Generelt er den bedste slags sortering en, der helt undgås. Med omhyggelig indeksering og nogle gange nogle kreative forespørgselsskrivninger kan vi ofte fjerne behovet for en sorteringsoperatør fra udførelsesplaner. Hvor dataene, der skal sorteres, er store, kan undgåelse af denne type sortering give meget betydelige præstationsforbedringer.
Den næstbedste slags sort er den, vi ikke kan undgå, men som reserverer en passende mængde hukommelse og bruger hele eller det meste til at gøre noget værd. At være um værd kan antage mange former. Nogle gange kan en sortering mere end betale sig selv ved at aktivere en senere operation, der fungerer meget mere effektivt på sorteret input. Andre gange er sorteringen ganske enkelt nødvendig, og vi skal bare gøre den så effektiv som muligt.
Så kommer de sorter, som vi normalt ønsker at undgå:dem, der reserverer langt mere hukommelse, end de har brug for, og dem, der reserverer for lidt. Sidstnævnte tilfælde er det, de fleste fokuserer på. Med utilstrækkelig hukommelse reserveret (eller tilgængelig) til at fuldføre den påkrævede sorteringsoperation i hukommelsen, vil en sorteringsoperatør, med få undtagelser, spilde datarækker til tempdb . I virkeligheden betyder dette næsten altid, at man skal skrive sorteringssider til fysisk lager (og selvfølgelig læse dem tilbage senere).
I moderne versioner af SQL Server resulterer en spildt sortering i et advarselsikon i efterudførelsesplaner, som kan omfatte detaljer om, hvor meget data der blev spildt, hvor mange tråde der var involveret og spildniveauet.
Baggrund:Spildniveauer
Overvej opgaven med at sortere 4000MB data, når vi kun har 500MB ledig hukommelse. Vi kan naturligvis ikke sortere hele sættet i hukommelsen på én gang, men vi kan opdele opgaven:
Vi læser først 500 MB data, sorterer det sæt i hukommelsen og skriver derefter resultatet til disken. At udføre dette i alt 8 gange bruger hele 4000MB input, hvilket resulterer i 8 sæt sorterede data på 500MB i størrelse. Det andet trin er at udføre en 8-vejs fletning af de sorterede datasæt. Bemærk, at en fletning er påkrævet, ikke en simpel sammenkædning af sættene, da dataene kun garanteres at blive sorteret efter behov inden for et bestemt 500 MB sæt på mellemstadiet.
I princippet kunne vi aflæse og flette en række ad gangen fra hver af de otte sorteringskørsler, men det ville ikke være særlig effektivt. I stedet læser vi den første del af hver slags køre tilbage i hukommelsen, f.eks. 60 MB. Dette bruger 8 x 60 MB =480 MB af de 500 MB vi har til rådighed. Vi kan derefter effektivt udføre 8-vejs fletningen i hukommelsen i et stykke tid, og buffere det endelige sorterede output med den 20 MB hukommelse, der stadig er tilgængelig. Efterhånden som hver af slagsrun-hukommelsesbufferne tømmes, læser vi en ny sektion af den slags, der løber ind i hukommelsen. Når alle sorteringskørsler er blevet brugt, er sorteringen fuldført.
Der er nogle yderligere detaljer og optimeringer, vi kan inkludere, men det er den grundlæggende skitse af et niveau 1-udslip, også kendt som et enkelt-pass-udslip. En enkelt ekstra passage over dataene er påkrævet for at producere det endelige sorterede output.
Nu kunne en n-vejs fletning teoretisk set rumme en slags enhver størrelse, i enhver mængde hukommelse, blot ved at øge antallet af mellemliggende lokalt sorterede sæt. Problemet er, at når 'n' stiger, ender vi med at læse og skrive mindre bidder af data. For eksempel vil sortering af 400 GB data i 500 MB hukommelse betyde noget i retning af en 800-vejs fletning, med kun omkring 0,6 MB fra hvert mellemsorteret sæt i hukommelsen på ethvert tidspunkt (800 x 0,6 MB =480 MB, hvilket giver plads til en outputbuffer).
Flere flettepas kan bruges til at omgå dette. Den generelle idé er gradvist at fusionere små bidder til større, indtil vi effektivt kan producere den endelige sorterede outputstrøm. I eksemplet kan dette betyde, at 40 af de 800 first-pass-sorterede sæt skal sammenføjes ad gangen, hvilket resulterer i 20 større bidder, som derefter kan slås sammen igen for at danne output. Med i alt to ekstra gennemgange af dataene ville dette være et niveau 2-udslip og så videre. Heldigvis muliggør en lineær stigning i spildniveau en eksponentiel stigning i sorteringsstørrelse, så dybe sorteringsniveauer er sjældent nødvendige.
Spillet "Niveau 15.000"
På dette tidspunkt undrer du dig måske over, hvilken kombination af lille hukommelsesbevilling og enorm datastørrelse, der muligvis kan resultere i et spild på niveau 15.000. Forsøger du at sortere hele internettet i 1 MB hukommelse? Muligvis, men det er alt for svært at demonstrere. For at være ærlig har jeg ingen idé om, om et så virkeligt højt spildniveau overhovedet er muligt i SQL Server. Målet her (en snyd, helt klart) er at få SQL Server til at rapportere et spild på niveau 15.000.
Nøgleingrediensen er partitionering. Siden SQL Server 2012 har vi fået lov til et (praktisk) maksimum på 15.000 partitioner pr. objekt (understøttelse af 15.000 partitioner er også tilgængelig på 2008 SP2 og 2008 R2 SP1, men du skal aktivere det manuelt pr. database, og være opmærksom på alle forbeholdene).
Den første ting, vi skal bruge, er en 15.000-element partitionsfunktion og et tilhørende partitionsskema. For at undgå en virkelig enorm inline kodeblok, bruger følgende script dynamisk SQL til at generere de nødvendige sætninger:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Scriptet er nemt nok at ændre til et lavere tal, hvis din opsætning kæmper med 15.000 partitioner (især fra et hukommelsessynspunkt, som vi snart vil se). De næste trin er at oprette en normal (ikke opdelt) heap-tabel med en enkelt heltalskolonne og derefter udfylde den med heltal fra 1 til 15.000 inklusive:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Det skulle være færdigt om 100 ms eller deromkring. Hvis du har en taltabel til rådighed, er du velkommen til at bruge den i stedet for at få en mere sæt-baseret oplevelse. Måden basistabellen er udfyldt på er ikke vigtig. For at få vores spild på 15.000 niveauer er alt, hvad vi skal gøre nu, at oprette et opdelt klyngeindeks på bordet:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
Udførelsestiden afhænger i høj grad af det anvendte lagersystem. På min bærbare computer tager det omkring 20 sekunder ved at bruge en ret typisk forbruger-SSD fra et par år siden, hvilket er ret betydeligt i betragtning af, at vi kun har at gøre med 15.000 rækker i alt. På en Azure VM med temmelig lav specifikation med ret forfærdelig I/O-ydeevne tog den samme test nærmere 20 minutter.
Analyse
Udførelsesplanen for indeksbygningen er:
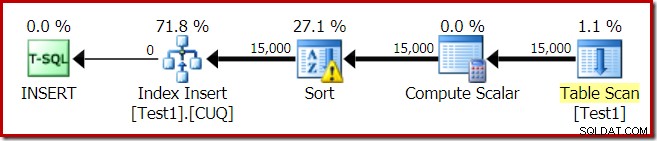
Tabelscanningen læser de 15.000 rækker fra vores heap-tabel. Compute Scalar beregner destinationsindekspartitionsnummeret for hver række ved hjælp af den interne funktion RangePartitionNew() . Sorten er den mest interessante del af planen, så vi vil se nærmere på den.
Først sorteringsadvarslen, som vist i Plan Explorer:

En lignende advarsel fra SSMS (taget fra en anden kørsel af scriptet):
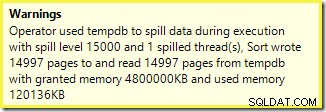
Den første ting at bemærke er rapporten om et spildniveau på 15.000 sorter, som lovet. Dette er ikke helt præcist, men detaljerne er ret interessante. Sorteringen i denne plan har et Partition ID egenskab, som normalt ikke er til stede:
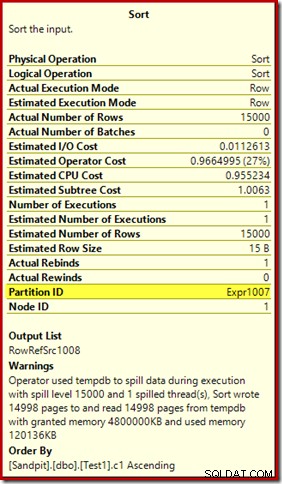
Denne egenskab er sat lig med definitionen af den interne partitioneringsfunktion i Compute Scalar.
Dette er en ikke-justeret indeksopbygning , fordi kilden og destinationen har forskellige opdelingsarrangementer. I dette tilfælde opstår forskellen, fordi kildeheap-tabellen ikke er partitioneret, men destinationsindekset er det. Som følge heraf oprettes 15.000 separate sorteringer under kørsel:én pr. ikke-tom målpartition. Hver af disse typer spilder til niveau 1, og SQL Server summerer alle disse spild for at give det endelige udslipsniveau på 15.000.
De 15.000 separate sorter forklarer den store hukommelsesbevilling. Hver sorteringsinstans har en minimumstørrelse på 40 sider, hvilket er 40 x 8KB =320KB. De 15.000 sorter kræver derfor 15.000 x 320KB =4.800.000KB hukommelse som minimum. Det er bare genert af 4,6 GB RAM, der udelukkende er reserveret til en forespørgsel, der sorterer 15.000 rækker, der indeholder en enkelt heltalskolonne. Og hver sortering spildes til disk, på trods af kun at modtage én række! Hvis parallelisme blev brugt til indeksopbygningen, kunne hukommelsesbevillingen blive yderligere oppustet med antallet af tråde. Bemærk også, at den enkelte række er skrevet på en side, som forklarer antallet af sider skrevet til og læst fra tempdb. Der ser ud til at være en racetilstand, der betyder, at det rapporterede antal sider ofte er et par mindre end 15.000.
Dette eksempel afspejler selvfølgelig en kantsag, men det er stadig svært at forstå, hvorfor hver sortering spilder sin enkelte række i stedet for at sortere i den hukommelse, den har fået. Måske er dette af en eller anden grund af en eller anden grund, eller måske er det simpelthen en fejl. Uanset hvad, er det stadig ret underholdende at se en slags et par hundrede KB data tage så lang tid med en 4,6 GB hukommelsesbevilling og et spild på 15.000 niveauer. Medmindre du støder på det i et produktionsmiljø, måske. Det er i hvert fald noget, man skal være opmærksom på.
Den vildledende udslipsrapport på 15.000 niveauer kommer stort set ned til repræsentationsbegrænsninger i showplanens output. Det grundlæggende problem er noget, der opstår mange steder, hvor gentagne handlinger forekommer, for eksempel på indersiden af de indlejrede løkker. Det ville bestemt være nyttigt at kunne se en mere præcis opdeling i stedet for en samlet total i disse tilfælde. Med tiden er dette område forbedret en smule, så vi har nu flere planoplysninger pr. tråd eller pr. partition for nogle operationer. Der er dog stadig lang vej igen.
Det er stadig mindre end nyttigt, at 15.000 separate niveau 1-udslip rapporteres her som et enkelt spil på 15.000 niveauer.
Testvarianter
Denne artikel handler mere om at fremhæve planinformationsbegrænsninger og potentialet for dårlig ydeevne, når der bruges ekstreme antal partitioner, end det handler om at gøre den bestemte eksempeloperation mere effektiv, men der er et par interessante variationer, jeg også vil se på .
Online, Sorter i tempdb
Udfører den samme opdelte indeksoprettelse med ONLINE = ON, SORT_IN_TEMPDB = ON lider ikke af den samme enorme hukommelsesbevilling og spild:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Bemærk, at du bruger ONLINE i sig selv er ikke tilstrækkeligt. Faktisk resulterer det i den samme plan som før med alle de samme problemer, plus en ekstra overhead til at bygge hver indekspartition online. For mig resulterer det i en eksekveringstid på godt et minut. Gud ved, hvor lang tid det ville tage på en lavspecifik Azure-instans med forfærdelig I/O-ydeevne.
I hvert fald, udførelsesplanen med ONLINE = ON, SORT_IN_TEMPDB = ON er:

Sorteringen udføres, før destinationspartitionsnummeret beregnes. Det har ikke egenskaben Partition ID, så det er bare en normal sortering. Hele operationen kører i omkring ti sekunder (der er stadig mange partitioner at oprette). Den reserverer mindre end 3MB hukommelse og bruger maksimalt 816KB. Sikke en forbedring i forhold til 4,6 GB og 15.000 spild.
Indeks først, derefter data
Lignende resultater kan opnås ved først at skrive dataene til en heap-tabel:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Opret derefter en tom partitioneret klynget tabel og indsæt dataene fra heapen:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Dette tager omkring ti sekunder, med en 2MB hukommelsesbevilling og uden spild:
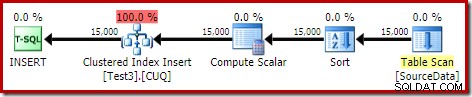
Naturligvis kunne sorteringen også undgås fuldstændigt ved at indeksere den (ikke-partitionerede) kildetabel og indsætte dataene i indeksrækkefølge (den bedste sortering er slet ingen sortering, husk).
Partitioneret heap, derefter data og derefter indeks
For denne sidste variation opretter vi først en partitioneret heap og indlæser de 15.000 testrækker:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Det script kører i et sekund eller to, hvilket er ret godt. Det sidste trin er at oprette det partitionerede klyngeindeks:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
Det er en komplet katastrofe, både fra et præstationssynspunkt og fra et showplaninformationsperspektiv. Selve operationen kører i knap et minut med følgende udførelsesplan:

Dette er en samlokaliseret indsatsplan. Den konstante scanning indeholder en række for hvert partitions-id. Den indvendige side af løkken søger til den aktuelle opdeling af bunken (ja, en søgning på en bunke). Sorteringen har en partitions-id-egenskab (på trods af at denne er konstant pr. loop-iteration), så der er en sortering pr. partition og den uønskede spild-adfærd. Statistikadvarslen på heap-bordet er falsk.
Roden af indsættelsesplanen angiver, at der var reserveret en hukommelsesbevilling på 1 MB, med et maksimum på 144 KB brugt:
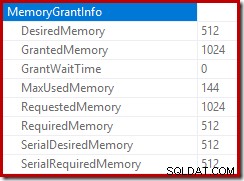
Sorteringsoperatøren rapporterer ikke et spild på niveau 15.000, men laver ellers et fuldstændig rod i den involverede per-loop iteration-matematik:

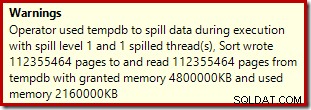
Overvågning af hukommelsen giver DMV under udførelse viser, at denne forespørgsel faktisk kun reserverer 1MB, med et maksimum på 144KB brugt på hver iteration af løkken. (Derimod er 4,6 GB hukommelsesreservationen i den første test absolut ægte.) Dette er selvfølgelig forvirrende.
Problemet (som tidligere nævnt) er, at SQL Server bliver forvirret over, hvordan man bedst rapporterer om, hvad der skete over mange iterationer. Det er sandsynligvis ikke praktisk at inkludere planydeevneoplysninger pr. partition pr. iteration, men man kan ikke komme væk fra det faktum, at det nuværende arrangement til tider giver forvirrende resultater. Vi kan kun håbe, at der en dag kan findes en bedre måde at rapportere denne type information på i et mere konsistent format.