I sidste måned dækkede jeg Peter Larssons puslespil med at matche udbud og efterspørgsel. Jeg viste Peters enkle markørbaserede løsning og forklarede, at den har lineær skalering. Udfordringen, jeg efterlod dig, er at prøve at finde en sæt-baseret løsning på opgaven, og dreng, har folk taget udfordringen op! Tak Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie og, selvfølgelig, Peter Larsson, for at sende jeres løsninger. Nogle af ideerne var geniale og direkte overvældende.
I denne måned vil jeg begynde at udforske de indsendte løsninger, groft sagt fra de dårligst ydende til de bedst ydende. Hvorfor overhovedet bøvle med de dårligt præsterende? For du kan stadig lære meget af dem; for eksempel ved at identificere anti-mønstre. Faktisk er det første forsøg på at løse denne udfordring for mange mennesker, inklusive mig selv og Peter, baseret på et interval skæringskoncept. Det sker, at den klassiske prædikatbaserede teknik til at identificere intervalskæringspunkter har dårlig ydeevne, da der ikke er noget godt indekseringsskema til at understøtte det. Denne artikel er dedikeret til denne dårligt ydende tilgang. På trods af den dårlige præstation er det en interessant øvelse at arbejde på løsningen. Det kræver, at man øver sig i at modellere problemet på en måde, der egner sig til sætbaseret behandling. Det er også interessant at identificere årsagen til den dårlige ydeevne, hvilket gør det lettere at undgå anti-mønsteret i fremtiden. Husk, denne løsning er kun udgangspunktet.
DDL og et lille sæt prøvedata
Som en påmindelse involverer opgaven at forespørge en tabel kaldet "Auktioner." Brug følgende kode til at oprette tabellen og udfylde den med et lille sæt eksempeldata:
DROP TABEL HVIS FINDER dbo.Auktioner; OPRET TABEL dbo.Auctions( ID INT IKKE NULL IDENTITET(1, 1) BEGRÆNSNING pk_Auctions PRIMÆR NØGLE KLUSTERET, Kode CHAR(1) IKKE NULL BEGRÆNSNING ck_Auctions_Code CHECK (Kode ='D' ELLER Kode ='S'), Mængde (19 DECIMAL) , 6) NOT NULL CONSTRAINT ck_Auctions_Quantity CHECK (Quantity> 0)); SÆT ANTAL TIL; SLET FRA dbo.Auktioner; SET IDENTITY_INSERT dbo.Auktioner TIL; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2,0); SET IDENTITY_INSERT dbo.Auktioner FRA;
Din opgave var at oprette parringer, der matcher udbud og efterspørgselsindtastninger baseret på ID-bestilling, ved at skrive dem til en midlertidig tabel. Følgende er det ønskede resultat for det lille sæt eksempeldata:
DemandID SupplyID TradeQuantity---------------------------------------------1 1000 5,0000002 1000 3,0000003 2000 6,0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Sidste måned leverede jeg også kode, som du kan bruge til at udfylde auktionstabellen med et stort sæt eksempeldata, der kontrollerer antallet af udbuds- og efterspørgselsposter samt deres rækkevidde af mængder. Sørg for at bruge koden fra sidste måneds artikel til at kontrollere løsningernes ydeevne.
Modellering af data som intervaller
En spændende idé, der egner sig til at understøtte sæt-baserede løsninger, er at modellere dataene som intervaller. Med andre ord, repræsentere hver efterspørgsels- og udbudspost som et interval, der starter med de løbende samlede mængder af samme art (efterspørgsel eller udbud) op til men eksklusive den aktuelle, og slutter med den løbende total inklusive den nuværende, naturligvis baseret på ID bestilling. Hvis man f.eks. ser på det lille sæt af prøvedata, er den første efterspørgselsindgang (ID 1) for en mængde på 5,0 og den anden (ID 2) er for en mængde på 3,0. Den første efterspørgselsindgang kan repræsenteres med intervalstart:0,0, slut:5,0, og den anden med intervalstart:5,0, slut:8,0 og så videre.
På samme måde kan den første udbudspost (ID 1000) er for en mængde på 8,0 og den anden (ID 2000) er for en mængde på 6,0. Den første forsyningspost kan repræsenteres med intervalstart:0,0, slut:8,0, og den anden med intervalstart:8,0, slut:14,0 og så videre.
De efterspørgsels-udbuds-parringer, du skal oprette, er så de overlappende segmenter af de skærende intervaller mellem de to typer.
Dette forstås nok bedst med en visuel afbildning af den intervalbaserede modellering af dataene og det ønskede resultat, som vist i figur 1.
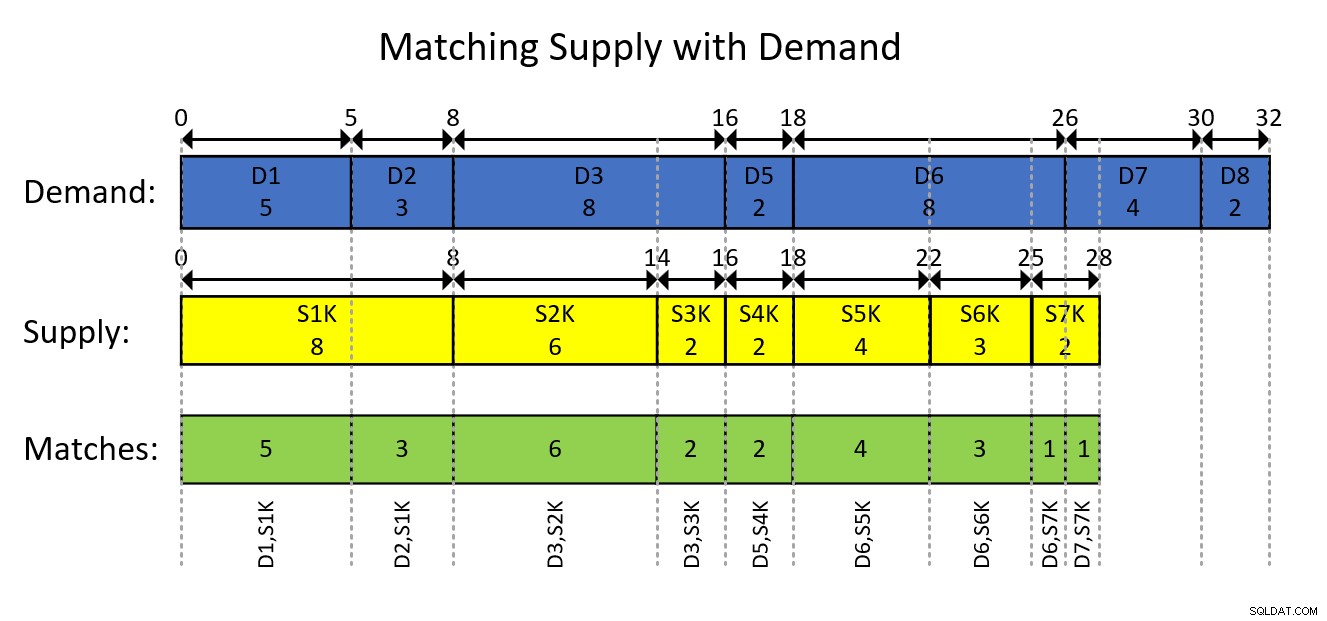 Figur 1:Modellering af data som intervaller
Figur 1:Modellering af data som intervaller
Den visuelle afbildning i figur 1 er ret selvforklarende, men kort sagt...
De blå rektangler repræsenterer efterspørgselsindtastningerne som intervaller, der viser de eksklusive løbende totalmængder som starten af intervallet og den inklusive løbende total som slutningen af intervallet. De gule rektangler gør det samme for forsyningsindtastninger. Læg derefter mærke til, hvordan de overlappende segmenter af de krydsende intervaller af de to slags, som er afbildet af de grønne rektangler, er de efterspørgsels-udbuds-parringer, du skal producere. For eksempel er den første resultatparring med efterspørgsels-ID 1, forsynings-ID 1000, mængde 5. Den anden resultatparring er med efterspørgsels-ID 2, forsynings-ID 1000, mængde 3. Og så videre.
Intervalkryds ved hjælp af CTE'er
Før du begynder at skrive T-SQL-koden med løsninger baseret på intervalmodelleringsideen, bør du allerede have en intuitiv fornemmelse for, hvilke indekser der sandsynligvis vil være nyttige her. Da du sandsynligvis vil bruge vinduesfunktioner til at beregne løbende totaler, kan du drage fordel af et dækkende indeks med en nøgle baseret på kolonnerne Kode, ID og inklusive kolonnen Antal. Her er koden til at oprette et sådant indeks:
OPRET UNIKT IKKE-KLUSTERET INDEX idx_Code_ID_i_Quantity PÅ dbo.Auctions(Code, ID) INCLUDE(Quantity);
Det er det samme indeks, som jeg anbefalede til den markørbaserede løsning, som jeg dækkede i sidste måned.
Her er der også potentiale for at drage fordel af batchbehandling. Du kan aktivere dens overvejelse uden kravene til batch-tilstand på rowstore, f.eks. ved at bruge SQL Server 2019 Enterprise eller nyere, ved at oprette følgende dummy columnstore-indeks:
OPRET IKKE-KLYNGERET COLUMNSTORE INDEX idx_cs PÅ dbo.Auctions(ID) WHERE ID =-1 OG ID =-2;
Du kan nu begynde at arbejde på løsningens T-SQL-kode.
Følgende kode opretter intervallerne, der repræsenterer efterspørgselsindtastningerne:
WITH D0 AS-- D0 beregner løbende efterspørgsel som EndDemand( SELECT ID, Quantity, SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand FROM dbo.Auktioner WHERE Code ='D'),-- D udtrækker forrige EndDemand som StartDemand, der udtrykker start-end-efterspørgsel som et intervalD AS( SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand FROM D0)SELECT *FROM D;
Forespørgslen, der definerer CTE D0, filtrerer efterspørgselsposter fra auktionstabellen og beregner en løbende total mængde som slutafgrænseren for efterspørgselsintervallerne. Derefter forespørger forespørgslen, der definerer den anden CTE kaldet D, D0 og beregner startadskilleren for efterspørgselsintervallerne ved at trække den aktuelle mængde fra slutadskilleren.
Denne kode genererer følgende output:
ID Antal StartDemand EndDemand---- ---------- ------------ ----------1 5,000000 0,000000 5,0000002 3,000000 5,000000 8,0000003 8,000000 8,000000 16,0000005 2,000000 16,000000 18,0000006 8,000000 18,000000 26,0000007 4,000000 26,00000 26,000 før 3000 000 26.000.Forsyningsintervallerne genereres meget ens ved at anvende den samme logik på forsyningsindtastningerne ved at bruge følgende kode:
WITH S0 AS-- S0 beregner kørende forsyning som EndSupply( SELECT ID, Quantity, SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply FRA dbo.Auctions WHERE Code ='S'),-- S udtrækker forrige EndSupply som StartSupply, der udtrykker start-end-forsyning som et intervalS AS( SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply FROM S0)SELECT *FROM S;Denne kode genererer følgende output:
ID Antal StartSupply EndSupply----- ---------- ------------ ----------1000 8,000000 0,000000 8,0000002000 6,000000 8,000000 14,0000003000 2.000000 14.000000 16.0000004000 2.000000 16.000000 18.0000005000 4.000000 18.000000 22.0000006000 3.000000 22.000000 25.0000007000 2.000000 25.000000 27.000000Det, der er tilbage, er så at identificere de krydsende efterspørgsels- og udbudsintervaller fra CTE'erne D og S og beregne de overlappende segmenter af disse skærende intervaller. Husk at resultatparringerne skal skrives ind i en midlertidig tabel. Dette kan gøres ved hjælp af følgende kode:
-- Drop temp-tabel, hvis den findes. WITH D0 AS-- D0 beregner løbende efterspørgsel som EndDemand( SELECT ID, Quantity, SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand FRA dbo.Auktioner WHERE Code ='D'),-- D udtræk prev EndDemand som StartDemand, der udtrykker start-end-efterspørgsel som et intervalD AS( SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand FROM D0),S0 AS-- S0 beregner kørende forsyning som EndSupply( SELECT ID, Quantity, SUM(Quantity) OVER (ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply FRA dbo.Auctions WHERE Code ='S'),-- S-udtræk prev EndSupply som StartSupply, der udtrykker start-end-forsyning som et intervalS AS( SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply FRA S0)-- Ydre forespørgsel identificerer handler som de overlappende segmenter af de skærende intervaller-- I de krydsende efterspørgsels- og udbudsintervaller er handelsmængden da -- MINST(EndDemand, EndSupply) - GREATEST(StartDemsnad, StartSupply)SELECT D.ID AS DemandID, S.ID AS SupplyID, CASE WH EN EndDemandStartSupply THEN StartDemand ELSE StartSupply END AS TradeQuantityINTO #MyPairingsFROM D INNER JOIN S ON D.StartDemand S. Udover koden, der skaber efterspørgsels- og udbudsintervallerne, som du allerede så tidligere, er den vigtigste tilføjelse her den ydre forespørgsel, som identificerer de skærende intervaller mellem D og S og beregner de overlappende segmenter. For at identificere de skærende intervaller forbinder den ydre forespørgsel D og S ved hjælp af følgende joinprædikat:
D.StartDemandS.StartSupply Det er det klassiske prædikat til at identificere interval skæringspunkter. Det er også hovedkilden til løsningens dårlige ydeevne, som jeg snart vil forklare.
Den ydre forespørgsel beregner også handelsmængden i SELECT-listen som:
MINST(EndDemand, EndSupply) - GREATEST(StartDemand, StartSupply)Hvis du bruger Azure SQL, kan du bruge dette udtryk. Hvis du bruger SQL Server 2019 eller tidligere, kan du bruge følgende logisk ækvivalente alternativ:
CASE WHEN EndDemandStartSupply THEN StartDemand ELSE StartSupply END Da kravet var at skrive resultatet ind i en midlertidig tabel, bruger den ydre forespørgsel en SELECT INTO-sætning til at opnå dette.
Ideen med at modellere dataene som intervaller er klart spændende og elegant. Men hvad med ydeevnen? Desværre har denne specifikke løsning et stort problem relateret til, hvordan interval skæringspunktet identificeres. Undersøg planen for denne løsning vist i figur 2.
Figur 2:Forespørgselsplan for vejkryds ved hjælp af CTE-løsning
Lad os starte med de billige dele af planen.
Den ydre input af Nested Loops join beregner efterspørgselsintervallerne. Den bruger en Index Seek-operator til at hente efterspørgselsposterne og en batch-mode Window Aggregate-operator til at beregne efterspørgselsintervallets slutadskiller (omtalt som Expr1005 i denne plan). Efterspørgselsinterval startadskilleren er så Udtr1005 – Antal (fra D).
Som en sidebemærkning kan du måske finde brugen af en eksplicit sorteringsoperator før batch-tilstanden Window Aggregate-operator overraskende her, eftersom de efterspørgselsposter, der hentes fra indekssøgningen, allerede er sorteret efter ID, som vinduesfunktionen skal have dem til. Dette har at gøre med det faktum, at SQL Server i øjeblikket ikke understøtter en effektiv kombination af parallel ordrebevarende indeksoperation forud for en parallel batch-tilstand Window Aggregate-operator. Hvis du tvinger en seriel plan kun til eksperimenterende formål, vil du se sorteringsoperatoren forsvinde. SQL Server besluttede generelt, at brugen af parallelisme her var foretrukket, på trods af at det resulterede i den ekstra eksplicitte sortering. Men igen, denne del af planen repræsenterer en lille del af arbejdet i den store sammenhæng.
På samme måde starter det indre input af Nested Loops-sammenføjningen med at beregne forsyningsintervallerne. Mærkeligt nok valgte SQL Server at bruge row-mode operatorer til at håndtere denne del. På den ene side involverer rækketilstandsoperatorer, der bruges til at beregne løbende totaler, mere overhead end batch-mode Window Aggregate-alternativet; på den anden side har SQL Server en effektiv parallel implementering af en ordrebevarende indeksoperation efterfulgt af vinduesfunktionens beregning, og undgår eksplicit sortering for denne del. Det er mærkeligt, at optimizeren valgte én strategi for efterspørgselsintervallerne og en anden for udbudsintervallerne. I hvert fald henter Index Seek-operatøren forsyningsposterne, og den efterfølgende sekvens af operatører op til Compute Scalar-operatøren beregner forsyningsintervallets slutafgrænser (benævnt Expr1009 i denne plan). Forsyningsinterval startadskilleren er så Udtr1009 – Antal (fra S).
På trods af den mængde tekst, jeg brugte til at beskrive disse to dele, er den virkelig dyre del af arbejdet i planen, hvad der kommer derefter.
Den næste del skal forbinde efterspørgselsintervallerne og udbudsintervallerne ved hjælp af følgende prædikat:
D.StartDemandS.StartSupply Uden noget understøttende indeks, forudsat DI-efterspørgselsintervaller og SI-forsyningsintervaller, ville dette involvere behandling af DI * SI-rækker. Planen i figur 2 blev oprettet efter at have udfyldt auktionstabellen med 400.000 rækker (200.000 efterspørgselsposter og 200.000 udbudsposter). Så uden understøttende indeks ville planen have været nødt til at behandle 200.000 * 200.000 =40.000.000.000 rækker. For at afbøde denne omkostning valgte optimeringsværktøjet at oprette et midlertidigt indeks (se Index Spool-operatøren) med forsyningsinterval-endeafgrænseren (Udtr1009) som nøglen. Det er stort set det bedste, den kunne gøre. Dette løser dog kun en del af problemet. Med to områdeprædikater kan kun det ene understøttes af et indekssøgningsprædikat. Den anden skal håndteres ved hjælp af et resterende prædikat. Faktisk kan du se i planen, at søgningen i det midlertidige indeks bruger søgeprædikatet Expr1009> Expr1005 – D.Quantity, efterfulgt af en filteroperator, der håndterer det resterende prædikat Expr1005> Expr1009 – S.Quantity.
Hvis det antages, at søgeprædikatet i gennemsnit isolerer halvdelen af forsyningsrækkerne fra indekset pr. efterspørgselsrække, er det samlede antal rækker, der udsendes fra Index Spool-operatøren og behandlet af Filter-operatøren, så DI * SI / 2. I vores tilfælde, med 200.000 efterspørgselsrækker og 200.000 udbudsrækker, oversættes dette til 20.000.000.000. Faktisk rapporterer pilen, der går fra Index Spool-operatoren til Filter-operatoren, et antal rækker tæt på dette.
Denne plan har kvadratisk skalering sammenlignet med den lineære skalering af den markørbaserede løsning fra sidste måned. Du kan se resultatet af en præstationstest, der sammenligner de to løsninger i figur 3. Du kan tydeligt se den pænt formede parabel for den sætbaserede løsning.
Figur 3:Ydelse af vejkryds ved brug af CTE'er Løsning versus markørbaseret løsning
Intervalkryds ved hjælp af midlertidige tabeller
Du kan forbedre tingene noget ved at erstatte brugen af CTE'er for efterspørgsels- og udbudsintervallerne med midlertidige tabeller, og for at undgå indeksspolen, skal du oprette dit eget indeks på temp-tabellen med forsyningsintervallerne med endeafgrænseren som nøglen. Her er den komplette løsnings kode:
-- Drop midlertidige tabeller, hvis de findes. WITH D0 AS-- D0 beregner løbende efterspørgsel som EndDemand( SELECT ID, Quantity, SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand FRA dbo.Auktioner WHERE Code ='D'),-- D udtræk prev EndDemand som StartDemand, der udtrykker start-end-efterspørgsel som et intervalD AS( SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand FRA D0)SELECT ID, Quantity, CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand, CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemandINTO #DemandFROM D;WITH S0 AS-- S0 beregner kørende forsyning som EndSupply( SELECT ID, Quantity, SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply FRA dbo.Auctions WHERE Code ='S'),-- S-udtræk prev EndSupply som StartSupply, der udtrykker start-end-forsyning som et intervalS AS( SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply FRA S0)SELECT ID, Quantity, CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply, CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupplyINTO #SupplyFROM S; OPRET UNIKT KLUSTERET INDEKS idx_cl_ES_ID PÅ #Supply(EndSupply, ID); -- Ydre forespørgsel identificerer handler som de overlappende segmenter af de krydsende intervaller-- I de krydsende efterspørgsels- og udbudsintervaller er handelsmængden da -- MINST(EndDemand, EndSupply) - GREATEST(StartDemsnad, StartSupply)SELECT D.ID AS DemandID, S.ID SOM SupplyID, CASE NÅR EndDemandStartSupply THEN StartDemand ELSE StartSupply ENDS AS TradeQuantityINTO #MyPairingsFROM #Demand AS D INNER JOIN #Supply AS SSEEKTHEDEFOR (EFT. S.EndSupply OG D.EndDemand> S.StartSupply; Planerne for denne løsning er vist i figur 4:
Figur 4:Forespørgselsplan for vejkryds ved hjælp af Temp Tables-løsning
De første to planer bruger en kombination af batch-mode Index Seek + Sort + Window Aggregate-operatører til at beregne udbuds- og efterspørgselsintervaller og skrive dem til midlertidige tabeller. Den tredje plan håndterer indeksoprettelsen på #Supply-tabellen med EndSupply-afgrænseren som den førende nøgle.
Den fjerde plan repræsenterer langt hovedparten af arbejdet, med en Nested Loops join-operatør, der matcher hvert interval fra #Demand, de krydsende intervaller fra #Supply. Bemærk, at Index Seek-operatøren også her er afhængig af prædikatet #Supply.EndSupply> #Demand.StartDemand som søgeprædikatet, og #Demand.EndDemand> #Supply.StartSupply som det resterende prædikat. Så med hensyn til kompleksitet/skalering får du den samme kvadratiske kompleksitet som for den tidligere løsning. Du betaler bare mindre pr. række, da du bruger dit eget indeks i stedet for den indeksspole, der blev brugt af den tidligere plan. Du kan se ydelsen af denne løsning sammenlignet med de to foregående i figur 5.
Figur 5:Ydelse af skæringspunkter ved hjælp af midlertidige tabeller sammenlignet med andre to løsninger
Som du kan se, klarer løsningen med temp-tabellerne sig bedre end den med CTE'erne, men den har stadig kvadratisk skalering og klarer sig meget dårligt i forhold til markøren.
Hvad er det næste?
Denne artikel dækkede det første forsøg på at håndtere den klassiske matchende udbud med efterspørgsel opgave ved hjælp af en sæt-baseret løsning. Ideen var at modellere dataene som intervaller, matche udbud med efterspørgselsposter ved at identificere krydsende udbuds- og efterspørgselsintervaller og derefter beregne handelsmængden baseret på størrelsen af de overlappende segmenter. Sikkert en spændende idé. Hovedproblemet med det er også det klassiske problem med at identificere interval skæringspunkter ved at bruge to rækkevidde prædikater. Selv med det bedste indeks på plads, kan du kun understøtte ét områdeprædikat med en indekssøgning; det andet områdeprædikat skal håndteres ved hjælp af et resterende prædikat. Dette resulterer i en plan med kvadratisk kompleksitet.
Så hvad kan du gøre for at overvinde denne forhindring? Der er flere forskellige ideer. En genial idé tilhører Joe Obbish, som du kan læse detaljeret om i hans blogindlæg. Jeg vil dække andre ideer i kommende artikler i serien.
[ Hop til:Original udfordring | Løsninger:Del 1 | Del 2 | del 3]