I det forrige blogindlæg har vi dækket det grundlæggende i skalering - hvad det er, hvad er typerne, hvad er et must-have, hvis vi vil skalere. Dette blogindlæg vil fokusere på udfordringerne og måderne, hvorpå vi kan skalere ud.
Udfordring ved at udskalere
Skalering af databaser er ikke den nemmeste opgave af flere årsager. Lad os fokusere lidt på udfordringerne i forbindelse med udskalering af din databaseinfrastruktur.
Stateful service
Vi kan skelne mellem to forskellige typer tjenester:statsløse og statslige. Statsløse tjenester er dem, der ikke er afhængige af nogen form for eksisterende data. Du kan bare gå videre, starte sådan en service, og det vil heldigvis bare fungere. Du behøver ikke bekymre dig om tilstanden af dataene eller tjenesten. Hvis det er oppe, vil det fungere korrekt, og du kan nemt sprede trafikken på tværs af flere tjenesteinstanser blot ved at tilføje flere kloner eller kopier af eksisterende VM'er, containere eller lignende. Et eksempel på en sådan tjeneste kan være en webapplikation - implementeret fra repoen, med en korrekt konfigureret webserver, en sådan tjeneste vil bare starte og fungere korrekt.
Problemet med databaser er, at databasen er alt andet end statsløs. Data skal indsættes i databasen, de skal behandles og bevares. Billedet af databasen er ikke mere end blot et par pakker installeret over OS-billedet, og uden data og korrekt konfiguration er det ret ubrugeligt. Dette øger kompleksiteten af databaseskaleringen. For statsløse tjenester er det bare at implementere dem og konfigurere nogle loadbalancere til at inkludere nye forekomster i arbejdsbyrden. For databaser, der implementerer databasen, er instansen kun udgangspunktet. Længere nede af banen er datahåndtering - du skal overføre data fra din eksisterende databaseinstans til den nye. Dette kan være en væsentlig del af problemet og den tid, det tager for de nye instanser at begynde at håndtere trafikken. Først efter at dataene er blevet overført, kan vi konfigurere de nye noder til at blive en del af den eksisterende replikeringstopologi - dataene skal opdateres på dem i realtid, baseret på den trafik, der når ud til andre noder.
Tid påkrævet for at opskalere
Det faktum, at databaser er stateful services, er en direkte årsag til den anden udfordring, vi står over for, når vi ønsker at skalere databaseinfrastrukturen ud. Statsløse tjenester - du starter dem bare, og det er det. Det er en ret hurtig proces. For databaser skal du overføre dataene. Hvor lang tid vil det tage, det afhænger af flere faktorer. Hvor stort er datasættet? Hvor hurtig er opbevaringen? Hvor hurtigt er netværket? Hvad er de andre trin, der kræves for at levere den nye node med de friske data? Er data komprimeret/dekomprimeret eller krypteret/dekrypteret i processen? I den virkelige verden kan det tage fra minutter til flere timer at klargøre dataene på en ny node. Dette begrænser alvorligt de tilfælde, hvor du kan skalere dit databasemiljø op. Pludselige, midlertidige belastningsspidser? Egentlig ikke, de kan være for længst væk, før du vil være i stand til at starte yderligere databasenoder. Pludselig og konsekvent belastningsforøgelse? Ja, det vil være muligt at håndtere det ved at tilføje flere noder, men det kan tage endda timer at hente dem frem og lade dem overtage trafikken fra eksisterende databasenoder.
Yderligere belastning forårsaget af opskaleringsprocessen
Det er meget vigtigt at huske på, at den tid, det tager at opskalere, kun er den ene side af problemet. Den anden side er belastningen forårsaget af skaleringsprocessen. Som vi nævnte tidligere, skal du overføre hele datasættet til nyligt tilføjede noder. Dette er ikke noget, du kan ignorere, trods alt kan det være en time lang proces med at læse dataene fra disken, sende dem over netværket og gemme dem et nyt sted. Hvis donoren, knudepunktet, hvor du læser dataene fra, er overbelastet, skal du overveje, hvordan den vil opføre sig, hvis den bliver tvunget til at udføre yderligere tung I/O-aktivitet? Vil din klynge være i stand til at påtage sig en ekstra arbejdsbyrde, hvis den allerede er under hårdt pres og spredt ud? Svaret er måske ikke let at få, da belastningen på noderne kan komme i forskellige former. CPU-bundet belastning vil være det bedste scenario, da I/O-aktiviteten bør være lav, og yderligere diskoperationer vil være håndterbare. I/O-bundet belastning kan på den anden side bremse dataoverførslen betydeligt, hvilket alvorligt påvirker klyngens evne til at skalere.
Skriveskalering
Udskaleringsprocessen, som vi nævnte tidligere, er stort set begrænset til skalering af læsninger. Det er altafgørende at forstå, at skalering af skrivninger er en helt anden historie. Du kan skalere læsninger ved blot at tilføje flere noder og sprede læsningerne over flere backend-noder. Skrifter er ikke så nemme at skalere. For det første kan du ikke udskalere skriverier bare sådan. Hver knude, der indeholder hele datasættet, er naturligvis påkrævet for at håndtere alle skrivninger, der udføres et eller andet sted i klyngen, fordi kun ved at anvende alle ændringer til datasættet, kan det opretholde konsistens. Så når du tænker på det, uanset hvordan du designer din klynge, og hvilken teknologi du bruger, skal hvert medlem af klyngen udføre hver skrivning. Uanset om det er en replika, der replikerer alle skrivninger fra sin master eller node i en multi-master klynge som Galera eller InnoDB Cluster, der udfører alle ændringer i datasættet udført på alle andre noder i klyngen, er resultatet det samme. Skrivninger skaleres ikke ud ved blot at tilføje flere noder til klyngen.
Hvordan kan vi udskalere databasen?
Så vi ved, hvilken slags udfordringer vi står over for. Hvilke muligheder har vi? Hvordan kan vi udskalere databasen?
Ved at tilføje replikaer
Først og fremmest vil vi skalere ud ved blot at tilføje flere noder. Selvfølgelig vil det tage tid, og det er bestemt ikke en proces, du kan forvente vil ske med det samme. Sikker på, du vil ikke være i stand til at skalere ud på den måde. På den anden side er det mest typiske problem, du vil stå over for, CPU-belastningen forårsaget af SELECT-forespørgsler, og som vi diskuterede, kan læsninger simpelthen skaleres ved blot at tilføje flere noder til klyngen. Flere noder at læse fra betyder, at belastningen på hver enkelt af dem vil blive reduceret. Når du er i begyndelsen af din rejse ind i din ansøgnings livscyklus, skal du bare antage, at det er det, du skal beskæftige dig med. CPU-belastning, ikke effektive forespørgsler. Det er meget usandsynligt, at du bliver nødt til at udskalere skrivninger indtil langt længere i livscyklussen, når din ansøgning allerede er modnet, og du skal forholde dig til antallet af kunder.
Ved at sønderdele
Tilføjelse af noder løser ikke skriveproblemet, det er det, vi har etableret. Det du i stedet skal gøre er sharding - opdeling af datasættet på tværs af klyngen. I dette tilfælde indeholder hver node kun en del af dataene, ikke alt. Dette giver os mulighed for endelig at begynde at skalere skrivninger. Lad os sige, at vi har fire noder, som hver indeholder halvdelen af datasættet.
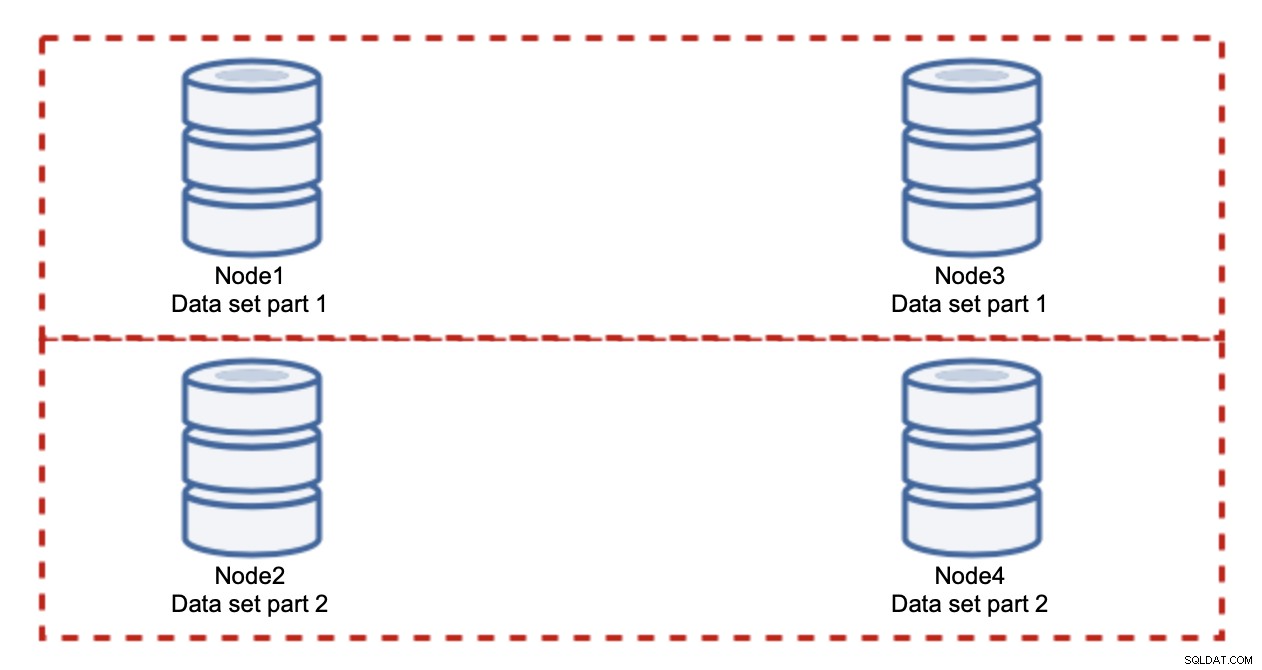
Som du kan se, er ideen enkel. Hvis skrivningen er relateret til del 1 af datasættet, vil den blive udført på node1 og node3. Hvis det er relateret til del 2 af datasættet, vil det blive udført på node2 og node4. Du kan tænke på databasenoderne som diske i et RAID. Her har vi et eksempel på RAID10, to par spejle, til redundans. I virkelig implementering kan det være mere komplekst, du kan have mere end én replika af dataene for forbedret høj tilgængelighed. Hovedessensen er, hvis man antager en helt fair opdeling af dataene, at halvdelen af skrivningerne vil ramme node1 og node3 og den anden halvdel noder 2 og 4. Hvis du vil opdele belastningen endnu mere, kan du introducere det tredje par noder:
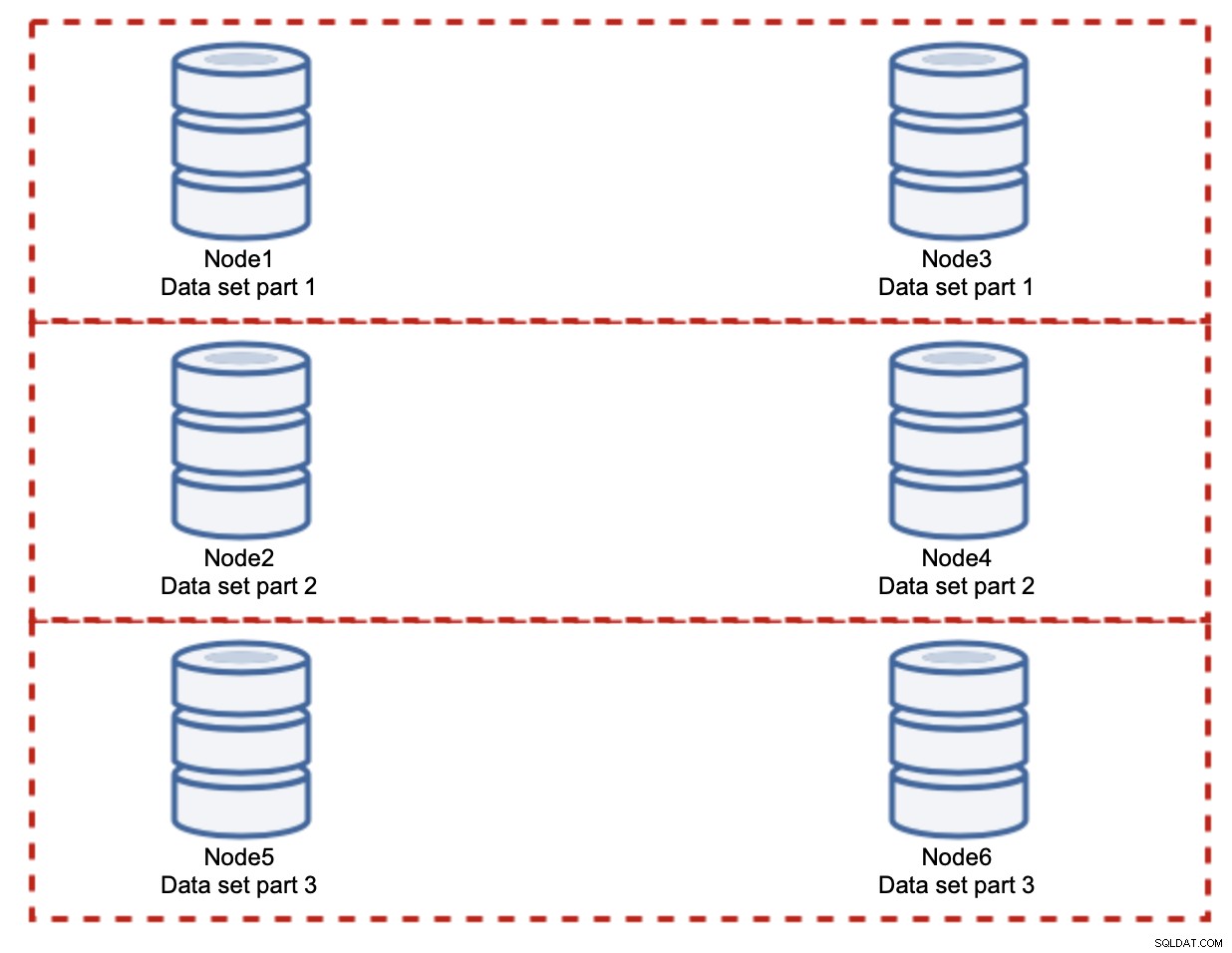
I dette tilfælde, igen, hvis man antager en helt fair opdeling, vil hvert par være ansvarlig for 33% af alle skriverier til klyngen.
Dette opsummerer stort set ideen med sharding. I vores eksempel kan vi ved at tilføje flere shards reducere skriveaktiviteten på databasenoderne til 33 % af den oprindelige I/O-belastning. Som du måske forestiller dig, kommer dette ikke uden ulemper.
Hvordan finder jeg ud af, hvilken shard mine data er placeret på? Detaljer er uden for dette opkalds omfang, men kort fortalt kan du enten implementere en slags funktion på en given kolonne (modulo eller hash på 'id'-kolonnen), eller du kan bygge en separat metadatabase, hvor du gemmer detaljerne af, hvordan dataene er fordelt.
Vi håber, at du fandt denne korte blogserie informativ, og at du fik en bedre forståelse af de forskellige udfordringer, vi står over for, når vi ønsker at skalere databasemiljøet ud. Hvis du har kommentarer eller forslag til dette emne, er du velkommen til at kommentere under dette indlæg og dele din oplevelse