Min ven Peter Larsson sendte mig en T-SQL-udfordring, der indebar at matche udbud og efterspørgsel. Hvad angår udfordringer, er det en formidabel en. Det er et ret almindeligt behov i det virkelige liv; det er nemt at beskrive, og det er ret nemt at løse med rimelig ydeevne ved hjælp af en markørbaseret løsning. Den vanskelige del er at løse det ved hjælp af en effektiv sæt-baseret løsning.
Når Peter sender mig et puslespil, svarer jeg typisk med et løsningsforslag, og han kommer som regel med en bedre ydende, genial løsning. Jeg har nogle gange mistanke om, at han sender mig puslespil for at motivere sig selv til at komme med en god løsning.
Da opgaven repræsenterer et fælles behov og er så interessant, spurgte jeg Peter, om han ville have noget imod, hvis jeg delte den og hans løsninger med sqlperformance.com-læserne, og han var glad for at give mig lov.
I denne måned vil jeg præsentere udfordringen og den klassiske markørbaserede løsning. I de efterfølgende artikler vil jeg præsentere sæt-baserede løsninger – inklusive dem, Peter og jeg arbejdede på.
Udfordringen
Udfordringen involverer at forespørge i en tabel kaldet Auktioner, som du opretter ved hjælp af følgende kode:
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); Denne tabel indeholder efterspørgsels- og udbudsposter. Efterspørgselsposter er markeret med koden D og udbudsposter med S. Din opgave er at matche udbuds- og efterspørgselsmængder baseret på ID-bestilling ved at skrive resultatet ind i en midlertidig tabel. Indtastningerne kunne repræsentere købs- og salgsordrer for kryptovaluta såsom BTC/USD, aktiekøbs- og salgsordrer såsom MSFT/USD eller enhver anden vare eller vare, hvor du skal matche udbud og efterspørgsel. Bemærk, at auktionsindgangene mangler en prisattribut. Som nævnt bør du matche udbuds- og efterspørgselsmængderne baseret på ID-bestilling. Denne rækkefølge kunne have været afledt af pris (stigende for udbudsposter og faldende for efterspørgselsposter) eller andre relevante kriterier. I denne udfordring var ideen at holde tingene enkle og antage, at ID'et allerede repræsenterer den relevante rækkefølge for matchning.
Som et eksempel kan du bruge følgende kode til at udfylde auktionstabellen med et lille sæt eksempeldata:
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
Det er meningen, at du skal matche udbuds- og efterspørgselsmængderne som sådan:
- En mængde på 5,0 matches for efterspørgsel 1 og udbud 1000, udtømmer efterspørgsel 1 og efterlader 3,0 af udbud 1000
- En mængde på 3,0 matches for Demand 2 og Supply 1000, hvilket udtømmer både Demand 2 og Supply 1000
- En mængde på 6,0 matches for efterspørgsel 3 og udbud 2000, hvilket efterlader 2,0 af efterspørgsel 3 og udtømmer udbud 2000
- En mængde på 2,0 matches for Demand 3 og Supply 3000, hvilket udtømmer både Demand 3 og Supply 3000
- En mængde på 2,0 matches for Demand 5 og Supply 4000, hvilket udtømmer både Demand 5 og Supply 4000
- En mængde på 4,0 matches for Demand 6 og Supply 5000, hvilket efterlader 4,0 af Demand 6 og udtømmer Supply 5000
- En mængde på 3,0 matches for Demand 6 og Supply 6000, hvilket efterlader 1,0 af Demand 6 og udtømmer Supply 6000
- En mængde på 1,0 matches for Demand 6 og Supply 7000, udtømmer Demand 6 og efterlader 1,0 af Supply 7000
- En mængde på 1,0 matches for Demand 7 og Supply 7000, hvilket efterlader 3,0 af Demand 7 og udtømmer Supply 7000; Efterspørgsel 8 matches ikke med nogen forsyningsposter og står derfor tilbage med den fulde mængde 2.0
Din løsning formodes at skrive følgende data ind i den resulterende midlertidige tabel:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Stort sæt prøvedata
For at teste løsningernes ydeevne skal du bruge et større sæt eksempeldata. For at hjælpe med dette kan du bruge funktionen GetNums, som du opretter ved at køre følgende kode:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Denne funktion returnerer en sekvens af heltal i det anmodede område.
Med denne funktion på plads kan du bruge følgende kode leveret af Peter til at udfylde auktionstabellen med eksempeldata og tilpasse input efter behov:
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; Som du kan se, kan du tilpasse antallet af købere og sælgere samt minimum og maksimum køber- og sælgermængder. Ovenstående kode angiver 200.000 købere og 200.000 sælgere, hvilket resulterer i i alt 400.000 rækker i auktionstabellen. Den sidste forespørgsel fortæller dig, hvor mange efterspørgsel (D) og udbud (S) poster blev skrevet til tabellen. Det returnerer følgende output for de førnævnte input:
Code Items ---- ----------- D 200000 S 200000
Jeg vil teste ydeevnen af forskellige løsninger ved at bruge ovenstående kode, idet jeg indstiller antallet af købere og sælgere hver til følgende:50.000, 100.000, 150.000 og 200.000. Det betyder, at jeg får følgende samlede antal rækker i tabellen:100.000, 200.000, 300.000 og 400.000. Selvfølgelig kan du tilpasse input, som du ønsker for at teste ydeevnen af dine løsninger.
Markør-baseret løsning
Peter leverede den markørbaserede løsning. Det er ret grundlæggende, hvilket er en af dets vigtige fordele. Det vil blive brugt som et benchmark.
Løsningen bruger to markører:en til efterspørgselsindgange sorteret efter ID og den anden til udbudsposter sorteret efter ID. For at undgå en fuld scanning og sortering pr. markør skal du oprette følgende indeks:
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
Her er den komplette løsnings kode:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; Som du kan se, starter koden med at oprette en midlertidig tabel. Den erklærer derefter de to markører og henter en række fra hver og skriver den aktuelle efterspørgselsmængde til variablen @DemandQuantity og den aktuelle forsyningsmængde til @SupplyQuantity. Den behandler derefter indtastningerne i en løkke, så længe den sidste hentning lykkedes. Koden anvender følgende logik i løkkens krop:
Hvis den aktuelle efterspørgselsmængde er mindre end eller lig med den aktuelle forsyningsmængde, gør koden følgende:
- Skriver en række i den midlertidige tabel med den aktuelle parring, med efterspørgselsmængden (@DemandQuantity) som den matchede mængde
- Trækker den aktuelle efterspørgselsmængde fra den aktuelle forsyningsmængde (@SupplyQuantity)
- Henter den næste række fra efterspørgselsmarkøren
Ellers gør koden følgende:
- Kontrollerer, om den aktuelle forsyningsmængde er større end nul, og hvis det er tilfældet, gør den følgende:
- Skriver en række i temp-tabellen med den aktuelle parring, med forsyningsmængden som den matchede mængde
- Trækker den aktuelle forsyningsmængde fra den aktuelle efterspørgselsmængde
- Henter den næste række fra forsyningsmarkøren
Når løkken er færdig, er der ikke flere par at matche, så koden rydder bare op i markørressourcerne.
Fra et præstationssynspunkt får du den typiske overhead af cursorhentning og looping. Så igen laver denne løsning en enkelt ordnet passage over efterspørgselsdataene og en enkelt ordnet passage over forsyningsdataene, hver ved hjælp af en søge- og rækkeviddescanning i det indeks, du oprettede tidligere. Planerne for markørforespørgslerne er vist i figur 1.

Figur 1:Planer for markørforespørgsler
Da planen udfører en søgning og bestilt rækkeviddescanning af hver af delene (efterspørgsel og udbud) uden nogen sortering involveret, har den lineær skalering. Dette blev bekræftet af de præstationstal, jeg fik, da jeg testede det, som vist i figur 2.
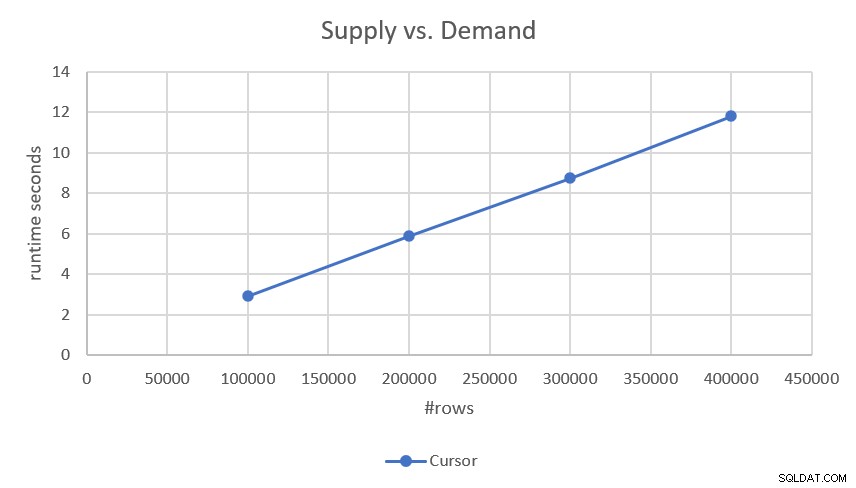
Figur 2:Ydelse af markørbaseret løsning
Hvis du er interesseret i de mere præcise køretider, her er de:
- 100.000 rækker (50.000 krav og 50.000 forsyninger):2,93 sekunder
- 200.000 rækker:5,89 sekunder
- 300.000 rækker:8,75 sekunder
- 400.000 rækker:11,81 sekunder
Da løsningen har lineær skalering, kan du nemt forudsige køretiden med andre skalaer. For eksempel, med en million rækker (f.eks. 500.000 krav og 500.000 forsyninger) skulle det tage omkring 29,5 sekunder at køre.
Udfordringen er i gang
Den markørbaserede løsning har lineær skalering, og som sådan er den ikke dårlig. Men det medfører den typiske cursorhentning og looping overhead. Selvfølgelig kan du reducere denne overhead ved at implementere den samme algoritme ved hjælp af en CLR-baseret løsning. Spørgsmålet er, om du kan komme med en velfungerende sæt-baseret løsning til denne opgave?
Som nævnt vil jeg udforske sæt-baserede løsninger – både dårligt ydende og godt ydende – fra næste måned. I mellemtiden, hvis du er klar til udfordringen, så se om du kan finde på dine egne sætbaserede løsninger.
For at verificere rigtigheden af din løsning skal du først sammenligne resultatet med det, der er vist her for det lille sæt eksempeldata. Du kan også kontrollere gyldigheden af din løsnings resultat med et stort sæt eksempeldata ved at kontrollere, at den symmetriske forskel mellem markørløsningens resultat og dit er tom. Forudsat at markørens resultat er gemt i en temp-tabel kaldet #PairingsCursor og dit i en temp-tabel kaldet #MyPairings, kan du bruge følgende kode til at opnå dette:
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
Resultatet skal være tomt.
Held og lykke!
[ Hop til løsninger:Del 1 | Del 2 | del 3]