
Denne måneds T-SQL tirsdag er vært for Mike Donnelly (@SQLMD), og han opsummerer emnet som følger:
Emnet i denne måned er ligetil, men meget åbent. Du skal lære noget nyt og derefter skrive et blogindlæg, der forklarer det.Nå, fra det øjeblik Mike annoncerede emnet, satte jeg mig ikke rigtig for at lære noget nyt, og da weekenden nærmede sig, og jeg vidste, at mandag ville angribe mig med jurypligt, troede jeg, at jeg skulle sidde her måned ud.
Så lærte Martin Smith mig noget, jeg enten aldrig vidste eller vidste for længe siden, men har glemt (nogle gange ved du ikke, hvad du ikke ved, og nogle gange kan du ikke huske, hvad du aldrig vidste, og hvad du ikke kan Husk). Min erindring var, at jeg ændrede en kolonne fra NOT NULL til NULL skal være en metadata-operation, hvor skrivning til enhver side udskydes, indtil den side er opdateret af andre årsager, da NULL bitmap behøvede ikke at eksistere før mindst én række kunne blive NULL .
I det samme indlæg mindede @ypercube mig også om dette relevante citat fra Books Online (tastefejl og det hele):
Ændring af en kolonne fra NOT NULL til NULL understøttes ikke som en onlinehandling, når den ændrede kolonne er referencer fra ikke-klyngede indekser."Ikke en online-operation" kan fortolkes som "ikke en metadata-kun-operation" - hvilket betyder, at det faktisk vil være en datastørrelse (jo større dit indeks, jo længere tid vil det tage).
Jeg satte mig for at bevise dette med et ret simpelt (men langvarigt) eksperiment mod en specifik målkolonne for at konvertere fra NOT NULL til NULL . Jeg ville oprette 3 tabeller, alle med en klynget primærnøgle, men hver med et andet ikke-klynget indeks. Den ene ville have målkolonnen som en nøglekolonne, den anden som en INCLUDE kolonne, og den tredje ville slet ikke henvise til målkolonnen.
Her er mine tabeller, og hvordan jeg udfyldte dem:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Hver tabel havde 100.000 rækker, de klyngede indekser havde 310 sider, og de ikke-klyngede indekser havde enten 272 sider (test1 og test2 ) eller 174 sider (test3 ). (Disse værdier er nemme at få fra sys.dm_db_index_physical_stats .)
Dernæst havde jeg brug for en enkel måde at fange operationer, der blev logget på sideniveau – jeg valgte sys.fn_dblog() , selvom jeg kunne have gravet dybere og kigget på sider direkte. Jeg gad ikke rode med LSN-værdier for at overføre til funktionen, da jeg ikke kørte dette i produktionen og var ligeglad med ydeevnen, så efter testene dumpede jeg bare resultaterne af funktionen, undtagen data, der blev logget før ALTER TABLE operationer.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Nu kunne jeg køre mine test, som var meget enklere end opsætningen.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Nu kunne jeg undersøge de operationer, der blev logget i hvert enkelt tilfælde:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Resultaterne synes at tyde på, at hver bladside i det ikke-klyngede indeks berøres for de tilfælde, hvor målkolonnen blev nævnt i indekset på nogen måde, men ingen sådanne operationer forekommer i det tilfælde, hvor målkolonnen ikke er nævnt i nogen ikke-klynget indeks:
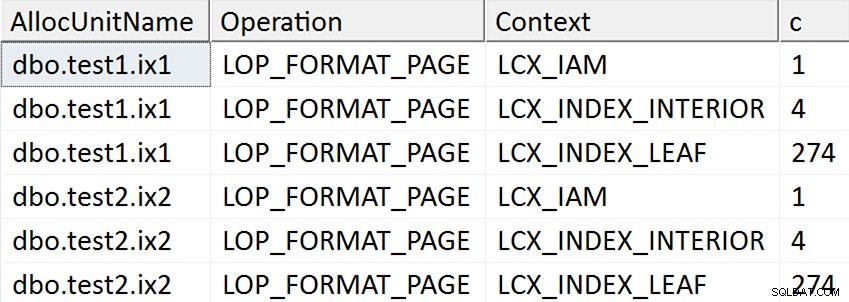
Faktisk tildeles nye sider i de første to tilfælde (du kan validere det med DBCC IND , som Spörri gjorde i sit svar), så operationen kan foregå online, men det betyder ikke, at den er hurtig (da den stadig skal udskrive en kopi af alle disse data og lave NULL bitmapændring som en del af udskrivning af hver ny side, og log al den aktivitet).
Jeg tror, de fleste mennesker ville have mistanke om, at det at ændre en kolonne fra NOT NULL til NULL ville kun være metadata-kun i alle scenarier, men jeg har vist her, at dette ikke er sandt, hvis kolonnen refereres af et ikke-klynget indeks (og lignende ting sker, uanset om det er en nøgle eller INCLUDE kolonne). Måske kan denne operation også tvinges til at være ONLINE i Azure SQL Database i dag, eller vil det være muligt i den næste større version? Dette vil ikke nødvendigvis få de faktiske fysiske operationer til at ske hurtigere, men det vil forhindre blokering som et resultat.
Jeg testede ikke det scenarie (og analysen af, om det virkelig er online, er alligevel sværere i Azure), og jeg testede det heller ikke på en bunke. Noget jeg kan gense i et fremtidigt indlæg. I mellemtiden skal du være forsigtig med eventuelle antagelser, du måtte gøre om handlinger, der kun er metadata.