Den hurtigste måde at beregne en median på bruger SQL Server 2012 OFFSET udvidelse til ORDER BY klausul. Den næsthurtigste løsning bruger en (muligvis indlejret) dynamisk markør, der fungerer på alle versioner, når den kører et tæt sekund. Denne artikel ser på en almindelig ROW_NUMBER fra før 2012 løsning på medianberegningsproblemet for at se, hvorfor det klarer sig dårligere, og hvad der kan gøres for at få det til at gå hurtigere.
Enkelt mediantest
Eksempeldataene for denne test består af en enkelt tabel med ti millioner rækker (gengivet fra Aaron Bertrands originale artikel):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); OFFSET-løsningen
For at sætte benchmark, her er SQL Server 2012 (eller nyere) OFFSET-løsning skabt af Peter Larsson:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Forespørgslen om at tælle rækkerne i tabellen kommenteres ud og erstattes med en hårdkodet værdi for at koncentrere sig om ydeevnen af kernekoden. Med en varm cache og udførelsesplansamling slået fra, kører denne forespørgsel i 910 ms i gennemsnit på min testmaskine. Udførelsesplanen er vist nedenfor:

Som en sidebemærkning er det interessant, at denne moderat komplekse forespørgsel kvalificerer til en triviel plan:
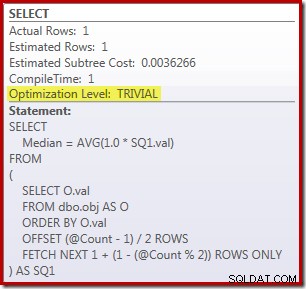
ROW_NUMBER-løsningen
For systemer, der kører SQL Server 2008 R2 eller tidligere, bruger den bedste ydeevne af de alternative løsninger en dynamisk markør som nævnt tidligere. Hvis du ikke er i stand til (eller ikke vil) overveje det som en mulighed, er det naturligt at overveje at efterligne 2012 OFFSET eksekveringsplan ved hjælp af ROW_NUMBER .
Den grundlæggende idé er at nummerere rækkerne i den rigtige rækkefølge og derefter filtrere efter kun den ene eller to rækker, der er nødvendige for at beregne medianen. Der er flere måder at skrive dette på i Transact SQL; en kompakt version, der fanger alle nøgleelementerne, er som følger:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
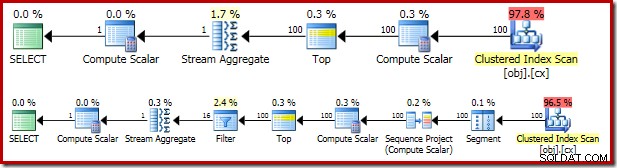
Den resulterende eksekveringsplan er ret lig OFFSET version:

Det er værd at se på hver af planoperatørerne efter tur for at forstå dem fuldt ud:
- Segmentoperatøren er overflødig i denne plan. Det ville være påkrævet, hvis
ROW_NUMBERrangeringsfunktionen havde enPARTITION BYklausul, men det gør den ikke. Alligevel forbliver det i den endelige plan. - Sekvensprojektet tilføjer et beregnet rækkenummer til strømmen af rækker.
- Compute Scalar definerer et udtryk forbundet med behovet for implicit at konvertere
valkolonne til numerisk, så den kan ganges med konstanten1.0i forespørgslen. Denne beregning udskydes, indtil den er nødvendig af en senere operatør (som tilfældigvis er Stream Aggregate). Denne kørselstidsoptimering betyder, at den implicitte konvertering kun udføres for de to rækker, der behandles af Stream Aggregate, ikke de 5.000.001 rækker, der er angivet for Compute Scalar. - Topoperatoren introduceres af forespørgselsoptimeringsværktøjet. Den genkender, at højst kun den første
(@Count + 2) / 2rækker er nødvendige for forespørgslen. Vi kunne have tilføjet enTOP ... ORDER BYi underforespørgslen for at gøre dette eksplicit, men denne optimering gør det stort set unødvendigt. - Filtret implementerer betingelsen i
WHEREklausul, bortfiltrering af alle undtagen de to 'midterste' rækker, der er nødvendige for at beregne medianen (den introducerede Top er også baseret på denne betingelse). - Strømaggregatet beregner
SUMogCOUNTaf de to medianrækker. - Den endelige Compute Scalar beregner gennemsnittet ud fra summen og tæller.
Rå ydeevne
Sammenlignet med OFFSET plan, kan vi forvente, at de yderligere segment-, sekvensprojekt- og filteroperatører vil have en negativ effekt på ydeevnen. Det er værd at bruge et øjeblik på at sammenligne de estimerede omkostninger ved de to planer:
OFFSET planen har en anslået pris på 0,0036266 enheder, mens ROW_NUMBER planen er estimeret til 0,0036744 enheder. Det er meget små tal, og der er lille forskel på de to.
Så det er måske overraskende, at ROW_NUMBER forespørgslen kører faktisk i 4000 ms i gennemsnit sammenlignet med 910 ms gennemsnit for OFFSET opløsning. Noget af denne stigning kan sikkert forklares med overhead for de ekstra planoperatører, men en faktor fire synes overdreven. Der skal være mere i det.
Du har sikkert også bemærket, at kardinalitetsestimaterne for begge estimerede planer ovenfor er temmelig håbløst forkerte. Dette skyldes effekten af Top-operatorerne, som har et udtryk, der refererer til en variabel som deres rækkeantalgrænser. Forespørgselsoptimeringsværktøjet kan ikke se indholdet af variabler på kompileringstidspunktet, så det tyer til sit standardgæt på 100 rækker. Begge planer støder faktisk på 5.000.001 rækker under kørsel.
Det hele er meget interessant, men det forklarer ikke direkte hvorfor ROW_NUMBER forespørgslen er mere end fire gange langsommere end OFFSET version. Når alt kommer til alt, er vurderingen af 100 rækkers kardinalitet lige så forkert i begge tilfælde.
Forbedring af ydeevnen af ROW_NUMBER-løsningen
I min tidligere artikel så vi, hvordan ydeevnen af den grupperede median OFFSET test kunne næsten fordobles ved blot at tilføje en PAGLOCK antydning. Dette tip tilsidesætter lagermotorens normale beslutning om at erhverve og frigive delte låse ved rækkegranulariteten (på grund af den lave forventede kardinalitet).
Som en yderligere påmindelse, PAGLOCK hint var unødvendigt i den enkelte median OFFSET test på grund af en separat intern optimering, der kan springe delte låse på rækkeniveau over, hvilket resulterer i, at kun et lille antal hensigtsdelte låse tages på sideniveau.
Vi forventer muligvis ROW_NUMBER enkelt median løsning for at drage fordel af den samme interne optimering, men det gør den ikke. Overvåger låseaktivitet, mens ROW_NUMBER forespørgslen udføres, ser vi over en halv million delte låse på rækkeniveau bliver taget og frigivet.
Så nu ved vi, hvad problemet er, vi kan forbedre låseydelsen på samme måde, som vi gjorde tidligere:enten med en PAGLOCK lås granularitetstip, eller ved at øge kardinalitetsestimatet ved hjælp af dokumenteret sporingsflag 4138.
Deaktivering af "rækkemålet" ved hjælp af sporingsflaget er den mindre tilfredsstillende løsning af flere årsager. For det første er det kun effektivt i SQL Server 2008 R2 eller nyere. Vi ville højst sandsynligt foretrække OFFSET løsning i SQL Server 2012, så dette begrænser effektivt sporingsflagrettelsen til kun SQL Server 2008 R2. For det andet kræver anvendelse af sporingsflaget tilladelser på administratorniveau, medmindre det anvendes via en planvejledning. En tredje grund er, at deaktivering af rækkemål for hele forespørgslen kan have andre uønskede virkninger, især i mere komplekse planer.
Derimod er PAGLOCK hint er effektivt, tilgængeligt i alle versioner af SQL Server uden særlige tilladelser og har ingen større bivirkninger ud over låsning af granularitet.
Anvendelse af PAGLOCK tip til ROW_NUMBER forespørgsel øger ydeevnen dramatisk:fra 4000 ms til 1500 ms:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
1500 ms resultatet er stadig betydeligt langsommere end 910 ms for OFFSET løsning, men det er i det mindste nu i samme boldgade. Den resterende præstationsforskel skyldes ganske enkelt det ekstra arbejde i udførelsesplanen:

I OFFSET plan, behandles fem millioner rækker så langt som til toppen (med udtrykkene defineret ved Compute Scalar udskudt som diskuteret tidligere). I ROW_NUMBER plan, skal det samme antal rækker behandles af Segment, Sekvensprojekt, Top og Filter.