Scan" i DB2.
Denne scanningsmetode bruges til et specifikt scenarie, hvor der er valgt en særskilt værdi for den førende nøglekolonne i B-Tree-indekset. Som en del af denne scanning undgår den at krydse alle ens nøglekolonneværdier i stedet for blot at krydse den første unikke værdi og derefter springe til den næste store.
Dette arbejde er stadig i gang i PostgreSQL med det foreløbige navn som "Index Skip Scan", og vi kan forvente at se dette i en fremtidig udgivelse.