Et engagement med præstationsjustering kan ende med at tage mange drejninger, mens du arbejder dig igennem det – det hele afhænger af, hvad der dukker op som problemet, og hvad dataene fortæller dig. Nogle dage lander den på en specifik forespørgsel eller et sæt forespørgsler, som kan forbedres med indekser - enten nye eller ændringer af eksisterende indekser. En af mine yndlingsdele af tuning er at arbejde med indekser, og da jeg tænkte på dette indlæg, blev jeg fristet til at betegne indeksjustering som en "lettere" opgave ... men det er det virkelig ikke.
Jeg tænker på indeksjustering som en kunst og en videnskab. Du skal prøve at tænke som optimeringsværktøjet, og du skal forstå tabelskemaet og den forespørgsel (eller forespørgsler), du prøver at justere. Begge disse er datadrevne og dermed i kategorien videnskab. Kunstkomponenten kommer i spil, når du tænker på den anden indekser på bordet og alle den andre forespørgsler, der involverer tabellen, som kan blive påvirket af indeksændringer.
Trin 1 :Identificer forespørgslen og gennemgå planen
Når jeg identificerer en forespørgsel, der kunne drage fordel af et indeks, får jeg straks dens plan. Jeg får ofte eksekveringsplanen fra plancachen eller Query Store, og bruger derefter SSMS til at få eksekveringsplanen plus Run-Time Statistics (også kaldet faktisk eksekveringsplan). Mange gange er formen på disse to planer den samme; men det er ikke en garanti, og derfor kan jeg godt lide at se begge dele.
Planen kan have en manglende indeksanbefaling, den kan have en klynget indeksscanning (eller heap-scanning, hvis der ikke er noget klynget indeks), den kan bruge et ikke-klynget indeks, men har derefter et opslag for at hente yderligere kolonner. At løse hvert af disse problemer individuelt lyder ret nemt. Bare tilføj det manglende indeks, ikke? Hvis der er en scanning af et klynget indeks eller heap, skal du oprette det indeks, jeg skal bruge til forespørgslen, og være færdig? Eller hvis der er et indeks, der bruges, men det går til tabellen for at få de ekstra kolonner, skal du blot tilføje kolonnerne til det indeks?
Det er normalt ikke så nemt, og selv når det er, gennemgår jeg stadig den proces, som jeg skitserer her.
Trin 2 :Bestem, hvilke tabeller der skal gennemgås
Nu hvor jeg har min forespørgsel, skal jeg finde ud af, hvilke tabeller der ikke er indekseret korrekt. Udover at gennemgå planen, aktiverer jeg også IO og TIME statistik i SSMS. Dette er nok old-school af mig, da eksekveringsplaner indeholder mere og mere information – inklusive varighed og IO-numre pr. operatør – med hver udgivelse, men jeg kan godt lide IO-statistikken, fordi jeg hurtigt kan se læsningerne for hver tabel. For forespørgsler, der er komplekse med flere joinforbindelser, eller underforespørgsler, eller CTE'er eller indlejrede visninger, forstå, hvor IO og/eller tid bruges i forespørgselsdrevene, hvor jeg bruger min tid. Når det er muligt fra dette tidspunkt, tager jeg den større, komplekse forespørgsel og deler den ned til den del, der forårsager det største problem.
For eksempel, hvis der er en forespørgsel, der slutter sig til 10 tabeller og har to underforespørgsler, hjælper planen (sammen med IO og varighedsoplysninger) mig med at identificere, hvor problemet findes. Så vil jeg trække den del af forespørgslen ud – den problematiske tabel og måske et par andre, som den slutter sig til – og fokusere på det. Nogle gange er det bare underforespørgslen, så jeg starter der.
Trin 3 :Se på eksisterende indekser
Med forespørgslen (eller en del af forespørgslen) defineret, så fokuserer jeg på de eksisterende indekser for de involverede tabeller. Til dette trin stoler jeg på Kimberlys version af sp_helpindex. Jeg foretrækker meget hendes version frem for standard sp_helpindex, fordi den også viser INKLUDEREDE kolonner og filterdefinitionen (hvis en findes). Afhængigt af antallet af indekser, der dukker op for en tabel, vil jeg ofte kopiere dette og indsætte det i Excel, og derefter bestille ud fra indeksnøglen og derefter de inkluderede kolonner. Dette lader mig finde eventuelle overflødigheder hurtigt.
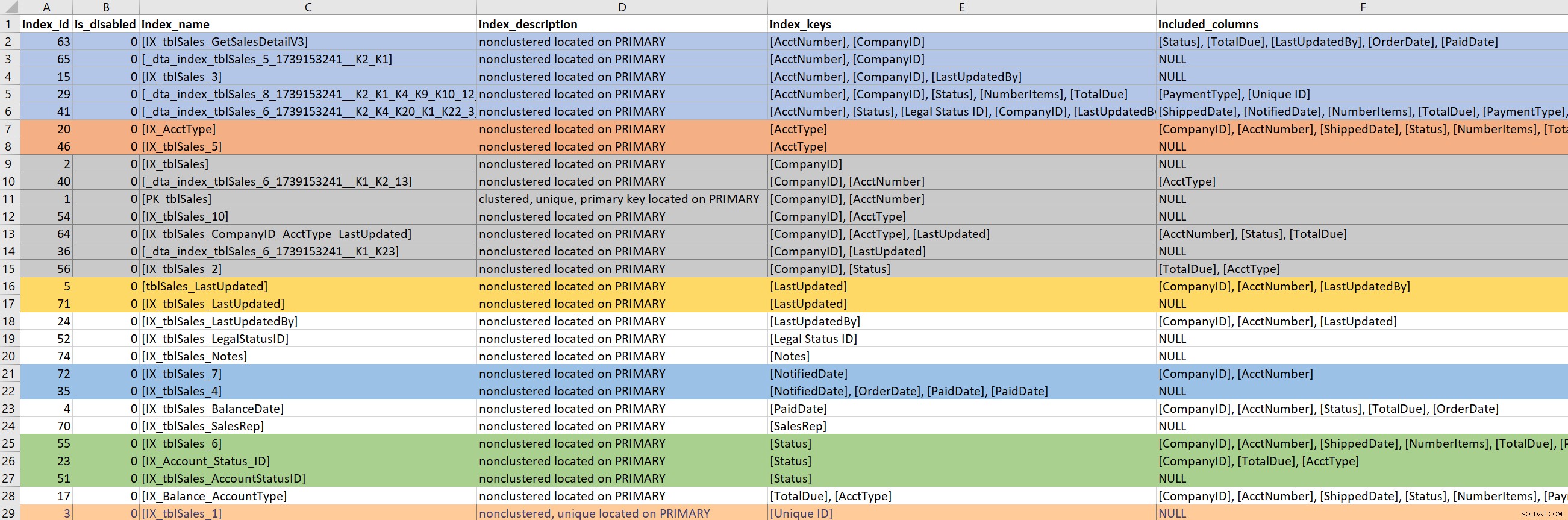
Baseret på eksemplet ovenfor er der syv indekser, der starter med CompanyID, fem, der starter med AcctNumber, og nogle andre potentielle redundanser. Selvom det virker ideelt kun at have én indeks, der fører på en bestemt kolonne (f.eks. CompanyID), for nogle forespørgselsmønstre, som ikke er nok.
Når jeg ser på eksisterende indekser, er det meget nemt at gå ned i et kaninhul. Jeg ser på outputtet ovenfor og begynder straks at spørge, hvorfor der er syv indekser, der starter med CompanyID, og jeg vil gerne vide, hvem der har oprettet dem, og hvorfor, og til hvilken forespørgsel. Men ... hvis min problematiske forespørgsel ikke bruger CompanyID, skal jeg så være ligeglad? Ja... for generelt er jeg der for at forbedre ydeevnen, og hvis det betyder, at man ser på andre indekser på bordet undervejs, så må det være sådan. Men det er her, det er nemt at miste overblikket over tid (og sande formål).
Hvis min problematiske forespørgsel har brug for et indeks, der fører på PaidDate, skal jeg kun forholde mig til ét eksisterende indeks. Hvis min problematiske forespørgsel har brug for et indeks, der fører på AcctNumber, bliver det vanskeligt. Når eksisterende indekser på en måde dækker en forespørgsel, og jeg søger at udvide et indeks (tilføje flere kolonner) eller konsolidere (slå to eller måske tre indekser sammen til ét), så er jeg nødt til at grave ind.
Trin 4:Indeks brugsstatistik
Jeg oplever, at mange mennesker ikke fanger statistik over indeksbrug løbende. Dette er uheldigt, fordi jeg finder dataene nyttige, når jeg skal beslutte, hvilke indekser der skal beholdes, og hvilke der skal droppes eller flettes. I det tilfælde, hvor jeg ikke har historisk brugsstatistik, tjekker jeg i det mindste for at se, hvordan brugen ser ud i øjeblikket (siden den sidste genstart af tjenesten):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
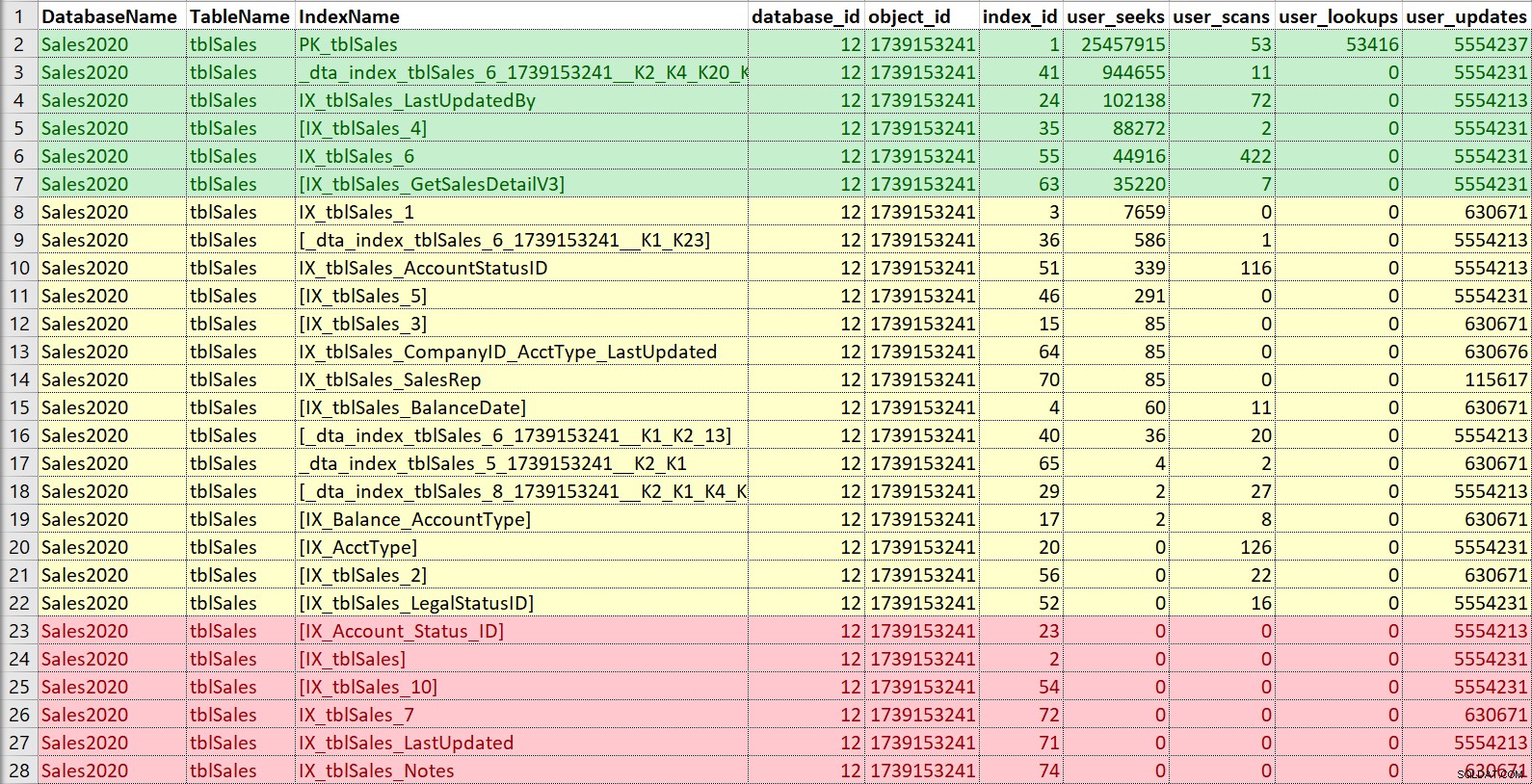
Igen kan jeg godt lide at sætte dette ind i Excel, sortere efter søgninger og derefter scanne, og også notere opdateringer. For dette eksempel er indekserne i rødt dem uden søgninger, scanninger eller opslag... kun opdateringer. Disse er kandidater til at blive deaktiveret og potentielt droppet, hvis de virkelig ikke bliver brugt (igen, at have brugshistorik ville hjælpe her). Indekserne i grønt bliver bestemt brugt, jeg vil gerne beholde dem (selvom de måske i nogle tilfælde kunne justeres). Dem i gul... nogle bliver brugt lidt, nogle bliver næsten ikke brugt. Igen, historie ville være nyttig her, eller kontekst fra andre - nogle gange kan et indeks være afgørende for en rapport eller proces, der ikke kører hele tiden.
Hvis jeg bare søger at ændre eller tilføje et nyt indeks i forhold til ægte oprydning og konsolidering, så er jeg mest bekymret over alle indekser, der ligner det, jeg vil tilføje eller ændre. Jeg vil dog sørge for at gøre kunden opmærksom på brugsoplysningerne og, hvis tiden tillader det, bistå med den overordnede indekseringsstrategi for tabellen.
Hvad er det næste?
Vi er ikke færdige! Dette er del 1 af min tilgang til indeksjustering, og min næste del vil vise resten af mine trin. I mellemtiden, hvis du ikke fanger statistik over indeksbrug, er det noget, du kan sætte på plads ved hjælp af forespørgslen ovenfor eller en anden variant. Jeg vil anbefale at fange brugsstatistik for alle brugerdatabaser, ikke kun en specifik tabel og database, som jeg har gjort ovenfor, så modificer prædikatet efter behov. Og endelig, som en del af det planlagte job med at snapshotte disse oplysninger til en tabel, glem ikke endnu et trin til at rydde op i tabellen, efter at data har været der i et stykke tid (jeg gemmer dem i mindst seks måneder; nogle vil måske sige en år er nødvendigt).