I del 1 af denne serie brugte du Flask og Connexion til at skabe en REST API, der leverer CRUD-operationer til en simpel struktur i hukommelsen kaldet PEOPLE . Det fungerede for at demonstrere, hvordan Connexion-modulet hjælper dig med at bygge en god REST API sammen med interaktiv dokumentation.
Som nogle bemærkede i kommentarerne til del 1, er PEOPLE strukturen geninitialiseres hver gang applikationen genstartes. I denne artikel lærer du, hvordan du gemmer PEOPLE struktur og de handlinger, som API'en giver, til en database, der bruger SQLAlchemy og Marshmallow.
SQLAlchemy leverer en Object Relational Model (ORM), som gemmer Python-objekter til en databaserepræsentation af objektets data. Det kan hjælpe dig med at fortsætte med at tænke på en pytonisk måde og ikke bekymre dig om, hvordan objektdataene vil blive repræsenteret i en database.
Marshmallow giver funktionalitet til at serialisere og deserialisere Python-objekter, når de flyder ud af og ind i vores JSON-baserede REST API. Marshmallow konverterer Python-klasseforekomster til objekter, der kan konverteres til JSON.
Du kan finde Python-koden til denne artikel her.
Gratis bonus: Klik her for at downloade en kopi af "REST API-eksempler"-vejledningen og få en praktisk introduktion til Python + REST API-principperne med praktiske eksempler.
Hvem er denne artikel til
Hvis du kunne lide del 1 af denne serie, udvider denne artikel dit værktøjsbælte yderligere. Du vil bruge SQLAlchemy til at få adgang til en database på en mere pytonisk måde end direkte SQL. Du vil også bruge Marshmallow til at serialisere og deserialisere de data, der administreres af REST API. For at gøre dette skal du bruge grundlæggende objektorienteret programmeringsfunktioner, der er tilgængelige i Python.
Du vil også bruge SQLAlchemy til at oprette en database samt interagere med den. Dette er nødvendigt for at få REST API op at køre med PEOPLE data brugt i del 1.
Webapplikationen præsenteret i del 1 vil få sine HTML- og JavaScript-filer ændret på mindre måder for også at understøtte ændringerne. Du kan gennemgå den endelige version af koden fra del 1 her.
Yderligere afhængigheder
Før du går i gang med at bygge denne nye funktionalitet, skal du opdatere den virtualenv, du har oprettet, for at køre del 1-koden, eller oprette en ny til dette projekt. Den nemmeste måde at gøre det på, efter du har aktiveret din virtualenv, er at køre denne kommando:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Dette tilføjer mere funktionalitet til din virtualenv:
-
Flask-SQLAlchemytilføjer SQLAlchemy sammen med nogle tie-ins til Flask, hvilket giver programmer adgang til databaser. -
flask-marshmallowtilføjer Flask-delene af Marshmallow, som lader programmer konvertere Python-objekter til og fra serialiserbare strukturer. -
marshmallow-sqlalchemytilføjer nogle Marshmallow-hooks til SQLAlchemy for at tillade programmer at serialisere og deserialisere Python-objekter genereret af SQLAlchemy. -
marshmallowtilføjer størstedelen af Marshmallow-funktionaliteten.
Persondata
Som nævnt ovenfor er PEOPLE datastrukturen i den forrige artikel er en Python-ordbog i hukommelsen. I den ordbog brugte du personens efternavn som opslagsnøgle. Datastrukturen så således ud i koden:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
De ændringer, du foretager i programmet, flytter alle data til en databasetabel. Dette betyder, at dataene vil blive gemt på din disk og vil eksistere mellem kørsler af server.py program.
Fordi efternavnet var ordbogsnøglen, begrænsede koden ændring af en persons efternavn:kun fornavnet kunne ændres. Derudover vil flytning til en database give dig mulighed for at ændre efternavnet, da det ikke længere vil blive brugt som opslagsnøgle for en person.
Konceptuelt kan en databasetabel opfattes som en todimensionel matrix, hvor rækkerne er poster, og kolonnerne er felter i disse poster.
Databasetabeller har normalt en automatisk stigende heltalsværdi som opslagsnøgle til rækker. Dette kaldes den primære nøgle. Hver post i tabellen vil have en primær nøgle, hvis værdi er unik på tværs af hele tabellen. Hvis du har en primærnøgle, der er uafhængig af de data, der er gemt i tabellen, kan du ændre ethvert andet felt i rækken.
Bemærk:
Den auto-inkrementerende primære nøgle betyder, at databasen tager sig af:
- Forøgelse af det største eksisterende primære nøglefelt hver gang en ny post indsættes i tabellen
- Brug af denne værdi som den primære nøgle til de nyligt indsatte data
Dette garanterer en unik primær nøgle, efterhånden som tabellen vokser.
Du kommer til at følge en databasekonvention om at navngive tabellen som ental, så tabellen vil blive kaldt person . Oversættelse af vores PEOPLE strukturen ovenfor til en databasetabel med navnet person giver dig dette:
| person_id | lname | fname | tidsstempel |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Påske | Kanin | 2018-08-08 21:16:01.886834 |
Hver kolonne i tabellen har et feltnavn som følger:
person_id: primært nøglefelt for hver personlname: efternavn på personenfname: fornavn på personentimestamp: tidsstempel forbundet med indsættelses-/opdateringshandlinger
Databaseinteraktion
Du kommer til at bruge SQLite som databasemotor til at gemme PEOPLE data. SQLite er den mest udbredte database i verden, og den leveres med Python gratis. Det er hurtigt, udfører alt sit arbejde ved hjælp af filer og er velegnet til rigtig mange projekter. Det er et komplet RDBMS (Relational Database Management System), der inkluderer SQL, sproget i mange databasesystemer.
Forestil dig i øjeblikket person tabel findes allerede i en SQLite-database. Hvis du har haft nogen erfaring med RDBMS, er du sikkert klar over SQL, det strukturerede forespørgselssprog, som de fleste RDBMS'er bruger til at interagere med databasen.
I modsætning til programmeringssprog som Python, definerer SQL ikke hvordan for at få dataene:det beskriver hvad data ønskes, hvilket efterlader hvordan op til databasemotoren.
En SQL-forespørgsel, der henter alle data i vores person tabel, sorteret efter efternavn, ville se således ud:
SELECT * FROM person ORDER BY 'lname';
Denne forespørgsel fortæller databasemotoren at hente alle felterne fra persontabellen og sortere dem i standard, stigende rækkefølge ved hjælp af lname Mark.
Hvis du skulle køre denne forespørgsel mod en SQLite-database, der indeholder person tabel, ville resultaterne være et sæt poster, der indeholder alle rækkerne i tabellen, hvor hver række indeholder dataene fra alle felterne, der udgør en række. Nedenfor er et eksempel, der bruger SQLite-kommandolinjeværktøjet, der kører ovenstående forespørgsel mod person database tabel:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
Outputtet ovenfor er en liste over alle rækkerne i person databasetabel med rørtegn ('|'), der adskiller felterne i rækken, hvilket udføres til visningsformål af SQLite.
Python er fuldstændig i stand til at interface med mange databasemotorer og udføre SQL-forespørgslen ovenfor. Resultaterne ville højst sandsynligt være en liste over tupler. Den ydre liste indeholder alle posterne i person bord. Hver individuel indre tupel ville indeholde alle data, der repræsenterer hvert felt defineret for en tabelrække.
At få data på denne måde er ikke særlig pytonisk. Listen over poster er okay, men hver enkelt post er kun en tuple af data. Det er op til programmet at kende indekset for hvert felt for at kunne hente et bestemt felt. Følgende Python-kode bruger SQLite til at demonstrere, hvordan man kører ovenstående forespørgsel og viser dataene:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Programmet ovenfor gør følgende:
-
Linje 1 importerer
sqlite3modul. -
Linje 3 opretter en forbindelse til databasefilen.
-
Linje 4 opretter en markør fra forbindelsen.
-
Linje 5 bruger markøren til at udføre en
SQLforespørgsel udtrykt som en streng. -
Linje 6 får alle posterne returneret af
SQLforespørgsel og tildeler dem tilpeoplevariabel. -
Linje 7 og 8 gentag over
peopleliste variabel og udskriv for- og efternavn på hver person.
people variabel fra Linje 6 ovenstående ville se sådan ud i Python:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
Outputtet af programmet ovenfor ser sådan ud:
Kent Brockman
Bunny Easter
Doug Farrell
I ovenstående program skal du vide, at en persons fornavn er ved indeks 2 , og en persons efternavn er ved indeks 1 . Værre, den interne struktur af person skal også være kendt, hver gang du videregiver iterationsvariablen person som en parameter til en funktion eller metode.
Det ville være meget bedre, hvis du fik det tilbage for person var et Python-objekt, hvor hvert af felterne er en attribut for objektet. Dette er en af de ting, SQLAlchemy gør.
Lille Bobby-borde
I ovenstående program er SQL-sætningen en simpel streng, der sendes direkte til databasen for at udføre. I dette tilfælde er det ikke et problem, fordi SQL er en streng bogstaveligt fuldstændig under programmets kontrol. Dog vil use casen for din REST API tage brugerinput fra webapplikationen og bruge den til at oprette SQL-forespørgsler. Dette kan åbne din applikation til angreb.
Du vil huske fra del 1, at REST API for at få en enkelt person fra PEOPLE data så således ud:
GET /api/people/{lname}
Dette betyder, at din API forventer en variabel, lname , i URL-slutpunktstien, som den bruger til at finde en enkelt person . Ændring af Python SQLite-koden fra oven for at gøre dette ville se sådan ud:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Ovenstående kodestykke gør følgende:
-
Linje 1 indstiller
lnamevariabel til'Farrell'. Dette ville komme fra REST API URL-slutpunktstien. -
Linje 2 bruger Python-strengformatering til at oprette en SQL-streng og udføre den.
For at gøre tingene enkle, angiver ovenstående kode lname variabel til en konstant, men i virkeligheden ville den komme fra API URL-slutpunktstien og kunne være hvad som helst leveret af brugeren. SQL'en genereret af strengformateringen ser sådan ud:
SELECT * FROM person WHERE lname = 'Farrell'
Når denne SQL udføres af databasen, søger den efter person tabel for en post, hvor efternavnet er lig med 'Farrell' . Dette er, hvad der er meningen, men ethvert program, der accepterer brugerinput, er også åbent for ondsindede brugere. I programmet ovenfor, hvor lname variabel indstilles af brugerleveret input, dette åbner dit program for det, der kaldes et SQL-injektionsangreb. Dette er det, der kærligt er kendt som Little Bobby Tables:
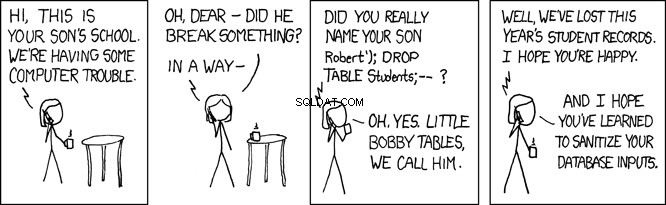
Forestil dig for eksempel en ondsindet bruger kaldet din REST API på denne måde:
GET /api/people/Farrell');DROP TABLE person;
REST API-anmodningen ovenfor angiver lname variabel til 'Farrell');DROP TABLE person;' , som i koden ovenfor ville generere denne SQL-sætning:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
Ovenstående SQL-sætning er gyldig, og når den udføres af databasen, vil den finde én post, hvor lname matcher 'Farrell' . Derefter vil den finde SQL-sætningens skilletegn ; og vil gå lige foran og slippe hele bordet. Dette ville i det væsentlige ødelægge din ansøgning.
Du kan beskytte dit program ved at rense alle data, du får fra brugere af din applikation. At rense data i denne sammenhæng betyder, at dit program skal undersøge de brugerleverede data og sikre sig, at de ikke indeholder noget farligt for programmet. Dette kan være vanskeligt at gøre rigtigt og skal gøres overalt, hvor brugerdata interagerer med databasen.
Der er en anden måde, der er meget nemmere:brug SQLAlchemy. Det vil rense brugerdata for dig, før du opretter SQL-sætninger. Det er en anden stor fordel og grund til at bruge SQLAlchemy, når du arbejder med databaser.
Modellering af data med SQLAlchemy
SQLAlchemy er et stort projekt og giver en masse funktionalitet til at arbejde med databaser ved hjælp af Python. En af de ting, det giver, er en ORM eller Object Relational Mapper, og det er det, du skal bruge til at oprette og arbejde med person database tabel. Dette giver dig mulighed for at kortlægge en række felter fra databasetabellen til et Python-objekt.
Objektorienteret programmering giver dig mulighed for at forbinde data med adfærd, de funktioner, der fungerer på disse data. Ved at oprette SQLAlchemy-klasser er du i stand til at forbinde felterne fra databasetabelrækkerne til adfærd, så du kan interagere med dataene. Her er SQLAlchemy-klassedefinitionen for dataene i person database tabel:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
Klassen Person arver fra db.Model , som du kommer til, når du begynder at bygge programkoden. Indtil videre betyder det, at du arver fra en basisklasse kaldet Model , der giver attributter og funktionalitet, der er fælles for alle klasser afledt af det.
Resten af definitionerne er attributter på klasseniveau defineret som følger:
-
__tablename__ = 'person'forbinder klassedefinitionen medpersondatabasetabel. -
person_id = db.Column(db.Integer, primary_key=True)opretter en databasekolonne, der indeholder et heltal, der fungerer som den primære nøgle for tabellen. Dette fortæller også databasen, atperson_idvil være en automatisk inkrementerende heltalsværdi. -
lname = db.Column(db.String)opretter efternavnsfeltet, en databasekolonne, der indeholder en strengværdi. -
fname = db.Column(db.String)opretter fornavnsfeltet, en databasekolonne, der indeholder en strengværdi. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)opretter et tidsstempelfelt, en databasekolonne, der indeholder en dato/tidsværdi.default=datetime.utcnowparameter indstiller tidsstempelværdien til den aktuelleutcnowværdi, når en post oprettes.onupdate=datetime.utcnowparameter opdaterer tidsstemplet med den aktuelleutcnowværdi, når posten opdateres.
Bemærk:UTC-tidsstempler
Du undrer dig måske over, hvorfor tidsstemplet i ovenstående klasse er standard til og opdateres af datetime.utcnow() metode, som returnerer en UTC eller Coordinated Universal Time. Dette er en måde at standardisere dit tidsstempels kilde på.
Kilden, eller nultid, er en linje, der løber nord og syd fra jordens nord- til sydpol gennem Storbritannien. Dette er nultidszonen, fra hvilken alle andre tidszoner er forskudt. Ved at bruge dette som nultidskilde, er dine tidsstempler forskudt fra dette standardreferencepunkt.
Hvis din applikation tilgås fra forskellige tidszoner, har du en måde at udføre dato/tidsberegninger på. Alt du behøver er et UTC-tidsstempel og destinationens tidszone.
Hvis du skulle bruge lokale tidszoner som din tidsstempelkilde, så kunne du ikke udføre dato/tidsberegninger uden information om de lokale tidszoner, der er forskudt fra nultid. Uden tidsstemplets kildeoplysninger kunne du slet ikke lave nogen sammenligning af dato/klokkeslæt eller matematik.
At arbejde med tidsstempler baseret på UTC er en god standard at følge. Her er et værktøjssæt til at arbejde med og bedre forstå dem.
Hvor er du på vej hen med denne Person klasse definition? Slutmålet er at kunne køre en forespørgsel ved hjælp af SQLAlchemy og få en liste over forekomster af Person tilbage klasse. Lad os som et eksempel se på den forrige SQL-sætning:
SELECT * FROM people ORDER BY lname;
Vis det samme lille eksempelprogram fra oven, men nu ved hjælp af SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Når du ignorerer linje 1 for øjeblikket, er det, du ønsker, alt person poster sorteret i stigende rækkefølge efter lname Mark. Hvad du får tilbage fra SQLAlchemy-sætningerne Person.query.order_by(Person.lname).all() er en liste over Person objekter for alle poster i person databasetabel i den rækkefølge. I ovenstående program er people variabel indeholder listen over Person genstande.
Programmet itererer over people variabel, der tager hver person igen og udskrive for- og efternavn på personen fra databasen. Bemærk, at programmet ikke behøver at bruge indekser for at få fname eller lname værdier:den bruger de attributter, der er defineret på Person objekt.
Brug af SQLAlchemy giver dig mulighed for at tænke i forhold til objekter med adfærd i stedet for rå SQL . Dette bliver endnu mere fordelagtigt, når dine databasetabeller bliver større og interaktionerne mere komplekse.
Serialisering/deserialisering af modellerede data
Det er meget praktisk at arbejde med SQLAlchemy-modellerede data inde i dine programmer. Det er især praktisk i programmer, der manipulerer dataene, måske laver beregninger eller bruger dem til at lave præsentationer på skærmen. Din applikation er en REST API, der i det væsentlige leverer CRUD-operationer på dataene, og som sådan udfører den ikke meget datamanipulation.
REST API'en arbejder med JSON-data, og her kan du løbe ind i et problem med SQLAlchemy-modellen. Fordi de data, der returneres af SQLAlchemy, er Python-klasseforekomster, kan Connexion ikke serialisere disse klasseforekomster til JSON-formaterede data. Husk fra del 1, at Connexion er det værktøj, du brugte til at designe og konfigurere REST API ved hjælp af en YAML-fil, og forbinde Python-metoder til den.
I denne sammenhæng betyder serialisering at konvertere Python-objekter, som kan indeholde andre Python-objekter og komplekse datatyper, til enklere datastrukturer, der kan parses til JSON-datatyper, som er anført her:
string: en strengtypenumber: tal understøttet af Python (heltal, flydende, lange)object: et JSON-objekt, som nogenlunde svarer til en Python-ordbogarray: svarer nogenlunde til en Python-listeboolean: repræsenteret i JSON somtrueellerfalse, men i Python somTrueellerFalsenull: i det væsentlige enNonei Python
Som et eksempel, din Person klasse indeholder et tidsstempel, som er en Python DateTime . Der er ingen dato/tidsdefinition i JSON, så tidsstemplet skal konverteres til en streng for at eksistere i en JSON-struktur.
Din Person klasse er enkel nok, så det ville ikke være meget svært at få dataattributterne fra den og oprette en ordbog manuelt for at returnere fra vores REST URL-slutpunkter. I en mere kompleks applikation med mange større SQLAlchemy-modeller ville dette ikke være tilfældet. En bedre løsning er at bruge et modul kaldet Marshmallow til at gøre arbejdet for dig.
Marshmallow hjælper dig med at oprette et PersonSchema klasse, som er ligesom SQLAlchemy Person klasse, vi har oprettet. Men her, i stedet for at tilknytte databasetabeller og feltnavne til klassen og dens attributter, er PersonSchema klasse definerer, hvordan attributterne for en klasse vil blive konverteret til JSON-venlige formater. Her er Marshmallow-klassens definition for dataene i vores person tabel:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
Klassen PersonSchema arver fra ma.ModelSchema , som du kommer til, når du begynder at bygge programkoden. For nu betyder det PersonSchema arver fra en Marshmallow-basisklasse kaldet ModelSchema , der giver attributter og funktionalitet, der er fælles for alle klasser afledt af det.
Resten af definitionen er som følger:
-
class Metadefinerer en klasse ved navnMetai din klasse.ModelSchemaklasse, atPersonSchemaklasse arver fra udseendet af denne interneMetaklasse og bruger den til at finde SQLAlchemy-modellenPersonogdb.session. Dette er hvordan Marshmallow finder attributter iPersonklasse og typen af disse attributter, så den ved, hvordan man serialiserer/deserialiserer dem. -
modelfortæller klassen, hvilken SQLAlchemy-model der skal bruges til at serialisere/deserialisere data til og fra. -
db.sessionfortæller klassen, hvilken databasesession den skal bruge til at introspektere og bestemme attributdatatyper.
Hvor er du på vej hen med denne klassedefinition? Du vil være i stand til at serialisere en forekomst af en Person klasse ind i JSON-data, og for at deserialisere JSON-data og oprette en Person klasseforekomster fra det.
Opret den initialiserede database
SQLAlchemy håndterer mange af de interaktioner, der er specifikke for bestemte databaser, og lader dig fokusere på datamodellerne, samt hvordan du bruger dem.
Nu hvor du faktisk skal oprette en database, som før nævnt, vil du bruge SQLite. Du gør dette af et par grunde. Det kommer med Python og skal ikke installeres som et separat modul. Det gemmer alle databaseoplysninger i en enkelt fil og er derfor let at konfigurere og bruge.
Installation af en separat databaseserver som MySQL eller PostgreSQL ville fungere fint, men ville kræve installation af disse systemer og få dem op at køre, hvilket er uden for rammerne af denne artikel.
Fordi SQLAlchemy håndterer databasen, er det på mange måder lige meget, hvad den underliggende database er.
Du vil oprette et nyt hjælpeprogram kaldet build_database.py at oprette og initialisere SQLite people.db databasefil, der indeholder din person database tabel. Undervejs vil du oprette to Python-moduler, config.py og models.py , som vil blive brugt af build_database.py og den ændrede server.py fra del 1.
Her kan du finde kildekoden til de moduler, du er ved at oprette, som introduceres her:
-
config.pyfår de nødvendige moduler importeret til programmet og konfigureret. Dette inkluderer Flask, Connexion, SQLAlchemy og Marshmallow. Fordi det vil blive brugt af bådebuild_database.pyogserver.py, vil nogle dele af konfigurationen kun gælde forserver.pyansøgning. -
models.pyer modulet, hvor du skal oprettePersonSQLAlchemy ogPersonSchemaMarshmallow klasse definitioner beskrevet ovenfor. Dette modul er afhængig afconfig.pyfor nogle af de objekter, der er oprettet og konfigureret der.
Konfigurationsmodul
config.py modul, som navnet antyder, er det sted, hvor alle konfigurationsoplysningerne oprettes og initialiseres. Vi kommer til at bruge dette modul til både vores build_database.py programfil og den snart opdaterede server.py fil fra del 1-artiklen. Det betyder, at vi skal konfigurere Flask, Connexion, SQLAlchemy og Marshmallow her.
Selvom build_database.py programmet gør ikke brug af Flask, Connexion eller Marshmallow, det bruger SQLAlchemy til at skabe vores forbindelse til SQLite-databasen. Her er koden til config.py modul:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Her er, hvad ovenstående kode gør:
-
Linje 2 – 4 importer Connexion som du gjorde i
server.pyprogram fra del 1. Det importerer ogsåSQLAlchemyfraflask_sqlalchemymodul. Dette giver din programdatabase adgang. Til sidst importerer denMarshmallowfraflask_marshamllowmodul. -
Linje 6 opretter variablen
basedirpeger på den mappe, programmet kører i. -
Linje 9 bruger
basedirvariabel for at oprette Connexion app-instansen og give den stien tilswagger.ymlfil. -
Linje 12 opretter en variabel
app, som er Flask-forekomsten initialiseret af Connexion. -
Linje 15 bruger
appvariabel til at konfigurere værdier, der bruges af SQLAlchemy. Først sætter denSQLALCHEMY_ECHOtilTrue. Dette får SQLAlchemy til at ekko SQL-sætninger, som den udfører til konsollen. Dette er meget nyttigt til at fejlfinde problemer, når du bygger databaseprogrammer. Indstil dette tilFalsetil produktionsmiljøer. -
Linje 16 indstiller
SQLALCHEMY_DATABASE_URItilsqlite:////' + os.path.join(basedir, 'people.db'). Dette fortæller SQLAlchemy at bruge SQLite som databasen og en fil med navnetpeople.dbi den aktuelle mappe som databasefil. Forskellige databasemotorer, som MySQL og PostgreSQL, vil have forskelligeSQLALCHEMY_DATABASE_URIstrenge for at konfigurere dem. -
Linje 17 indstiller
SQLALCHEMY_TRACK_MODIFICATIONStilFalse, ved at slå SQLAlchemy-hændelsessystemet fra, som er slået til som standard. Hændelsessystemet genererer hændelser, der er nyttige i hændelsesdrevne programmer, men tilføjer betydelige omkostninger. Da du ikke opretter et begivenhedsdrevet program, skal du slå denne funktion fra. -
Linje 19 opretter
dbvariabel ved at kaldeSQLAlchemy(app). Dette initialiserer SQLAlchemy ved at sendeappkonfigurationsoplysningerne er netop indstillet.dbvariabel er det, der importeres tilbuild_database.pyprogram for at give det adgang til SQLAlchemy og databasen. Det vil tjene det samme formål iserver.pyprogram ogpeople.pymodul. -
Linje 23 opretter
mavariabel ved at kaldeMarshmallow(app). Dette initialiserer Marshmallow og giver den mulighed for at introspektere SQLAlchemy-komponenterne, der er knyttet til appen. Dette er grunden til, at Marshmallow initialiseres efter SQLAlchemy.
Modulmodul
models.py modul er oprettet for at give Person og PersonSchema klasser nøjagtigt som beskrevet i afsnittene ovenfor om modellering og serialisering af dataene. Her er koden til det modul:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Her er, hvad ovenstående kode gør:
-
Linje 1 importerer
datetimeobjekt fradatetimemodul, der følger med Python. Dette giver dig en måde at oprette et tidsstempel iPersonklasse. -
Linje 2 importerer
dbogmainstansvariabler defineret iconfig.pymodul. Dette giver modulet adgang til SQLAlchemy-attributter og metoder knyttet tildbvariabel, og Marshmallow-attributterne og -metoderne knyttet tilmavariabel. -
Linje 4 – 9 definere
Personklasse som diskuteret i datamodelleringsafsnittet ovenfor, men nu ved du, hvordb.Modelsom klassen arver fra stammer fra. Dette giverPersonklasse SQLAlchemy-funktioner, såsom en forbindelse til databasen og adgang til dens tabeller. -
Linje 11 – 14 definere
PersonSchemaklasse som blev diskuteret i afsnittet om dataserialisering ovenfor. Denne klasse arver frama.ModelSchemaog giverPersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People data. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodule. -
Line 3 imports the
Personclass definition from themodels.pymodule. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()call. This creates the database by using thedbinstance imported from theconfigmodule. Thedbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonklasse. After it is instantiated, you call thedb.session.add(p)fungere. This uses the database connection instancedbto access thesessionobjekt. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionobject. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Bemærk: At Line 22, no data has been added to the database. Everything is being saved within the session objekt. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py fil. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname værdi.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Beskrivelse |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people bord. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT svar. You can check out the updated swagger.yml fil.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodule. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeopleliste. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Bemærk: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person database. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()instance. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person objekt. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personerNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} afsnit. This section of the UI gets a single person from the database and looks like this:
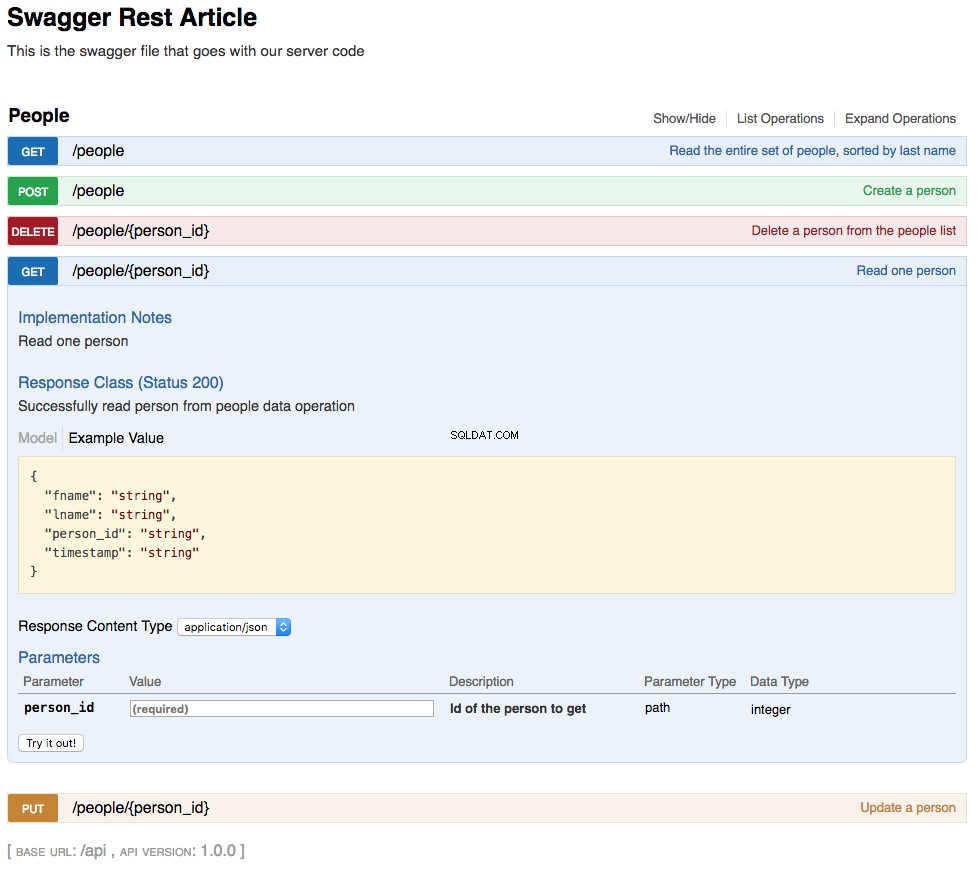
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Konklusion
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.