SQL Server introducerede In-Memory OLTP-objekter i SQL Server 2014. Der var mange begrænsninger i den oprindelige udgivelse; nogle er blevet behandlet i SQL Server 2016, og det forventes, at flere vil blive behandlet i den næste udgivelse, efterhånden som funktionen fortsætter med at udvikle sig. Indtil videre virker adoption af In-Memory OLTP ikke særlig udbredt, men efterhånden som funktionen modnes, forventer jeg, at flere kunder vil begynde at spørge om implementering. Som med enhver større skema- eller kodeændring anbefaler jeg en grundig test for at afgøre, om In-Memory OLTP vil give de forventede fordele. Med det i tankerne var jeg interesseret i at se, hvordan ydeevnen ændrede sig for meget simple INSERT-, UPDATE- og DELETE-sætninger med In-Memory OLTP. Jeg håbede på, at hvis jeg kunne demonstrere låsning eller låsning som et problem med diskbaserede tabeller, så ville tabellerne i hukommelsen give en løsning, da de er låse- og låsefri.
Jeg udviklede følgende test tilfælde:
- En diskbaseret tabel med traditionelle lagrede procedurer for DML.
- En In-Memory-tabel med traditionelle lagrede procedurer for DML.
- En tabel i hukommelsen med indbyggede kompilerede procedurer for DML.
Jeg var interesseret i at sammenligne ydeevnen af traditionelle lagrede procedurer og indbyggede kompilerede procedurer, fordi en begrænsning ved en indbygget kompileret procedure er, at alle tabeller, der henvises til, skal være i hukommelsen. Mens enkeltrækkede, solitære modifikationer kan være almindelige i nogle systemer, ser jeg ofte ændringer, der forekommer i en større lagret procedure med flere sætninger (SELECT og DML), der får adgang til en eller flere tabeller. In-Memory OLTP-dokumentationen anbefaler på det kraftigste at bruge indbyggede kompilerede procedurer for at få det bedste udbytte med hensyn til ydeevne. Jeg ville gerne forstå, hvor meget det forbedrede ydeevnen.
Opsætningen
Jeg oprettede en database med en hukommelsesoptimeret filgruppe og oprettede derefter tre forskellige tabeller i databasen (en disk-baseret, to i hukommelsen):
- DiskTabel
- InMemory_Temp1
- InMemory_Temp2
DDL var næsten den samme for alle objekter, idet den tog højde for on-disk versus in-memory, hvor det var relevant. DiskTable DDL vs. In-Memory DDL:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Jeg oprettede også ni lagrede procedurer - en for hver tabel/ændringskombination.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Opdatering
- InMemRegularSP _Slet
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Hver lagret procedure accepterede et heltalsinput til loop for det antal ændringer. De lagrede procedurer fulgte det samme format, variationer var kun den tabel, der blev tilgået, og om objektet var oprindeligt kompileret eller ej. Den komplette kode til at oprette databasen og objekterne kan findes her, med eksempler på INSERT og UPDATE sætninger nedenfor:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Bemærk:IDs_*-tabellerne blev genudfyldt efter hvert sæt INSERT'er var fuldført, og var specifikke for de tre forskellige scenarier.
Testmetode
Testen blev udført ved hjælp af .cmd-scripts, som brugte sqlcmd til at kalde et script, der udførte den lagrede procedure, for eksempel:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"afslut
Jeg brugte denne tilgang til at oprette en eller flere forbindelser til databasen, der ville køre samtidigt. Udover at forstå grundlæggende ændringer i præstationer, ønskede jeg også at undersøge effekten af forskellige arbejdsbelastninger. Disse scripts blev initieret fra en separat maskine for at eliminere overhead af instansierende forbindelser. Hver lagret procedure blev udført 1000 gange af en forbindelse, og jeg testede 1 forbindelse, 10 forbindelser og 100 forbindelser (henholdsvis 1000, 10000 og 100000 ændringer). Jeg fangede præstationsmålinger ved hjælp af Query Store og fangede også Wait Statistics. Med Query Store kunne jeg fange gennemsnitlig varighed og CPU for hver lagret procedure. Ventestatistikdata blev registreret for hver forbindelse ved hjælp af dm_exec_session_wait_stats, og derefter aggregeret for hele testen.
Jeg kørte hver test fire gange og beregnede derefter de overordnede gennemsnit for de data, der blev brugt i dette indlæg. Scripts, der bruges til test af arbejdsbelastning, kan downloades herfra.
Resultater
Som man ville forudsige, var ydeevnen med In-Memory-objekter bedre end med disk-baserede objekter. En In-Memory-tabel med en almindelig lagret procedure havde dog nogle gange sammenlignelig eller kun lidt bedre ydeevne sammenlignet med en diskbaseret tabel med en almindelig lagret procedure. Husk:Jeg var interesseret i at forstå, om jeg virkelig havde brug for en kompileret lagret procedure for at få en stor fordel med en in-memory-tabel. For dette scenarie gjorde jeg. I alle tilfælde havde in-memory-tabellen med den oprindeligt kompilerede procedure en væsentlig bedre ydeevne. De to grafer nedenfor viser de samme data, men med forskellige skalaer for x-aksen, for at demonstrere, at ydeevnen for almindelige lagrede procedurer, der ændrer data, forringes med flere samtidige forbindelser.
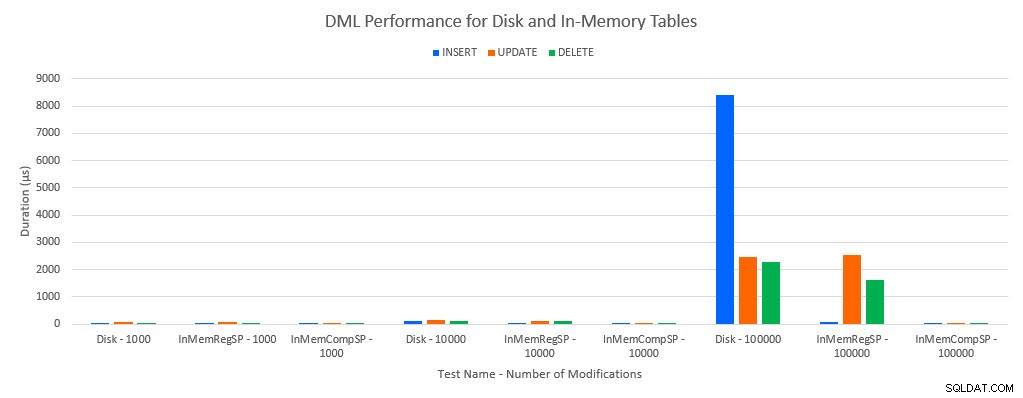
DML-ydelse efter test og arbejdsbelastning
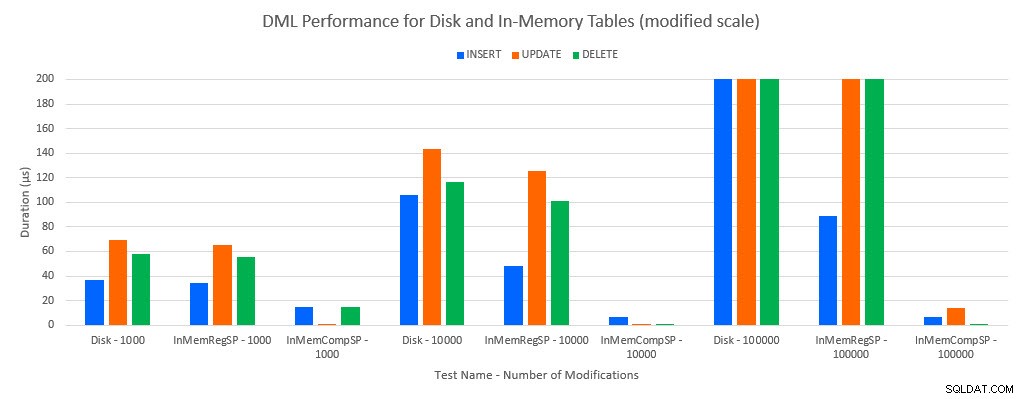
DML-ydeevne efter test og arbejdsbelastning [Modificeret skala]
Undtagelsen er INSERTs i In-Memory-tabellen med den almindelige lagrede procedure. Med 100 forbindelser er den gennemsnitlige varighed over 8ms for en diskbaseret tabel, men mindre end 100 mikrosekunder for In-Memory-tabellen. Den sandsynlige årsag er fraværet af låsning og låsning med In-Memory-tabellen, og dette understøttes med ventestatistikdata:
| Test | INDSÆT | OPDATERING | SLET |
|---|---|---|---|
| Disktabel – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Disktabel – 10.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 10.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 10.000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| Disktabel – 100.000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 100.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 100.000 | WRITELOG | WRITELOG | WRITELOG |
Ventstatistik ved test
Ventestatistikdata er angivet her baseret på samlet ressourceventetid (som generelt også er oversat til højeste gennemsnitlige ressourcetid, men der var undtagelser). WRITELOG ventetypen er den begrænsende faktor i dette system det meste af tiden. Men PAGELATCH_EX venter på 100 samtidige forbindelser, der kører INSERT-sætninger, tyder på, at med yderligere belastning kan låse- og låseadfærden, der eksisterer med diskbaserede tabeller, være begrænsende faktor. I UPDATE- og DELETE-scenarierne med 10 og 100 forbindelser til de diskbaserede tabeltests var den gennemsnitlige ressourceventetid højest for låse (LCK_M_X).
Konklusion
In-Memory OLTP kan absolut give et ydelsesboost for den rigtige arbejdsbyrde. Eksemplerne testet her er dog ekstremt enkle og bør ikke bedømmes som grund alene til at migrere til en In-Memory-løsning. Der er flere begrænsninger, der stadig eksisterer, som skal overvejes, og grundig test skal udføres, før en migrering finder sted (især fordi migrering til en In-Memory-tabel er en offlineproces). Men for det rigtige scenarie kan denne nye funktion give et ydelsesboost. Så længe du forstår, at nogle underliggende begrænsninger stadig vil eksistere, såsom transaktionsloghastighed for holdbare tabeller, dog højst sandsynligt på en reduceret måde – uanset om tabellen findes på disk eller i hukommelsen.