 Da jeg voksede op, elskede jeg spil, der testede evner til at matche hukommelse og mønster. Flere af mine venner havde Simon, mens jeg havde en knock-off ved navn Einstein. Andre havde en Atari Touch Me, som jeg allerede dengang vidste var en tvivlsom navngivningsbeslutning. I disse dage betyder mønstermatching noget meget anderledes for mig og kan være en dyr del af daglige databaseforespørgsler.
Da jeg voksede op, elskede jeg spil, der testede evner til at matche hukommelse og mønster. Flere af mine venner havde Simon, mens jeg havde en knock-off ved navn Einstein. Andre havde en Atari Touch Me, som jeg allerede dengang vidste var en tvivlsom navngivningsbeslutning. I disse dage betyder mønstermatching noget meget anderledes for mig og kan være en dyr del af daglige databaseforespørgsler.
Jeg stødte for nylig på et par kommentarer om Stack Overflow, hvor en bruger erklærede, som om det var en kendsgerning, at CHARINDEX yder bedre end LEFT eller LIKE . I et tilfælde citerede personen en artikel af David Lozinski, "SQL:LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX." Ja, artiklen viser, at i det konstruerede eksempel CHARINDEX klarede sig bedst. Men da jeg altid er skeptisk over for generelle udsagn som den, og ikke kunne komme i tanke om en logisk grund til, hvorfor en strengfunktion altid ville præstere bedre end en anden, med alt andet lige , jeg kørte hans tests. Sikkert nok havde jeg gentagne gange forskellige resultater på min maskine (klik for at forstørre):
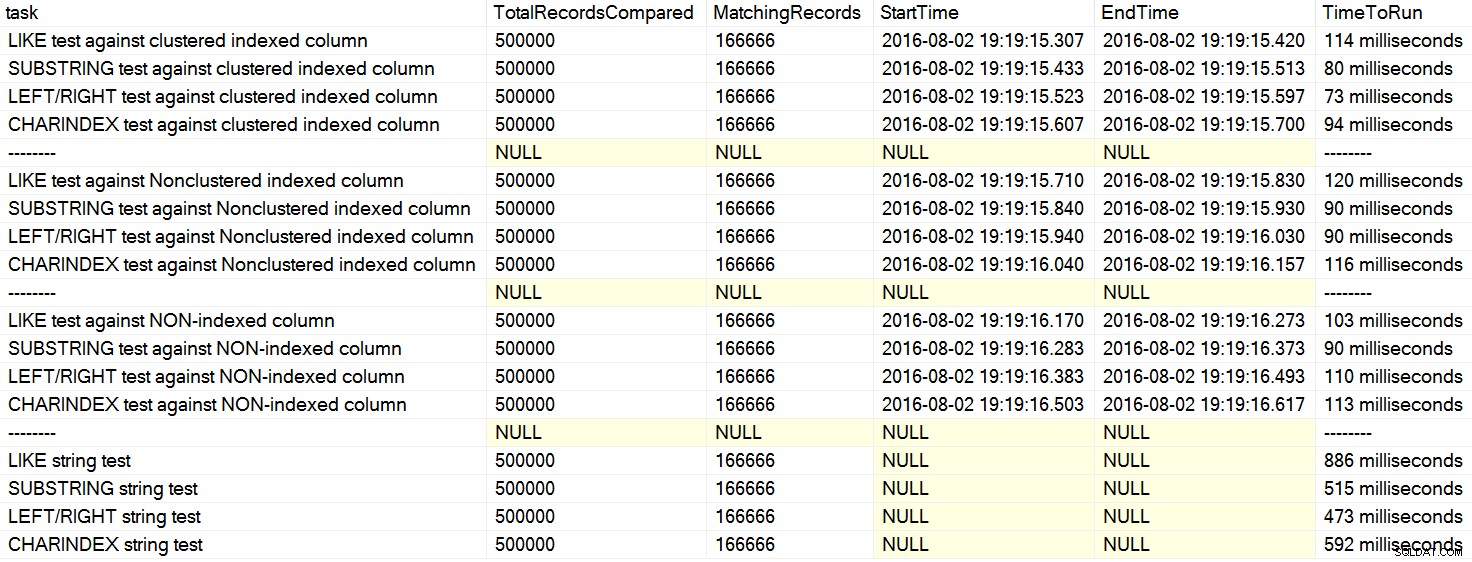 På min maskine var CHARINDEX langsommere end VENSTRE/HØJRE/SUBSTRING.
På min maskine var CHARINDEX langsommere end VENSTRE/HØJRE/SUBSTRING.
Davids test sammenlignede grundlæggende disse forespørgselsstrukturer – på udkig efter et strengmønster enten i begyndelsen eller slutningen af en kolonneværdi – med hensyn til rå varighed:
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern; WHERE LEFT(Column, LEN(@pattern)) = @pattern OR RIGHT(Column, LEN(@pattern)) = @pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
Bare ser på disse klausuler, kan du se hvorfor CHARINDEX kan være mindre effektiv – det foretager flere yderligere funktionelle opkald, de andre tilgange ikke behøver at udføre. Hvorfor denne tilgang fungerede bedst på Davids maskine, er jeg ikke sikker på; måske kørte han koden nøjagtigt som postet, og droppede ikke rigtig buffere mellem testene, sådan at de sidstnævnte test havde gavn af cachelagrede data.
I teorien CHARINDEX kunne have været udtrykt mere enkelt, f.eks.:
WHERE CHARINDEX(@pattern, Column) = 1 OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(Men dette klarede sig faktisk endnu værre i mine tilfældige tests.)
Og hvorfor disse endda er OR forhold, jeg er ikke sikker. Realistisk set laver du det meste af tiden en af to typer mønstersøgninger:starter med eller indeholder (det er langt mindre almindeligt at lede efter slutter med ). Og i de fleste af disse tilfælde har brugeren en tendens til at angive på forhånd, om de vil starter med eller indeholder , i hvert fald i alle ansøgninger, jeg har været involveret i i min karriere.
Det giver mening at adskille dem som separate typer forespørgsler i stedet for at bruge et ELLER betinget, da starter med kan gøre brug af et indeks (hvis der findes et, der er egnet nok til en søgning, eller er tyndere end det clusterede indeks), mens slutter med kan ikke (og ELLER forhold har en tendens til at kaste skruenøgler mod optimeringsværktøjet generelt). Hvis jeg kan stole på LIKE at bruge et indeks, når det kan, og at yde lige så godt som eller bedre end de andre løsninger ovenfor i de fleste eller alle tilfælde, så kan jeg gøre denne logik meget nem. En lagret procedure kan tage to parametre – mønsteret, der søges efter, og typen af søgning, der skal udføres (generelt er der fire typer strengmatchning – starter med, slutter med, indeholder eller eksakt match).
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Dette håndterer hver potentiel sag uden at bruge dynamisk SQL; OPTION (RECOMPILE) er der, fordi du ikke ønsker, at en plan, der er optimeret til "slutter med" (som næsten helt sikkert skal scannes) skal genbruges til en "starter med"-forespørgsel eller omvendt; det vil også sikre, at estimater er korrekte ("starter med S" har sandsynligvis meget anderledes kardinalitet end "starter med QX"). Selvom du har et scenarie, hvor brugere vælger én type søgning 99% af tiden, kan du bruge dynamisk SQL her i stedet for at rekompilere, men i så fald vil du stadig være sårbar over for parametersniffing. I mange betingede logiske forespørgsler er genkompilering og/eller fuld dynamisk SQL ofte den mest fornuftige tilgang (se mit indlæg om "Køkkenvasken").
Testene
Da jeg for nylig er begyndt at se på den nye WideWorldImporters eksempeldatabase, besluttede jeg at køre mine egne tests der. Det var svært at finde en tabel af anstændig størrelse uden et ColumnStore-indeks eller en tidsoversigtstabel, men Sales.Invoices , som har 70.510 rækker, har en simpel nvarchar(20) kolonne kaldet CustomerPurchaseOrderNumber som jeg besluttede at bruge til testene. (Hvorfor er det nvarchar(20) Når hver enkelt værdi er et 5-cifret tal, aner jeg ikke, men mønstermatching er ligeglad med, om bytene nedenunder repræsenterer tal eller strenge.)
| Salg.Invoices CustomerPurchaseOrderNumber | ||
|---|---|---|
| Mønster | # rækker | % af tabellen |
| Starter med "1" | 70.505 | 99,993 % |
| Starter med "2" | 5 | 0,007 % |
| Ender med "5" | 6.897 | 9,782 % |
| Ender med "30" | 749 | 1,062 % |
Jeg søgte rundt i værdierne i tabellen for at finde frem til flere søgekriterier, der ville producere vidt forskellige antal rækker, forhåbentlig for at afsløre enhver vippepunktsadfærd med en given tilgang. Til højre er de søgeforespørgsler, jeg landede på.
Jeg ønskede at bevise over for mig selv, at ovenstående procedure unægtelig var bedre samlet for alle mulige søgninger end nogen af de forespørgsler, der bruger OR conditionals, uanset om de bruger LIKE , LEFT/RIGHT , SUBSTRING , eller CHARINDEX . Jeg tog Davids grundlæggende forespørgselsstrukturer og satte dem i lagrede procedurer (med det forbehold, at jeg ikke rigtig kan teste "indeholder" uden hans input, og at jeg var nødt til at lave hans OR logik lidt mere fleksibel for at få det samme antal rækker), sammen med en version af min logik. Jeg planlagde også at teste procedurerne med og uden et indeks, jeg ville oprette i søgekolonnen, og under både en varm og en kold cache.
Procedurerne:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Jeg lavede også versioner af Davids procedurer tro mod hans oprindelige hensigt, idet jeg antager, at kravet virkelig er at finde rækker, hvor søgemønsteret er i begyndelsen *eller* slutningen af strengen. Jeg gjorde dette ganske enkelt, så jeg kunne sammenligne ydeevnen af de forskellige tilgange, præcis som han skrev dem, for at se, om mine resultater på dette datasæt ville matche mine test af hans originale script på mit system. I dette tilfælde var der ingen grund til at introducere en version af min egen, da den simpelthen ville matche hans LIKE % + @pattern OR LIKE @pattern + % variation.
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO Med procedurerne på plads kunne jeg generere testkoden – hvilket ofte er lige så sjovt som det originale problem. Først en logningstabel:
DROP TABLE IF EXISTS dbo.LoggingTable; GO SET NOCOUNT ON; CREATE TABLE dbo.LoggingTable ( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME() );
Derefter vælger koden, der skal udføre, operationer ved hjælp af de forskellige procedurer og argumenter:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn; Resultater
Jeg kørte disse tests på en virtuel maskine, der kører Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149) med 4 CPU'er og 32 GB RAM. Jeg kørte hvert sæt test 11 gange; til de varme cache-tests smed jeg det første sæt resultater ud, fordi nogle af dem var virkelig kolde cache-tests.
Jeg kæmpede med, hvordan jeg skulle tegne resultaterne for at vise mønstre, mest fordi der simpelthen ikke var nogen mønstre. Næsten hver metode var den bedste i ét scenarie og den værste i et andet. I de følgende tabeller fremhævede jeg den bedst og dårligst ydende procedure for hver kolonne, og du kan se, at resultaterne er langt fra afgørende:
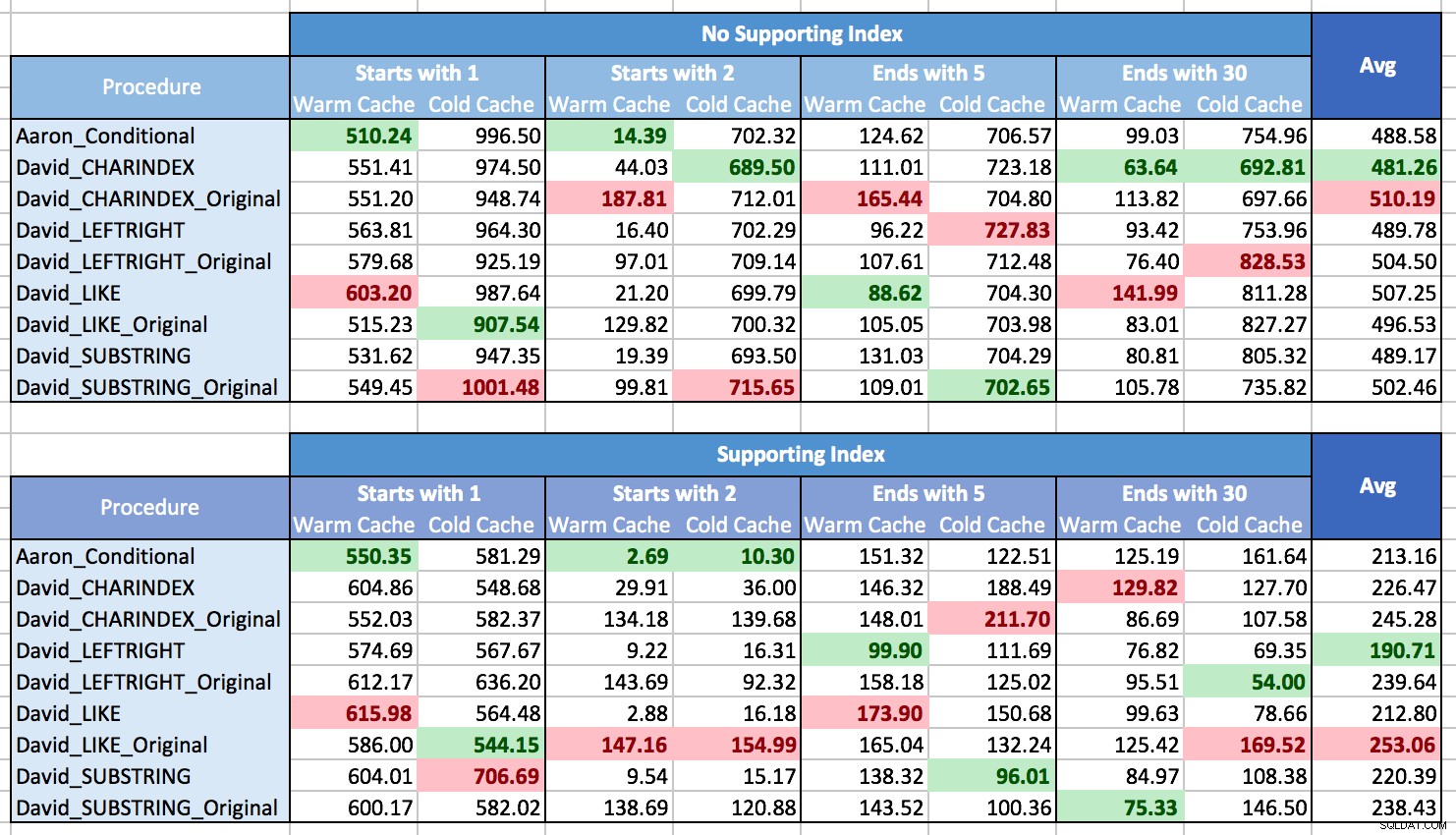 I disse test vandt CHARINDEX nogle gange, og nogle gange gjorde det ikke.
I disse test vandt CHARINDEX nogle gange, og nogle gange gjorde det ikke.
Hvad jeg har lært er, at hvis du i det hele taget står over for mange forskellige situationer (forskellige typer mønstermatching, med et understøttende indeks eller ej, data kan ikke altid være i hukommelsen), er der virkelig ingen klar vinder, og rækkevidden af ydeevne i gennemsnit er ret lille (faktisk, da en varm cache ikke altid hjalp, ville jeg formoder, at resultaterne var mere påvirket af omkostningerne ved at gengive resultaterne end at hente dem). For individuelle scenarier, stol ikke på mine tests; køre nogle benchmarks selv givet din hardware, konfiguration, data og brugsmønstre.
Forbehold
Nogle ting, jeg ikke overvejede til disse tests:
- Klyngede vs. ikke-klyngede . Da det er usandsynligt, at dit klyngede indeks vil være på en kolonne, hvor du udfører mønstermatchende søgninger mod begyndelsen eller slutningen af strengen, og da en søgning stort set vil være den samme i begge tilfælde (og forskellene mellem scanninger vil stort set være funktion af indeksbredde vs. tabelbredde), testede jeg kun ydeevne ved hjælp af et ikke-klynget indeks. Hvis du har nogle specifikke scenarier, hvor denne forskel alene gør en stor forskel med hensyn til mønstermatchning, så lad mig det vide.
- MAX typer . Hvis du søger efter strenge i
varchar(max)/nvarchar(max), disse kan ikke indekseres, så medmindre du bruger beregnede kolonner til at repræsentere dele af værdien, vil en scanning være påkrævet – uanset om du leder efter starter med, slutter med eller indeholder. Om præstationsoverhead korrelerer med størrelsen af strengen, eller yderligere overhead er introduceret simpelthen på grund af typen, testede jeg ikke.
- Fuldtekstsøgning . Jeg har leget med denne funktion her og dengang, og jeg kan stave til den, men hvis min forståelse er korrekt, kan dette kun være nyttigt, hvis du søger efter hele non-stop ord og ikke bekymrer dig om, hvor i strengen de var fundet. Det ville ikke være nyttigt, hvis du lagrede tekstafsnit og ville finde alle dem, der starter med "Y", indeholder ordet "den" eller slutter med et spørgsmålstegn.
Oversigt
Den eneste generelle erklæring, jeg kan komme med, når jeg går væk fra denne test, er, at der ikke er nogen generelle erklæringer om, hvad der er den mest effektive måde at udføre strengmønstermatchning på. Selvom jeg er forudindtaget over for min betingede tilgang til fleksibilitet og vedligeholdelse, var det ikke præstationsvinderen i alle scenarier. For mig, medmindre jeg rammer en præstationsflaskehals, og jeg følger alle veje, vil jeg fortsætte med at bruge min tilgang til konsistens. Som jeg foreslog ovenfor, hvis du har et meget snævert scenarie og er meget følsom over for små forskelle i varighed, vil du gerne køre dine egne tests for at bestemme, hvilken metode der konsekvent er den bedste performer for dig.