Der er to komplementære færdigheder, der er meget nyttige i forespørgselsindstilling. Den ene er evnen til at læse og fortolke udførelsesplaner. Den anden er at vide lidt om, hvordan forespørgselsoptimeringsværktøjet fungerer til at oversætte SQL-tekst til en eksekveringsplan. At sætte de to ting sammen kan hjælpe os med at finde tidspunkter, hvor en forventet optimering ikke blev anvendt, hvilket resulterer i en eksekveringsplan, der ikke er så effektiv, som den kunne være. Manglen på dokumentation omkring præcis, hvilke optimeringer SQL Server kan anvende (og under hvilke omstændigheder), betyder dog, at meget af dette kommer ned til erfaring.
Et eksempel
Eksempelforespørgslen til denne artikel er baseret på spørgsmål stillet af SQL Server MVP Fabiano Amorim for et par måneder siden, baseret på et problem i den virkelige verden, han stødte på. Skemaet og testforespørgslen nedenfor er en forenkling af den virkelige situation, men den bevarer alle de vigtige funktioner.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Test 1 – 10.000 rækker, SQL Server 2005+
De specifikke tabeldata betyder ikke rigtig noget for disse tests. Følgende forespørgsler indlæser blot 10.000 rækker fra en taltabel til hver af de tre testtabeller:
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
Med dataene indlæst er udførelsesplanen, der er udarbejdet for testforespørgslen:
SELECT MAX(c1) FROM dbo.V1;
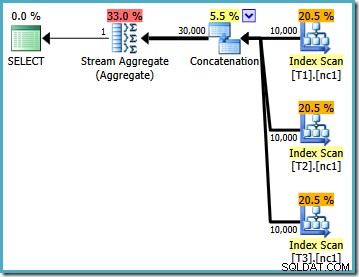
Denne eksekveringsplan er en ret direkte implementering af den logiske SQL-forespørgsel (efter at visningsreferencen V1 er udvidet). Optimizeren ser forespørgslen efter visningsudvidelse, næsten som om forespørgslen var blevet skrevet ud i sin helhed:
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
Ved at sammenligne den udvidede tekst med udførelsesplanen er direkteheden af forespørgselsoptimeringsimplementeringen klar. Der er en indeksscanning for hver læsning af basistabellerne, en sammenkædningsoperator til at implementere UNION ALL , og et Stream Aggregate for den endelige MAX samlet.
Egenskaberne for eksekveringsplanen viser, at omkostningsbaseret optimering blev startet (optimeringsniveauet er FULL ), men at den ophørte tidligt, fordi der blev fundet en 'god nok' plan. Den anslåede pris for den valgte plan er 0,1016240 magiske optimeringsenheder.
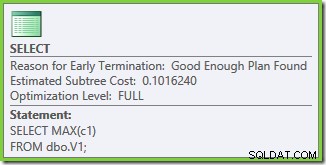
Test 2 – 50.000 rækker, SQL Server 2008 og 2008 R2
Kør følgende script for at nulstille testmiljøet til at køre med 50.000 rækker:
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
Udførelsesplanen for denne test afhænger af den version af SQL Server, du kører. I SQL Server 2008 og 2008 R2 får vi følgende plan:
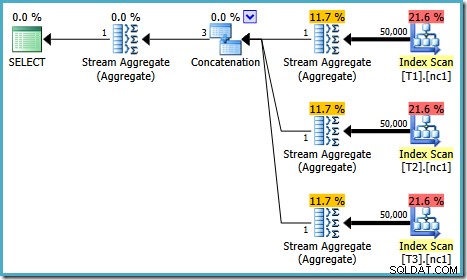
Planegenskaberne viser, at omkostningsbaseret optimering stadig sluttede tidligt af samme årsag som tidligere. De estimerede omkostninger er højere end tidligere på 0,41375 enheder, men det forventes på grund af den højere kardinalitet af basistabellerne.
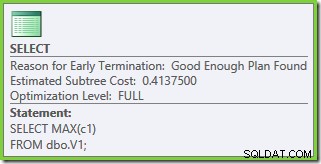
Test 3 – 50.000 rækker, SQL Server 2005 og 2012
Den samme forespørgsel, der blev kørt i 2005 eller 2012, producerer en anden eksekveringsplan:
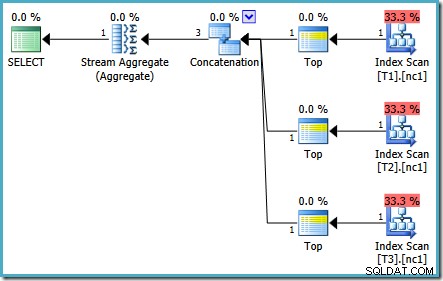
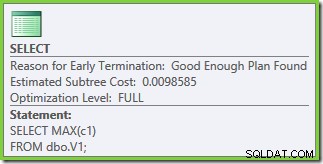
Optimering sluttede tidligt igen, men de anslåede planomkostninger for 50.000 rækker pr. basistabel er nede på 0,0098585 (fra 0,41375 på SQL Server 2008 og 2008 R2).
Forklaring
Som du måske ved, opdeler SQL Server-forespørgselsoptimeringen optimeringsindsatsen i flere faser, hvor senere faser tilføjer flere optimeringsteknikker og giver mere tid. Optimeringsstadierne er:
- Triviel plan
- Omkostningsbaseret optimering
- Transaktionsbehandling (søgning 0)
- Hurtig plan (søgning 1)
- Hurtig plan med parallelitet aktiveret
- Fuld optimering (søgning 2)
Ingen af de test, der udføres her, kvalificerer sig til en triviel plan, fordi aggregatet og fagforeningerne har flere implementeringsmuligheder, hvilket kræver en omkostningsbaseret beslutning.
Transaktionsbehandling
Transaktionsbehandlingsstadiet (TP) kræver, at en forespørgsel indeholder mindst tre tabelreferencer, ellers springer omkostningsbaseret optimering dette trin over og går direkte videre til Quick Plan. TP-stadiet er rettet mod de billige navigationsforespørgsler, der er typiske for OLTP-arbejdsbelastninger. Den prøver et begrænset antal optimeringsteknikker og er begrænset til at finde planer med Nested Loop Joins (medmindre en Hash Join er nødvendig for at generere en gyldig plan).
I nogle henseender er det overraskende, at testforespørgslen kvalificerer sig til et trin, der sigter mod at finde OLTP-planer. Selvom forespørgslen indeholder de tre krævede tabelreferencer, indeholder den ingen joinforbindelser. Kravet med tre tabeller er kun en heuristik, så jeg vil ikke arbejde på sagen.
Hvilke optimeringsfaser blev kørt?
Der er en række metoder, den dokumenterede er at sammenligne indholdet af sys.dm_exec_query_optimizer_info før og efter kompilering. Det er fint, men det registrerer oplysninger for hele instansen, så du skal være forsigtig med, at din er den eneste forespørgselskompilering, der sker mellem snapshots.
Et udokumenteret (men rimeligt velkendt) alternativ, der fungerer på alle aktuelt understøttede versioner af SQL Server, er at aktivere sporingsflag 8675 og 3604, mens forespørgslen kompileres.
Test 1
Denne test producerer sporingsflag 8675-output svarende til følgende:

Den anslåede pris på 0,101624 efter TP-stadiet er lav nok til, at optimeringsværktøjet ikke fortsætter med at lede efter billigere planer. Den simple plan, vi ender med, er ganske rimelig i betragtning af grundtabellernes relativt lave kardinalitet, selvom den ikke er rigtig optimal.
Test 2
Med 50.000 rækker i hver basistabel afslører sporingsflaget forskellige oplysninger:

Denne gang er den estimerede pris efter TP-stadiet 0,428735 (flere rækker =højere pris). Dette er nok til at opmuntre optimizeren til Quick Plan-stadiet. Med flere tilgængelige optimeringsteknikker finder denne fase en plan med en pris på 0,41375 . Dette repræsenterer ikke en enorm forbedring i forhold til test 1-planen, men den er lavere end standardomkostningstærsklen for parallelitet og ikke nok til at gå ind i fuld optimering, så igen slutter optimering tidligt.
Test 3
For SQL Server 2005 og 2012-kørsel er sporingsflagoutputtet:

Der er mindre forskelle i antallet af kørende opgaver mellem versioner, men den vigtige forskel er, at på SQL Server 2005 og 2012 finder Quick Plan-stadiet en plan, der kun koster 0,0098543 enheder. Dette er planen, der indeholder Top-operatører i stedet for de tre Stream Aggregates under Concatenation-operatoren, der ses i SQL Server 2008 og 2008 R2-planerne.
Bugs og udokumenterede rettelser
SQL Server 2008 og 2008 R2 indeholder en regressionsfejl (sammenlignet med 2005), der blev rettet under sporingsflag 4199, men ikke dokumenteret så vidt jeg kan se. Der er dokumentation for TF 4199, der viser rettelser, der er gjort tilgængelige under separate sporingsflag, før de bliver omfattet af 4199, men som den Knowledge Base-artikle siger:
Dette ene sporingsflag kan bruges til at aktivere alle de rettelser, der tidligere blev lavet til forespørgselsprocessoren under mange sporingsflag. Derudover vil alle fremtidige rettelser til forespørgselsprocessor blive kontrolleret ved at bruge dette sporingsflag.
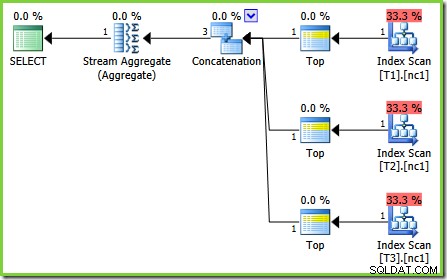
Fejlen i dette tilfælde er en af disse 'fremtidige forespørgselsprocessorrettelser'. En særlig optimeringsregel, ScalarGbAggToTop , anvendes ikke på de nye aggregater, der ses i test 2-planen. Med sporingsflag 4199 aktiveret på passende builds af SQL Server 2008 og 2008 R2, er fejlen rettet, og den optimale plan fra test 3 opnås:
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Konklusion
Når du ved, at optimeringsværktøjet kan transformere en skalar MIN eller MAX samles til en TOP (1) på en bestilt strøm virker planen vist i test 2 mærkelig. De skalære aggregater over en indeksscanning (som kan give orden, hvis du bliver bedt om det) skiller sig ud som en savnet optimering, der normalt ville blive anvendt.
Dette er den pointe, jeg kom med i introduktionen:Når du først får en fornemmelse for den slags ting, optimeringsværktøjet kan gøre, kan det hjælpe dig med at genkende tilfælde, hvor noget er gået galt.
Svaret vil ikke altid være at aktivere sporingsflag 4199, da du kan støde på problemer, der endnu ikke er blevet rettet. Du vil måske heller ikke have, at de andre QP-rettelser, der er dækket af sporingsflaget, skal gælde i et bestemt tilfælde - optimeringsrettelser gør ikke altid tingene bedre. Hvis de gjorde det, ville der ikke være behov for at beskytte mod uheldige planregressioner ved at bruge dette flag.
Løsningen i andre tilfælde kan være at formulere SQL-forespørgslen ved hjælp af en anden syntaks, at dele forespørgslen op i mere optimeringsvenlige bidder eller noget helt andet. Uanset hvad svaret viser sig at være, kan det stadig betale sig at vide lidt om optimizer internals, så du kan genkende, at der var et problem i første omgang :)