Den generelle strategi, som SQL Server-databasemotoren bruger til at holde en indekseret visning synkroniseret med dens basistabeller – som jeg beskrev mere detaljeret i mit sidste indlæg – er at udføre trinvis vedligeholdelse af visningen, når der sker en dataændringsoperation mod en af tabellerne, der henvises til i visningen. I store træk er tanken at:
- Indsaml oplysninger om ændringerne i basistabel
- Anvend de projektioner, filtre og joinforbindelser, der er defineret i visningen
- Aggregér ændringerne pr. indekseret visningsklyngenøgle
- Beslut om hver ændring skal resultere i en indsættelse, opdatering eller sletning af visningen
- Beregn de værdier, der skal ændres, tilføjes eller fjernes i visningen
- Anvend visningsændringerne
Eller endnu mere kortfattet (omend med risiko for grov forenkling):
- Beregn de trinvise visningseffekter af de oprindelige dataændringer;
- Anvend disse ændringer på visningen
Dette er normalt en meget mere effektiv strategi end at genopbygge hele visningen efter hver underliggende dataændring (den sikre, men langsomme mulighed), men den er afhængig af, at den inkrementelle opdateringslogik er korrekt for enhver tænkelig dataændring, mod enhver mulig indekseret visningsdefinition.
Som titlen antyder, handler denne artikel om et interessant tilfælde, hvor logikken for trinvis opdatering bryder sammen, hvilket resulterer i en korrupt indekseret visning, der ikke længere matcher de underliggende data. Før vi kommer til selve fejlen, skal vi hurtigt gennemgå skalar- og vektoraggregater.
Skalære og vektoraggregater
Hvis du ikke er bekendt med udtrykket, er der to typer aggregater. Et aggregat, der er knyttet til en GROUP BY-sætning (selvom gruppen efter liste er tom), er kendt som en vektoraggregat . Et aggregat uden en GROUP BY-klausul er kendt som et skalæraggregat .
Mens et vektoraggregat garanteret producerer en enkelt outputrække for hver gruppe, der er til stede i datasættet, er skalære aggregater en smule anderledes. Skalære aggregater altid producere en enkelt outputrække, selvom inputsættet er tomt.
Vektor aggregeret eksempel
Følgende AdventureWorks-eksempel beregner to vektoraggregater (en sum og et antal) på et tomt inputsæt:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Disse forespørgsler producerer følgende output (ingen rækker):

Resultatet er det samme, hvis vi erstatter GROUP BY-sætningen med et tomt sæt (kræver SQL Server 2008 eller nyere):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Udførelsesplanerne er også identiske i begge tilfælde. Dette er udførelsesplanen for tælleforespørgslen:
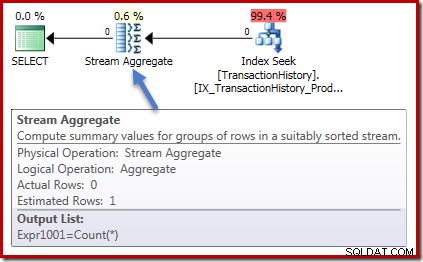
Nul rækker input til Stream Aggregate, og nul rækker ud. Summeudførelsesplanen ser således ud:

Igen nul rækker ind i aggregatet og nul rækker ud. Alle gode simple ting indtil videre.
Skalære aggregater
Se nu, hvad der sker, hvis vi fjerner GROUP BY-sætningen fra forespørgslerne fuldstændigt:
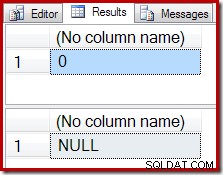
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
I stedet for et tomt resultat, producerer COUNT-aggregatet et nul, og SUM returnerer et NULL:
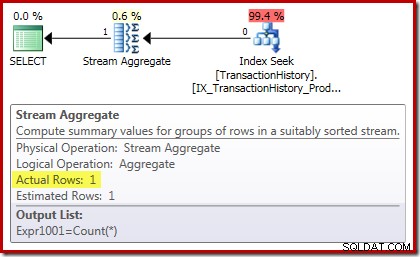
Optællingsplanen bekræfter, at nul-input-rækker producerer en enkelt række af output fra Stream Aggregate:
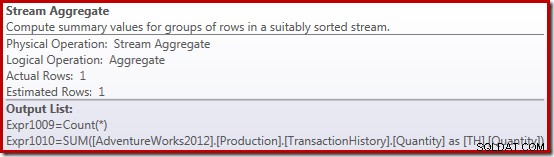
Summeudførelsesplanen er endnu mere interessant:
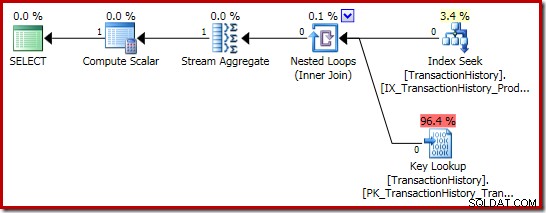
Strømaggregategenskaberne viser et tælleaggregat, der beregnes ud over den sum, vi bad om:
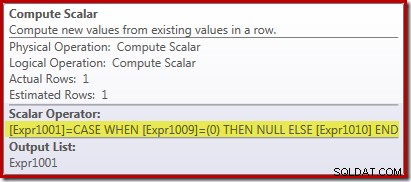
Den nye Compute Scalar-operator bruges til at returnere NULL, hvis antallet af rækker modtaget af Stream Aggregate er nul, ellers returnerer den summen af de data, der er fundet:
Det hele virker måske lidt mærkeligt, men sådan fungerer det:
- Et vektoraggregat med nul rækker returnerer nul rækker;
- Et skalært aggregat producerer altid nøjagtig én række output, selv for et tomt input;
- Det skalære antal af nul rækker er nul; og
- Den skalære sum af nul rækker er NULL (ikke nul).
Den vigtige pointe for vores nuværende formål er, at skalære aggregater altid producerer en enkelt række af output, selvom det betyder at skabe en ud af ingenting. Desuden er den skalære sum af nul rækker NULL, ikke nul.
Disse adfærd er i øvrigt alle "korrekte". Tingene er, som de er, fordi SQL-standarden oprindeligt ikke definerede adfærden for skalære aggregater, og overlod det til implementeringen. SQL Server bevarer sin oprindelige implementering af bagudkompatibilitetsårsager. Vektoraggregater har altid haft veldefineret adfærd.
Indekserede visninger og vektoraggregation
Overvej nu en simpel indekseret visning, der inkorporerer et par (vektor)aggregater:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Følgende forespørgsler viser indholdet af basistabellen, resultatet af forespørgsel i den indekserede visning og resultatet af at køre visningsforespørgslen på den tabel, der ligger til grund for visningen:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
Resultaterne er:
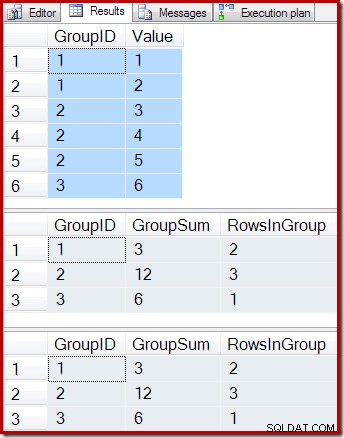
Som forventet giver den indekserede visning og den underliggende forespørgsel nøjagtig de samme resultater. Resultaterne vil fortsat forblive synkroniserede efter alle mulige ændringer af basistabellen T1. For at minde os selv om, hvordan det hele fungerer, kan du overveje det simple tilfælde at tilføje en enkelt ny række til basistabellen:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Udførelsesplanen for denne indsættelse indeholder al den logik, der er nødvendig for at holde den indekserede visning synkroniseret:
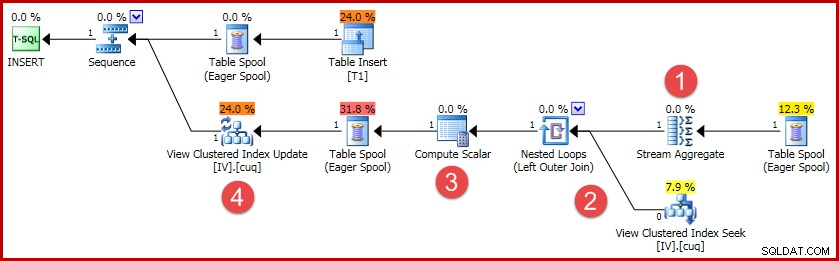
De vigtigste aktiviteter i planen er:
- Strømaggregatet beregner ændringerne pr. indekseret visningsnøgle
- Den ydre tilslutning til visningen linker ændringsoversigten til målvisningsrækken, hvis nogen
- Beregningsskalaren afgør, om hver ændring vil kræve en indsættelse, opdatering eller sletning i forhold til visningen, og beregner de nødvendige værdier.
- Visningsopdateringsoperatøren udfører fysisk hver ændring af visningsklyngeindekset.
Der er nogle planforskelle for forskellige ændringshandlinger i forhold til basistabellen (f.eks. opdateringer og sletninger), men den brede idé bag at holde visningen synkroniseret forbliver den samme:Saml ændringerne pr. visningsnøgle, find visningsrækken, hvis den findes, og udfør derefter en kombination af indsættelse, opdatering og sletning af visningsindekset efter behov.
Uanset hvilke ændringer du foretager i basistabellen i dette eksempel, vil den indekserede visning forblive korrekt synkroniseret – NOEXPAND- og EXPAND VIEWS-forespørgslerne ovenfor vil altid returnere det samme resultatsæt. Sådan skal tingene altid fungere.
Indekserede visninger og skalær aggregation
Prøv nu dette eksempel, hvor den indekserede visning bruger skalær aggregering (ingen GROUP BY-sætning i visningen):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Dette er et helt lovligt indekseret synspunkt; der opstår ingen fejl ved oprettelse af den. Der er dog et fingerpeg om, at vi måske gør noget lidt mærkeligt:Når det er tid til at materialisere visningen ved at skabe det nødvendige unikke klyngeindeks, er der ikke en oplagt kolonne at vælge som nøglen. Normalt ville vi selvfølgelig vælge grupperingskolonnerne fra visningens GROUP BY-klausul.
Scriptet ovenfor vælger vilkårligt kolonnen NumRows. Det valg er ikke vigtigt. Du er velkommen til at oprette det unikke grupperede indeks, uanset hvad du vælger. Visningen vil altid indeholde nøjagtig én række på grund af de skalære aggregater, så der er ingen chance for en unik nøgleovertrædelse. I den forstand er valget af visningsindeksnøgle overflødig, men ikke desto mindre påkrævet.
Ved at genbruge testforespørgslerne fra det forrige eksempel kan vi se, at den indekserede visning fungerer korrekt:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
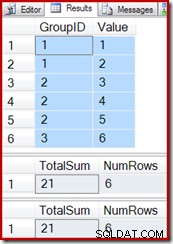
Indsættelse af en ny række i basistabellen (som vi gjorde med vektoraggregatets indekserede visning) fortsætter også med at fungere korrekt:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Udførelsesplanen er ens, men ikke helt identisk:
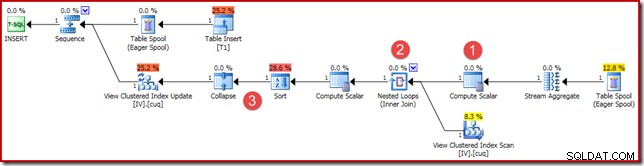
De vigtigste forskelle er:
- Denne nye Compute Scalar er der af samme årsager, som da vi sammenlignede vektor- og skalaraggregeringsresultater tidligere:den sikrer, at en NULL-sum returneres (i stedet for nul), hvis aggregatet fungerer på et tomt sæt. Dette er den påkrævede adfærd for en skalær sum af ingen rækker.
- Den ydre forbindelse, der er set tidligere, er blevet erstattet af en indre forbindelse. Der vil altid være nøjagtig én række i den indekserede visning (på grund af den skalære aggregering), så der er ikke tale om at have behov for en ydre joinforbindelse for at teste, om en visningsrække matcher eller ej. Den ene række i visningen repræsenterer altid hele datasættet. Denne Inner Join har intet prædikat, så det er teknisk set en cross join (til en tabel med en garanteret enkelt række).
- Sorterings- og Collapse-operatørerne er til stede af tekniske årsager, der er beskrevet i min tidligere artikel om vedligeholdelse af indekseret visning. De påvirker ikke den korrekte drift af vedligeholdelsen af den indekserede visning her.
Faktisk kan mange forskellige typer af dataændringsoperationer udføres med succes mod basistabellen T1 i dette eksempel; effekterne vil blive korrekt afspejlet i den indekserede visning. Følgende ændringshandlinger mod basistabellen kan alle udføres, mens den indekserede visning holdes korrekt:
- Slet eksisterende rækker
- Opdater eksisterende rækker
- Indsæt nye rækker
Dette kan virke som en omfattende liste, men det er den ikke.
Bugen afsløret
Spørgsmålet er ret subtilt og relaterer sig (som du burde forvente) til den forskellige adfærd af vektor- og skalaraggregater. Nøglepunkterne er, at et skalært aggregat altid vil producere en outputrække, selvom det ikke modtager nogen rækker på sit input, og den skalære sum af et tomt sæt er NULL, ikke nul.
For at forårsage et problem er det eneste, vi skal gøre, at indsætte eller slette rækker i basistabellen.
Det udsagn er ikke så tosset, som det måske umiddelbart lyder.
Pointen er, at en indsæt- eller sletningsforespørgsel, der ikke påvirker nogen basistabelrækker, stadig opdaterer visningen, fordi det skalære Stream Aggregate i den indekserede visnings vedligeholdelsesdel af forespørgselsplanen vil producere en outputrække, selv når den præsenteres uden input. Beregningsskalaren, der følger streamaggregatet, genererer også en NULL-sum, når antallet af rækker er nul.
Følgende script viser fejlen i aktion:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
Outputtet af det script er vist nedenfor:
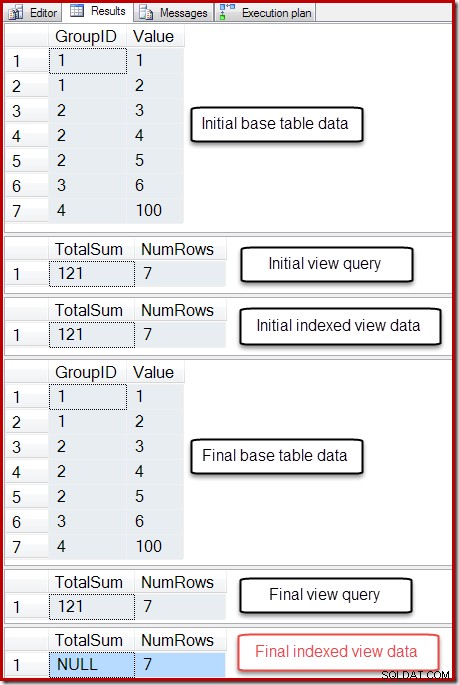
Den endelige tilstand af den indekserede visnings kolonne Totalsum stemmer ikke overens med den underliggende visningsforespørgsel eller basistabeldataene. NULL-summen har ødelagt visningen, hvilket kan bekræftes ved at køre DBCC CHECKTABLE (på den indekserede visning).
Den udførelsesplan, der er ansvarlig for korruptionen, er vist nedenfor:
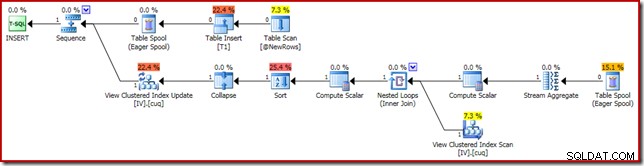
Zoom ind viser nul-rækkernes input til Stream Aggregate og én-rækkes output:
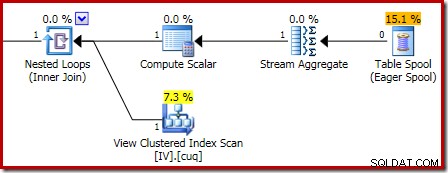
Hvis du vil prøve korruptionsscriptet ovenfor med en sletning i stedet for en indsættelse, er her et eksempel:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
Sletningen påvirker ingen basistabelrækker, men ændrer stadig den indekserede visnings sumkolonne til NULL.
Generalisering af fejlen
Du kan sandsynligvis komme med et hvilket som helst antal indsættelser og slette basistabelforespørgsler, der ikke påvirker rækker og forårsager korruption af denne indekserede visning. Det samme grundlæggende problem gælder dog for en bredere problemklasse end blot indsættelser og sletninger, der ikke påvirker rækker i basistabel.
Det er for eksempel muligt at producere den samme korruption ved hjælp af en indsats, der gør tilføje rækker til basistabellen. Den væsentlige ingrediens er, at ingen tilføjede rækker bør kvalificere sig til visningen . Dette vil resultere i et tomt input til Stream Aggregate og det korruptionsforårsagende NULL række output fra følgende Compute Scalar.
En måde at opnå dette på er at inkludere en WHERE-sætning i visningen, der afviser nogle af basistabelrækkerne:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); I betragtning af den nye begrænsning af gruppe-id'er inkluderet i visningen, vil følgende indsættelse tilføje rækker til basistabellen, men stadig korrupt den indekserede visning vil en NULL sum:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; Outputtet viser den nu velkendte indekskorruption:
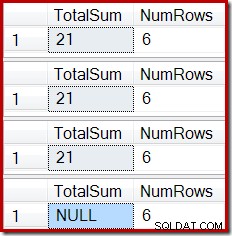
En lignende effekt kan frembringes ved hjælp af en visning, der indeholder en eller flere indre sammenføjninger. Så længe rækker, der tilføjes til basistabellen, afvises (f.eks. ved ikke at deltage), vil Stream Aggregate ikke modtage rækker, Compute Scalar vil generere en NULL sum, og den indekserede visning vil sandsynligvis blive beskadiget.
Sidste tanker
Dette problem opstår tilfældigvis ikke for opdateringsforespørgsler (i hvert fald så vidt jeg kan se), men det ser ud til at være mere tilfældigt end design – det problematiske Stream Aggregate er stadig til stede i potentielt sårbare opdateringsplaner, men Compute Scalar, der genererer NULL summen tilføjes ikke (eller måske optimeres væk). Fortæl mig venligst, hvis du formår at reproducere fejlen ved hjælp af en opdateringsforespørgsel.
Indtil denne fejl er rettet (eller måske skalære aggregater bliver forbudt i indekserede visninger), skal du være meget forsigtig med at bruge aggregater i en indekseret visning uden en GROUP BY-klausul.
Denne artikel blev foranlediget af et Connect-emne indsendt af Vladimir Moldovanenko, som var venlig nok til at efterlade en kommentar til et gammelt blogindlæg af mig (som vedrører en anden indekseret visningskorruption forårsaget af MERGE-erklæringen). Vladimir brugte skalære aggregater i en indekseret visning af gode grunde, så vær ikke for hurtig til at bedømme denne fejl som en edge-case, som du aldrig vil støde på i et produktionsmiljø! Tak til Vladimir for at gøre mig opmærksom på hans Connect-emne.