Denne artikel er sjette del i en serie om tabeludtryk. Sidste måned i del 5 dækkede jeg den logiske behandling af ikke-rekursive CTE'er. I denne måned dækker jeg den logiske behandling af rekursive CTE'er. Jeg beskriver T-SQL's understøttelse af rekursive CTE'er, samt standardelementer, der endnu ikke understøttes af T-SQL. Jeg leverer logisk ækvivalente T-SQL-løsninger til de ikke-understøttede elementer.
Eksempel på data
Til eksempeldata vil jeg bruge en tabel kaldet Medarbejdere, som indeholder et hierarki af medarbejdere. Den empid-kolonnen repræsenterer medarbejder-id'et for den underordnede (den underordnede node), og mgrid-kolonnen repræsenterer lederens medarbejder-id (den overordnede knude). Brug følgende kode til at oprette og udfylde tabellen Medarbejdere i tempdb-databasen:
INDSTIL ANTAL TIL; BRUG tempdb;DROP TABLE HVIS FINDER dbo.Employees;GO OPRET TABEL dbo.Employees( empid INT IKKE NULL BEGRÆNSNING PK_Employees PRIMÆR NØGLE, mgrid INT NULL BEGRÆNSNING FK_Employees_Employees_Employees deb. NULLE CHECK (empid <> mgrid)); INSERT INTO dbo.Employees(empid, mgrid, empname, salary) VALUES(1, NULL, 'David' , $10000.00), (2, 1, 'Eitan' , $7000.00), (3, 1, 'Ina' , $7500.00) , (4, 2, 'Seraph' , $5000.00), (5, 2, 'Jiru' , $5500.00), (6, 2, 'Steve' , $4500.00), (7, 3, 'Aaron' , $5000.00), ( 8, 5, 'Lilach' , $3500.00), (9, 7, 'Rita' , $3000.00), (10, 5, 'Sean' , $3000.00), (11, 7, 'Gabriel', $3000.00), (12, 9, 'Emilia' , $2000,00), (13, 9, 'Michael', $2000,00), (14, 9, 'Didi', $1500,00); OPRET UNIKT INDEX idx_unc_mgrid_empid PÅ dbo.Employees(mgrid, empid) INCLUDE(empname, løn);
Bemærk, at roden af medarbejderhierarkiet – den administrerende direktør – har en NULL i mgrid-kolonnen. Alle de øvrige medarbejdere har en leder, så deres mgrid-kolonne er indstillet til deres leders medarbejder-id.
Figur 1 har en grafisk afbildning af medarbejderhierarkiet, der viser medarbejdernavnet, ID og dets placering i hierarkiet.
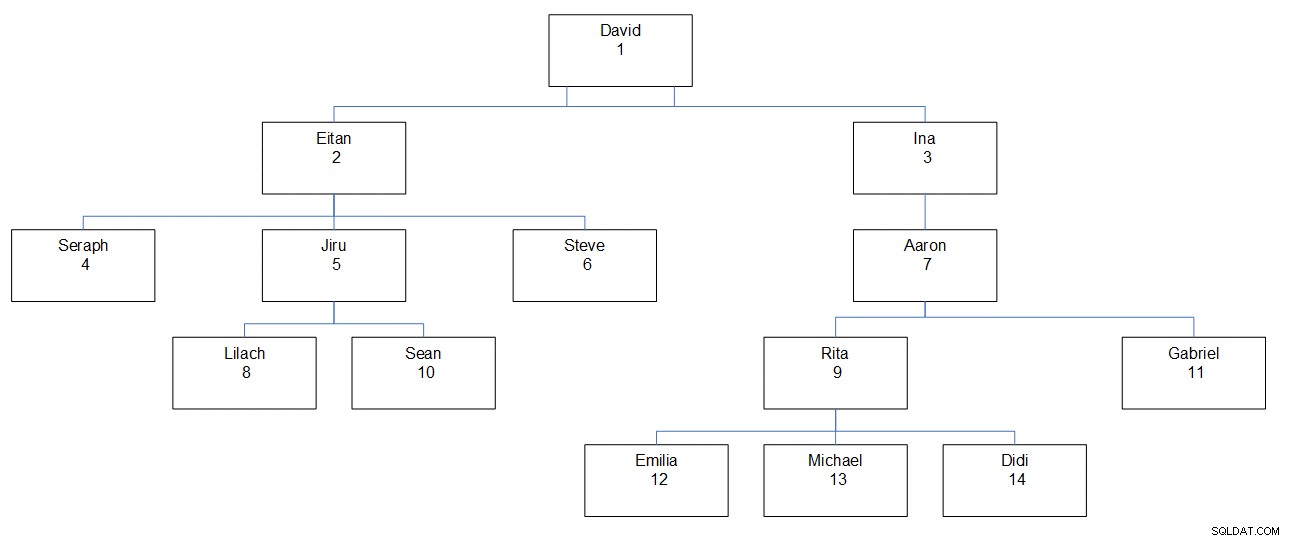 Figur 1:Medarbejderhierarki
Figur 1:Medarbejderhierarki
Rekursive CTE'er
Rekursive CTE'er har mange use cases. En klassisk kategori af anvendelser har at gøre med håndtering af grafstrukturer, som vores medarbejderhierarki. Opgaver, der involverer grafer, kræver ofte at krydse stier med vilkårlig længde. For eksempel, givet medarbejder-id'et for en leder, returner inputmedarbejderen, såvel som alle underordnede af inputmedarbejderen på alle niveauer; dvs. direkte og indirekte underordnede. Hvis du havde en kendt lille grænse for antallet af niveauer, som du muligvis skal følge (graden af grafen), kunne du bruge en forespørgsel med en joinforbindelse pr. niveau af underordnede. Men hvis graden af grafen er potentielt høj, bliver det på et tidspunkt upraktisk at skrive en forespørgsel med mange joinforbindelser. En anden mulighed er at bruge imperativ iterativ kode, men sådanne løsninger har tendens til at være langvarige. Det er her, rekursive CTE'er virkelig skinner - de gør dig i stand til at bruge deklarative, kortfattede og intuitive løsninger.
Jeg starter med det grundlæggende i rekursive CTE'er, før jeg kommer til de mere interessante ting, hvor jeg dækker søge- og cykelmuligheder.
Husk, at syntaksen for en forespørgsel mod en CTE er som følger:
MEDAS
(
)
Her viser jeg en CTE defineret ved hjælp af WITH-sætningen, men som du ved, kan du definere flere CTE'er adskilt af kommaer.
I almindelige, ikke-rekursive CTE'er er det indre tabeludtryk baseret på en forespørgsel, der kun evalueres én gang. I rekursive CTE'er er det indre tabeludtryk baseret på typisk to forespørgsler kendt som medlemmer , selvom du kan have mere end to til at håndtere nogle specielle behov. Medlemmerne adskilles typisk af en UNION ALL-operatør for at angive, at deres resultater er ensartede.
Et medlem kan være et ankermedlem — hvilket betyder, at det kun evalueres én gang; eller det kan være et rekursivt medlem — hvilket betyder, at det evalueres gentagne gange, indtil det returnerer et tomt resultatsæt. Her er syntaksen for en forespørgsel mod en rekursiv CTE, der er baseret på et ankermedlem og et rekursivt medlem:
MEDAS
(
UNION ALLE
)
Det, der gør et medlem rekursivt, er at have en reference til CTE-navnet. Denne reference repræsenterer den sidste udførelses resultatsæt. I den første udførelse af det rekursive medlem repræsenterer referencen til CTE-navnet ankermedlemmets resultatsæt. I den N'te udførelse, hvor N> 1, repræsenterer referencen til CTE-navnet resultatsættet af (N – 1) udførelsen af det rekursive medlem. Som nævnt, når det rekursive medlem returnerer et tomt sæt, udføres det ikke igen. En reference til CTE-navnet i den ydre forespørgsel repræsenterer de forenede resultatsæt af den enkelte udførelse af ankermedlemmet og alle udførelserne af det rekursive medlem.
Følgende kode implementerer den førnævnte opgave med at returnere undertræet af medarbejdere for en given input manager, idet medarbejder ID 3 videregives som root-medarbejder i dette eksempel:
DECLARE @root AS INT =3; WITH C AS( SELECT empid, mgrid, empname FRA dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid)SELECT empid, mgrid, empnameFROM C;
Ankerforespørgslen udføres kun én gang og returnerer rækken for input-rodmedarbejderen (medarbejder 3 i vores tilfælde).
Den rekursive forespørgsel slutter sig til sættet af medarbejdere fra det tidligere niveau – repræsenteret ved referencen til CTE-navnet, kaldet M for ledere – med deres direkte underordnede fra tabellen Medarbejdere, kaldet S for underordnede. Join-prædikatet er S.mgrid =M.empid, hvilket betyder, at underordnets mgrid-værdi er lig med lederens empid-værdi. Den rekursive forespørgsel udføres fire gange som følger:
- Returner underordnede af medarbejder 3; output:medarbejder 7
- Returner underordnede af medarbejder 7; output:medarbejdere 9 og 11
- Returner underordnede af medarbejdere 9 og 11; output:12, 13 og 14
- Returner underordnede af medarbejdere 12, 13 og 14; output:tomt sæt; rekursion stopper
Referencen til CTE-navnet i den ydre forespørgsel repræsenterer de samlede resultater af den enkelte udførelse af ankerforespørgslen (medarbejder 3) med resultaterne af alle udførelser af den rekursive forespørgsel (medarbejdere 7, 9, 11, 12, 13 og 14). Denne kode genererer følgende output:
empid mgrid empname------ ------ --------3 1 Ina7 3 Aaron9 7 Rita11 7 Gabriel12 9 Emilia13 9 Michael14 9 Didi
Et almindeligt problem i programmeringsløsninger er løbsk kode som uendelige sløjfer, der typisk er forårsaget af en fejl. Med rekursive CTE'er kan en fejl føre til en baneudførelse af det rekursive medlem. Antag for eksempel, at du i vores løsning til at returnere underordnede af en inputmedarbejder havde en fejl i det rekursive medlems join-prædikat. I stedet for at bruge ON S.mgrid =M.empid, brugte du ON S.mgrid =S.mgrid, sådan:
DECLARE @root AS INT =3; WITH C AS( SELECT empid, mgrid, empname FRA dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =S .mgrid)SELECT empid, mgrid, empnameFROM C;
Givet mindst én medarbejder med et ikke-null manager-id til stede i tabellen, vil udførelsen af det rekursive medlem blive ved med at returnere et ikke-tomt resultat. Husk, at den implicitte opsigelsesbetingelse for det rekursive medlem er, når dets udførelse returnerer et tomt resultatsæt. Hvis det returnerer et ikke-tomt resultatsæt, udfører SQL Server det igen. Du indser, at hvis SQL Server ikke havde en mekanisme til at begrænse de rekursive eksekveringer, ville den bare blive ved med at udføre det rekursive medlem gentagne gange for evigt. Som en sikkerhedsforanstaltning understøtter T-SQL en MAXRECURSION-forespørgselsindstilling, der begrænser det maksimalt tilladte antal henrettelser af det rekursive medlem. Som standard er denne grænse sat til 100, men du kan ændre den til enhver ikke-negativ SMALLINT-værdi, hvor 0 repræsenterer ingen grænse. Indstilling af den maksimale rekursionsgrænse til en positiv værdi N betyder, at N + 1 forsøg på udførelse af det rekursive element afbrydes med en fejl. For eksempel, at køre ovenstående buggy-kode, som den er, betyder, at du stoler på standard maks. rekursionsgrænse på 100, så 101-udførelsen af det rekursive medlem mislykkes:
empid mgrid empname------ ------ --------3 1 Ina2 1 Eitan3 1 Ina...Msg 530, Level 16, State 1, Line 121
Oplysningen er afsluttet. Den maksimale rekursion 100 er opbrugt før udfyldelse af erklæringen.
Sig, at det i din organisation er sikkert at antage, at medarbejderhierarkiet ikke vil overstige 6 ledelsesniveauer. Du kan reducere den maksimale rekursionsgrænse fra 100 til et meget mindre tal, såsom 10 for at være på den sikre side, sådan:
DECLARE @root AS INT =3; WITH C AS( SELECT empid, mgrid, empname FRA dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =S .mgrid)SELECT empid, mgrid, empnameFROM COPTION (MAXRECURSION 10);
Hvis der nu er en fejl, der resulterer i en løbsk eksekvering af det rekursive medlem, vil det blive opdaget ved de 11 forsøg på at udføre det rekursive medlem i stedet for ved 101-udførelsen:
empid mgrid empname------ ------ --------3 1 Ina2 1 Eitan3 1 Ina...Msg 530, Level 16, State 1, Line 149
Oplysningen er afsluttet. Den maksimale rekursion 10 er opbrugt før udfyldelse af erklæringen.
Det er vigtigt at bemærke, at den maksimale rekursionsgrænse hovedsageligt skal bruges som en sikkerhedsforanstaltning for at afbryde udførelsen af buggy runaway-kode. Husk, at når grænsen overskrides, afbrydes udførelsen af koden med en fejl. Du bør ikke bruge denne mulighed til at begrænse antallet af niveauer, du skal besøge, til filtreringsformål. Du ønsker ikke, at der genereres en fejl, når der ikke er noget problem med koden.
Til filtreringsformål kan du begrænse antallet af niveauer, der skal besøges programmatisk. Du definerer en kolonne kaldet lvl, der sporer niveaunummeret for den aktuelle medarbejder sammenlignet med input-rodmedarbejderen. I ankerforespørgslen sætter du lvl-kolonnen til konstanten 0. I den rekursive forespørgsel sætter du den til managerens lvl-værdi plus 1. For at filtrere så mange niveauer under inputroden som @maxlevel, skal du tilføje prædikatet M.lvl <@ maxlevel til ON-sætningen af den rekursive forespørgsel. For eksempel returnerer følgende kode medarbejder 3 og to niveauer af underordnede af medarbejder 3:
DECLARE @root AS INT =3, @maxlevel AS INT =2; WITH C AS( SELECT empid, mgrid, empname, 0 AS lvl FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid AND M.lvl <@maxlevel)SELECT empid, mgrid, empname, lvlFROM C;
Denne forespørgsel genererer følgende output:
empid mgrid empname lvl------ -------------- ----3 1 Ina 07 3 Aaron 19 7 Rita 211 7 Gabriel 2
Standard SEARCH og CYCLE klausuler
ISO/IEC SQL-standarden definerer to meget kraftfulde muligheder for rekursive CTE'er. En er en sætning kaldet SEARCH, der styrer den rekursive søgerækkefølge, og en anden er en sætning kaldet CYCLE, der identificerer cyklusser i de gennemkørte stier. Her er standardsyntaksen for de to klausuler:
7.18Funktion
Angiv genereringen af bestillings- og cyklusdetektionsinformation i resultatet af rekursive forespørgselsudtryk.
Format
AS
SØG
DYBDE FØRST AF
CYKLUS
STANDARD
I skrivende stund understøtter T-SQL ikke disse muligheder, men i de følgende links kan du finde anmodninger om funktionsforbedring, der beder om deres optagelse i T-SQL i fremtiden, og stemme på dem:
- Tilføj understøttelse af ISO/IEC SQL SEARCH-klausul til rekursive CTE'er i T-SQL
- Tilføj understøttelse af ISO/IEC SQL CYCLE-sætning til rekursive CTE'er i T-SQL
I de følgende afsnit vil jeg beskrive de to standardmuligheder og også give logisk ækvivalente alternative løsninger, der i øjeblikket er tilgængelige i T-SQL.
SØGE-klausul
Standard SEARCH-klausulen definerer den rekursive søgerækkefølge som BREADTH FIRST eller DEPTH FIRST med nogle specificerede rækkefølgekolonne(r), og opretter en ny sekvenskolonne med ordenspositionerne for de besøgte noder. Du angiver BREADTH FIRST for at søge først på tværs af hvert niveau (bredde) og derefter ned i niveauerne (dybde). Du angiver DEPTH FIRST for at søge først ned (dybde) og derefter på tværs (bredde).
Du angiver SEARCH-sætningen lige før den ydre forespørgsel.
Jeg starter med et eksempel på bredde først rekursiv søgerækkefølge. Bare husk, at denne funktion ikke er tilgængelig i T-SQL, så du vil faktisk ikke kunne køre de eksempler, der bruger standardklausulerne i SQL Server eller Azure SQL Database. Følgende kode returnerer undertræet for medarbejder 1, der beder om en bredde første søgeordre efter empid, hvilket skaber en sekvenskolonne kaldet seqbreadth med ordenspositionerne for de besøgte noder:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FRA dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) SØG BREADTH FØRST VED empid SET seqbreadth---------------------------------------- ---- VÆLG empid, mgrid, empname, seqbreadthFROM CORDER BY seqbreadth;
Her er det ønskede output af denne kode:
empid mgrid empname seqbreadth------ ------ -------- -----------1 NULL David 12 1 Eitan 23 1 Ina 34 2 Seraph 45 2 Jiru 56 2 Steve 67 3 Aaron 78 5 Lilach 89 7 Rita 910 5 Sean 1011 7 Gabriel 1112 9 Emilia 1213 9 Michael 1314 9 Didi 14
Bliv ikke forvirret af det faktum, at seqbreadth-værdierne ser ud til at være identiske med empid-værdierne. Det er bare tilfældigt som et resultat af den måde, jeg manuelt tildelte empid-værdierne i de eksempeldata, jeg oprettede.
Figur 2 har en grafisk afbildning af medarbejderhierarkiet, med en stiplet linje, der viser bredden i første rækkefølge, hvori knudepunkterne blev søgt. Empid-værdierne vises lige under medarbejdernavnene, og de tildelte seqbreadth-værdier vises i nederste venstre hjørne af hver boks.
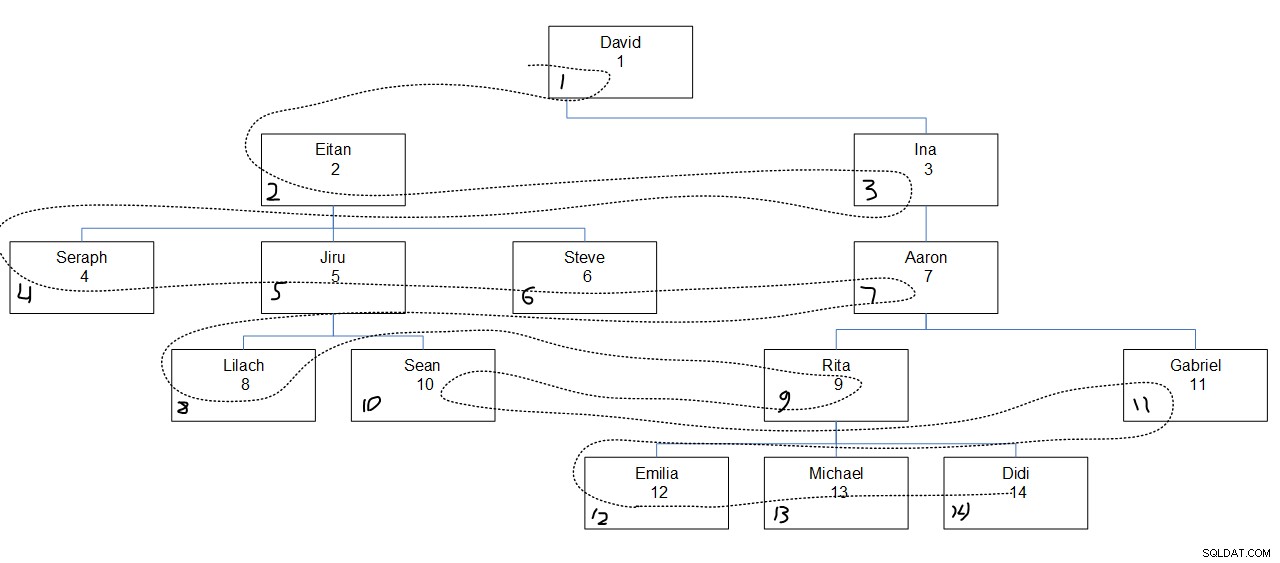 Figur 2:Søgebredde først
Figur 2:Søgebredde først
Det, der er interessant at bemærke her, er, at inden for hvert niveau søges noderne baseret på den specificerede kolonnerækkefølge (empid i vores tilfælde) uanset nodens modertilknytning. Læg for eksempel mærke til, at Lilach på det fjerde niveau får adgang først, Rita som nummer to, Sean på tredje og Gabriel sidst. Det er fordi blandt alle medarbejdere på fjerde niveau, er det deres rækkefølge baseret på deres empid værdier. Det er ikke sådan, at Lilach og Sean formodes at blive eftersøgt fortløbende, fordi de er direkte underordnede af den samme manager, Jiru.
Det er ret nemt at komme med en T-SQL-løsning, der giver den logiske ækvivalent til standardindstillingen SAERCH DEPTH FIRST. Du opretter en kolonne kaldet lvl som jeg viste tidligere for at spore niveauet af noden i forhold til roden (0 for det første niveau, 1 for det andet, og så videre). Derefter beregner du den ønskede resultatsekvenskolonne i den ydre forespørgsel ved hjælp af en ROW_NUMBER-funktion. Som vinduesbestilling angiver du først lvl og derefter den ønskede bestillingskolonne (empid i vores tilfælde). Her er den komplette løsnings kode:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, 0 AS lvl FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadthFROM CORDER BY seqbreadth;
Lad os derefter undersøge DEPTH FIRST søgerækkefølgen. I henhold til standarden skal følgende kode returnere undertræet for medarbejder 1, der beder om en dybde-første søgeordre efter empid, hvilket skaber en sekvenskolonne kaldet seqdepth med ordenspositionerne for de søgte noder:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FRA dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) SØG DYBDE FØRST VED empid SET seqdepth---------------------------------------- VÆLG empid, mgrid, empname, seqdepthFROM CORDER BY seqdepth;
Følgende er det ønskede output af denne kode:
empid mgrid empname seqdepth------ ------ -------- ----------1 NULL David 12 1 Eitan 24 2 Seraph 35 2 Jiru 48 5 Lilach 510 5 Sean 66 2 Steve 73 1 Ina 87 3 Aaron 99 7 Rita 1012 9 Emilia 1113 9 Michael 1214 9 Didi 1311 7 Gabriel 14
Når man ser på det ønskede forespørgselsoutput, er det sandsynligvis svært at finde ud af, hvorfor sekvensværdierne blev tildelt, som de var. Figur 3 burde hjælpe. Den har en grafisk afbildning af medarbejderhierarkiet med en stiplet linje, der afspejler dybdens første søgerækkefølge, med de tildelte sekvensværdier i nederste venstre hjørne af hver boks.
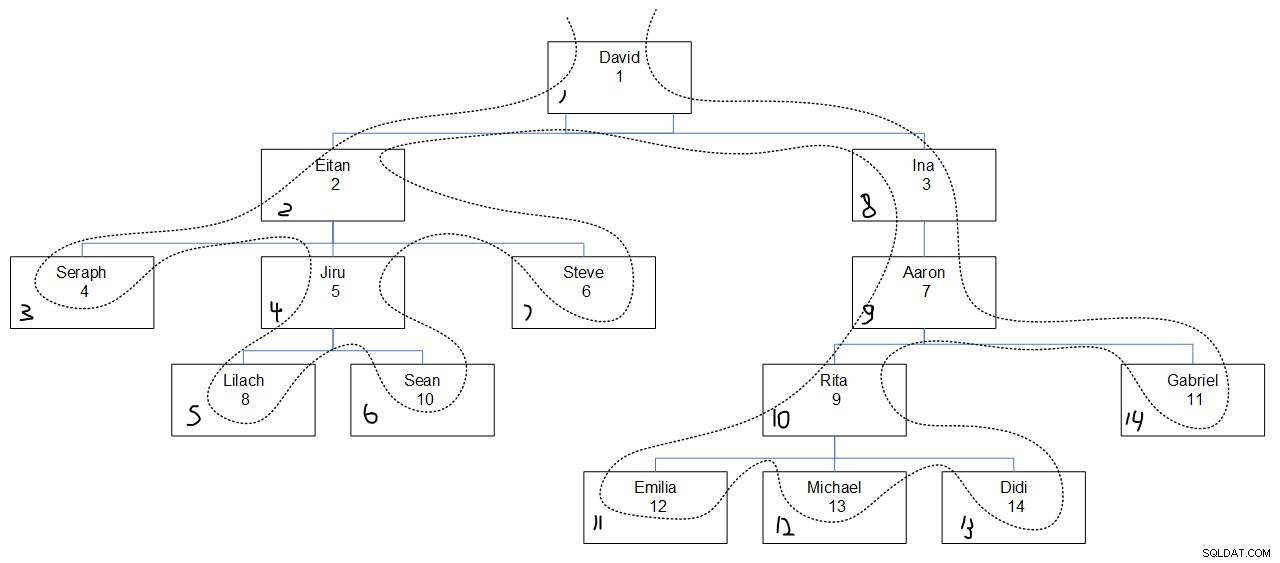 Figur 3:Søgedybde først
Figur 3:Søgedybde først
At komme med en T-SQL-løsning, der giver den logiske ækvivalent til standardindstillingen SEARCH DEPTH FIRST, er lidt vanskelig, men alligevel gennemførligt. Jeg vil beskrive løsningen i to trin.
I trin 1 beregner du for hver node en binær sorteringssti, der er lavet af et segment pr. forfader til noden, hvor hvert segment afspejler sorteringspositionen for forfaderen blandt dens søskende. Du bygger denne sti på samme måde som du beregner lvl-kolonnen. Det vil sige, start med en tom binær streng for rodnoden i ankerforespørgslen. I den rekursive forespørgsel sammenkæder du derefter overordnets sti med nodens sorteringsposition blandt søskende, efter du har konverteret den til et binært segment. Du bruger funktionen ROW_NUMBER til at beregne positionen, partitioneret af forælderen (mgrid i vores tilfælde) og ordnet efter den relevante rækkefølgekolonne (empid i vores tilfælde). Du konverterer rækkenummeret til en binær værdi af tilstrækkelig størrelse afhængigt af det maksimale antal direkte børn, som en forælder kan have i din graf. BINARY(1) understøtter op til 255 børn pr. forælder, BINARY(2) understøtter 65.535, BINARY(3):16.777.215, BINARY(4):4.294.967.295. I en rekursiv CTE skal tilsvarende kolonner i anker- og rekursive forespørgsler være af samme type og størrelse , så sørg for at konvertere sorteringsstien til en binær værdi af samme størrelse i begge.
Her er koden, der implementerer trin 1 i vores løsning (forudsat at BINARY(1) er tilstrækkelig pr. segment, hvilket betyder, at du ikke har mere end 255 direkte underordnede pr. leder):
DECLARE @root AS INT =1; MED C AS( SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FRA dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FRA C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, sortpathFROM C;
Denne kode genererer følgende output:
empid mgrid empname sortpath------ ------ -------- -----------1 NULL David 0x2 1 Eitan 0x013 1 Ina 0x027 3 Aaron 0x02019 7 RITA 0x02010111 7 GABRIEL 0X02010212 9 EMILIA 0X0201010113 9 MICHAEL 0X0201010214 9 DIDI 0X020101034 2 SERAPH 0X01015 2 JIRU 0X01026 2 STEVE 0X01038 5 LILACH 0X01010110 5 SAN 0X01020202Bemærk, at jeg brugte en tom binær streng som sorteringssti for rodknudepunktet for det enkelte undertræ, som vi forespørger her. Hvis ankermedlemmet potentielt kan returnere flere undertrærødder, skal du blot starte med et segment, der er baseret på en ROW_NUMBER-beregning i ankerforespørgslen, på samme måde som du beregner det i den rekursive forespørgsel. I et sådant tilfælde vil din sorteringssti være et segment længere.
Hvad der er tilbage at gøre i trin 2, er at oprette den ønskede resultatsøjledybde ved at beregne rækkenumre, der er sorteret efter sorteringssti i den ydre forespørgsel, som sådan
DECLARE @root AS INT =1; MED C AS( SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FRA dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FRA C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepthFROM CORDER BY seqdepth;Denne løsning er den logiske ækvivalent til at bruge standardindstillingen SEARCH DEPTH FIRST vist tidligere sammen med dens ønskede output.
Når først du har en sekvenskolonne, der afspejler dybden første søgerækkefølge (seqdepth i vores tilfælde), kan du med blot en lille smule mere indsats generere en meget flot visuel afbildning af hierarkiet. Du skal også bruge den førnævnte lvl-kolonne. Du bestiller den ydre forespørgsel efter sekvenskolonnen. Du returnerer en eller anden egenskab, som du vil bruge til at repræsentere noden (f.eks. embedsnavn i vores tilfælde), med præfiks af en streng (sig ' | ') replikeret lvl gange. Her er den komplette kode for at opnå en sådan visuel afbildning:
DECLARE @root AS INT =1; MED C AS( SELECT empid, empname, 0 AS lvl, CAST(0x AS VARBINARY(900)) AS sortpath FRA dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.empname, M.lvl + 1 AS lvl, CAST(M.sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FRA C AS M INNER JOIN DBO.Employees AS S ON S.mgrid =M.empid)SELECT empid, ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth, REPLICATE(' | ', lvl) + empname AS empFROM CORDER BY seqdepth;Denne kode genererer følgende output:
empid seqdepth emp------ ---------- --------------------1 1 David2 2 | Eitan4 3 | | Seraph5 4 | | Jiru8 5 | | | Lilach10 6 | | | Sean6 7 | | Steve3 8 | Ina7 9 | | Aaron9 10 | | | Rita12 11 | | | | Emilia13 12 | | | | Michael14 13 | | | | Didi11 14 | | | GabrielDet er ret fedt!
CYCLE-sætning
Grafstrukturer kan have cyklusser. Disse cyklusser kan være gyldige eller ugyldige. Et eksempel på gyldige cykler er en graf, der repræsenterer motorveje og veje, der forbinder byer og byer. Det er det, der omtales som en cyklisk graf . Omvendt skal en graf, der repræsenterer et medarbejderhierarki, som i vores tilfælde, ikke have cyklusser. Det er det, der omtales som en acyklisk kurve. Men antag, at du på grund af en fejlagtig opdatering ender med en cyklus utilsigtet. Antag for eksempel, at du ved en fejl opdaterer leder-id'et for den administrerende direktør (medarbejder 1) til medarbejder 14 ved at køre følgende kode:
OPDATERING Medarbejdere SET mgrid =14WHERE empid =1;Du har nu en ugyldig cyklus i medarbejderhierarkiet.
Uanset om cyklusser er gyldige eller ugyldige, når du krydser grafstrukturen, ønsker du bestemt ikke at blive ved med at forfølge en cyklisk sti gentagne gange. I begge tilfælde vil du stoppe med at forfølge en sti, når en ikke-første forekomst af den samme knude er fundet, og markere en sådan sti som cyklisk.
Så hvad sker der, når du forespørger på en graf, der har cyklusser ved hjælp af en rekursiv forespørgsel, uden nogen mekanisme på plads til at opdage dem? Dette afhænger af implementeringen. I SQL Server vil du på et tidspunkt ramme den maksimale rekursionsgrænse, og din forespørgsel vil blive afbrudt. For eksempel, hvis du antager, at du kørte ovenstående opdatering, der introducerede cyklussen, kan du prøve at køre følgende rekursive forespørgsel for at identificere undertræet for medarbejder 1:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FRA dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid)SELECT empid, mgrid, empnameFROM C;Da denne kode ikke angiver en eksplicit maksimal rekursionsgrænse, antages standardgrænsen på 100. SQL Server afbryder udførelsen af denne kode før fuldførelse og genererer en fejl:
empid mgrid empname------ ------ --------1 14 David2 1 Eitan3 1 Ina7 3 Aaron9 7 Rita11 7 Gabriel12 9 Emilia13 9 Michael14 9 Didi1 14 David2 1 Eitan3 1 Ina7 3 Aaron...Besked 530, niveau 16, tilstand 1, linje 432
Oplysningen blev afsluttet. Den maksimale rekursion 100 er opbrugt før udfyldelse af erklæringen.SQL-standarden definerer en klausul kaldet CYCLE for rekursive CTE'er, hvilket gør det muligt for dig at håndtere cyklusser i din graf. Du angiver denne klausul lige før den ydre forespørgsel. Hvis et SEARCH-udtryk også er til stede, angiver du det først og derefter CYCLE-udtrykket. Her er syntaksen for CYCLE-sætningen:
CYCLE
INDSTILTIL STANDARD
BRUGERDetekteringen af en cyklus er baseret på den specificerede cykluskolonneliste . For eksempel vil du i vores medarbejderhierarki sandsynligvis bruge empid-kolonnen til dette formål. Når den samme empid-værdi vises for anden gang, detekteres en cyklus, og forespørgslen forfølger ikke en sådan sti længere. Du angiver en ny cyklusmærkekolonne der vil indikere, om en cyklus blev fundet eller ej, og dine egne værdier som cyklusmærket og ikke-cyklusmærke værdier. For eksempel kan disse være 1 og 0 eller 'Ja' og 'Nej' eller andre værdier efter eget valg. I USING-sætningen angiver du et nyt array-kolonnenavn, der vil indeholde stien til noder fundet hidtil.
Her er, hvordan du ville håndtere en anmodning om underordnede af en input-rodmedarbejder med mulighed for at detektere cyklusser baseret på empid-kolonnen, hvilket angiver 1 i cyklusmærke-kolonnen, når en cyklus er detekteret, og 0 ellers:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname FRA dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) CYCLE empid SET cyklus TIL 1 STANDARD 0------------------------------------------- VÆLG empid, mgrid, empnameFROM C;Her er det ønskede output af denne kode:
empid mgrid empname cyklus -------------- ------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0T-SQL understøtter i øjeblikket ikke CYCLE-sætningen, men der er en løsning, der giver en logisk ækvivalent. Det involverer tre trin. Husk, at du tidligere byggede en binær sorteringssti til at håndtere den rekursive søgerækkefølge. På lignende måde bygger du som det første trin i løsningen en karakterstreng-baseret forfædresti lavet af node-id'erne (medarbejder-id'er i vores tilfælde) fra forfædrene, der fører til den aktuelle node, inklusive den nuværende node. Du vil have separatorer mellem node-id'erne, inklusive en i begyndelsen og en i slutningen.
Her er koden til at bygge sådan en forfædresti:
DECLARE @root AS INT =1; MED C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FRA dbo.Medarbejdere WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FRA C AS M INNER JOIN dbo.Medarbejdere AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpathFROM C;Denne kode genererer følgende output, forfølger stadig cykliske stier og afbryder derfor før færdiggørelsen, når den maksimale rekursionsgrænse er overskredet:
empid mgrid empname ancpath------ ------ -------- --------------------1 14 David . 1.2 1 Eitan .1.2.3 1 Ina .1.3.7 3 Aaron .1.3.7.9 7 Rita .1.3.7.9.11 7 Gabriel .1.3.7.11.12 9 Emilia .1.3.7.9.12.13 9 Michael .1. 13.14 9 Didi .1.3.7.9.14.1 14 David .1.3.7.9.14.1.2 1 Eitan .1.3.7.9.14.1.2.3 1 Ina .1.3.7.9.14.1.3.7 3 Aaron .1.3.7. ...Msg 530, Level 16, State 1, Line 492
Oplysningen blev afsluttet. Den maksimale rekursion 100 er opbrugt før udfyldelse af erklæringen.Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path
'.1.3.7.9.14.1.'.In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpath, cycleFROM C;This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle------ ------ -------- ------------------- ------1 14 David .1. 02 1 Eitan .1.2. 03 1 Ina .1.3. 07 3 Aaron .1.3.7. 09 7 Rita .1.3.7.9. 011 7 Gabriel .1.3.7.11. 012 9 Emilia .1.3.7.9.12. 013 9 Michael .1.3.7.9.13. 014 9 Didi .1.3.7.9.14. 01 14 David .1.3.7.9.14.1. 12 1 Eitan .1.3.7.9.14.1.2. 03 1 Ina .1.3.7.9.14.1.3. 17 3 Aaron .1.3.7.9.14.1.3.7. 1...Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid AND M.cycle =0)SELECT empid, mgrid, empname, cycleFROM C;This code runs to completion, and generates the following output:
empid mgrid empname cycle------ ------ -------- -----------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees SET mgrid =NULLWHERE empid =1;Run the recursive query and you will find that there are no cycles present.
Konklusion
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.