Kameraer, svingdøre, elevatorer, temperatursensorer, alarmer – alle disse enheder producerer et stort antal indbyrdes forbundne signaler, der er relateret til begivenheder, der sker omkring os. Forestil dig nu, at du er den person, der skal spore statusser, producere realtidsrapporter og lave forudsigelser baseret på alle disse signaldata. For at gøre dette skal du først gemme disse data. En datamodel, der understøtter sådan signalbehandling, er emnet for dagens artikel.
Den enkleste måde at gemme indgående signaler på ville være blot at gemme en tekstlig repræsentation af dem på en enorm liste. Denne tilgang ville give os mulighed for at udføre indsættelser hurtigt, men opdateringer ville være problematiske. En sådan model ville heller ikke blive normaliseret, og derfor vil vi ikke gå i den retning.
Vi opretter en normaliseret datamodel, der kan bruges til at gemme data genereret af forskellige enheder og også definere, hvordan enhederne er relateret. En sådan model ville effektivt gemme alt, hvad vi har brug for, og kunne også bruges til analyser og forudsigende analyser.
Datamodel
Signalbehandlingsdatamodellen
Modellen består af tre fagområder:
ComplexesInstallations & DevicesSignals & Events
Vi vil beskrive hvert af disse emneområder i den rækkefølge, de er anført.
Komplekser
Mens jeg oprettede denne datamodel, gik jeg ud fra den antagelse, at vi vil bruge den til at spore, hvad der sker i større komplekser. Komplekser varierer i størrelse fra et enkeltværelse til et indkøbscenter. Det er vigtigt, at hvert kompleks har mindst én enhed/sensor, men det vil sandsynligvis have mange flere.
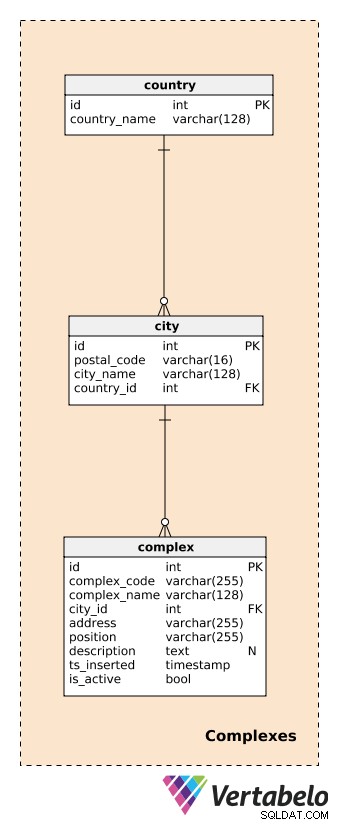
Før vi beskriver komplekser, skal vi definere tabellerne, der håndterer lande og byer. Disse vil give en ret detaljeret beskrivelse af placeringen af hvert kompleks.
For hvert country , vi gemmer dens UNIKKE country_name; for hver city , gemmer vi den UNIKKE kombination af postal_code , city_name og country_id . Jeg vil ikke gå i detaljer her, og vi antager, at hver by kun har ét postnummer. I virkeligheden vil de fleste byer have mere end ét postnummer; i så fald kan vi bruge hovedkoden for hver by.
Et complex er den faktiske bygning eller det sted, hvor datagenererende enheder er installeret. Som tidligere nævnt kan komplekser variere fra et enkelt værelse eller en målestation til meget større steder som parkeringspladser, indkøbscentre, biografer osv. De er genstand for vores analyse. Vi ønsker at kunne spore, hvad der sker på det komplekse plan i realtid og senere at producere rapporter og analyser. For hvert kompleks definerer vi en:
complex_code– En UNIK identifikator for hvert kompleks. Mens vi har en separat primær nøgleattribut (id) for denne tabel kan vi forvente, at vi vil arve en anden identifikationskode for hvert kompleks fra et andet system.complex_name– Et navn, der bruges til at beskrive det kompleks. I tilfælde af indkøbscentre og biografer kan dette være deres faktiske og velkendte navn; til en målestation kunne vi bruge et generisk navn.city_id– En reference til den by, hvor komplekset er placeret.address– Den fysiske adresse på dette kompleks.position– Kompleksets position (dvs. geografiske koordinater) defineret i tekstformat.description– En tekstbeskrivelse, der nærmere beskriver dette kompleks.ts_inserted– Et tidsstempel, da denne post blev indsat.is_active– En boolsk værdi, der angiver, om dette kompleks stadig er aktivt eller ej.
Installationer og enheder
Nu rykker vi tættere på hjertet af vores model. Vi vil sandsynligvis have et antal enheder installeret i hvert kompleks. Vi vil også næsten helt sikkert gruppere disse enheder baseret på deres formål - f.eks. vi kunne sætte kameraer, dørsensorer og en motor, der bruges til at åbne og lukke en dør i en gruppe, fordi de arbejder sammen.
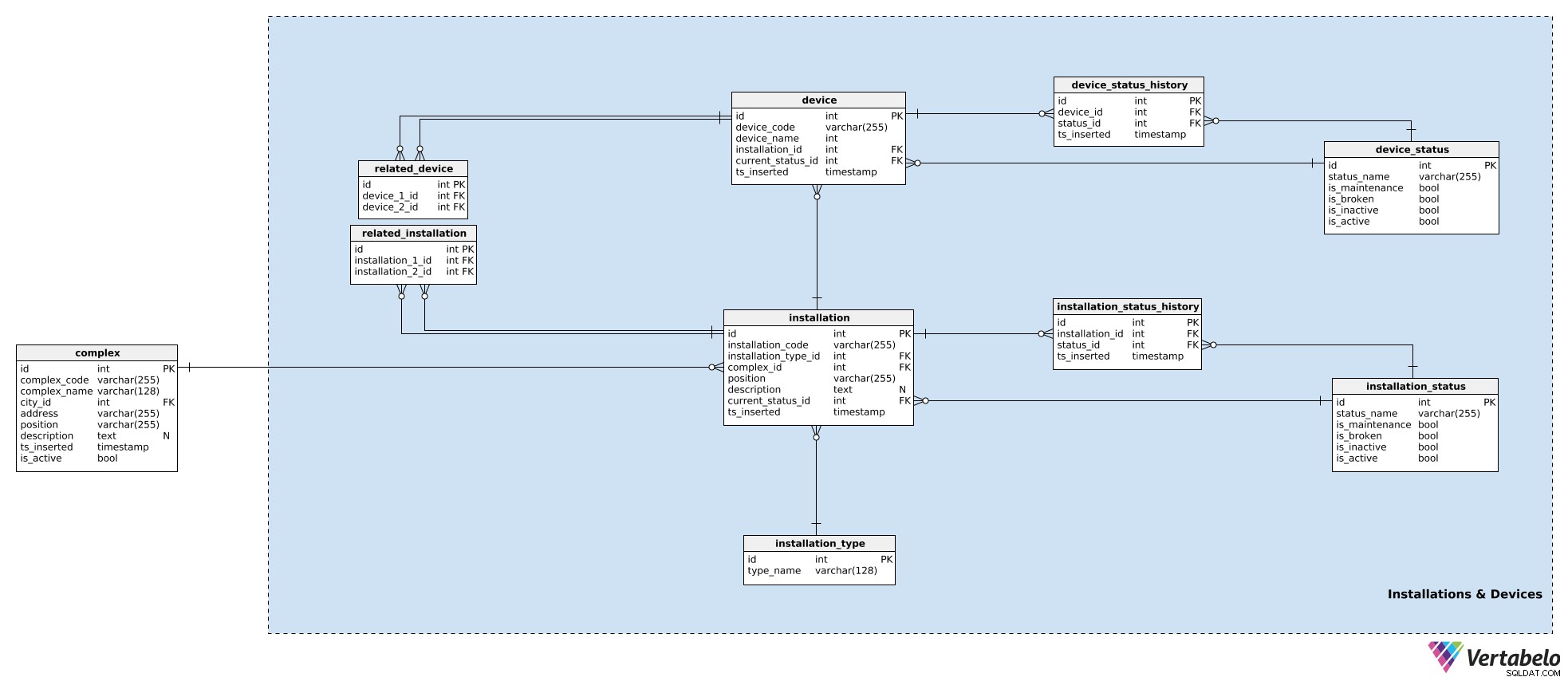
I vores model er enheder, der arbejder sammen i ét kompleks, grupperet i installationer. Disse kunne være til hoveddøre, rulletrapper, temperatursensorer osv. For hver installation gemmer vi følgende detaljer i installation tabel:
installation_code– En UNIK kode, der bruges til at angive den installation.installation type_id– En reference tilinstallation_typeordbog. Denne ordbog gemmer kun et UNIKTtype_nameegenskab, der beskriver typen, f.eks. rulletrappe, elevator.complex_id– En reference tilcomplexden installation tilhører.position– Koordinaterne, i tekstformat, for den installation inde i komplekset.description– En tekstbeskrivelse af installationen.current_status_id– En reference til den aktuelle status (frainstallation_statustabel) for den pågældende installation.ts_inserted– Et tidsstempel, da denne post blev indsat i vores system.
Vi har allerede nævnt installationsstatusser. En liste over alle mulige statusser er gemt i installation_status ordbog. Hver status er UNIKT defineret af dens status_name . Udover det gemmer vi flag, der angiver, om denne status, når den bruges, antyder, at installationen is_broken , is_inactive , is_maintenance , eller is_active . Kun ét af disse flag bør indstilles ad gangen.
Vi har allerede tildelt en aktuel status til installationen. Hvis vi skal spore, hvad der sker med enheden, skal vi også gemme dens historie. For at gøre det bruger vi endnu en tabel, installation_status_history . For hver post her gemmer vi referencer til den relaterede installation og status samt øjeblikket (ts_inserted ), da denne status blev tildelt.
Installationer er en del af vores komplekser. Selvom hver installation er en enkelt enhed, kan den stadig være relateret til andre installationer. (F.eks. er et videosystem ved et indkøbscenters hovedindgang åbenlyst relateret til indkøbscentrets hoveddøre – folk vil først blive set af kameraet, og så åbnes dørene.) Hvis vi vil holde styr på disse relationer, gemmer vi dem i related_installation bord. Bemærk venligst, at denne tabel kun indeholder UNIKKE par af to nøgler, som begge refererer til installation bord.
Den samme logik bruges til at gemme enheder. Enheder er enkelte stykker hardware, der producerer de signaler, vi er interesserede i. Mens installationer hører til komplekser, hører enheder til installationer. For hver device , vi gemmer:
device_code– En UNIK måde at betegne hver enhed på.device_name– Et navn til denne enhed.installation_id– En reference til den installation, denne enhed tilhører.current_status_id– Enhedens aktuelle status.ts_inserted– Et tidsstempel, da denne post blev indsat.
Statusser håndteres på samme måde. Vi bruger device_status tabel for at gemme en liste over alle mulige enhedsstatusser. Denne tabel har samme struktur som installation_status og attributterne bruges på samme måde. Grunden til at have de to separate statusordbøger er, at enheder og deres installationer kan have forskellige statusser – i hvert fald i navn.
Den aktuelle status er gemt i device.current_status_id attribut og statushistorik gemmes i device_status_history bord. For hver post her gemmer vi relationer til enheden og status samt det øjeblik, hvor denne post blev indsat.
Den sidste tabel i dette emneområde er related_device bord. Selvom det er ret tydeligt, at alle enheder inde i den samme installation er tæt beslægtede, vil jeg gerne have mulighed for at relatere to enheder, der tilhører enhver installation. Det gør vi ved at gemme deres to enheds-id'er i denne tabel.
Signaler og begivenheder
Nu er vi klar til hjertet af hele modellen.
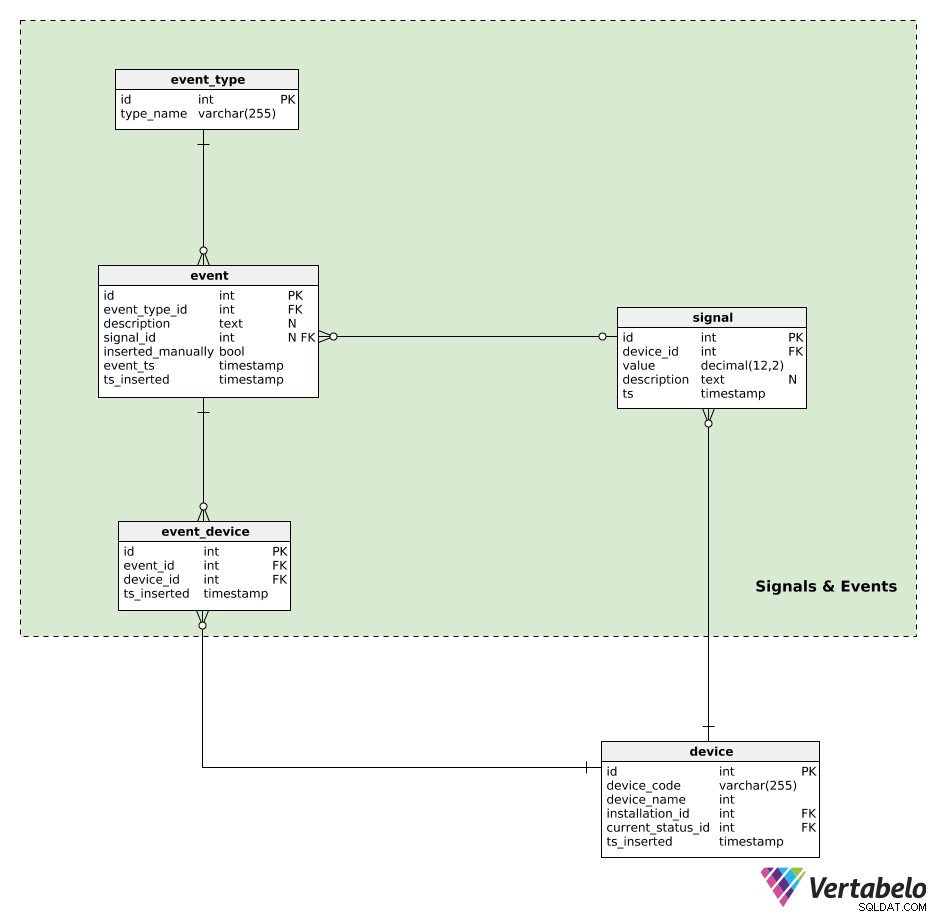
Enheder genererer signaler. Alle signaldata opbevares i signal bord. For hvert signal gemmer vi:
device_id– En reference til den enhed, der genererede dette signal.value– Den numeriske værdi af dette signal.description– En tekstværdi, der kunne indeholde yderligere parametre (f.eks. signaltype, værdier, anvendt måleenhed) relateret til det enkelte signal. Disse data gemmes i et JSON-lignende format.ts– Et tidsstempel, når dette signal blev indsat i bordet.
Vi kan forvente, at dette bord vil blive ekstremt hårdt brugt, med et stort antal indsatser udført pr. Derfor bør databasevedligeholdelse fokusere på at spore størrelsen af denne tabel.
Den sidste ting, jeg vil gøre, er at tilføje begivenheder til vores datamodel. Hændelser kan genereres automatisk af et signal eller indsættes manuelt. En automatisk genereret hændelse kunne være "dør åben i 5 minutter", mens en manuelt indsat hændelse kunne være "enheden måtte slukkes på grund af dette signal". Hele ideen er at gemme handlinger, der opstod som et resultat af enhedens adfærd. Senere kunne vi bruge disse hændelser, mens vi udførte en enhedsadfærdsanalyse.
Begivenheder vil blive granuleret efter event_type . Hver type er UNIKT defineret af dens type_name .
Alle automatisk genererede eller manuelt indsatte hændelser registreres i event bord. For hver post her gemmer vi:
event_type_id– En reference til den relaterede hændelsestype.description– En tekstbeskrivelse af den begivenhed.signal_id– En henvisning til det signal, hvis nogen, der forårsagede hændelsen.inserted_manually– Et flag, der angiver, om denne post blev indsat manuelt eller ej.event_tsogts_inserted– Tidsstempler, hvornår denne hændelse faktisk fandt sted, og hvornår en registrering af den blev indsat. Disse to kan være forskellige, især når hændelsesposter indsættes manuelt.
Den sidste tabel i vores model er event_device bord. Denne tabel bruges til at relatere hændelser med alle de enheder, der var involveret. For hver post gemmer vi det UNIKKE par event_id – device_id og tidsstemplet, da posten blev indsat.
Hvad synes du om vores signalbehandlingsdatamodel?
I dag har vi analyseret en forenklet datamodel, som vi kunne bruge til at spore signaler fra et sæt enheder installeret forskellige steder. Selve modellen burde være nok til at gemme alt, hvad vi har brug for for at spore statusser og udføre analyser. Alligevel er der mange forbedringer mulige. Hvad kunne vi tilføje? Fortæl os venligst i kommentarerne nedenfor.