En løndatamodel giver dig mulighed for nemt at beregne dine medarbejderes løn. Hvordan fungerer denne model?
Uanset om du driver en lille eller stor virksomhed, har du brug for en form for lønløsning. Det er her, en lønansøgning kommer til nytte. Plus, jo større virksomheden er, jo sværere bliver det at håndtere medarbejdernes lønberegninger; her bliver en lønansøgning en nødvendighed. For at hjælpe dig med at forstå alle de data, der kræves til en sådan applikation, leder vi dig gennem en relateret datamodel.
Lad os se, hvordan vores løndatamodel fungerer!
Datamodel
Med at skabe denne datamodel forsøgte jeg at skabe en model, der er generelt anvendelig for enhver virksomhed. Der vil naturligvis altid være forskelle i regler, virksomhedspolitikker osv., der vil kræve, at modellen skal tilpasses til at dække behovene for en specifik lønsum. Principperne i denne model burde dog være relevante for de fleste organisationer.
Det skal bemærkes, at denne model blev skabt med flere antagelser:
- Løn som aftalt i ansættelseskontrakt er per år.
- Nettoløn (dvs. med visse beløb fratrukket skat osv.) udbetales til medarbejderne.
- Løn udbetales månedligt.
Datamodellen består af fjorten tabeller og er opdelt i to emneområder:
MedarbejdereLøn
For bedre at forstå modellen er det nødvendigt at gennemgå hvert fagområde grundigt.
Medarbejdere
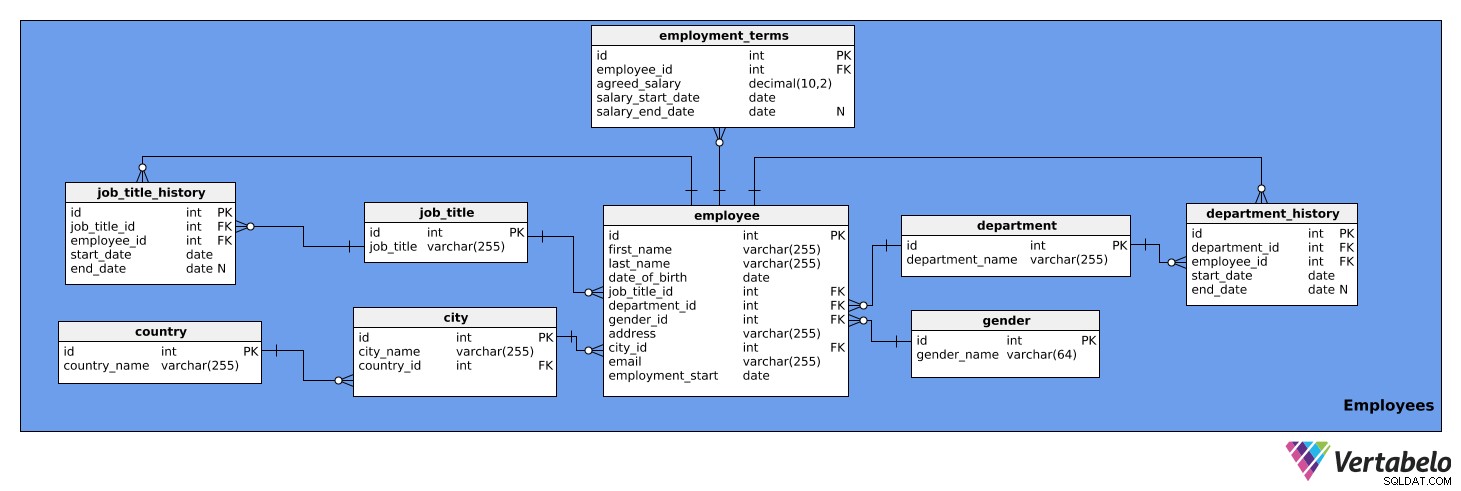
Dette emneområde indeholder detaljerede oplysninger om medarbejdere. Den består af ni tabeller:
medarbejderansættelsesvilkårjob_titeljob_titelhistorieafdelingafdelingshistoriebylandkøn
Den første tabel, vi vil se på, er medarbejderen bord. Den indeholder en liste over alle medarbejdere og deres relevante detaljer. Tabellens attributter er:
id– Et unikt ID for hver medarbejder.fornavn– Medarbejderens fornavn.efternavn– Medarbejderens efternavn.job_titel-id– Referencer tiljob_titletabel.afdelings-id– Henviser tilafdelingentabel.gender_id– Refererer tilkønnet tabel. adresse– Medarbejderens adresse.by_id– Henviser tilbyentabel.e-mail– Medarbejderens e-mail.beskæftigelse_start– Datoen, hvor denne persons ansættelse startede.
Bemærk, at kolonnerne job_title_id og department_id er overflødige, da oplysningerne om aktuelle stillingsbetegnelser og afdelinger kan tilgås fra job_title_history og department_history tabeller. Vi vil dog beholde disse to kolonner i denne tabel for hurtigere adgang til oplysningerne.
Følgende er ansættelsesvilkårene bord. Den gemmer data om hver enkelt medarbejders løn, som aftalt i ansættelseskontrakten, og hvordan den har ændret sig over tid. Tabellens attributter er:
id– Et unikt ID for hvert sæt ansættelsesvilkår.medarbejder-id– Henviser tilmedarbejderentabel.aftalt_løn– Den i ansættelseskontrakten anførte løn.løn_startdato– Startdatoen for den aftalte løn.løn_slutdato– Slutdatoen for den aftalte løn. Dette kan være NULL, fordi en løn muligvis ikke har nogen planlagt ændring.
job_titlen tabel er en liste over de stillingsbetegnelser, der kan tildeles forskellige virksomhedens medarbejdere, f.eks. analytiker, chauffør, sekretær, direktør osv. Tabellen har følgende egenskaber:
id– Et unikt ID for hver stillingsbetegnelse.job_titel– Navnet på stillingsbetegnelsen. Dette er den alternative nøgle.
Vi har også brug for et bord til at gemme hver medarbejders jobtitelhistorik. Vi har brug for dette, fordi medarbejdere kan forfremmes, degraderes eller omplaceres i virksomheden. job_title_history tabel vil administrere disse oplysninger og vil bestå af følgende attributter:
id– Et unikt ID for jobtitlens historiske post.job_titel-id– Referencer tiljob_titletabel.medarbejder-id– Henviser tilmedarbejderentabel.startdato– Den dato, hvor medarbejderen første gang havde denne stillingsbetegnelse.slutdato– Da medarbejderen holdt op med at have den stillingsbetegnelse. Dette kan være NULL, fordi medarbejderen i øjeblikket muligvis har denne stillingsbetegnelse.
Kombinationen af job_title_id , medarbejder-id og startdato er den alternative nøgle til ovenstående tabel. En medarbejder kan kun få tildelt én stillingsbetegnelse på en given dato.
Den næste tabel er afdelingen bord. Dette vil blot vise alle virksomhedens afdelinger, såsom IT, Regnskab, Juridisk osv. Det indeholder to attributter:
id– Et unikt ID for hver afdeling.afdelingsnavn– Navnet på hver afdeling. Dette er den alternative nøgle.
Medarbejdere kan også skifte afdeling i virksomheden. Derfor skal vi have en afdelingshistorie bord. Denne tabel gemmer følgende:
id– Et unikt ID for den pågældende afdelings historiske post.afdelings-id– Henviser tilafdelingentabel.medarbejder-id– Henviser tilmedarbejderentabel.startdato– Den dato, hvor en medarbejder begyndte at arbejde i en afdeling.slutdato- Den dato, hvor en medarbejder stoppede med at arbejde i den afdeling. Dette kan være NULL, fordi medarbejderen muligvis stadig arbejder der.
Kombinationen af department_id , medarbejder-id og startdato er den alternative nøgle. En medarbejder kan kun arbejde i én afdeling ad gangen.
Den næste tabel, vi vil tale om, er byen bord. Dette er en liste over alle relevante byer. Den har følgende attributter:
id– Et unikt ID for hver by.bynavn– Byens navn.country_id– Henviser tillandettabel.
landet bord er næste i vores model. Det er blot en liste over lande, og den indeholder følgende oplysninger:
id– Et unikt ID for hvert land.land_navn– Landets navn. Dette er den alternative nøgle.
Den sidste tabel i dette emneområde er kønnet bord. Denne tabel viser alle køn. Den indeholder følgende attributter:
id– Et unikt ID for hvert køn.kønsnavn– Navnet på køn.
Lad os nu analysere det andet emneområde.
Løn
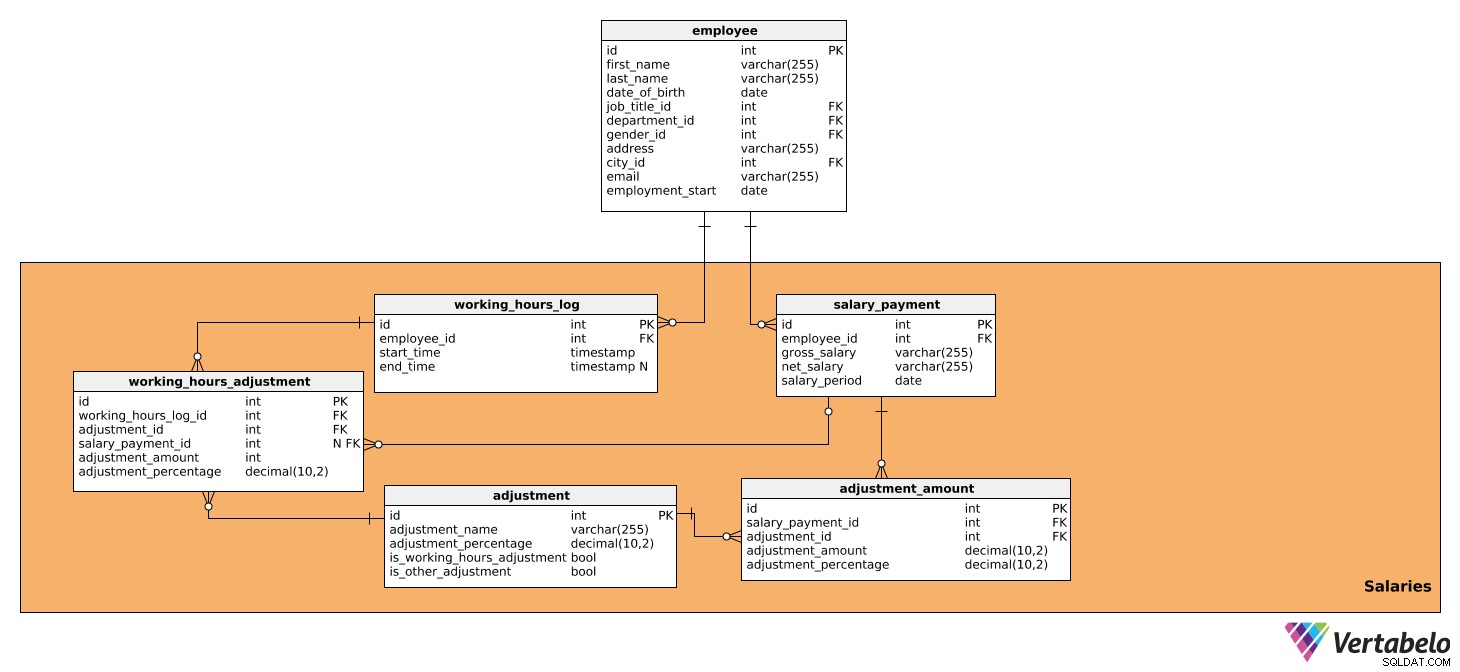
Dette emneområde består af tabeller, der indeholder alle de data, der direkte påvirker lønberegningen for hver periode samt det beløb, der skal udbetales. Den består af fem borde:
løn_betalingworking_hours_logarbejdstimersjusteringjusteringadjustment_amount
Lad os nu se på hver tabel.
Den første tabel er løn_betaling . Den indeholder alle relevante detaljer om den løn, der udbetales til hver medarbejder og har følgende egenskaber:
id– Et unikt ID for hver løn.medarbejder-id– Henviser tilmedarbejderentabel.bruttoløn– Bruttolønnen, som skal danne grundlag for yderligere tilpasninger.netto_løn– Nettolønnen (dvs. det beløb, medarbejderen modtager efter forskellige fradrag).lønperiode– Den periode, lønnen beregnes og udbetales for.
For det andet er working_hours_log bord. Den indeholder data om det antal timer, hver medarbejder har arbejdet, hvilket kan påvirke visse lønreguleringer. Denne tabel har følgende attributter:
id– Et unikt ID for hver logindtastning.medarbejder-id– Henviser tilmedarbejderentabel.starttid– Det tidspunkt, hvor medarbejderen loggede ind, dvs. begyndte at arbejde for dagen.sluttid– Når medarbejderen loggede ud. Det kan være NULL, fordi vi ikke kender det nøjagtige tidspunkt, før medarbejderen logger ud.
Den næste tabel, vi vil analysere, er arbejdstimersjustering . Denne tabel vil kun blive brugt i beregningen af justeringer baseret på de arbejdede timer, dvs. dem der har en TRUE værdi i is_working_hours_adjustment i justering bord. Attributterne er som følger:
id– Et unikt ID for hver justering.working_hours_log_id– Henviser tilworking_hours_logtabel.adjustment_id- Henviser tiljusteringentabel.salary_payment_id– Henviser tillønbetaling bord. Denne værdi kan være NULL fordi salary_payment_idvil kun blive brugt én gang om måneden, når vi igangsætter en lønberegning.adjustment_amount– Størrelsen af justeringen.adjustment_procent– Det procentvise beløb for justeringen. Dette vil blive brugt til historiske formål, da procentdelen kan ændre sig over tid.
Den næste tabel, vi vil tale om, er justeringen bord. Den indeholder information om alle de reguleringer, der anvendes til lønberegning, dvs. alle de skatter og bidrag, der har indflydelse på lønsummen. Den vil også indeholde alle de justeringer, der afhænger af de timer, der arbejdes og ikke arbejdes, såsom bonusser, overarbejde, sygeorlov og barsel. Til det har vi brug for følgende data:
id– Et unikt ID for hver justering.adjustment_name– Et navn, der beskriver denne justering.adjustment_procent– Det procentvise beløb for den bestemte justering.is_working_hours_adjustment– Der er tale om en flagmarkering, hvis en justering direkte afhænger af arbejdstiden, f.eks. overarbejde, sygemelding mv.is_other_adjustment– Dette er en flagmarkeringsjustering, som ikke gør direkte afhængig af arbejdstimer, såsom skattefradrag, sociale bidrag, arbejdsgiverbidrag osv.
Derefter skal vi bruge adjustment_amount bord. Det vil blive brugt til at beregne alle lønjusteringer undtagen dem, der allerede er i arbejdstimersjustering , dvs. dem, der har en TRUE-værdi i is_other_adjustment i justering bord. Tabellen indeholder følgende attributter:
id– Et unikt ID for hver indtastning af justeringsbeløb.salary_payment_id– Henviser tillønbetaling tabel. adjustment_id– Refererer tiljusteringentabel.adjustment_amount– Størrelsen af hver beregnet justering.adjustment_procent- Det procentvise beløb for justeringen. Det vil blive brugt til historiske formål, da procentdelen kan ændre sig over tid.
Lad mig give dig et eksempel på, hvordan tabellerne working_hours_log , justering af arbejdstimer , justering , og adjustment_amount arbejde sammen om at beregne en løn. Hver dag logger medarbejderen, hvornår han eller hun kommer på arbejde, og hvornår han eller hun tager afsted. Disse data kan ses i working_hours_log bord. Lad os sige, at vores medarbejder har arbejdet 10 timer overarbejde i en måned, og i henhold til virksomhedens politik vil han eller hun blive betalt 20 % mere i timen for hver time overarbejde. Ved at henvise til justeringen tabel, vil vi være i stand til at finde den nødvendige justering, altså overarbejde, som vil have en vis procentdel (20%). Vi har også is_working_hours_adjustment indstillet til TRUE. Ved at bruge data fra disse to tabeller vil vi være i stand til at beregne justeringen og gemme den i working_hours_adjustment bord.
Nu kan vi beregne alle andre justeringer, der ikke afhænger af arbejdstimerne. Dette vil blive gjort i adjustment_amount bord. Ligesom vi gjorde ovenfor, vil vi referere til justeringen tabel og find de justeringer, som vi skal bruge – f.eks. skattefradrag, socialsikringsbidrag eller arbejdsgiverbidrag – og deres relevante procentsatser. is_other_adjustment flag i justeringen tabel vil blive sat til TRUE for disse justeringer.
Baseret på disse beregninger kan vi gemme bruttoløn- og nettoløndata i løn_betaling bord.
Ved at gennemgå dette eksempel har vi dækket alt i vores datamodel!
Kan du lide løndatamodellen?
Jeg forsøgte at skabe en model, der kunne bruges i næsten alle situationer. Det er dog umuligt at inkludere alle de specifikke parametre, der påvirker lønberegningen, i en artikel af denne længde. Ved at dække generelle principper har jeg forsøgt at gøre denne model nyttig som et solidt grundlag for din løndatamodel.
Hvad synes du om løndatamodellen? Er det anvendeligt som en løsning til dine lønbehov? Har du fundet på noget andet? Er der specifikke problemer, du har fundet, som ville ændre datamodellen væsentligt? Sig din mening i kommentarfeltet.