Sidste år bloggede Andy Mallon om at udvide en kolonne fra int til bigint uden nedetid. (Hvorfor dette ikke kun er en metadata-operation i moderne versioner af SQL Server er uden for mig, men det er et andet indlæg.)
Normalt, når vi beskæftiger os med dette problem, er de brede og massive tabeller (i både rækkeantal og ren størrelse), og den kolonne, vi skal ændre, er den eneste/ledende kolonne i klyngingsnøglen. Der er typisk også andre komplikationer involveret - indgående fremmednøglebegrænsninger, masser af ikke-klyngede indekser og en travl database, der er ultrafølsom over for logaktivitet (fordi den er involveret i ændringssporing, replikering, tilgængelighedsgrupper eller alle tre ).
Af denne grund er vi nødt til at tage en tilgang som Andy skitserede, hvor vi bygger en skyggetabel med det nye skema, skaber triggere for at holde begge kopier synkroniseret og derefter batch/udfylder i det teams eget tempo, indtil de er klar til at bytte i kopien som den ægte vare.
Men jeg er doven!
Der er nogle tilfælde, hvor du kan ændre kolonnen direkte, hvis du har råd til et lille vindue med nedetid/blokering, og det bliver en meget enklere operation. I sidste uge dukkede et sådant tilfælde op, med en tabel over 1 TB, men kun 100.000 rækker. Næsten alle data var off-row (LOB), de havde råd til et lille vindue med nedetid, hvis det var nødvendigt, og de planlagde at deaktivere ændringssporing og omkonfigurere den alligevel. Jeg var sikker på, at genskabelse af den klyngede PK ikke behøvede at røre LOB-dataene (meget), foreslog jeg, at dette kunne være et tilfælde, hvor vi bare kan anvende ændringen direkte.
I et isoleret scenarie (ingen indgående fremmednøgler, ingen yderligere indekser, ingen aktiviteter afhængigt af log-læseren og ingen bekymringer om samtidighed), satte jeg nogle test sammen for i et vakuum at se, hvad denne ændring ville kræve med hensyn til varighed og indvirkning på transaktionsloggen. Hovedspørgsmålet, jeg ikke vidste, hvordan jeg skulle besvare på forhånd, var:"Hvad er de trinvise omkostninger ved at opdatere tabeller på stedet, når der er store mængder ikke-nøgledata?"
Jeg vil prøve at pakke en masse ind i et indlæg her. Jeg testede en masse, og det hele hænger sammen, selvom ikke alle testscenarier gælder for dig. Vær venlig at bære over med mig.
Tabellene
Jeg oprettede 6 tabeller, inklusive en baseline, der kun havde nøglekolonnen, en tabel med 4K lagret i rækken og derefter fire tabeller hver med en varchar(max) kolonne udfyldt med varierende mængder strengdata (4K, 16K, 64K og 256K).
CREATE TABLE dbo.withJustId( id int NOT NULL, CONSTRAINT pk_withJustId PRIMÆR NØGLE KLYNGET (id)); OPRET TABEL dbo.withoutLob( id int NOT NULL, extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withoutLob PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob004( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)), CONSTRAINT pk_withLob004 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob016( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)), CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob064 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)), CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)); CREATE TABLE dbo.withLob256 ( id int NOT NULL, extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)), CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id));
Jeg fyldte hver med 100.000 rækker:
INSERT dbo.withJustId (id) SELECT TOP (100000) id =ROW_NUMBER() OVER (ORDER BY c1.name) FRA sys.all_columns AS c1 CROSS JOIN sys.all_objects; INSERT dbo.withoutLob (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId;INSERT dbo.withLob)SELECT064 id FROM dbo.withJustId;INSERT dbo.withLob256 (id) SELECT id FROM dbo.withJustId;
Jeg erkender, at ovenstående er urealistisk; hvor ofte har vi en tabel, der kun er en identifikator + LOB-data? Jeg kørte testene igen med disse yderligere fire kolonner for at give ikke-LOB-datasiderne lidt mere virkelighed:
fill1 char(320) NOT NULL DEFAULT ('x'), count1 int NOT NULL DEFAULT (0), count2 int NOT NULL DEFAULT (0), dt datetime2 NOT NULL DEFAULT sysutcdatetime(),
Disse tabeller er kun lidt større med hensyn til samlet størrelse, men den proportionale stigning i mængden af ikke-LOB-data (ikke illustreret i dette diagram) er den store, men skjulte forskel:
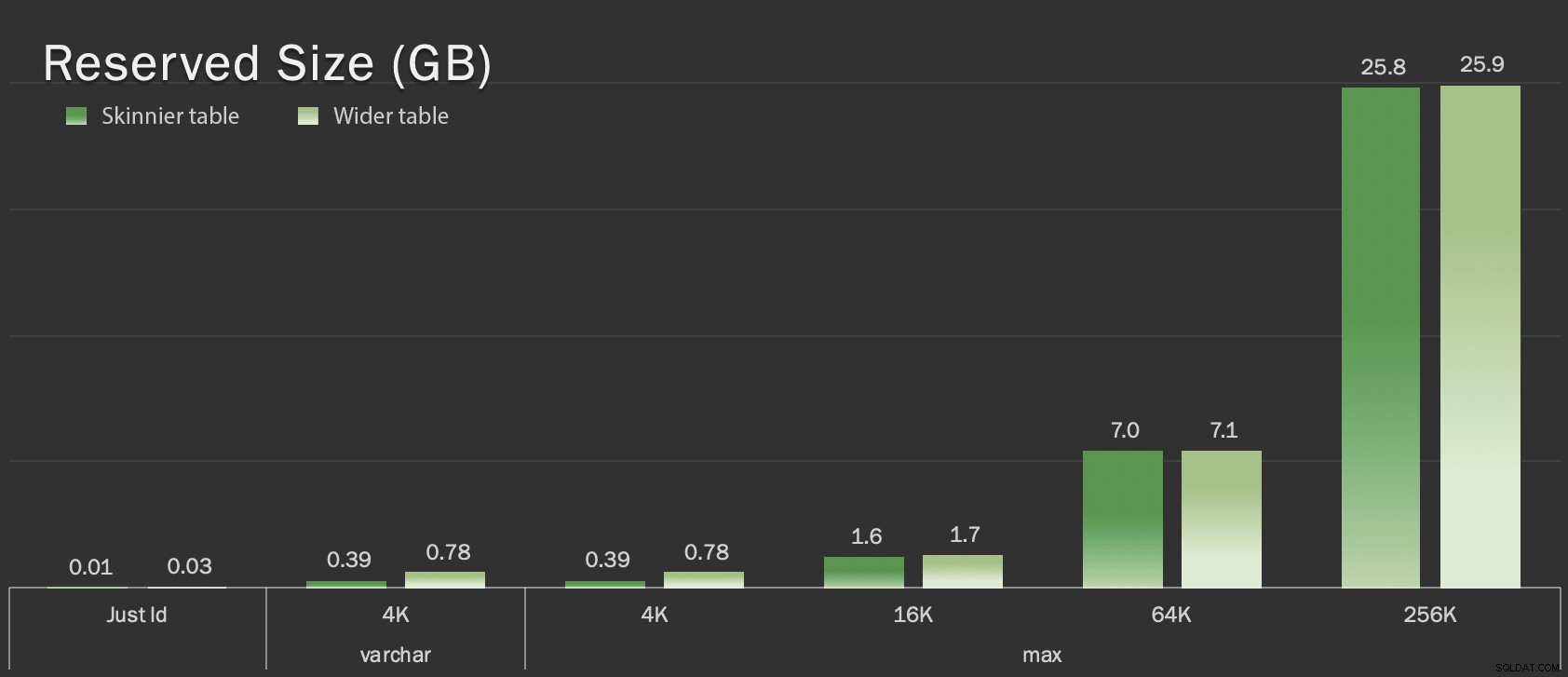 Reserveret størrelse af tabeller, i GB
Reserveret størrelse af tabeller, i GB
Testene
Derefter timede og indsamlede jeg logdata for hver af disse operationer (med og uden ONLINE = ON ) mod hver variation af tabellen:
ÆNDRINGSTABEL dbo. DROP CONSTRAINT pk_; ALTER TABLE dbo. ALTER COLUMN id bigint IKKE NULL; -- MED (ONLINE =TIL); ÆNDRINGSTABEL dbo. TILFØJ BEGRÆNSNING pk_ PRIMÆR NØGLE KLYNGET (id);
I virkeligheden brugte jeg dynamisk SQL til at generere alle disse tests, så jeg ikke fikslet manuelt med scripts før hver test.
I et andet indlæg vil jeg dele den dynamiske SQL, jeg brugte til at generere disse tests, og samle timingen for hvert trin.
Til sammenligning testede jeg også Andys metode (omend uden batching, og kun på den tynde version af bordet):
OPRET TABEL dbo._kopi (id bigint IKKE NULL -- <, ekstradatakolonne, når det er relevant> BEGRÆNSNING pk_kopi_ PRIMÆR NØGLE KLUSTERET (id)); INSERT dbo._kopi SELECT * FRA dbo.; EXEC sys.sp_rename N'dbo.', N'dbo._old', N'OBJECT';EXEC sys.sp_rename N'dbo._copy', N'dbo.' , N'OBJECT';
Jeg sprang over de bredere borde her; Jeg ønskede ikke at introducere kompleksiteten af kodning og måling af batch-operationer. Det åbenlyse smertepunkt her er, at i modsætning til at ændre kolonnen på stedet, skal du med skyggemetoden kopiere hver enkelt byte af de LOB-data. Batching kan minimere den store effekt af at forsøge at gøre det i en enkelt transaktion, men al den blanding skal til sidst laves om nedstrøms. Batching ved kilden kan ikke helt kontrollere, hvor meget det vil gøre ondt på destinationen.
Resultaterne
De første resultater, jeg vil vise, er kun den gennemsnitlige varighed for ændringer på stedet, for alle 12 tabelkonfigurationer og med og uden ONLINE = ON :
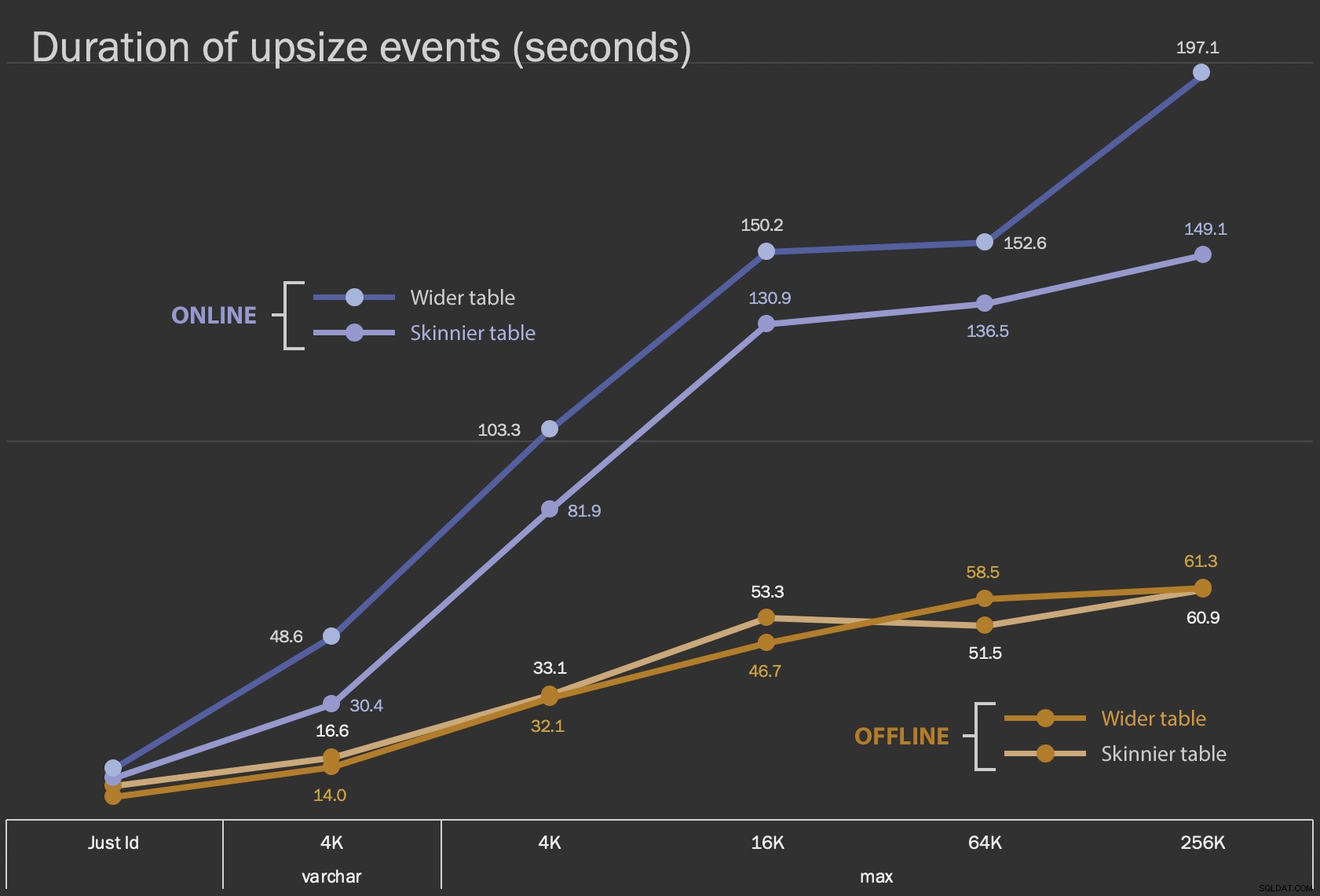 Varighed, i sekunder, af ændring af kolonnen på plads
Varighed, i sekunder, af ændring af kolonnen på plads
At udføre dette som en online operation tager længere tid (200 sekunder i værste fald), men blokerer ikke brugere. Det ser ud til at stige sammen med størrelsen, men ikke helt lineært. Udførelse af denne handling offline forårsager blokering, men er meget hurtigere og ændrer sig ikke helt så drastisk, efterhånden som bordet bliver større (selv ved den største størrelse skete dette stadig på omkring et minut).
Det er vanskeligt at sammenligne disse operationer på stedet med swap og drop operationen ved at bruge et linjediagram på grund af den enorme forskel i skala. I stedet vil jeg vise et vandret søjlediagram for den varighed, der er involveret i hver tabelkonfiguration. Når genskabelsen er hurtigere, maler jeg den rækkes baggrund grøn; når det er langsommere (eller falder mellem offline- og onlinemetoden), behøver jeg nok ikke, men jeg maler den rækkes baggrund rød.
| LOB-størrelse | Tilgang | Tabelkonfiguration | Varighed (sekunder) | ||
|---|---|---|---|
| Just Id | ALTER Offline | Skinnere bord (10 MB) | 8.8 |
| Større bord (30 MB) | 6.3 | ||
| ALTER Online | Slankere bord | 11.0 | |
| Bredere tabel | 13.6 | ||
| Genopret | Slankere bord | 3.4 | |
| varchar 4K | Offline | Skinnere bord (390 MB) | 16.6 |
| Større bord (780 MB) | 14.0 | ||
| Online | Slankere bord | 30.4 | |
| Bredere tabel | 48.6 | ||
| Genopret | Slankere bord | 1.290,0 | |
| maks. 4k | Offline | Skinnere bord (390 MB) | 33.1 |
| Større bord (780 MB) | 32.1 | ||
| Online | Slankere bord | 81.9 | |
| Bredere tabel | 103.3 | ||
| Genopret | Slankere bord | 28.9 | |
| maks. 16k | Offline | Skinnere bord (1,6 GB) | 53.3 |
| Bredere bord (1,7 GB) | 46.7 | ||
| Online | Slankere bord | 130.9 | |
| Bredere tabel | 150.2 | ||
| Genopret | Slankere bord | 81.8 | |
| maks. 64k | Offline | Skinmer bord (7,0 GB) | 51.5 |
| Bredere bord (7,1 GB) | 58.5 | ||
| Online | Slankere bord | 136.5 | |
| Bredere tabel | 152.6 | ||
| Genopret | Slankere bord | 226.5 | |
| maks. 256k | Offline | Skinnere bord (25,8 GB) | 60.9 |
| Bredere bord (25,9 GB) | 61.3 | ||
| Online | Slankere bord | 149.1 | |
| Bredere tabel | 197.1 | ||
| Genopret | Slankere bord | 1.576,7 | |
Dette er en uretfærdig rystelse af Andys metode, fordi – i den virkelige verden – ville du ikke udføre hele den operation i ét skud. Jeg viste ikke brug af transaktionslog her for kortheds skyld, men det ville også være nemmere at kontrollere det gennem batching i en side-by-side operation. Selvom hans tilgang kræver mere arbejde i forvejen, er det meget sikrere med hensyn til nedetid og/eller blokering. Men du kan se i tilfælde, hvor du har mange off-row-data og har råd til et kort afbrydelse, at det er meget mindre smertefuldt at ændre kolonnen direkte. "For stor til at ændre på stedet" er subjektiv og kan give forskellige resultater afhængigt af, hvad "stor" betyder. Før du forpligter dig til en tilgang, kan det være fornuftigt at teste ændringen mod en rimelig kopi, fordi den på stedet-operationen kan repræsentere en acceptabel afvejning.
Konklusion
Jeg skrev ikke dette for at skændes med Andy. Fremgangsmåden i det originale indlæg er sund, 100 % pålidelig, og vi bruger den hele tiden. Når brute force dog værdsættes over kirurgisk præcision, og især hvis du kan tage et stykke nedetid, kan der være værdi i den enklere tilgang til visse bordformer.