Jeg tror, at alle allerede kender mine meninger om MERGE og hvorfor jeg holder mig fra det. Men her er et andet (anti-)mønster, jeg ser overalt, når folk vil udføre en upsert (opdater en række, hvis den findes, og indsæt den, hvis den ikke gør):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Dette ligner et ret logisk flow, der afspejler, hvordan vi tænker om dette i det virkelige liv:
- Finder der allerede en række for denne nøgle?
- JA :OK, opdater den række.
- NEJ :OK, så tilføj det.
Men dette er spild.
At lokalisere rækken for at bekræfte, at den eksisterer, kun for at skulle finde den igen for at opdatere den, er to gange så meget. for ingenting. Også selvom nøglen er indekseret (hvilket jeg håber altid er tilfældet). Hvis jeg sætter denne logik ind i et flowdiagram og forbinder, ved hvert trin, den type operation, der skal ske i databasen, ville jeg have dette:
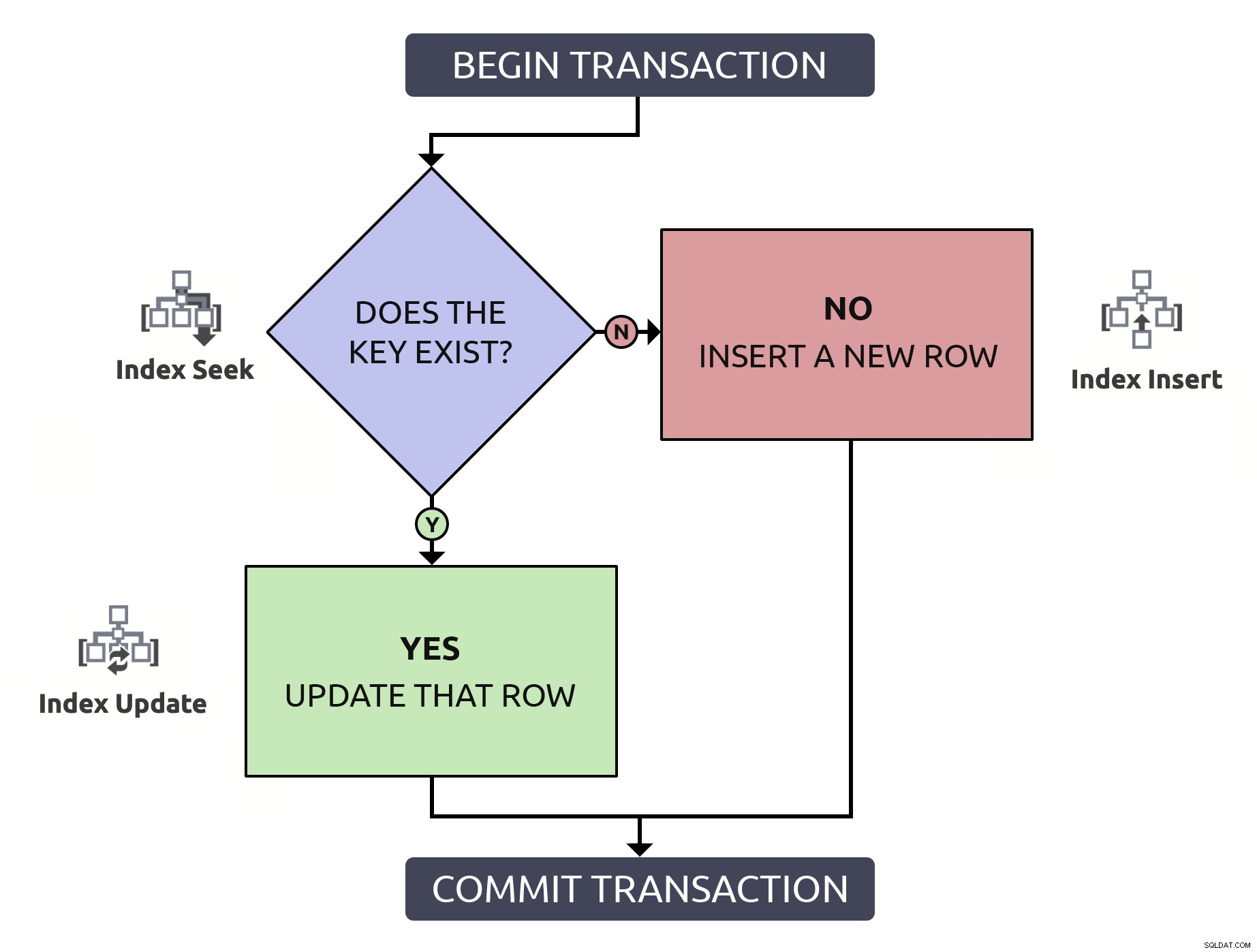 Bemærk, at alle stier vil medføre to indeksoperationer.
Bemærk, at alle stier vil medføre to indeksoperationer.
Endnu vigtigere, bortset fra ydeevne, medmindre du både bruger en eksplicit transaktion og hæver isolationsniveauet, kan flere ting gå galt, når rækken ikke allerede eksisterer:
- Hvis nøglen findes, og to sessioner forsøger at opdatere samtidigt, bliver de begge opdateret (man vil "vinde"; "taberen" vil følge med ændringen, der hænger ved, hvilket fører til en "tabt opdatering"). Dette er ikke et problem i sig selv, og det er sådan, vi bør forventer, at et system med samtidighed virker. Paul White taler om den interne mekanik mere detaljeret her, og Martin Smith taler om nogle andre nuancer her.
- Hvis nøglen ikke eksisterer, men begge sessioner består eksistenskontrollen på samme måde, kan alt ske, når de begge forsøger at indsætte:
- deadlock på grund af inkompatible låse;
- hæv nøgleovertrædelsesfejl det skulle ikke være sket; eller,
- indsæt dublerede nøgleværdier hvis den kolonne ikke er korrekt begrænset.
Den sidste er den værste, IMHO, fordi det er den, der potentielt korrumperer data . Deadlocks og undtagelser kan nemt håndteres med ting som fejlhåndtering, XACT_ABORT , og prøv logik igen, afhængigt af hvor ofte du forventer kollisioner. Men hvis du bliver lullet ind i en følelse af sikkerhed, at IF EXISTS check beskytter dig mod dubletter (eller nøgleovertrædelser), det er en overraskelse, der venter på at ske. Hvis du forventer, at en kolonne fungerer som en nøgle, skal du gøre den officiel og tilføje en begrænsning.
"Mange mennesker siger..."
Dan Guzman talte om løbsforholdene for mere end ti år siden i Conditional INSERT/UPDATE Race Condition og senere i "UPSERT" Race Condition With MERGE.
Michael Swart har også behandlet dette emne flere gange:
- Mythbusting:Concurrent Update/Insert Solutions – hvor han erkendte, at det at lade den indledende logik være på plads og kun hæve isolationsniveauet, bare ændrede nøgleovertrædelser til dødvande;
- Vær forsigtig med fletteerklæringen – hvor han tjekkede sin entusiasme over
MERGE; og, - Hvad skal du undgå, hvis du ønsker at bruge MERGE – hvor han endnu en gang bekræftede, at der stadig er masser af gyldige grunde til fortsat at undgå
MERGE.
Sørg også for at læse alle kommentarerne til alle tre indlæg.
Løsningen
Jeg har rettet mange dødvande i min karriere ved blot at justere til følgende mønster (ophæv den overflødige check, omslut sekvensen i en transaktion og beskyt den første bordadgang med passende låsning):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Hvorfor har vi brug for to tip? Er det ikke UPDLOCK nok?
UPDLOCKbruges til at beskytte mod dødvande konverteringer ved erklæringen niveau (lad en anden session vente i stedet for at tilskynde et offer til at prøve igen).SERIALIZABLEbruges til at beskytte mod ændringer af de underliggende data gennem hele transaktionen (sørg for, at en række, der ikke eksisterer, fortsat ikke eksisterer).
Det er lidt mere kode, men det er 1000 % sikrere og endda i de værste case (rækken findes ikke allerede), den udfører det samme som anti-mønsteret. I bedste tilfælde, hvis du opdaterer en række, der allerede eksisterer, vil det være mere effektivt kun at finde den række én gang. Ved at kombinere denne logik med de operationer på højt niveau, der skal ske i databasen, er det lidt enklere:
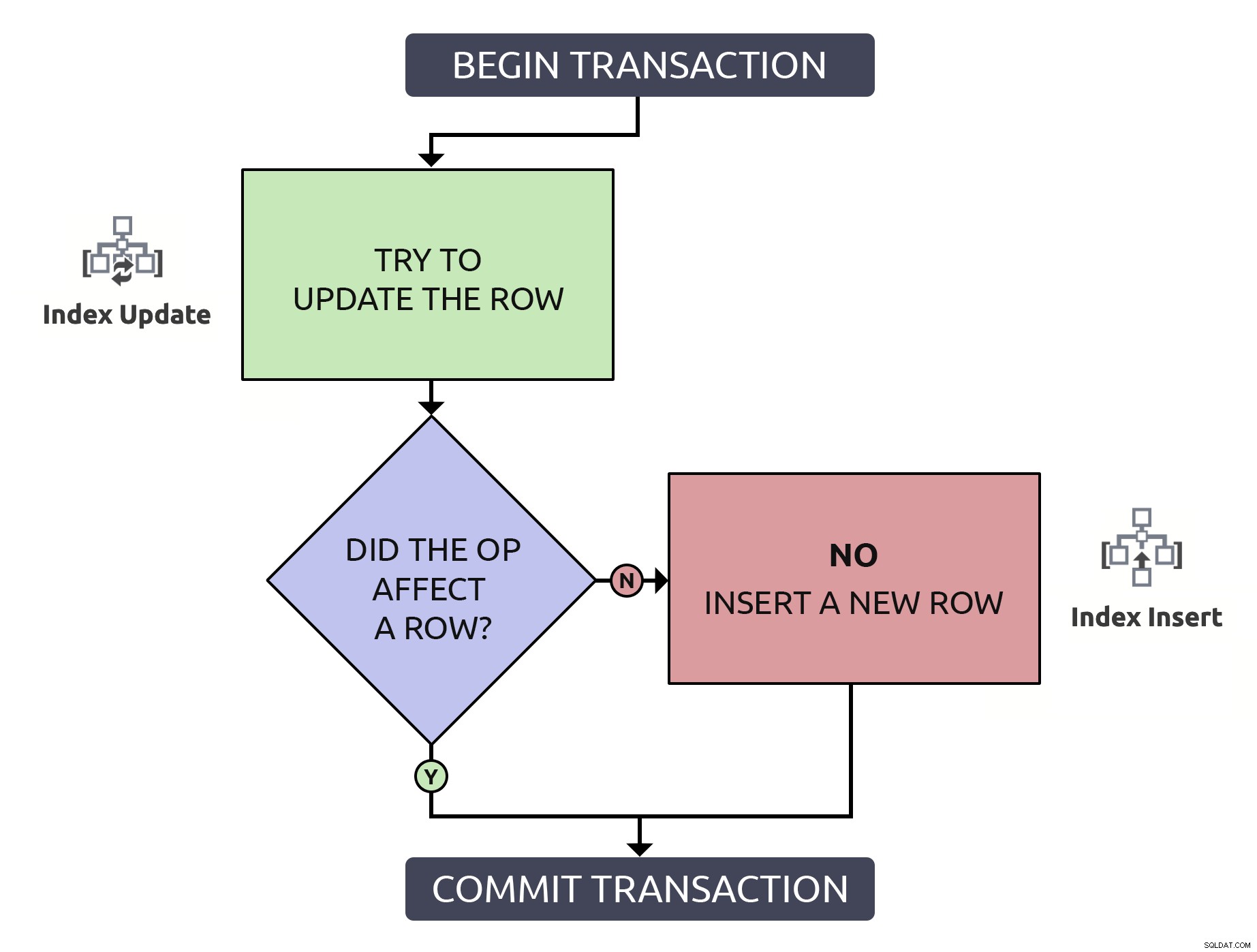 I dette tilfælde medfører én sti kun en enkelt indeksoperation.
I dette tilfælde medfører én sti kun en enkelt indeksoperation.
Men igen, ydeevne til side:
- Hvis nøglen findes, og to sessioner forsøger at opdatere den på samme tid, vil de både skiftes til og opdatere rækken med succes , ligesom før.
- Hvis nøglen ikke findes, vil én session "vinde" og indsætte rækken . Den anden må vente indtil låsene frigives for overhovedet at kontrollere, om de eksisterer, og blive tvunget til at opdatere.
I begge tilfælde mister forfatteren, der vandt løbet, deres data til alt, hvad "taberen" opdaterede efter dem.
Bemærk, at samlet gennemstrømning på et meget samtidig system kan lider, men det er en afvejning, du bør være villig til at foretage. At du får masser af dødvande ofre eller nøgleovertrædelsesfejl, men de sker hurtigt, er ikke en god præstationsmåling. Nogle mennesker ville elske at se al blokering fjernet fra alle scenarier, men noget af det er blokering, du absolut ønsker for dataintegritet.
Men hvad hvis en opdatering er mindre sandsynlig?
Det er klart, at ovenstående løsning optimerer til opdateringer og antager, at en nøgle, du forsøger at skrive til, allerede vil eksistere i tabellen mindst lige så ofte, som den ikke gør. Hvis du hellere vil optimere til indstik, ved at vide eller gætte på, at det vil være mere sandsynligt, at indsætninger er mere sandsynlige end opdateringer, kan du vende logikken rundt og stadig have en sikker indsættelsesoperation:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; Der er også "bare gør det"-tilgangen, hvor du blindt indsætter og lader kollisioner skabe undtagelser for den, der ringer:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
Omkostningerne ved disse undtagelser vil ofte opveje omkostningerne ved at tjekke først; du bliver nødt til at prøve det med et nogenlunde præcist gæt på hit/miss rate. Jeg skrev om dette her og her.
Hvad med at ophæve flere rækker?
Ovenstående omhandler enkeltindsættelses-/opdateringsbeslutninger, men Justin Pealing spurgte, hvad du skal gøre, når du behandler flere rækker uden at vide, hvilken af dem allerede eksisterer?
Hvis du antager, at du sender et sæt rækker ved at bruge noget som en tabelværdiparameter, ville du opdatere ved hjælp af en join og derefter indsætte ved at bruge IKKE EKSISTERER, men mønsteret ville stadig svare til den første fremgangsmåde ovenfor:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Hvis du samler flere rækker på en anden måde end en TVP (XML, kommasepareret liste, voodoo), skal du først placere dem i en tabelform og slutte dig til hvad det er. Pas på ikke at optimere til indsættelser først i dette scenarie, ellers vil du potentielt opdatere nogle rækker to gange.
Konklusion
Disse upsert-mønstre er overlegne i forhold til dem, jeg ser alt for ofte, og jeg håber, du begynder at bruge dem. Jeg vil pege på dette indlæg, hver gang jeg ser IF EXISTS mønster i naturen. Og hej, endnu en shoutout til Paul White (sql.kiwi | @SQK_Kiwi), fordi han er så fremragende til at gøre svære koncepter nemme at forstå og til gengæld forklare.
Og hvis du føler, du skal brug MERGE , vær venlig ikke at @ mig; enten har du en god grund (måske har du brug for en obskur MERGE -kun funktionalitet), ellers tog du ikke ovenstående links seriøst.