Hos Stack Overflow har vi nogle tabeller, der bruger klyngede kolonnelagerindekser, og disse fungerer fremragende til størstedelen af vores arbejdsbyrde. Men vi stødte for nylig på en situation, hvor "perfekte storme" - flere processer, der alle forsøgte at slette fra den samme CCI - ville overvælde CPU'en, da de alle gik bredt parallelt og kæmpede for at fuldføre deres operation. Sådan så det ud i SolarWinds SQL Sentry:
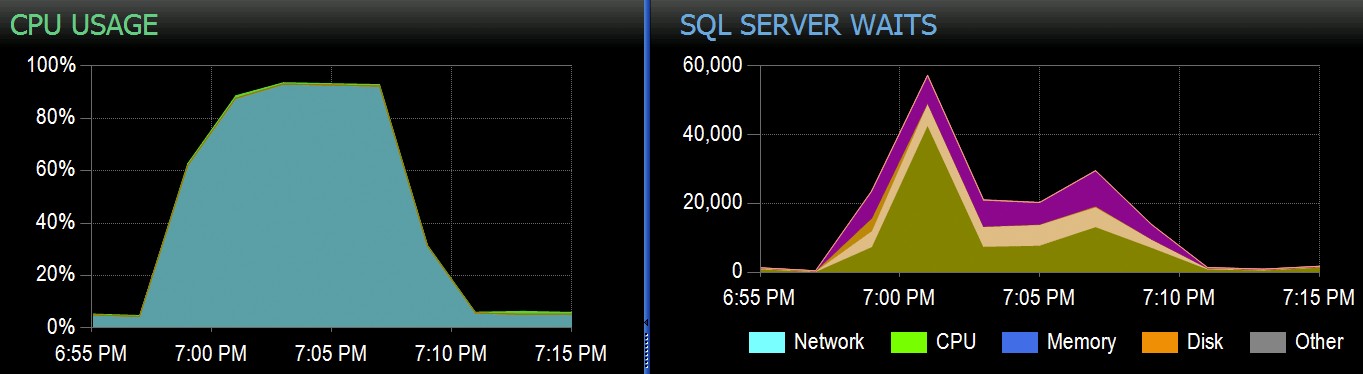
Og her er de interessante ventetider forbundet med disse forespørgsler:
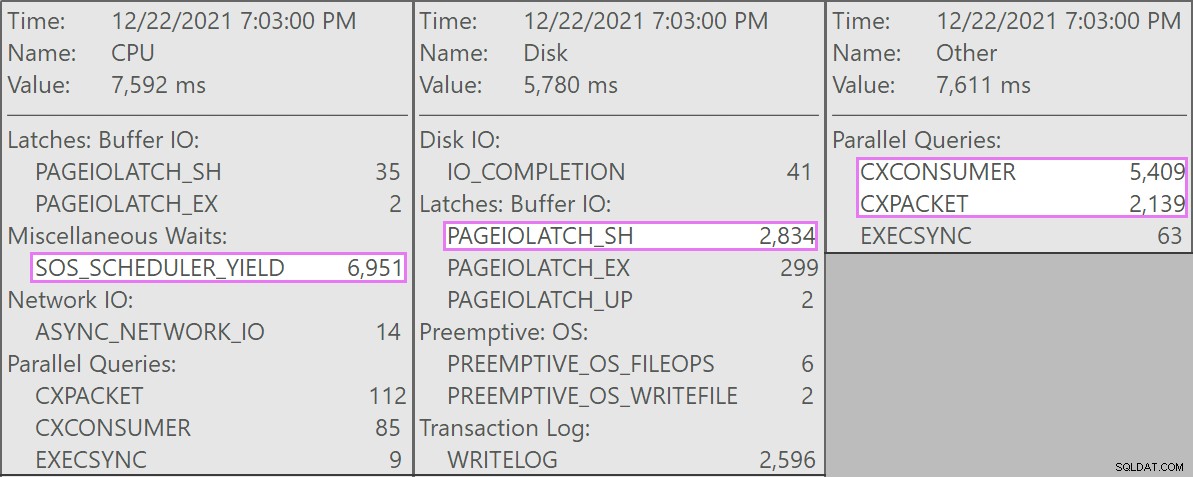
De konkurrerende forespørgsler var alle af denne form:
SLET dbo.LargeColumnstoreTable WHERE col1 =@p1 OG col2 =@p2;
Planen så således ud:

Og advarslen på scanningen advarede os om nogle ret ekstreme resterende I/O:

Tabellen har 1,9 milliarder rækker, men er kun 32 GB (tak, søjleformet lagerplads!). Alligevel ville disse sletninger på én række tage 10-15 sekunder hver, hvor det meste af denne tid blev brugt på SOS_SCHEDULER_YIELD .
Heldigvis, da sletningsoperationen i dette scenarie kunne være asynkron, var vi i stand til at løse problemet med to ændringer (selvom jeg oversimplifiserer groft her):
- Vi begrænsede
MAXDOPpå databaseniveau, så disse sletninger kan ikke gå helt så parallelt - Vi forbedrede serialiseringen af processerne, der kommer fra applikationen (i grunden satte vi sletninger i kø gennem en enkelt afsender)
Som DBA kan vi nemt styre MAXDOP , medmindre det er tilsidesat på forespørgselsniveau (endnu et kaninhul for en anden dag). Vi kan ikke nødvendigvis kontrollere applikationen i dette omfang, især hvis den er distribueret eller ikke vores. Hvordan kan vi serialisere skrivningerne i dette tilfælde uden at ændre applikationslogikken drastisk?
En mock-opsætning
Jeg har ikke tænkt mig at forsøge at oprette en tabel med to milliarder rækker lokalt – pyt med den nøjagtige tabel – men vi kan tilnærme noget på en mindre skala og forsøge at genskabe det samme problem.
Lad os foregive, at dette er SuggestedEdits bord (i virkeligheden er det ikke). Men det er et nemt eksempel at bruge, fordi vi kan trække skemaet fra Stack Exchange Data Explorer. Ved at bruge dette som en base kan vi oprette en tilsvarende tabel (med et par mindre ændringer for at gøre det nemmere at udfylde) og smide et klynget kolonnelagerindeks på det:
CREATE TABLE dbo.FakeSuggestedEdits( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Kommentar nvarchar (800) NOT NULL DEFAULT NEWID(), Tekst nvarchar (max) NOT NULL DEFAULT NEWID(), Title 0 nvarchar NOT DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID entydigt id NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE);
For at udfylde den med 100 millioner rækker, kan vi krydsforbinde sys.all_objects og sys.all_columns fem gange (på mit system vil dette producere 2,68 millioner rækker hver gang, men YMMV):
-- 2680350 * 5 ~ 3 minutter INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FRA sys.all_objects AS o CROSS JOIN sys.columns AS c;GO 5>Derefter kan vi tjekke pladsen:
EXEC sys.sp_spaceused @objname =N'dbo.FakeSuggestedEdits';Det er kun 1,3 GB, men dette burde være tilstrækkeligt:
Efterligner vores Clustered Column Store Slet
Her er en simpel forespørgsel, der nogenlunde matcher, hvad vores applikation gjorde med bordet:
DECLARE @p1 int =ABS(CHECKSUM(NEWID())) % 10000000, @p2 int =7;DELETE dbo.FakeSuggestedEdits WHERE Id =@p1 AND OwnerUserId =@p2;Planen er dog ikke helt et perfekt match:
For at få det til at gå parallelt og producere lignende påstande på min sparsomme bærbare computer, var jeg nødt til at tvinge optimizeren lidt med dette tip:
MULIGHED (QUERYTRACEON 8649);Nu ser det rigtigt ud:
Gengivelse af problemet
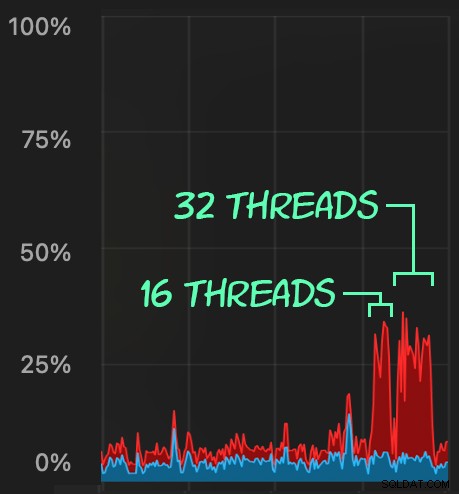
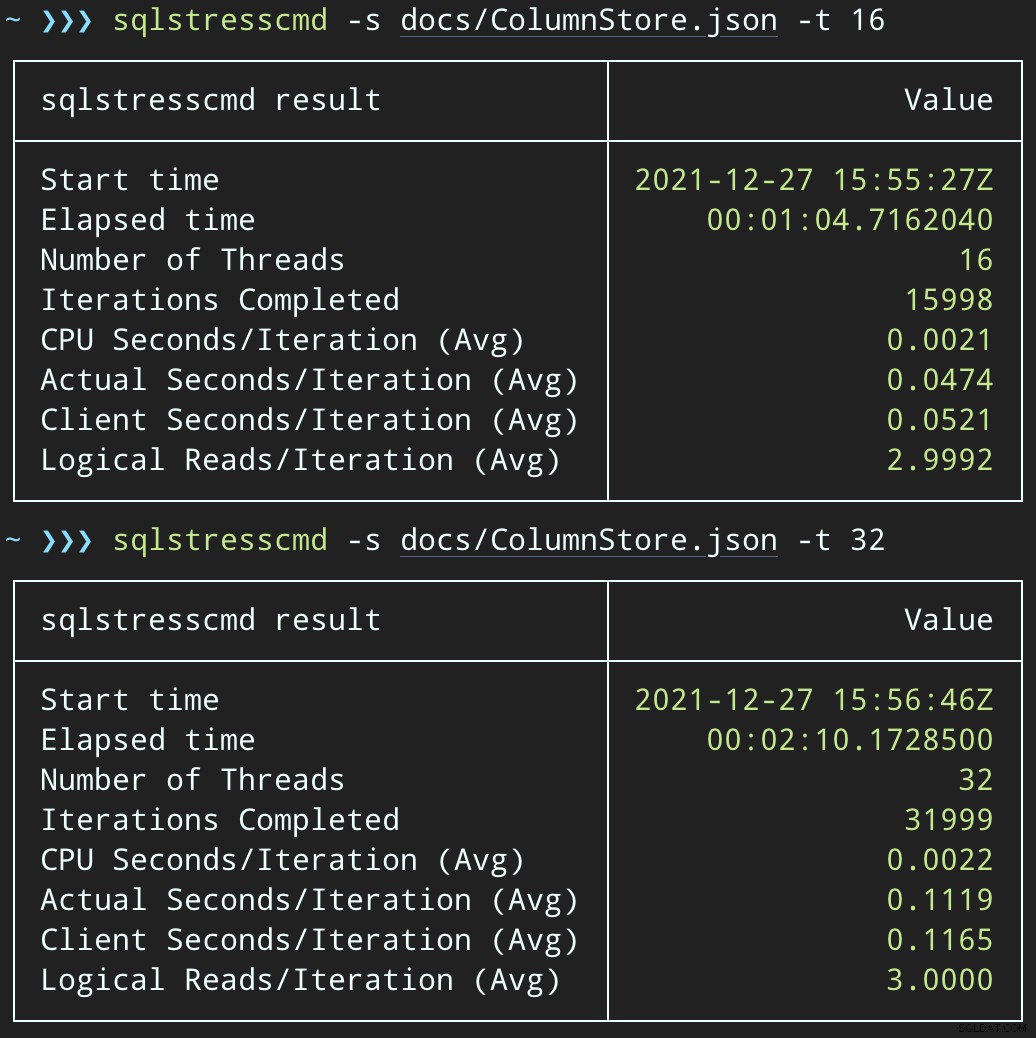
Derefter kan vi skabe en bølge af samtidig sletteaktivitet ved at bruge SqlStressCmd til at slette 1.000 tilfældige rækker ved hjælp af 16 og 32 tråde:
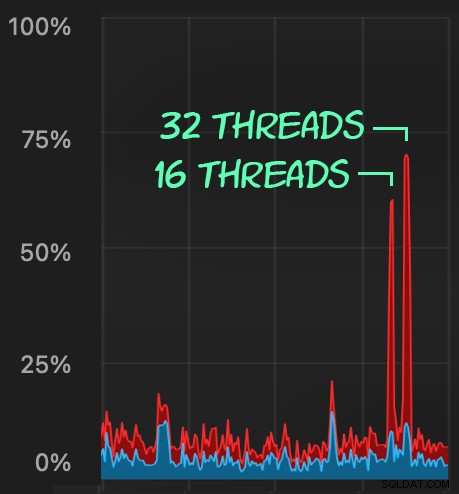
sqlstresscmd -s docs/ColumnStore.json -t 16sqlstresscmd -s docs/ColumnStore.json -t 32Vi kan observere den belastning, dette påfører CPU:
Belastningen på CPU varer i hele batchene på henholdsvis omkring 64 og 130 sekunder:
Bemærk:Outputtet fra SQLQueryStress er nogle gange lidt ude af iterationer, men jeg har bekræftet, at det arbejde, du beder den om at udføre, bliver udført præcist.
En potentiel løsning:En slettekø
Til at begynde med tænkte jeg på at introducere en køtabel i databasen, som vi kunne bruge til at aflaste sletteaktivitet:
CREATE TABLE dbo.SuggestedEditDeleteQueue( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerpreUserId in);Alt, hvad vi behøver, er en I STEDET FOR trigger til at opsnappe disse useriøse sletninger, der kommer fra applikationen, og placere dem i køen til baggrundsbehandling. Desværre kan du ikke oprette en trigger på en tabel med et klynget kolonnelagerindeks:
Msg 35358, Level 16, State 1
CREATE TRIGGER på tabellen 'dbo.FakeSuggestedEdits' mislykkedes, fordi du ikke kan oprette en trigger på en tabel med et klynget kolonnelagerindeks. Overvej at håndhæve logikken i triggeren på en anden måde, eller hvis du skal bruge en trigger, så brug i stedet et heap- eller B-tree-indeks.Vi har brug for en minimal ændring af applikationskoden, så den kalder en lagret procedure til at håndtere sletningen:
OPRET PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId intASBEGIN SET NOCOUNT ON; SLET dbo.FakeSuggestedEdits WHERE Id =@Id OG OwnerUserId =@OwnerUserId;ENDDette er ikke en permanent tilstand; dette er blot for at holde adfærden den samme, mens du kun ændrer én ting i appen. Når appen er ændret og kalder denne lagrede procedure i stedet for at sende ad hoc-sletteforespørgsler, kan den lagrede procedure ændres:
OPRET PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId intASBEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId;ENDTest virkningen af køen
Nu, hvis vi ændrer SqlQueryStress til at kalde den lagrede procedure i stedet:
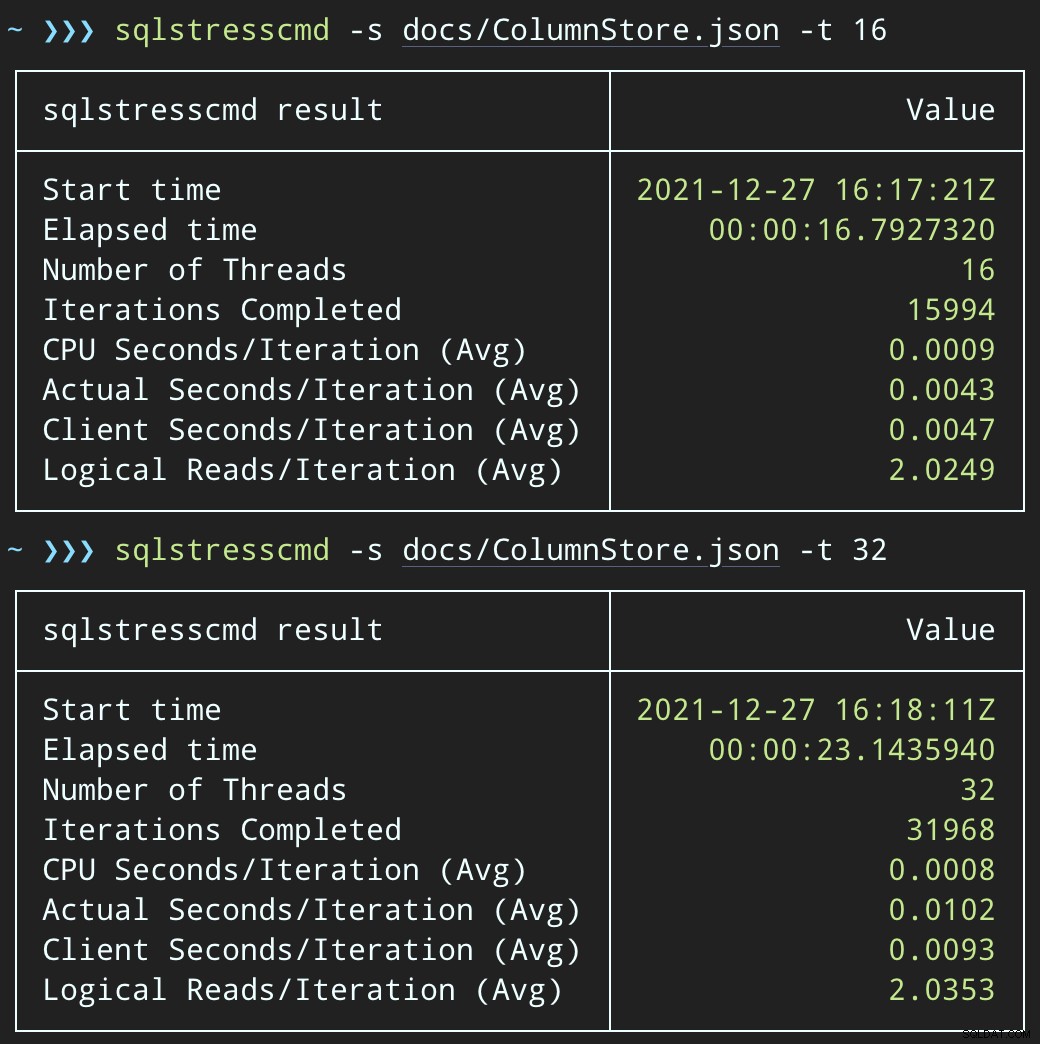
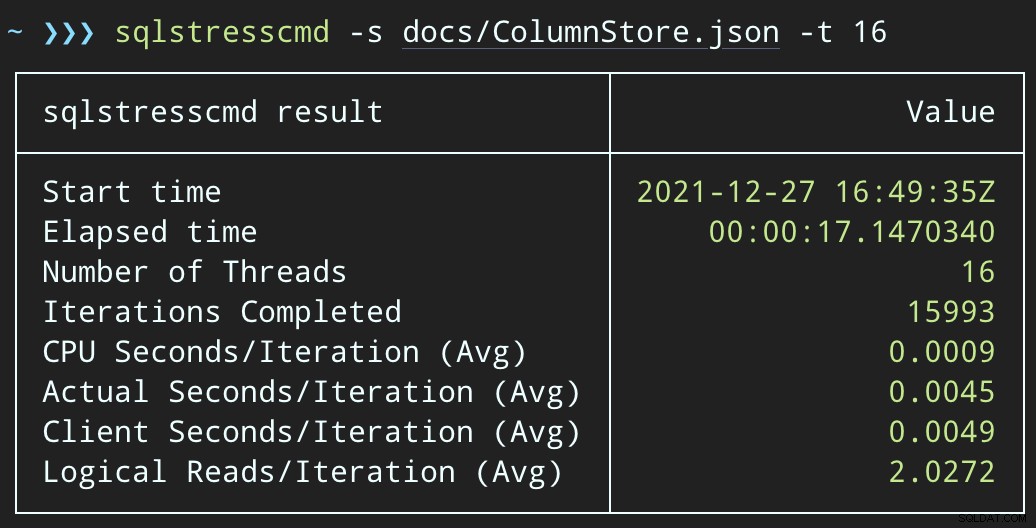
DECLARE @p1 int =ABS(CHECKSUM(NEWID())) % 10000000, @p2 int =7;EXEC dbo.DeleteSuggestedEdit @Id =@p1, @OwnerUserId =@p2;Og indsend lignende batches (anbring 16K eller 32K rækker i køen):
DECLARE @p1 int =ABS(CHECKSUM(NEWID())) % 10000000, @p2 int =7;EXEC dbo.@Id =@p1 OG OwnerUserId =@p2;CPU-påvirkningen er lidt højere:
Men arbejdsbelastningerne slutter meget hurtigere — henholdsvis 16 og 23 sekunder:
Dette er en betydelig reduktion af smerten, som applikationerne vil føle, når de kommer ind i perioder med høj samtidighed.
Vi er stadig nødt til at udføre sletningen, selvom
Vi skal stadig behandle disse sletninger i baggrunden, men vi kan nu indføre batching og have fuld kontrol over hastigheden og eventuelle forsinkelser, vi ønsker at injicere mellem operationerne. Her er den helt grundlæggende struktur for en lagret procedure til at behandle køen (ganske vist uden fuldt overdraget transaktionskontrol, fejlhåndtering eller oprydning af køtabel):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue @JobSize int =10000, @BatchSize int =100, @DelayInSeconds int =2 -- skal være mellem 1 og 59ASBEGIN SET NOCOUNT ON; DECLARE @d TABLE(Id int, OwnerUserId int); DECLARE @rc int =1, @jc int =0, @wf nvarchar(100) =N'WAITFOR DELAY ' + CHAR(39) + '00:00:' + RIGHT('0' + CONVERT(varchar(2) , @DelayInSeconds), 2) + CHAR(39); MENS @rc> 0 OG @jc <@JobSize BEGIN SLET @d; OPDATERING TOP (@BatchSize) q SET ProcessedDate =sysdatetime() OUTPUT inserted.Id, inserted.OwnerUserId INTO @d FRA dbo.SuggestedEditDeleteQueue SOM q MED (UPDLOCK, READPAST) WHERE ER ProcessedDate; SET @rc =@@ RÆKEL; HVIS @rc =0 BREAK; SLET fse FRA dbo.FakeSuggestedEdits AS fse INNER JOIN @d AS d PÅ fse.Id =d.Id OG fse.OwnerUserId =d.OwnerUserId; SET @jc +=@rc; HVIS @jc> @JobSize BREAK; EXEC sys.sp_executesql @wf; END RAISERROR('Slettede %d rækker.', 0, 1, @jc) MED NUWAIT;ENDNu vil det tage længere tid at slette rækker - gennemsnittet for 10.000 rækker er 223 sekunder, hvoraf ~100 er bevidst forsinkelse. Men ingen bruger venter, så hvem bekymrer sig? CPU-profilen er næsten nul, og appen kan fortsætte med at tilføje elementer i køen så meget samtidig, som den vil, med næsten ingen konflikt med baggrundsjobbet. Mens jeg behandlede 10.000 rækker, tilføjede jeg yderligere 16.000 rækker til køen, og den brugte den samme CPU som før - det tog kun et sekund længere, end da jobbet ikke kørte:
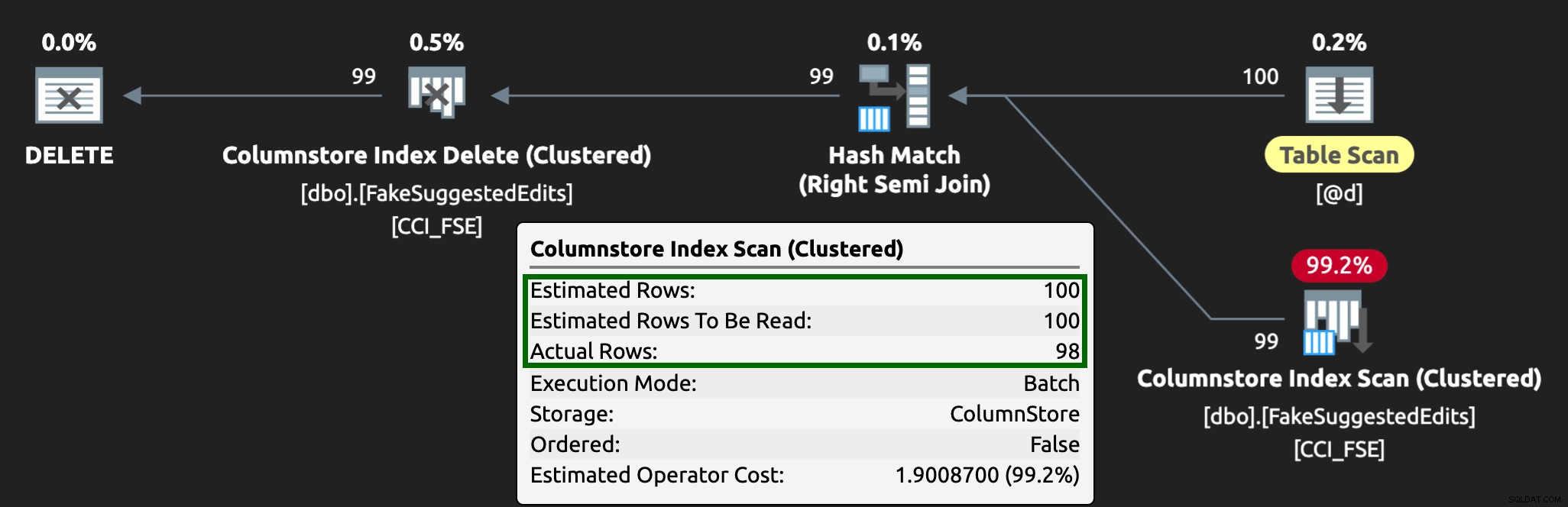
Og planen ser nu sådan ud med meget bedre estimerede / faktiske rækker:
Jeg kan se, at denne køtabeltilgang er en effektiv måde at håndtere høj DML samtidighed på, men den kræver i det mindste en lille smule fleksibilitet med de applikationer, der indsender DML - dette er en af grundene til, at jeg virkelig godt kan lide, at applikationer kalder lagrede procedurer, da de give os meget mere kontrol tættere på dataene.
Andre muligheder
Hvis du ikke har mulighed for at ændre sletteforespørgslerne fra applikationen - eller hvis du ikke kan udskyde sletningerne til en baggrundsproces - kan du overveje andre muligheder for at reducere virkningen af sletningerne:

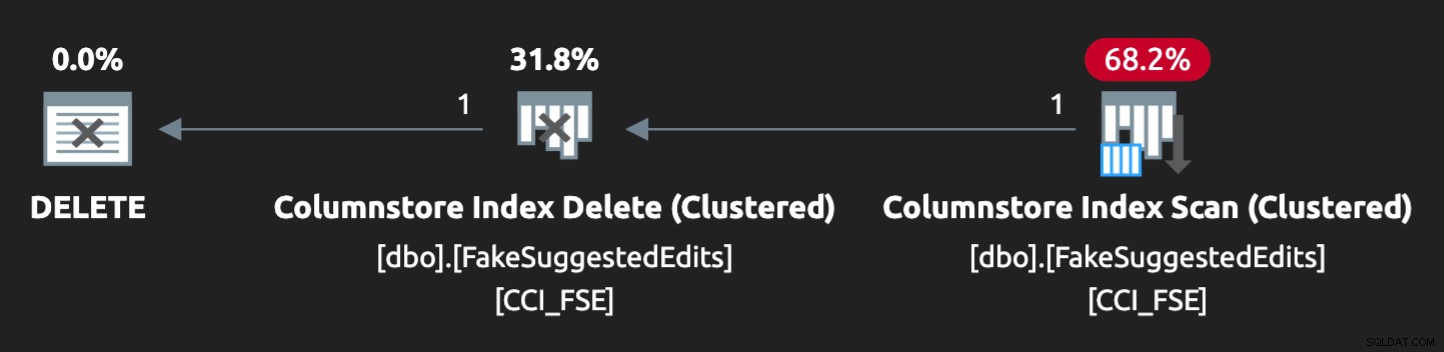

- Et ikke-klynget indeks på prædikatkolonnerne for at understøtte punktopslag (vi kan gøre dette isoleret uden at ændre applikationen)
- Kun brug af bløde sletninger (kræver stadig ændringer af applikationen)
Det bliver interessant at se, om disse muligheder tilbyder lignende fordele, men jeg gemmer dem til et fremtidigt indlæg.