[ Del 1 | Del 2 | Del 3 | Del 4 ]
Der er skrevet meget gennem årene om at forstå og optimere SELECT forespørgsler, men snarere mindre om dataændring. Denne serie af indlæg ser på et problem, der er specifikt for INSERT , OPDATERING , SLET og FLET forespørgsler – Halloween-problemet.
Udtrykket "Halloween Problem" blev oprindeligt opfundet med henvisning til en SQL OPDATERING forespørgsel, der skulle give en forhøjelse på 10 % til hver medarbejder, der tjente mindre end $25.000. Problemet var, at forespørgslen blev ved med at give 10 % forhøjelser indtil alle tjent mindst $25.000. Vi vil se senere i denne serie, at det underliggende problem også gælder for INSERT , SLET og FLET forespørgsler, men for denne første post vil det være nyttigt at undersøge OPDATERING problem i en smule detaljer.
Baggrund
SQL-sproget giver brugere mulighed for at specificere databaseændringer ved hjælp af en OPDATERING sætning, men syntaksen siger intet om hvordan databasemotoren skal udføre ændringerne. På den anden side specificerer SQL-standarden, at resultatet af en OPDATERING skal være det samme, som hvis det var blevet udført i tre separate og ikke-overlappende faser:
- En skrivebeskyttet søgning bestemmer de poster, der skal ændres, og de nye kolonneværdier
- Ændringer anvendes på berørte poster
- Databasekonsistensbegrænsninger er verificeret
At implementere disse tre faser bogstaveligt i en databasemotor ville give korrekte resultater, men ydeevnen er måske ikke særlig god. De mellemliggende resultater på hvert trin vil kræve systemhukommelse, hvilket reducerer antallet af forespørgsler, som systemet kan udføre samtidigt. Den nødvendige hukommelse kan også overstige det, der er tilgængeligt, hvilket kræver, at mindst en del af opdateringssættet skrives ud til disklageret og læses igen senere. Sidst, men ikke mindst, skal hver række i tabellen røres flere gange under denne udførelsesmodel.
En alternativ strategi er at behandle OPDATERING en række ad gangen. Dette har den fordel, at det kun berører hver række én gang og kræver generelt ikke hukommelse til lagring (selvom nogle operationer, som en fuld sortering, skal behandle det fulde inputsæt, før den første række af output produceres). Denne iterative model er den, der bruges af SQL Server-forespørgselsudførelsesmotoren.
Udfordringen for forespørgselsoptimeringsværktøjet er at finde en iterativ (række for række) eksekveringsplan, der opfylder OPDATERING semantik, der kræves af SQL-standarden, samtidig med at ydeevnen og samtidighedsfordelene ved pipelinet eksekvering bevares.
Opdateringsbehandling
For at illustrere det oprindelige problem vil vi anvende en forhøjelse på 10 % til hver medarbejder, der tjener mindre end $25.000 ved at bruge Medarbejdere tabel nedenfor:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Tre-faset opdateringsstrategi
Den skrivebeskyttede første fase finder alle de poster, der opfylder WHERE klausulprædikat og gemmer nok information til, at den anden fase kan udføre sit arbejde. I praksis betyder det, at der registreres en unik identifikator for hver kvalificerende række (de klyngede indeksnøgler eller heap-række-id) og den nye lønværdi. Når første fase er afsluttet, overføres hele sættet af opdateringsoplysninger til den anden fase, som lokaliserer hver post, der skal opdateres, ved hjælp af den unikke identifikator og ændrer lønnen til den nye værdi. Den tredje fase kontrollerer derefter, at ingen databaseintegritetsbegrænsninger er overtrådt af tabellens endelige tilstand.
Iterativ strategi
Denne tilgang læser en række ad gangen fra kildetabellen. Hvis rækken opfylder WHERE klausulprædikat anvendes lønforhøjelsen. Denne proces gentages, indtil alle rækker er blevet behandlet fra kilden. Et eksempel på en eksekveringsplan ved hjælp af denne model er vist nedenfor:

Som det er sædvanligt for SQL Servers efterspørgselsdrevne pipeline, starter eksekveringen ved operatøren længst til venstre –
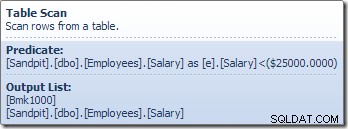
Tabelscanningsoperatøren læser rækker én ad gangen fra lagermotoren, indtil den finder én, der opfylder lønprædikatet. Outputlisten i grafikken ovenfor viser tabelscanningsoperatøren, der returnerer en række-id og den aktuelle værdi af kolonnen Løn for denne række. En enkelt række, der indeholder referencer til disse to oplysninger, sendes videre til Compute Scalar:
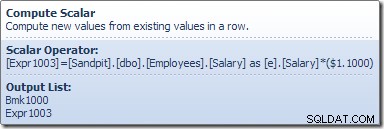
Compute Scalar definerer et udtryk, der anvender lønstigningen på den aktuelle række. Den returnerer en række, der indeholder referencer til række-id'et og den ændrede løn til tabelopdateringen, som kalder lagermotoren til at udføre dataændringen. Denne iterative proces fortsætter, indtil tabelscanningen løber tør for rækker. Den samme grundlæggende proces følges, hvis tabellen har et klynget indeks:
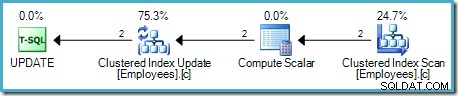
Den væsentligste forskel er, at de grupperede indeksnøgler og uniquifier (hvis de findes) bruges som rækkeidentifikation i stedet for en heap RID.
Problemet
Skiftet fra den logiske trefasede operation defineret i SQL-standarden til den fysiske iterative udførelsesmodel har introduceret en række subtile ændringer, hvoraf kun én vi skal se på i dag. Der kan opstå et problem i vores kørende eksempel, hvis der er et ikke-klynget indeks i kolonnen Løn, som forespørgselsoptimeringsværktøjet beslutter at bruge til at finde rækker, der kvalificerer sig (Løn <$25.000):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Række-for-række-udførelsesmodellen kan nu producere forkerte resultater eller endda komme ind i en uendelig løkke. Overvej en (imaginær) iterativ eksekveringsplan, der søger efter lønindekset, returnerer en række ad gangen til Compute Scalar og i sidste ende videre til opdateringsoperatøren:

Der er et par ekstra Compute Scalars i denne plan på grund af en optimering, der springer ikke-klyngede indeksvedligeholdelse over, hvis lønværdien ikke er ændret (kun muligt for en nulløn i dette tilfælde).
Når man ignorerer det, er det vigtige træk ved denne plan, at vi nu har en bestilt delvis indeksscanning, der sender en række ad gangen til en operatør, der ændrer det samme indeks (den grønne fremhævning i SQL Sentry Plan Explorer-grafikken ovenfor gør det klart, at Clustered Indeksopdateringsoperatøren vedligeholder både basistabellen og det ikke-klyngede indeks).
Problemet er i hvert fald, at opdateringen ved at behandle en række ad gangen kan flytte den aktuelle række foran scanningspositionen, der bruges af Index Seek til at finde rækker, der skal ændres. At arbejde gennem eksemplet burde gøre denne udtalelse en smule klarere:
Det ikke-klyngede indeks tastes og sorteres stigende efter lønværdien. Indekset indeholder også en pointer til den overordnede række i basistabellen (enten en heap RID eller de klyngede indeksnøgler plus uniquifier, hvis det er nødvendigt). For at gøre eksemplet nemmere at følge, antag, at basistabellen nu har et unikt klynget indeks i kolonnen Navn, så det ikke-klyngede indeksindhold ved starten af opdateringsbehandlingen er:
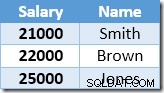
Den første række, der returneres af Index Seek, er lønnen på $21.000 for Smith. Denne værdi opdateres til $23.100 i basistabellen og det ikke-klyngede indeks af Clustered Index-operatoren. Det ikke-klyngede indeks indeholder nu:
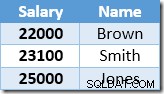
Den næste række, der returneres af Index Seek, vil være $22.000-indgangen for Brown, som er opdateret til $24.200:
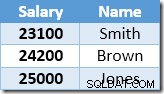
Nu finder Index Seek værdien på $23.100 for Smith, som opdateres igen , til $25.410. Denne proces fortsætter, indtil alle medarbejdere har en løn på mindst $25.000 – hvilket ikke er et korrekt resultat for den givne OPDATERING forespørgsel. Den samme effekt under andre omstændigheder kan føre til en løbsk opdatering, som kun stopper, når serveren løber tør for logplads, eller der opstår en overløbsfejl (det kunne forekomme i dette tilfælde, hvis nogen havde en nulløn). Dette er Halloween-problemet, da det gælder for opdateringer.
Undgå Halloween-problemet for opdateringer
Ørneøjede læsere vil have bemærket, at de estimerede omkostningsprocenter i den imaginære Index Seek-plan ikke talte op til 100 %. Dette er ikke et problem med Plan Explorer – jeg fjernede bevidst en nøgleoperatør fra planen:

Forespørgselsoptimeringsværktøjet erkender, at denne pipelinede opdateringsplan er sårbar over for Halloween-problemet, og introducerer en Ivrig bordspole for at forhindre det i at opstå. Der er ingen antydning eller sporingsflag for at forhindre inklusion af spolen i denne udførelsesplan, fordi den er påkrævet for korrekthed.
Som navnet antyder, forbruger spolen ivrigt alle rækker fra dens underordnede operatør (indekssøgningen), før den returnerer en række til dens overordnede Compute Scalar. Effekten af dette er at indføre fuldstændig faseadskillelse – alle kvalificerende rækker læses og gemmes i et midlertidigt lager, før der udføres opdateringer.
Dette bringer os tættere på den trefasede logiske semantik af SQL-standarden, selvom planudførelsen stadig er grundlæggende iterativ, med operatorer til højre for spoolen, der danner læsemarkøren , og operatorer til venstre, der danner skrivemarkøren . Indholdet af spolen læses og behandles stadig række for række (det videregives ikke en masse som sammenligningen med SQL-standarden ellers kunne få dig til at tro).
Ulemperne ved faseadskillelsen er de samme som tidligere nævnt. Bordspolen bruger tempdb plads (sider i bufferpuljen) og kan kræve fysisk læsning og skrivning til disk under hukommelsestryk. Forespørgselsoptimeringsværktøjet tildeler en estimeret pris til spolen (med forbehold for alle de sædvanlige advarsler om estimeringer) og vil vælge mellem planer, der kræver beskyttelse mod Halloween-problemet versus dem, der ikke gør det på grundlag af estimerede omkostninger som normalt. Naturligvis kan optimeringsværktøjet forkert vælge mellem mulighederne af en af de normale årsager.
I dette tilfælde er afvejningen mellem effektivitetsforøgelsen ved at søge direkte til kvalificerende poster (dem med en løn <$25.000) i forhold til den anslåede pris på spolen, der kræves for at undgå Halloween-problemet. En alternativ plan (i dette specifikke tilfælde) er en fuld scanning af det klyngede indeks (eller heap). Denne strategi kræver ikke den samme Halloween-beskyttelse, fordi nøglerne af det klyngede indeks er ikke ændret:

Fordi indekstasterne er stabile, kan rækker ikke flytte position i indekset mellem iterationer, hvilket undgår Halloween-problemet i dette tilfælde. Afhængigt af driftsomkostningerne for Clustered Index Scan sammenlignet med Index Seek plus Eager Table Spool-kombinationen, som er set tidligere, kan den ene plan udføres hurtigere end den anden. En anden overvejelse er, at planen med Halloween Protection vil anskaffe flere låse end den fuldt udbyggede plan, og låsene vil blive holdt i længere tid.
Sidste tanker
Forståelse af Halloween-problemet og de virkninger, det kan have på dataændringsforespørgselsplaner, vil hjælpe dig med at analysere dataændrende eksekveringsplaner og kan tilbyde muligheder for at undgå omkostningerne og bivirkningerne ved unødvendig beskyttelse, hvor et alternativ er tilgængeligt.
Der er flere former for Halloween-problemet, som ikke alle er forårsaget af læsning og skrivning til nøglerne i et fælles indeks. Halloween-problemet er heller ikke begrænset til OPDATERING forespørgsler. Forespørgselsoptimeringsværktøjet har flere tricks i ærmet for at undgå Halloween-problemet bortset fra brute-force faseadskillelse ved hjælp af en Ivrig bordspole. Disse punkter (og flere) vil blive udforsket i de næste dele af denne serie.
[ Del 1 | Del 2 | Del 3 | Del 4 ]