Sidste fredag holdt jeg et webinar om Plan Explorer 3.0, de nye funktioner, og hvorfor vi besluttede at eliminere PRO-udgaven og give alle funktionerne væk gratis . Hvis du gik glip af det, kan du se webinaret her:
- Plan Explorer 3.0-webinar
Der blev stillet mange gode spørgsmål, og dem vil jeg prøve at besvare her. Vi stillede også et par af vores egne spørgsmål på forskellige tidspunkter under præsentationen, og brugerne bad om detaljer om dem, så jeg starter med undersøgelsesspørgsmålene. Vi havde et højdepunkt på 502 deltagere, og jeg vil angive på skemaerne nedenfor, hvor mange mennesker der besvarede hvert spørgsmål. Da det første spørgsmål blev stillet før webinaret teknisk startede, svarede et mindre antal personer på det.
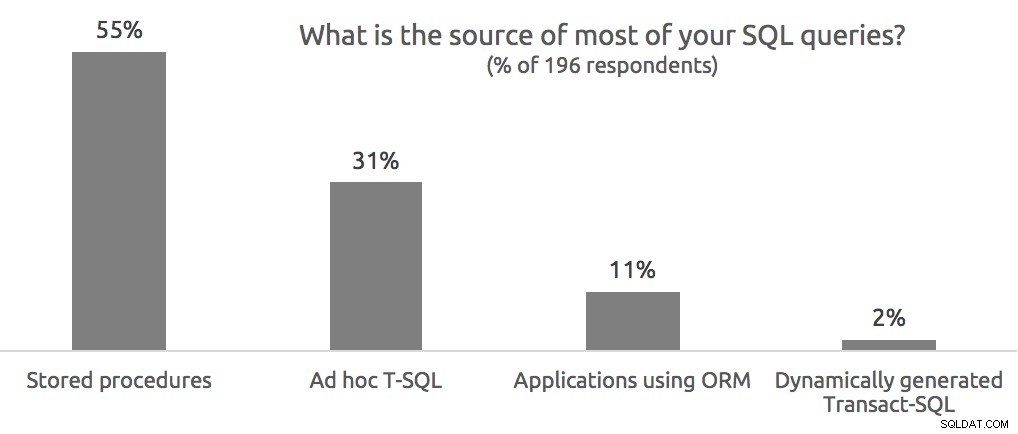
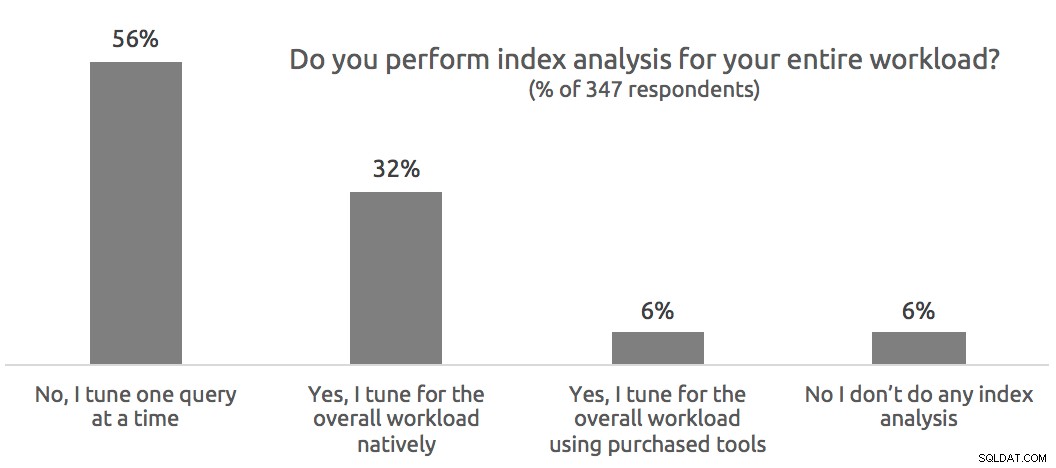
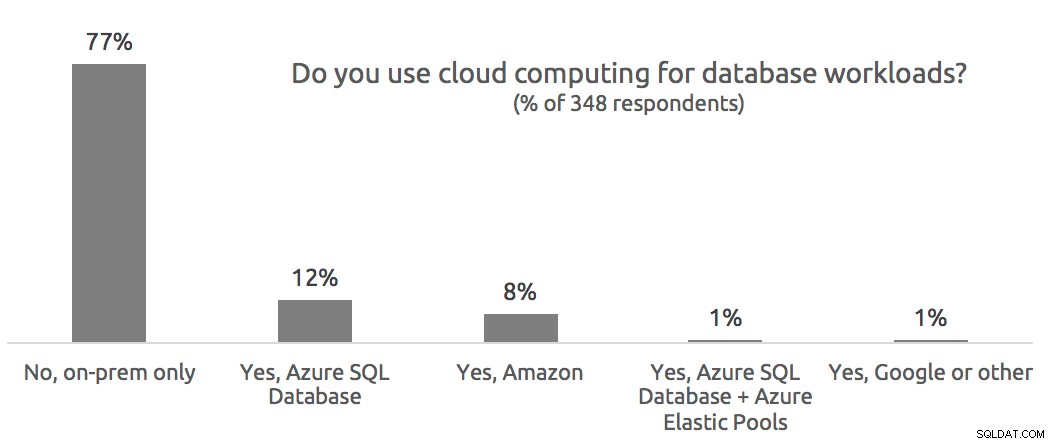
Spørgsmål fra publikum
Sp.:Er kodeeksemplerne tilgængelige?
A: Ja, de tre sessionsfiler, jeg brugte til mine demoer, er tilgængelige her:
- Plan Explorer 3.0 Webinar-demoer
Du kan åbne disse i den seneste build af Plan Explorer, men hvis du vil køre nogen af forespørgslerne igen lokalt, skal du bruge AdventureWorks2014 (med det forstørrende script fra Jonathan Kehayias) og/eller den nye Wide World Importers-eksempeldatabase.
Sp:Så alt, der vises i dag, er i den nye, samlede, gratis Plan Explorer? Hvis ja, hvad er din virksomheds nye indtægtsmodel?A: Jeg bliver altid overrasket, når jeg støder på folk, der tror, at alt, hvad vi tilbyder, er Plan Explorer (jeg ser disse personligt, og der var også flere lignende kommentarer på Gregs blogindlæg). Vores rigtige brød og smør er i vores overvågningsplatform, og vi håber, at din positive oplevelse med Plan Explorer også vil få dig til at prøve vores andre løsninger.
Sp:Vi bruger stadig SQL Server 2008. Er der fordele ved at bruge PE vs. SSMS?A: Ja, mens du vil gå glip af nogle af funktionerne (såsom Live Query Profile), er der meget mere information tilgængelig for dig sammenlignet med SSMS, og vi gør vores bedste for at gøre specifikke problemer meget mere synlige.
Sp:Fungerer Live Query Profile for SQL Server 2014?A: Ja, så længe Service Pack 1 anvendes, da funktionen er afhængig af en DMV, der blev tilføjet i SQL Server 2014 SP1.
Sp:Hvad er begrænsningerne med hensyn til SQL Server 2012? Kan jeg overhovedet bruge dette værktøj?A: Absolut. Den begrænsning, jeg tog op under webinaret om SQL Server 2012 og lavere, er, at de ikke er i stand til at fange Live Query Profile-data.
Sp:Er dataene kun indsamlet til SQL Server 2014 og nyere? Hvad hvis SQL Server 2014 er installeret, men kompatibiliteten er indstillet til 2012?A: Ja, Live Query Profile (og ressourcediagrammerne) fungerer i SQL Server 2014 (med mindst SP1), SQL Server 2016 og Azure SQL Database. Det er upåvirket af kompatibilitetsniveau.
Sp:Hvilken version af SQL Server er nødvendig for at få oplysninger om ventestatistikker tilbage?
A: Indsamling af ventestatistikker er afhængig af en udvidet hændelsessession, så du skal køre mod SQL Server 2008 eller nyere og køre i konteksten af en bruger eller login med tilstrækkelige tilladelser til at oprette og droppe en udvidet hændelsessession (CONTROL SERVER i SQL Server 2008 og 2008 R2, og ALTER ANY EVENT SESSION i SQL Server 2012 og nyere).
A: Der var mange variationer på disse to spørgsmål, og ud fra lyden af det legede folk aktivt med den nye version under webinaret og så hverken indeksanalysedata eller liveforespørgselsprofildata. Hvis du har en eksisterende plan hentet fra SSMS eller en tidligere version af Plan Explorer, vil der ikke være nogen information at vise.
For at indsamle indeksanalyse data, skal du generere en estimeret eller faktisk plan fra Plan Explorer. For at se et kolonne- og indeksgitter skal du vælge en valgt handling:i rullemenuen øverst på fanen Indeksanalyse.
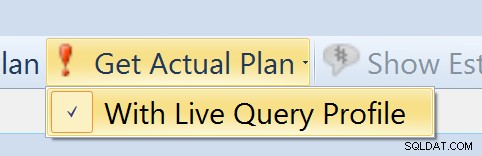
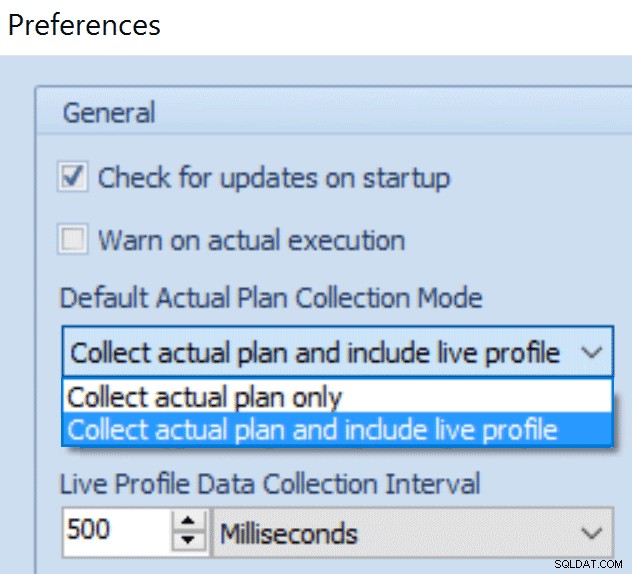
For at indsamle Live Query Profile data, skal du generere en faktisk plan fra Plan Explorer, og køre mod 2014 SP1 eller bedre. Du skal også sikre dig, at du har valgt indstillingen "Med Live Query Profile" (se billedet til højre), og vente på, at forespørgselsudførelsen er færdig, før diagrammerne gengives. I en fremtidig version gengives diagrammet i realtid, men i denne udgivelse gør vi det, når alle data er blevet indsamlet.
Sp:Fungerer Live Query Profile mod klonede databaser i SQL Server 2014 SP2?A: Ja, dette vil virke, men det vil ikke give meget information, da en klonet database er tom – du vil se de rigtige estimater i planen, men de faktiske værdier vil alle være 0, og derfor repræsenterer runtime-metrikkene ikke nogen realistisk eller meningsfulde flaskehalse. Medmindre du udfylder klonen med alternative data, som Erin Stellato promoverer i et tidligere indlæg. Bemærk også, at hvis du ønsker, at forespørgselsplaner skal afspejle reelle produktionsdatastørrelser, skal du sørge for, at alle former for autostatistik er slået fra, ellers vil de blive opdateret, mens du kører forespørgsler, og så vil alle estimater være 0.
Sp:Fungerer den nye version af Plan Explorer med SQL Server 2016?A: Ja. Vi understøtter alle de nye SQL Server 2016 plan operatører og andre showplan ændringer (se mit indlæg, "Plan Explorer Support for SQL Server 2016"), og tilføjelsen fungerer også med den seneste version af SSMS (se mit indlæg, "Annoncing Plan Explorer Add-In Support for SSMS 2016").
Sp:Så selv en faktisk eksekveringsplan i SSMS er mærket med estimeret omkostninger?A: Ja det er rigtigt. Når du fanger Live Query Profile-data, kan vi ændre omkostningsprocenterne for alle operatørerne, fordi vi med en betydelig grad af nøjagtighed ved, hvor meget faktisk arbejde hver operation udførte (forespørgslen skal dog køre længere end en tærskelværdi). Dette kan især være nyttigt, hvis du fejlfinder et I/O-problem, fordi estimaterne aldrig ser ud til at tage højde for I/O-flaskehalse. Følgende grafik gennemgår de originale estimater (vi kan altid vise dig, hvad SSMS ville have fortalt dig), de faktiske værdier efter omregning og de faktiske værdier efter omkostning og ændring af omkostninger til "ved I/O" og linjebredder til "efter datastørrelse":
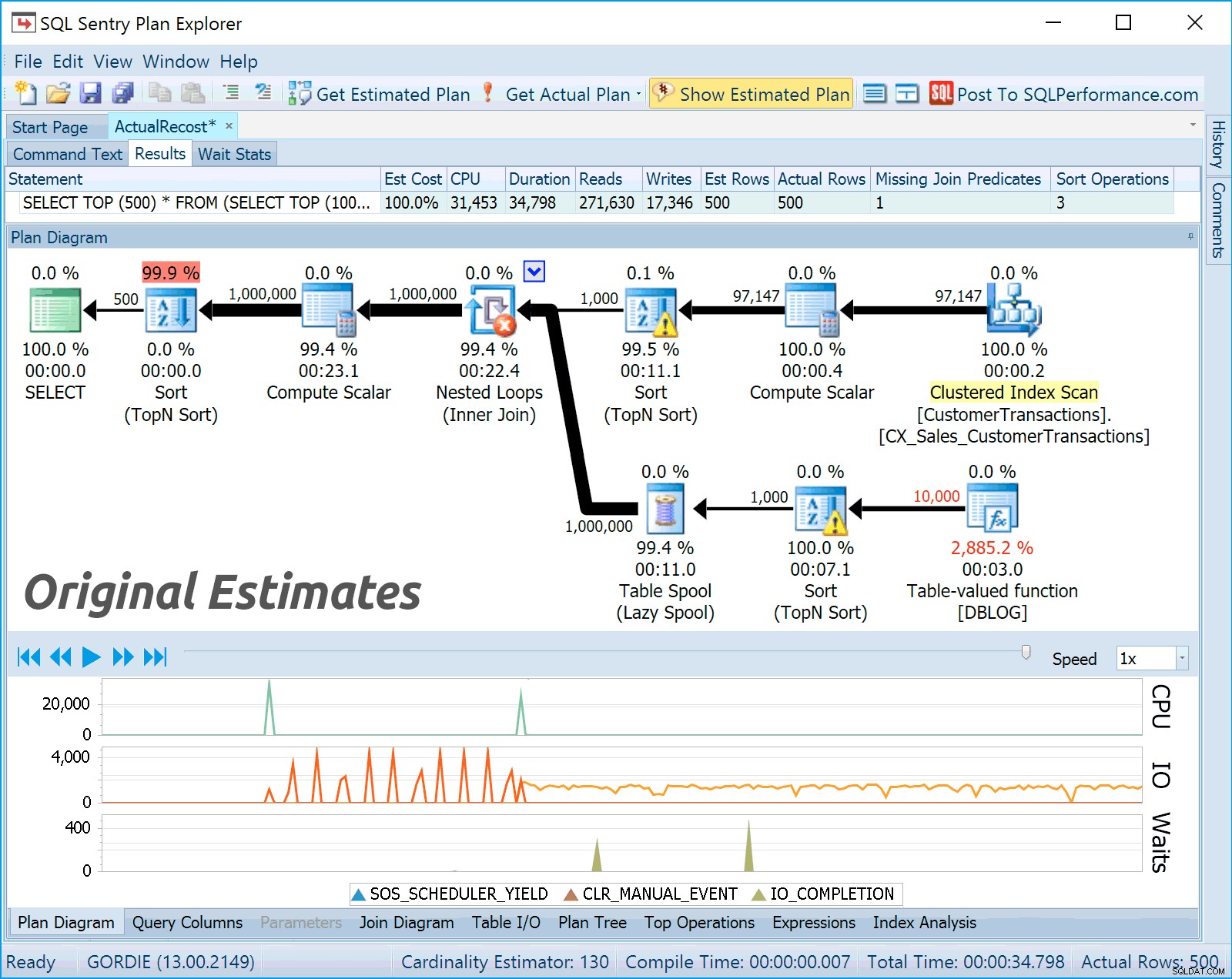
A: Jeg behandlede dette spørgsmål i webinaret, men for at være klar, tror jeg, at der er to trin i udviklingen af en forespørgsel:(1) sikring af korrekte resultater og (2) optimering af ydeevne. Jeg er overbevist om, at du i øjeblikket skal bruge SSMS til (1) og Plan Explorer for (2). Jeg har længe promoveret, at når folk er sikre på, at de har de rigtige resultater, bør de tune ved at generere faktiske eksekveringsplaner fra Plan Explorer, fordi vi indsamler meget mere runtime-information til dig. Disse runtime-oplysninger er særligt nyttige, hvis du deler dine planer på vores Q &A-websted, fordi det gør alle metrics og potentielle flaskehalse meget mere tydelige.
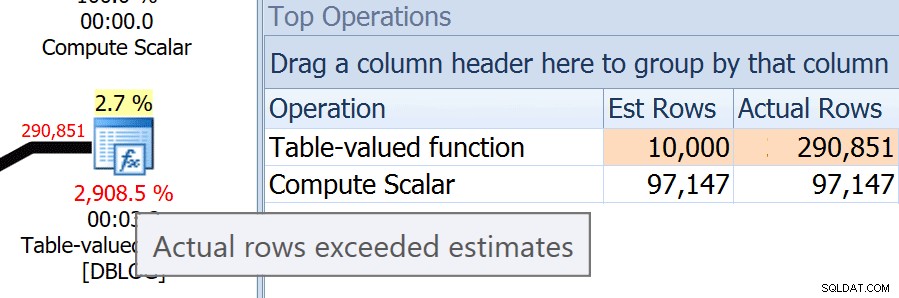
Sp:Hvad er procenterne under operatoren... for eksempel 2.885 % under funktionen?A: Denne procentdel er ikke en omkostning, men snarere procentdelen af rækker, der faktisk blev behandlet i forhold til estimatet. I dette tilfælde estimerede SQL Server, at funktionen ville returnere 10.000 rækker, men ved runtime returnerede den tæt på 300.000! Du kan se et værktøjstip, hvis du kun svæver på det %-tal, og du kan se rækkeantal-estimatforskellene i værktøjstip for operatøren eller i andre gitter som Top Operations (funktionen returnerer et andet antal rækker nu, end den gjorde under demoen):
A: Ja, alle vores paneler er justerbare; mange har en push-pin som skifter mellem statisk og auto-hide, de fleste paneler kan trækkes rundt (ligesom i Visual Studio, SSMS osv.), og især replay panelet har en lille pil øverst i midten, der giver dig mulighed for at for hurtigt at vise/skjule:
A: Jeg er ikke sikker på, om jeg fortolker spørgsmålet korrekt, men alle vores paneler er kontekstfølsomme, og erklæringen for den plan, der i øjeblikket undersøges, vises både i erklæringsgitteret og i panelet Tekstdata:
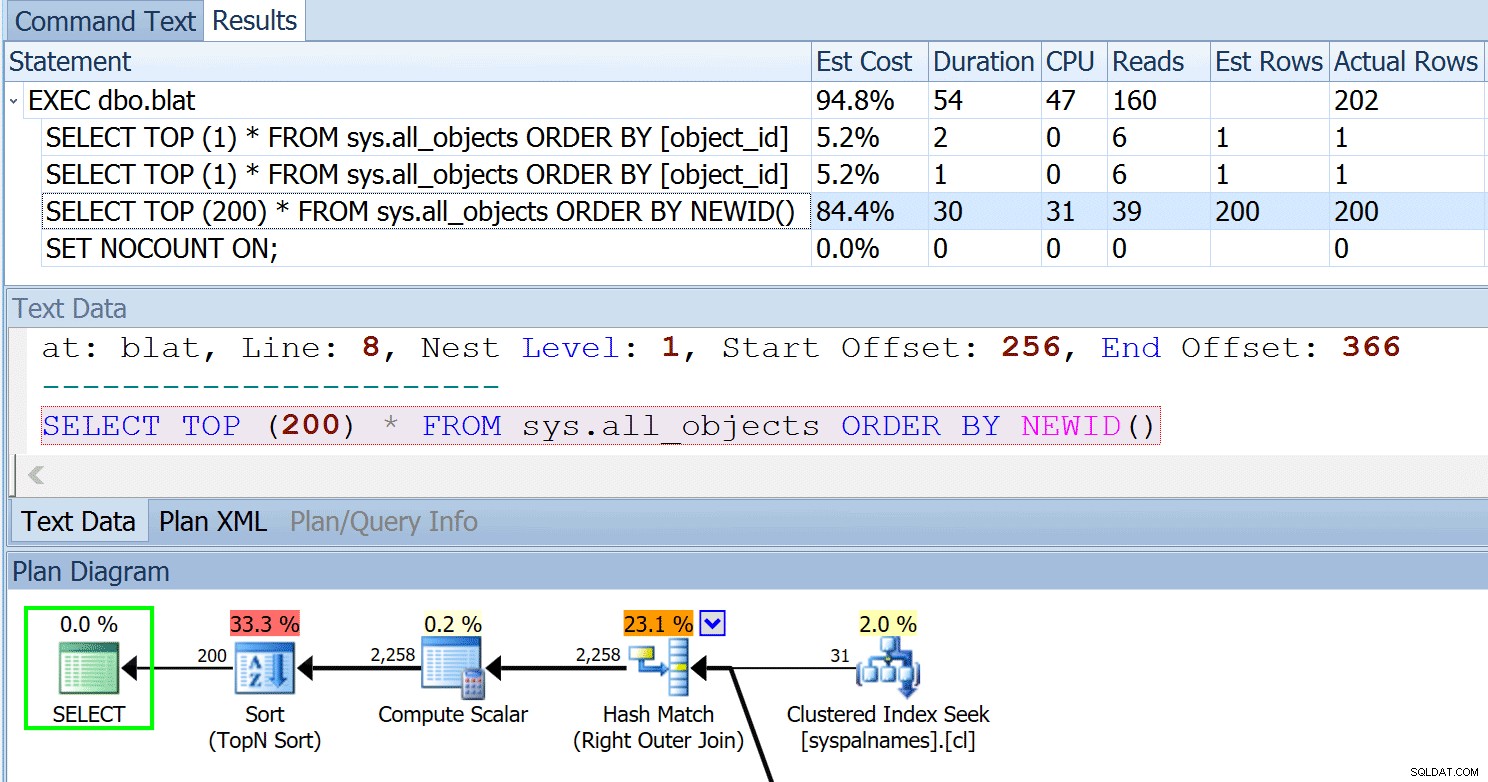
Hvis erklæringsteksten ikke er fuldt synlig på grund af længden, kan du altid højreklikke på den celle og vælge Kopier sætning til kommandotekstkopiering og derefter skifte til den fane. Eller, hvis du ikke vil overskrive det aktuelle indhold af kommandotekstfanen, skal du vælge Kopier> Celle og indsætte i en ny session, SSMS eller en anden editor.
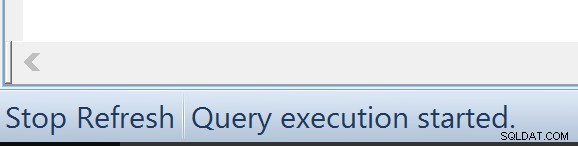
Sp:Hvordan kan jeg stoppe en "Få en faktisk plan", hvis jeg ved en fejl startede en 1-times forespørgsel?A: Hvis en forespørgsel kører i øjeblikket, er der en Stop-knap på statuslinjen, nederst til venstre:
A: Vi har bestemt planer om at gøre indeksscripting mere robust i fremtiden, herunder muligheder som DROP_EXISTING og ONLINE.
Sp.:Hænger dette sammen med SentryOne?A: Al funktionaliteten i Plan Explorer er også tilgængelig i SentryOne Client. Du behøver teknisk set ikke at installere Plan Explorer, hvis du har klienten, bortset fra at opdateringer skubbes efter en anden tidsplan, så i mange tilfælde kan det give mening at have begge installeret.
Husk, at planer, som vi indsamler for dig under overvågningsaktiviteter, er estimerede planer på grund af de høje omkostninger ved at indsamle faktiske planer for alle forespørgsler, der kører mod en server. Dette betyder, at hvis du borer ned til en samlet plan i klienten, vil den ikke have yderligere oplysninger såsom indeksanalyse og Live Query Profile-data. Du kan altid køre forespørgslen igen, interaktivt, for at få de ekstra runtime-data.
Spørgsmål:Hvad er ydeevnen for disse nye funktioner?A: De fleste af de oplysninger, vi indsamler, er ikke dyrere, end hvis du kørte de samme forespørgsler og indsamlede de samme runtime-data fra Management Studio (f.eks. med SHOWPLAN, STATISTICS TIME og STATISTICS IO tændt). Meget af dette opvejes dog af vores standardadfærd med at kassere resultater, så vi belaster ikke serveren med at overføre resultater til vores applikation.
For ekstremt komplekse planer, der kører mod databaser med meget komplekse skemaer og MANGE indekser, kan indsamlingen af indeks og statistik være mindre effektiv, men det vil være yderst usandsynligt, at det vil forårsage nogen mærkbar indvirkning på eksisterende arbejdsbelastninger. Dette vil ikke blive påvirket af antallet af rækker i en tabel, som blev nævnt i en variant af dette spørgsmål.
For virkelig langvarige eller ressourcekrævende forespørgsler ville min største bekymring være vores Live Query Profile-samling. Vi har to præferencer, der kan hjælpe med dette:om vi skal inkludere Live Query Profile med al faktisk plangenerering som standard, og hvilket interval der skal indsamles data fra DMV. Selvom jeg stadig føler, at overheaden af denne samling aldrig bør komme i nærheden af overheaden af selve forespørgslen, kan du justere disse indstillinger for at gøre samlingen mindre aggressiv.
Når alt er sagt, med ansvarsfraskrivelsen om, at alt skal gøres med måde, har jeg ikke observeret nogen problemer i forbindelse med overhead ved indsamling af data, og jeg vil ikke tøve med at bruge den fulde funktionalitet mod en produktionsinstans.
Sp.:Er der noget derinde, der kan hjælpe med at opbygge filtrerede indekser?A: I øjeblikket har vi ikke nogen funktionalitet, der anbefaler filtrerede indekser, men det er bestemt på vores radar.
Sp.:Har du planer om at tilføje en funktion til sammenligning af forespørgselsplaner til Plan Explorer?A: Ja, dette har bestemt været på vores køreplan længe før denne funktionalitet blev introduceret i SSMS. :-) Vi vil tage os tid og bygge et funktionssæt, som du forhåbentlig er kommet til at forvente af os.
Sp:Kan du bruge SSIS-pakker til at finde ud af en pakkes ydeevne?A: Jeg formoder, at du kunne, hvis du påkalder pakken eller jobbet gennem T-SQL mod en server (Plan Explorer har ikke mulighed for at starte ting som SSIS-pakker direkte). Men applikationen vil kun vise de ydeevneaspekter, der er synliggjort gennem SQL Server – hvis der er ineffektivitet i SSIS-pakken, som ikke er relateret til eksekvering mod SQL Server (f.eks. en uendelig løkke i en script-opgave), er vi vil ikke være i stand til at hente dem, fordi vi ikke har nogen synlighed og udfører ingen kodeanalyse.
Spørgsmål:Kan du hurtigt vise, hvordan man bruger deadlock-analysefunktionen?A: Jeg gik glip af dette spørgsmål under webinaret, men jeg taler om denne funktionalitet i mit Demo Kit, Jonathan Kehayias har blogget om det her, Steve Wright har en video om det på YouTube, og den officielle dokumentation kan gennemgås i PE-brugervejledningen.
Sp:Kan dette bruges som Profiler? Kan jeg analysere en hel arbejdsbyrde?A: Plan Explorer er designet til at hjælpe med at analysere individuelle forespørgsler og deres udførelsesplaner. Vi har en fuldt udstyret overvågningsplatform til større indsatser, og der er også adskillige tredjepartsværktøjer til analyse af arbejdsbelastning derude.
Sp:Jeg er meget ny inden for forespørgselsjustering – kan du foreslå værktøjer og artikler til en dybere forståelse?A: Der er mange ressourcer til at blive bedre til forespørgselsjustering:
- Enhver T-SQL-bog af Itzik Ben-Gan, Grant Fritchey eller Benjamin Nevarez;
- Ethvert blogindlæg af Paul White eller Rob Farley;
- Spørgsmål og svar her på answers.sqlperformance.com eller over på dba.stackexchange.com;
- Forespørgselsjustering af videoer på YouTube;
- Demo-kittet (med en ny version på vej!); og,
- Øv . Helt seriøst. Du kan læse alle de bøger og artikler, du ønsker, men uden praktisk, praktisk arbejdsfejlfinding og forbedring af problematiske forespørgsler med reelle ydeevneproblemer, vil det være svært at blive ekspert. IMHO.
Oversigt
Tak fordi du deltog i webinaret, og mange tak for alle de gode spørgsmål. Jeg er ked af, at jeg ikke var i stand til at behandle dem alle, men jeg håber, at dette var nyttigt alligevel. Hvis du havde et spørgsmål, som jeg ikke besvarede ovenfor, er du velkommen til at stille mig direkte på abertrand@sentryone.com.