I den sidste måned har jeg haft kontakt med adskillige kunder, der har haft implicitte konverteringsproblemer på kolonnesiden i forbindelse med deres OLTP-arbejdsbelastninger. Ved to lejligheder var den akkumulerede effekt af de implicitte konverteringer på kolonnesiden den underliggende årsag til, at det overordnede ydelsesproblem for SQL-serveren blev gennemgået, og der er desværre ikke en magisk indstilling eller konfigurationsmulighed, som vi kan justere for at forbedre situationen når dette er tilfældet. Selvom vi kan tilbyde forslag til at rette andre, lavere hængende frugter, der kan påvirke ydeevnen generelt, er effekten af de implicitte konverteringer på kolonnesiden noget, der enten kræver en skemadesignændring for at rette eller en kodeændring for at forhindre kolonne- sidekonvertering fra at ske mod det aktuelle databaseskema fuldstændigt.
Implicitte konverteringer er resultatet af, at databasemotoren sammenligner værdier af forskellige datatyper under udførelse af forespørgsler. En liste over de mulige implicitte konverteringer, der kan forekomme inde i databasemotoren, kan findes i Books Online-emnet Data Type Conversion (Database Engine). Implicitte konverteringer sker altid baseret på datatypeprioriteten for de datatyper, der sammenlignes under operationen. Datatypeprioritetsrækkefølgen kan findes i Books Online-emnet Data Type Precedence (Transact-SQL). Jeg bloggede for nylig om de implicitte konverteringer, der resulterer i en indeksscanning, og leverede diagrammer, der også kan bruges til at bestemme de mest problematiske implicitte konverteringer.
Opsætning af testene
For at demonstrere præstationsomkostningerne forbundet med implicitte konverteringer på kolonnesiden, der resulterer i en indeksscanning, har jeg kørt en række forskellige tests mod AdventureWorks2012-databasen ved at bruge tabellen Sales.SalesOrderDetail til at bygge testtabeller og datasæt. Den mest almindelige kolonneside-implicitte konvertering, som jeg ser som konsulent, sker, når kolonnetypen er char eller varchar, og applikationskoden sender en parameter, der er nchar eller nvarchar, og filtrerer på char- eller varchar-kolonnen. For at simulere denne type scenarie oprettede jeg en kopi af SalesOrderDetail-tabellen (kaldet SalesOrderDetail_ASCII) og ændrede CarrierTrackingNumber-kolonnen fra nvarchar til varchar. Derudover tilføjede jeg et ikke-klynget indeks på CarrierTrackingNumber-kolonnen til den originale SalesOrderDetail-tabel samt den nye SalesOrderDetail_ASCII-tabel.
USE [AdventureWorks2012]
GO
-- Add CarrierTrackingNumber index to original Sales.SalesOrderDetail table
IF NOT EXISTS
(
SELECT 1 FROM sys.indexes
WHERE [object_id] = OBJECT_ID(N'Sales.SalesOrderDetail')
AND name=N'IX_SalesOrderDetail_CarrierTrackingNumber'
)
BEGIN
CREATE INDEX IX_SalesOrderDetail_CarrierTrackingNumber
ON Sales.SalesOrderDetail (CarrierTrackingNumber);
END
GO
IF OBJECT_ID('Sales.SalesOrderDetail_ASCII') IS NOT NULL
BEGIN
DROP TABLE Sales.SalesOrderDetail_ASCII;
END
GO
CREATE TABLE Sales.SalesOrderDetail_ASCII
(
SalesOrderID int NOT NULL,
SalesOrderDetailID int NOT NULL IDENTITY (1, 1),
CarrierTrackingNumber varchar(25) NULL,
OrderQty smallint NOT NULL,
ProductID int NOT NULL,
SpecialOfferID int NOT NULL,
UnitPrice money NOT NULL,
UnitPriceDiscount money NOT NULL,
LineTotal AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))),
rowguid uniqueidentifier NOT NULL ROWGUIDCOL,
ModifiedDate datetime NOT NULL
);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII ON;
GO
INSERT INTO Sales.SalesOrderDetail_ASCII
(
SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
)
SELECT
SalesOrderID, SalesOrderDetailID, CONVERT(varchar(25), CarrierTrackingNumber),
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
FROM Sales.SalesOrderDetail WITH (HOLDLOCK TABLOCKX);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII OFF;
GO
ALTER TABLE Sales.SalesOrderDetail_ASCII ADD CONSTRAINT
PK_SalesOrderDetail_ASCII_SalesOrderID_SalesOrderDetailID
PRIMARY KEY CLUSTERED (SalesOrderID, SalesOrderDetailID);
CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderDetail_ASCII_rowguid
ON Sales.SalesOrderDetail_ASCII (rowguid);
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ASCII_ProductID
ON Sales.SalesOrderDetail_ASCII (ProductID);
CREATE INDEX IX_SalesOrderDetail_ASCII_CarrierTrackingNumber
ON Sales.SalesOrderDetail_ASCII (CarrierTrackingNumber);
GO Den nye SalesOrderDetail_ASCII-tabel har 121.317 rækker og er 17,5 MB i størrelse og vil blive brugt til at evaluere overhead for en lille tabel. Jeg oprettede også en tabel, der er ti gange større, ved at bruge en modificeret version af scriptet Enlarging the AdventureWorks Sample Databases fra min blog, som indeholder 1.334.487 rækker og er 190 MB i størrelse. Testserveren til dette er den samme 4 vCPU VM med 4 GB RAM, der kører Windows Server 2008 R2 og SQL Server 2012, med Service Pack 1 og Cumulative Update 3, som jeg har brugt i tidligere artikler, så tabellerne vil passe helt i hukommelsen , hvilket eliminerer disk I/O-overhead fra at påvirke de test, der køres.
Testens arbejdsbyrde blev genereret ved hjælp af en række PowerShell-scripts, som vælger listen over CarrierTrackingNumbers fra SalesOrderDetail-tabellen ved at bygge en ArrayList og derefter tilfældigt vælge et CarrierTrackingNumber fra ArrayList for at forespørge SalesOrderDetail_ASCII-tabellen ved hjælp af en varchar-parameter og derefter en nvarchar-parameter, og derefter forespørge SalesOrderDetail-tabellen ved hjælp af en nvarchar-parameter for at give en sammenligning for, hvor kolonnen og parameteren begge er nvarchar. Hver af de individuelle test kører erklæringen 10.000 gange for at tillade måling af ydeevne overhead over en vedvarende arbejdsbyrde.
#No Implicit Conversions
$loop = 10000;
Write-Host "Small table no conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::VarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table no conversion end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table implicit conversions
$loop = 10000;
Write-Host "Small table implicit conversions start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table implicit conversions end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table unicode no implicit conversions
$loop = 10000;
Write-Host "Small table unicode no implicit conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail "
"WHERE CarrierTrackingNumber = @CTNumber;"
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table unicode no implicit conversion end time:"
[DateTime]::Now Et andet sæt test blev kørt mod tabellerne SalesOrderDetailEnlarged_ASCII og SalesOrderDetailEnlarged ved at bruge den samme parameterisering som det første sæt test for at vise overhead-forskellen, når størrelsen af de data, der er lagret i tabellen, stiger over tid. Et sidste sæt test blev også kørt mod SalesOrderDetail-tabellen ved at bruge kolonnen ProductID som en filterkolonne med parametertyperne int, bigint og derefter smallint for at give en sammenligning af overheaden af implicitte konverteringer, der ikke resulterer i en indeksscanning til sammenligning.
Bemærk:Alle scripts er knyttet til denne artikel for at tillade reproduktion af de implicitte konverteringstests til yderligere evaluering og sammenligning.
Testresultater
Under hver af testkørslerne blev Performance Monitor konfigureret til at køre et dataindsamlersæt, der inkluderede Processor\% Processor Time og SQL Server:SQLStatisitics\Batch Requests/sek tællere for at spore ydeevneoverhead for hver af testene. Derudover er Extended Events blevet konfigureret til at spore hændelsen rpc_completed for at tillade sporing af den gennemsnitlige varighed, cpu_time og logiske læsninger for hver af testene.
Lille tabel CarrierTrackingNumber-resultater
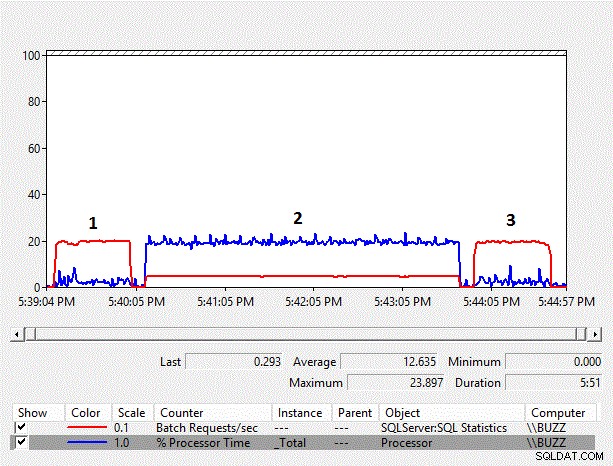
Figur 1 – Præstationsmonitordiagram over tællere
| TestID | Kolonnedatatype | Parameterdatatype | Gns. % processortid | Gns. batchanmodninger/sek. | Varighed h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 2.5 | 192.3 | 0:00:51 |
| 2 | Varchar | Nvarchar | 19.4 | 46.7 | 0:03:33 |
| 3 | Nvarchar | Nvarchar | 2.6 | 192.3 | 0:00:51 |
Tabel 2 – Gennemsnit af data for præstationsmonitor
Fra resultaterne kan vi se, at den implicitte konvertering på kolonnesiden fra varchar til nvarchar og den resulterende indeksscanning har en væsentlig indflydelse på arbejdsbyrdens ydeevne. Den gennemsnitlige %-processortid for den implicitte konverteringstest på kolonnesiden (TestID =2) er næsten ti gange så lang som de andre tests, hvor den implicitte konvertering på kolonnesiden, hvilket resulterede i en indeksscanning, ikke fandt sted. Derudover var de gennemsnitlige batchanmodninger/sek. for den implicitte konverteringstest på kolonnesiden lige under 25 % af de andre tests. Varigheden af testene, hvor implicitte konverteringer ikke fandt sted, tog begge 51 sekunder, selvom dataene blev gemt som nvarchar i test nummer 3 ved brug af en nvarchar-datatype, der krævede dobbelt så meget lagerplads. Dette forventes, fordi tabellen stadig er mindre end bufferpuljen.
| TestID | Gns. cpu_time (µs) | Gns. varighed (µs) | Gns. logical_reads |
|---|---|---|---|
| 1 | 40.7 | 154.9 | 51.6 |
| 2 | 15.640,8 | 15.760,0 | 385.6 |
| 3 | 45.3 | 169,7 | 52.7 |
Tabel 3 – Gennemsnit af udvidede hændelser
Dataene indsamlet af hændelsen rpc_completed i Extended Events viser, at den gennemsnitlige cpu_tid, varighed og logiske læsninger forbundet med de forespørgsler, der ikke udfører en implicit konvertering på kolonnesiden, er nogenlunde ækvivalente, hvor den implicitte konvertering på kolonnesiden medfører en betydelig CPU overhead, samt en længere gennemsnitlig varighed med væsentligt mere logiske aflæsninger.
Forstørret tabel CarrierTrackingNumber-resultater
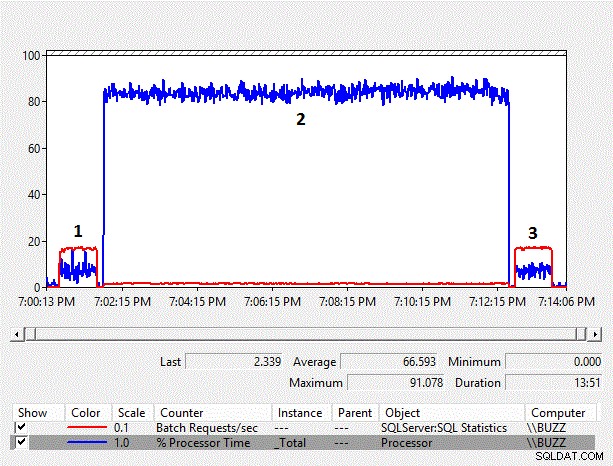
Figur 4 – Præstationsmonitordiagram over tællere
| TestID | Kolonnedatatype | Parameterdatatype | Gns. % processortid | Gns. batchanmodninger/sek. | Varighed h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 7.2 | 164.0 | 0:01:00 |
| 2 | Varchar | Nvarchar | 83.8 | 15.4 | 0:10:49 |
| 3 | Nvarchar | Nvarchar | 7.0 | 166.7 | 0:01:00 |
Tabel 5 – Gennemsnit af data for Performance Monitor
Efterhånden som størrelsen af dataene øges, øges ydeevneoverheaden for den implicitte konvertering på kolonnesiden også. Den gennemsnitlige %-processortid for den implicitte konverteringstest på kolonnesiden (TestID =2) er igen næsten ti gange så meget som de andre tests, hvor den implicitte konvertering på kolonnesiden, der resulterede i en indeksscanning, ikke fandt sted. Derudover var de gennemsnitlige batchanmodninger/sek. for den implicitte konverteringstest på kolonnesiden lige under 10 % af de andre tests. Varigheden af testene, hvor implicitte konverteringer ikke fandt sted, tog begge et minut, mens den implicitte konverteringstest på kolonnesiden krævede tæt på elleve minutter at udføre.
| TestID | Gns. cpu_time (µs) | Gns. varighed (µs) | Gns. logical_reads |
|---|---|---|---|
| 1 | 728.5 | 1.036,5 | 569.6 |
| 2 | 214.174,6 | 59.519.1 | 4.358,2 |
| 3 | 821.5 | 1.032,4 | 553.5 |
Tabel 6 – Gennemsnit af udvidede hændelser
Resultaterne for udvidede hændelser begynder virkelig at vise den ydeevne, der er forårsaget af de implicitte konverteringer på kolonnesiden for arbejdsbyrden. Den gennemsnitlige cpu_time pr. udførelse hopper til over 214ms og er over 200 gange cpu_time for de sætninger, der ikke har de implicitte konverteringer på kolonnesiden. Varigheden er også næsten 60 gange så lang som for de udsagn, der ikke har de implicitte konverteringer på kolonnesiden.
Oversigt
Efterhånden som størrelsen af dataene fortsætter med at stige, vil de overhead, der er forbundet med implicitte konverteringer på kolonnesiden, der resulterer i en indeksscanning for arbejdsbyrden, også fortsætte med at vokse, og det vigtige at huske er, at der på et tidspunkt ikke er nogen mængde hardware. vil være i stand til at klare ydelsen overhead. Implicitte konverteringer er let at forhindre, når der findes et godt databaseskemadesign, og udviklere følger gode applikationskodningsteknikker. I situationer, hvor applikationskodningspraksis resulterer i parameterisering, der udnytter nvarchar-parameterisering, er det bedre at matche databaseskemadesignet til forespørgselsparameteriseringen end at bruge varchar-kolonner i databasedesignet og pådrage sig ydeevneoverhead fra den implicitte konvertering på kolonnesiden.
Download demo-scripts:Implicit_Conversion_Tests.zip (5 KB)