Der har været mange diskussioner om In-Memory OLTP (funktionen tidligere kendt som "Hekaton"), og hvordan den kan hjælpe meget specifikke, højvolumen arbejdsbelastninger. Midt i en anden samtale bemærkede jeg tilfældigvis noget i CREATE TYPE dokumentation for SQL Server 2014, der fik mig til at tro, at der kunne være en mere generel use case:

Relativt stille og uanmeldte tilføjelser til CREATE TYPE-dokumentationen
Baseret på syntaksdiagrammet ser det ud til, at tabelværdiparametre (TVP'er) kan hukommelsesoptimeres, ligesom permanente tabeller kan. Og dermed begyndte hjulene straks at dreje.
En ting, jeg har brugt TVP'er til, er at hjælpe kunder med at eliminere dyre strengopdelingsmetoder i T-SQL eller CLR (se baggrund i tidligere indlæg her, her og her). I mine test udkonkurrerede brugen af en almindelig TVP tilsvarende mønstre ved brug af CLR- eller T-SQL-opdelingsfunktioner med en betydelig margin (25-50%). Jeg undrede mig logisk:Ville der være nogen ydeevnegevinst fra en hukommelsesoptimeret TVP?
Der har været en vis bekymring omkring In-Memory OLTP generelt, fordi der er mange begrænsninger og funktionshuller, du har brug for en separat filgruppe til hukommelsesoptimerede data, du skal flytte hele tabeller til hukommelsesoptimeret, og den bedste fordel er typisk opnås ved også at skabe oprindeligt kompilerede lagrede procedurer (som har deres egne begrænsninger). Som jeg vil demonstrere, hvis du antager, at din tabeltype indeholder simple datastrukturer (f.eks. repræsenterer et sæt heltal eller strenge), eliminerer brug af denne teknologi kun til TVP'er nogle af disse spørgsmål.
Testen
Du har stadig brug for en hukommelsesoptimeret filgruppe, selvom du ikke skal oprette permanente, hukommelsesoptimerede tabeller. Så lad os oprette en ny database med den passende struktur på plads:
OPRET DATABASE xtp;GOALTER DATABASE xtp TILFØJ FILGRUPPE xtp INDEHOLDER MEMORY_OPTIMIZED_DATA;GOALTER DATABASE xtp TILFØJ FIL (name='xtpmod', filnavn='c:\...\xtp.mod') TIL FILGRUPPE;GOALtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT =ON;GO
Nu kan vi oprette en almindelig tabeltype, som vi ville i dag, og en hukommelsesoptimeret tabeltype med et ikke-clusteret hash-indeks og en bucket count, jeg trak ud af luften (mere information om beregning af hukommelseskrav og bucket count i den virkelige verden her):
USE xtp;GO CREATE TYPE dbo.ClassicTVP AS TABLE( Item INT PRIMARY KEY); CREATE TYPE dbo.InMemoryTVP AS TABLE( Item INT NOT NULL PRIMÆR NØGLE IKKE-KLUNGERET HASH MED (BUCKET_COUNT =256)) MED (MEMORY_OPTIMIZED =ON);
Hvis du prøver dette i en database, der ikke har en hukommelsesoptimeret filgruppe, får du denne fejlmeddelelse, ligesom du ville have gjort, hvis du forsøgte at oprette en normal hukommelsesoptimeret tabel:
Msg 41337, Level 16, State 0, Line 9MEMORY_OPTIMIZED_DATA filgruppen eksisterer ikke eller er tom. Hukommelsesoptimerede tabeller kan ikke oprettes for en database, før den har én MEMORY_OPTIMIZED_DATA filgruppe, der ikke er tom.
For at teste en forespørgsel mod en almindelig, ikke-hukommelsesoptimeret tabel trak jeg simpelthen nogle data ind i en ny tabel fra AdventureWorks2012 eksempeldatabasen ved hjælp af SELECT INTO for at ignorere alle disse irriterende begrænsninger, indekser og udvidede egenskaber, og oprettede derefter et klynget indeks på den kolonne, jeg vidste, jeg ville søge på (ProductID ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rækker OPRET UNIKT KLUSTERET INDEX p PÅ dbo.Products(ProductID);
Dernæst oprettede jeg fire lagrede procedurer:to for hver tabeltype; hver bruger EXISTS og JOIN tilgange (jeg kan typisk godt lide at undersøge begge dele, selvom jeg foretrækker EXISTS; senere vil du se, hvorfor jeg ikke ønskede at begrænse min test til kun at EXISTS ). I dette tilfælde tildeler jeg blot en vilkårlig række til en variabel, så jeg kan observere høje eksekveringsantal uden at beskæftige mig med resultatsæt og andet output og overhead:
-- Old-school TVP ved hjælp af EXISTS:CREATE PROCEDURE dbo.ClassicTVP_Exists @Classic dbo.ClassicTVP LÆS-KUN. DECLARE @navn NVARCHAR(50); VÆLG @navn =p.Navn FRA dbo.Products AS p WHERE EXISTS (VÆLG 1 FRA @Classic AS t WHERE t.Item =p.ProductID );ENDGO -- In-Memory TVP ved hjælp af EXISTS:CREATE PROCEDURE dbo.InMemoryTVP_Exists @InMemory dbo.InMemoryTVP LÆSEKUN. DECLARE @navn NVARCHAR(50); SELECT @name =p.Name FRA dbo.Products AS p WHERE EXISTS (VÆLG 1 FRA @InMemory AS t WHERE t.Item =p.ProductID );ENDGO -- Old-school TVP ved hjælp af en JOIN:CREATE PROCEDURE dbo.ClassicTVP_Join @ Klassisk dbo.ClassicTVP LÆSEKUN. DECLARE @navn NVARCHAR(50); VÆLG @navn =p.Navn FRA dbo.Products AS p INNER JOIN @Classic AS t ON t.Item =p.ProductID;ENDGO -- In-Memory TVP ved hjælp af en JOIN:CREATE PROCEDURE dbo.InMemoryTVP_Join @InMemory dbo.InMemoryTVP READONLY SÆT ANTAL TIL; DECLARE @navn NVARCHAR(50); VÆLG @navn =p.Navn FRA dbo.Products AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID;ENDGO
Dernæst havde jeg brug for at simulere den slags forespørgsel, der typisk kommer mod denne type tabel og kræver et TVP eller lignende mønster i første omgang. Forestil dig en formular med en rullemenu eller et sæt afkrydsningsfelter, der indeholder en liste over produkter, og brugeren kan vælge de 20 eller 50 eller 200, som de vil sammenligne, liste, hvad har du. Værdierne kommer ikke til at være i et pænt sammenhængende sæt; de vil typisk være spredt over det hele (hvis det var et forudsigeligt sammenhængende område, ville forespørgslen være meget enklere:start- og slutværdier). Så jeg har lige valgt en vilkårlig 20 værdier fra tabellen (forsøger at forblive under f.eks. 5% af tabellens størrelse), ordnet tilfældigt. En nem måde at bygge en genbrugelig VALUES klausul som denne er som følger:
DECLARE @x VARCHAR(4000) =''; VÆLG TOP (20) @x +='(' + RTRIM(ProduktID) + '),' FRA dbo.Produkter BESTIL VED NEWID(); VÆLG @x; Resultaterne (dine vil næsten helt sikkert variere):
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),(442),(450),(735) ),(441),(409),(454),(780),(966),(988),(512),
I modsætning til en direkte INSERT...SELECT , dette gør det ret nemt at manipulere det output til en genanvendelig erklæring for at udfylde vores TVP'er gentagne gange med de samme værdier og gennem flere iterationer af test:
INDSTIL ANTAL TIL; DECLARE @ClassicTVP dbo.ClassicTVP;DECLARE @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442) ,(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442) ,(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP;EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP_Join @InMemoryTVP_Join @InMemoryTVP_Join @InMemoryTVP_JoinHvis vi kører denne batch ved hjælp af SQL Sentry Plan Explorer, viser de resulterende planer en stor forskel:TVP'en i hukommelsen er i stand til at bruge en indlejret loops join og 20 single-row clustered index søgninger, vs. en merge join feedet 502 rækker af en klynget indeksscanning for den klassiske TVP. Og i dette tilfælde gav EXISTS og JOIN identiske planer. Dette kan tippe med et meget højere antal værdier, men lad os fortsætte med den antagelse, at antallet af værdier vil være mindre end 5 % af tabelstørrelsen:
Planer for klassiske TVP'er og In-Memory TVP'er
Værktøjstip til scan/seek-operatorer, der fremhæver store forskelle – Klassisk til venstre, In- Hukommelse til højre
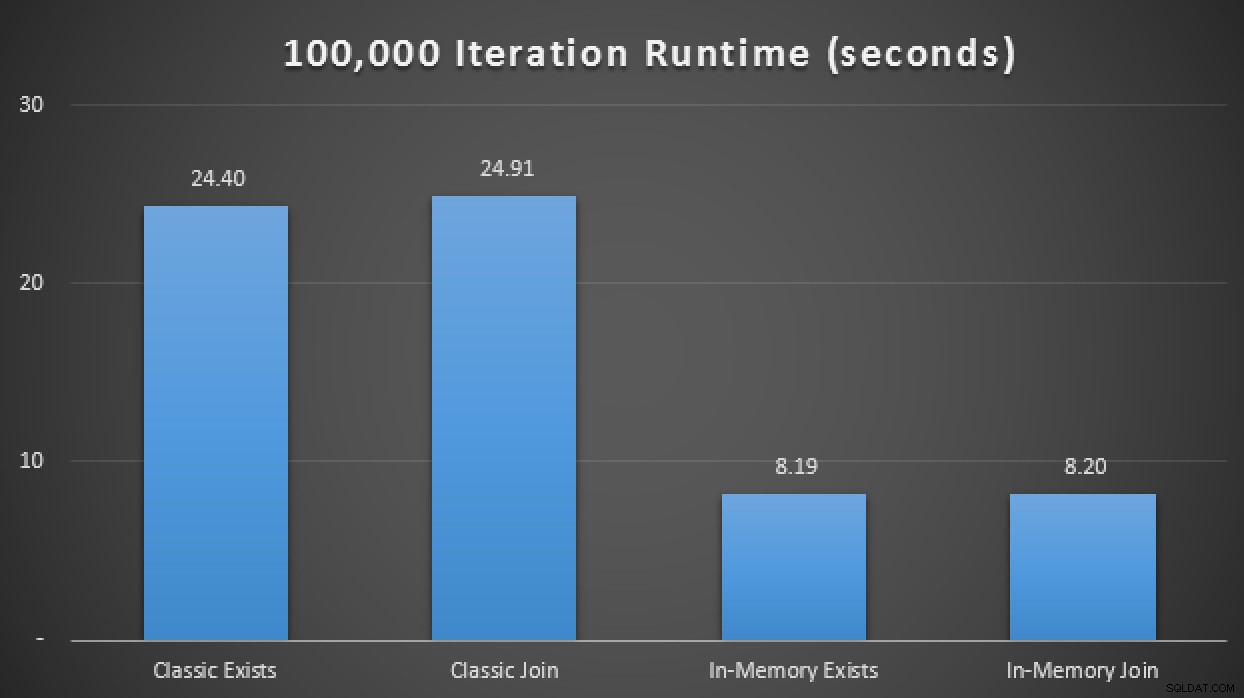
Hvad betyder det nu i skala? Lad os slå enhver showplan-samling fra, og ændre testscriptet en smule for at køre hver procedure 100.000 gange, og opfange kumulativ runtime manuelt:
ERKLÆR @i TINYINT =1, @j INT =1; WHILE @i <=4BEGIN SELECT SYSDATETIME(); WHILE @j <=100000 BEGIN HVIS @i =1 BEGIN EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP; END IF @i =2 BEGIN EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP; END IF @i =3 BEGIN EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP; END IF @i =4 BEGIN EXEC dbo.InMemoryTVP_Join @InMemory =@InMemoryTVP; SLUT SÆT @j +=1; END SELECT @i +=1, @j =1;END SELECT SYSDATETIME();I resultaterne, i gennemsnit over 10 kørsler, ser vi, at i det mindste i dette begrænsede testtilfælde, at brug af en hukommelsesoptimeret tabeltype gav en omtrent 3X forbedring i forhold til den velsagtens mest kritiske ydeevnemåling i OLTP (runtime varighed):
Runtime-resultater, der viser en 3X forbedring med In-Memory TVP'er em>In-Memory + In-Memory + In-Memory:In-Memory Inception
Nu hvor vi har set, hvad vi kan gøre ved blot at ændre vores almindelige tabeltype til en hukommelsesoptimeret tabeltype, lad os se, om vi kan presse mere ydeevne ud af det samme forespørgselsmønster, når vi anvender trifectaen:en in-memory tabel ved hjælp af en indbygget kompileret hukommelsesoptimeret lagret procedure, som accepterer en tabeltabel i hukommelsen som en parameter med en tabelværdi.
Først skal vi oprette en ny kopi af tabellen og udfylde den fra den lokale tabel, vi allerede har oprettet:
CREATE TABLE dbo.Products_InMemory( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, Product Number NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15)Lager NOT NULL , ReorderPoint SMALLINT IKKE NULL, StandardCost MONEY NOT NULL, ListePris MONEY NOT NULL, [Størrelse] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [NULL, DECIMAL) DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, Se llStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMÆR NØGLE IKKE-KLUNGERET HASH (Produkt-ID) MED =(DAT5 ME_6)_TÆL =2D-5 ME_TÆL. INSERT dbo.Products_InMemory SELECT * FRA dbo.Products;Dernæst opretter vi en indbygget kompileret lagret procedure, der tager vores eksisterende hukommelsesoptimerede tabeltype som en TVP:
OPRET PROCEDURE dbo.InMemoryProcedure @InMemory dbo.InMemoryTVP LÆSEKUN MED NATIVE_COMPILATION, SCHEMABINDING, UDFØR SOM EJER SOM BEGIN ATOMIC WITH (TRANSAKTIONSISOLATIONSNIVEAU =SNAPSHOT,'us_english N'); DECLARE @Navn NVARCHAR(50); VÆLG @Name =Name FROM dbo.Products_InMemory AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID;END GOEt par forbehold. Vi kan ikke bruge en almindelig, ikke-hukommelsesoptimeret tabeltype som en parameter til en indbygget kompileret lagret procedure. Hvis vi prøver, får vi:
Msg 41323, Level 16, State 1, Procedure InMemoryProcedure
Tabeltypen 'dbo.ClassicTVP' er ikke en hukommelsesoptimeret tabeltype og kan ikke bruges i en indbygget kompileret lagret procedure.Vi kan heller ikke bruge
Msg 12311, Level 16, State 37, Procedure NativeCompiled_ExistsEXISTSmønster her enten; når vi prøver, får vi:
Underforespørgsler (forespørgsler indlejret i en anden forespørgsel) understøttes ikke med oprindeligt kompilerede lagrede procedurer.Der er mange andre advarsler og begrænsninger med In-Memory OLTP og indbygget kompilerede lagrede procedurer. Jeg ville bare dele et par ting, der tydeligvis kunne se ud til at mangle fra testen.
Så ved at tilføje denne nye oprindeligt kompilerede lagrede procedure til testmatrixen ovenfor, fandt jeg ud af, at den – igen i gennemsnit over 10 kørsler – udførte de 100.000 iterationer på blot 1,25 sekunder. Dette repræsenterer groft en 20X forbedring i forhold til almindelige TVP'er og en 6-7X forbedring i forhold til in-memory TVP'er ved brug af traditionelle tabeller og procedurer:
Runtime-resultater, der viser op til 20X forbedring med In-Memory overaltKonklusion
Hvis du bruger TVP'er nu, eller du bruger mønstre, der kunne erstattes af TVP'er, skal du absolut overveje at tilføje hukommelsesoptimerede TVP'er til dine testplaner, men husk på, at du muligvis ikke ser de samme forbedringer i dit scenarie. (Og selvfølgelig huske på, at TVP'er generelt har mange forbehold og begrænsninger, og de er heller ikke passende til alle scenarier. Erland Sommarskog har en god artikel om nutidens TVP'er her.)
Faktisk kan du se, at i den lave ende af volumen og samtidighed er der ingen forskel - men prøv venligst i realistisk skala. Dette var en meget enkel og konstrueret test på en moderne bærbar computer med en enkelt SSD, men når du taler om reel volumen og/eller spinny mekaniske diske, kan disse ydeevneegenskaber have meget mere vægt. Der kommer en opfølgning med nogle demonstrationer af større datastørrelser.