En vigtig del af forespørgselsjustering er at forstå de algoritmer, der er tilgængelige for optimeringsværktøjet til at håndtere forskellige forespørgselskonstruktioner, f.eks. filtrering, sammenføjning, gruppering og aggregering, og hvordan de skaleres. Denne viden hjælper dig med at forberede et optimalt fysisk miljø til dine forespørgsler, såsom at oprette de rigtige indekser. Det hjælper dig også med intuitivt at fornemme, hvilken algoritme du skal forvente at se i planen under et bestemt sæt omstændigheder, baseret på din fortrolighed med de tærskler, hvor optimizeren skal skifte fra en algoritme til en anden. Når du derefter tuner dårligt ydende forespørgsler, kan du nemmere få øje på områder i forespørgselsplanen, hvor optimeringsværktøjet kan have truffet suboptimale valg, for eksempel på grund af unøjagtige kardinalitetsestimater, og tage skridt til at rette dem.
En anden vigtig del af forespørgselstuning er at tænke ud af boksen - ud over de algoritmer, der er tilgængelige for optimeringsværktøjet, når de bruger de åbenlyse værktøjer. Vær kreativ. Lad os sige, at du har en forespørgsel, der klarer sig dårligt, selvom du har indrettet de optimale fysiske rammer. For de forespørgselskonstruktioner, du brugte, er de tilgængelige algoritmer for optimeringsværktøjet x, y og z, og optimeringsværktøjet valgte det bedste, det kunne under omstændighederne. Alligevel klarer forespørgslen sig dårligt. Kan du forestille dig en teoretisk plan med en algoritme, der kan give en meget bedre forespørgsel? Hvis du kan forestille dig det, er chancerne for, at du vil være i stand til at opnå det med en omskrivning af forespørgsler, måske med mindre indlysende forespørgselskonstruktioner til opgaven.
I denne serie af artikler fokuserer jeg på gruppering og aggregering af data. Jeg starter med at gennemgå de algoritmer, der er tilgængelige for optimeringsværktøjet, når du bruger grupperede forespørgsler. Jeg vil derefter beskrive scenarier, hvor ingen af de eksisterende algoritmer klarer sig godt, og viser forespørgselsomskrivninger, der resulterer i fremragende ydeevne og skalering.
Jeg vil gerne takke Craig Freedman, Vassilis Papadimos og Joe Sack, medlemmer af skæringspunktet mellem sættet af klogeste mennesker på planeten og sættet af SQL Server-udviklere, for at svare på mine spørgsmål om forespørgselsoptimering!
Til eksempeldata vil jeg bruge en database kaldet PerformanceV3. Du kan downloade et script til at oprette og udfylde databasen herfra. Jeg bruger en tabel kaldet dbo.Orders, som er udfyldt med 1.000.000 rækker. Denne tabel har et par indekser, som ikke er nødvendige og kan forstyrre mine eksempler, så kør følgende kode for at slette disse unødvendige indekser:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
De eneste to indekser tilbage i denne tabel er et klynget indeks kaldet idx_cl_od på ordredato-kolonnen og et ikke-klynget unikt indeks kaldet PK_Orders på ordre-id-kolonnen, der håndhæver den primære nøglebegrænsning.
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid
Eksisterende algoritmer
SQL Server understøtter to hovedalgoritmer til aggregering af data:Stream Aggregate og Hash Aggregate. Med grupperede forespørgsler kræver Stream Aggregate-algoritmen, at dataene sorteres efter de grupperede kolonner, så du skal skelne mellem to tilfælde. Den ene er et forudbestilt Stream Aggregate, f.eks. når data opnås forudbestilt fra et indeks. En anden er et ikke-forudbestilt Stream Aggregate, hvor der kræves et ekstra trin for eksplicit at sortere inputtet. Disse to tilfælde skaleres meget forskelligt, så du kan lige så godt betragte dem som to forskellige algoritmer.
Hash Aggregate-algoritmen organiserer grupperne og deres aggregater i en hash-tabel. Det kræver ikke, at inputtet er bestilt.
Med nok data overvejer optimeringsværktøjet at parallelisere arbejdet ved at anvende det, der er kendt som et lokalt-globalt aggregat. I et sådant tilfælde opdeles inputtet i flere tråde, og hver tråd anvender en af de førnævnte algoritmer til lokalt at aggregere sin delmængde af rækker. Et globalt aggregat bruger derefter en af de førnævnte algoritmer til at aggregere resultaterne af de lokale aggregater.
I denne artikel fokuserer jeg på den forudbestilte Stream Aggregate-algoritme og dens skalering. I fremtidige dele af denne serie vil jeg dække andre algoritmer og beskrive de tærskler, hvor optimizeren skifter fra den ene til den anden, og hvornår du bør overveje forespørgselsomskrivninger.
Forudbestilt Stream Aggregate
Givet en grupperet forespørgsel med et ikke-tomt grupperingssæt (det sæt af udtryk, som du grupperer efter), kræver Stream Aggregate-algoritmen, at inputrækkerne er ordnet efter de udtryk, der danner grupperingssættet. Når algoritmen behandler den første række i en gruppe, initialiserer den et medlem, der har den mellemliggende aggregerede værdi med den relevante værdi (f.eks. første rækkes værdi for et MAX-aggregat). Når den behandler en ikke-første række i gruppen, tildeler den dette medlem resultatet af en beregning, der involverer den mellemliggende aggregerede værdi og den nye rækkes værdi (f.eks. maksimum mellem den mellemliggende aggregerede værdi og den nye værdi). Så snart et af grupperingssættets medlemmer ændrer sin værdi, eller inputtet er forbrugt, anses den aktuelle samlede værdi for at være det endelige resultat for den sidste gruppe.
En måde at få dataene ordnet, som Stream Aggregate-algoritmen har brug for, er at få dem forudbestilt fra et indeks. Du skal have indekset defineret med grupperingssættets kolonner som nøgler - i en hvilken som helst rækkefølge blandt dem. Du ønsker også, at indekset skal være dækkende. Overvej f.eks. følgende forespørgsel (vi kalder den forespørgsel 1):
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
Et optimalt rækkelagerindeks til at understøtte denne forespørgsel ville være et defineret med shipperid som den førende nøglekolonne og ordredato enten som en inkluderet kolonne eller som en anden nøglekolonne:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
Med dette indeks på plads får du den estimerede plan vist i figur 1 (ved hjælp af SentryOne Plan Explorer).

Figur 1:Plan for forespørgsel 1
Bemærk, at indeksscanningsoperatøren har en Ordret:Ægte egenskab, der angiver, at den er påkrævet for at levere rækkerne, der er ordnet efter indeksnøglen. Stream Aggregate-operatøren indtager derefter rækkerne, som den har brug for. Med hensyn til hvordan operatørens omkostninger beregnes; før vi kommer til det, et hurtigt forord først...
Som du måske allerede ved, når SQL Server optimerer en forespørgsel, evaluerer den flere kandidatplaner og vælger til sidst den med den laveste estimerede pris. Den estimerede planomkostning er summen af alle operatørernes estimerede omkostninger. Til gengæld er hver operatørs estimerede omkostninger summen af de estimerede I/O-omkostninger og estimerede CPU-omkostninger. Omkostningsenheden er meningsløs i sig selv. Dens relevans er i den sammenligning, som optimizeren foretager mellem kandidatplaner. Det vil sige, at omkostningsformlerne blev designet med det mål, at mellem kandidatplaner vil den med de laveste omkostninger (forhåbentlig) repræsentere den, der vil afslutte hurtigere. En frygtelig kompleks opgave at udføre præcist!
Jo mere omkostningsformlerne tager tilstrækkeligt hensyn til de faktorer, der virkelig påvirker algoritmens ydeevne og skalering, jo mere nøjagtige er de, og jo mere sandsynligt er det, at givet nøjagtige kardinalitetsestimater, vil optimeringsværktøjet vælge den optimale plan. I hvert fald, hvis du vil forstå, hvorfor optimeringsværktøjet vælger én algoritme frem for en anden, skal du forstå to hovedting:Den ene er, hvordan algoritmerne fungerer og skalerer, og en anden er SQL Servers omkostningsmodel.
Så tilbage til planen i figur 1; lad os prøve at forstå, hvordan omkostningerne beregnes. Som en politik vil Microsoft ikke afsløre de interne omkostningsformler, som de bruger. Da jeg var barn, var jeg fascineret af at skille ting ad. Ure, radioer, kassettebånd (ja, jeg er så gammel), you name it. Jeg ville gerne vide, hvordan tingene blev lavet. På samme måde ser jeg værdi i omvendt konstruktion af formlerne, da hvis jeg formår at forudsige omkostningerne nogenlunde præcist, betyder det sandsynligvis, at jeg forstår algoritmen godt. I løbet af processen kommer du til at lære en masse.
Vores forespørgsel optager 1.000.000 rækker. Selv med dette antal rækker ser I/O-omkostningerne ud til at være ubetydelige sammenlignet med CPU-omkostningerne, så det er sikkert sikkert at ignorere det.
Hvad angår CPU-omkostningerne, vil du prøve at finde ud af, hvilke faktorer der påvirker det og på hvilken måde. Teoretisk set kan der være en række faktorer:antal inputrækker, antal grupper, kardinalitet af grupperingssættet, datatype og størrelsen af grupperingssættets medlemmer. Så for at prøve at måle effekten af nogen af disse faktorer, vil du sammenligne estimerede omkostninger for to forespørgsler, der kun adskiller sig i den faktor, du ønsker at måle. For at måle virkningen af antallet af rækker på omkostningerne skal du for eksempel have to forespørgsler med et forskelligt antal inputrækker, men med alle andre aspekter ens (antal grupper, kardinalitet af grupperingssæt osv.). Det er også vigtigt at verificere, at de estimerede tal - ikke de faktiske - er de ønskede, da optimeringsværktøjet er afhængigt af de estimerede tal til at beregne omkostningerne.
Når du laver sådanne sammenligninger, er det godt at have teknikker, der giver dig mulighed for fuldt ud at kontrollere de estimerede tal. For eksempel er en enkel måde at kontrollere det estimerede antal inputrækker på at forespørge på et tabeludtryk, der er baseret på en TOP-forespørgsel, og anvende den samlede funktion i den ydre forespørgsel. Hvis du er bekymret for, at optimeringsværktøjet på grund af din brug af TOP-operatøren vil anvende rækkemål, og at disse vil resultere i justering af de oprindelige omkostninger, gælder dette kun for operatører, der vises i planen under Top-operatøren (til højre), ikke over (til venstre). Streamaggregatoperatoren vises naturligt over topoperatoren i planen, da den optager de filtrerede rækker.
Hvad angår styring af det estimerede antal outputgrupper, kan du gøre det ved at bruge grupperingsudtrykket
For at sikre, at du får Stream Aggregate-algoritmen og en seriel plan, kan du gennemtvinge dette med forespørgselstipene:OPTION(ORDER GROUP, MAXDOP 1).
Du vil også finde ud af, om der er nogen opstartsomkostninger for operatøren, så du kan tage højde for det i din omvendte manipulerede formel.
Lad os starte med at finde ud af, hvordan antallet af inputrækker påvirker operatørens estimerede CPU-omkostninger. Det er klart, at denne faktor bør være relevant for operatørens omkostninger. Du forventer også, at prisen pr. række er konstant. Her er et par forespørgsler til sammenligning, der kun adskiller sig i det estimerede antal inputrækker (kald dem henholdsvis forespørgsel 2 og forespørgsel 3):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Figur 2 har de relevante dele af de estimerede planer for disse forespørgsler:

Figur 2:Planer for forespørgsel 2 og forespørgsel 3
Forudsat at prisen pr. række er konstant, kan du beregne den som forskellen mellem operatøromkostningerne divideret med forskellen mellem operatørens inputkardinaliteter:
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
For at kontrollere, at det tal, du fik, faktisk er konstant og korrekt, kan du prøve at forudsige de estimerede omkostninger i forespørgsler med et andet antal inputrækker. For eksempel er den forventede pris med 500.000 inputrækker:
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
Brug følgende forespørgsel til at kontrollere, om din forudsigelse er korrekt (kald den forespørgsel 4):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Den relevante del af planen for denne forespørgsel er vist i figur 3.
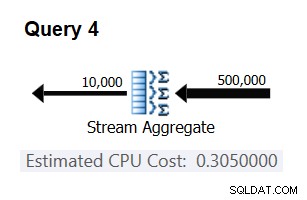
Figur 3:Plan for forespørgsel 4
Bingo. Det er naturligvis en god idé at kontrollere flere ekstra inputkardinaliteter. Med alle dem, jeg tjekkede, var tesen om, at der er en konstant pris pr. inputrække på 0,0000006 korrekt.
Lad os derefter prøve at finde ud af, hvordan det anslåede antal grupper påvirker operatørens CPU-omkostninger. Du ville forvente, at der kræves noget CPU-arbejde for at behandle hver gruppe, og det er også rimeligt at forvente, at det er konstant pr. gruppe. For at teste denne afhandling og beregne prisen pr. gruppe kan du bruge følgende to forespørgsler, som kun adskiller sig i antallet af resultatgrupper (kald dem henholdsvis forespørgsel 5 og forespørgsel 6):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
De relevante dele af de estimerede forespørgselsplaner er vist i figur 4.
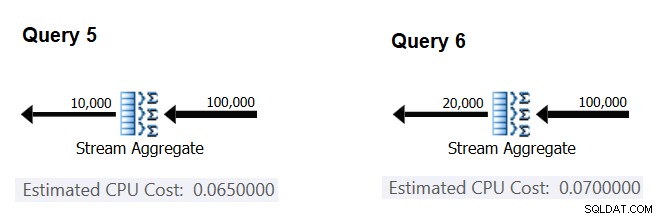
Figur 4:Planer for forespørgsel 5 og forespørgsel 6
På samme måde som du beregnede den faste pris pr. inputrække, kan du beregne den faste pris pr. outputgruppe som forskellen mellem operatøromkostningerne divideret med forskellen mellem operatørens outputkardinaliteter:
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
Og ligesom jeg demonstrerede før, kan du verificere dine resultater ved at forudsige omkostningerne med andre antal outputgrupper og sammenligne dine forudsagte tal med dem, der produceres af optimeringsværktøjet. Med alle de grupper, jeg prøvede, var de forudsagte omkostninger nøjagtige.
Ved at bruge lignende teknikker kan du kontrollere, om andre faktorer påvirker operatørens omkostninger. Min test viser, at grupperingssættets kardinalitet (antal udtryk, som du grupperer efter), datatyperne og størrelserne af de grupperede udtryk ikke har nogen indflydelse på de estimerede omkostninger.
Det, der er tilbage, er at kontrollere, om der er nogen meningsfuld startomkostning for operatøren. Hvis der er en, bør den komplette (forhåbentlig) formel til at beregne operatørens CPU-omkostninger være:
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Så du kan udlede startomkostningerne fra resten:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
Du kan bruge en hvilken som helst forespørgselsplan fra denne artikel til dette formål. For eksempel ved at bruge tallene fra planen for forespørgsel 5 vist tidligere i figur 4, får du:
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
Som det ser ud til, har Stream Aggregate-operatøren ingen CPU-relaterede opstartsomkostninger, eller den er så lav, at den ikke vises med nøjagtigheden af omkostningsmålet.
Som konklusion er den omvendte formel for Stream Aggregate-operatøromkostningerne:
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Figur 5 viser skaleringen af Stream Aggregate-operatørens omkostninger med hensyn til både antallet af rækker og antallet af grupper.
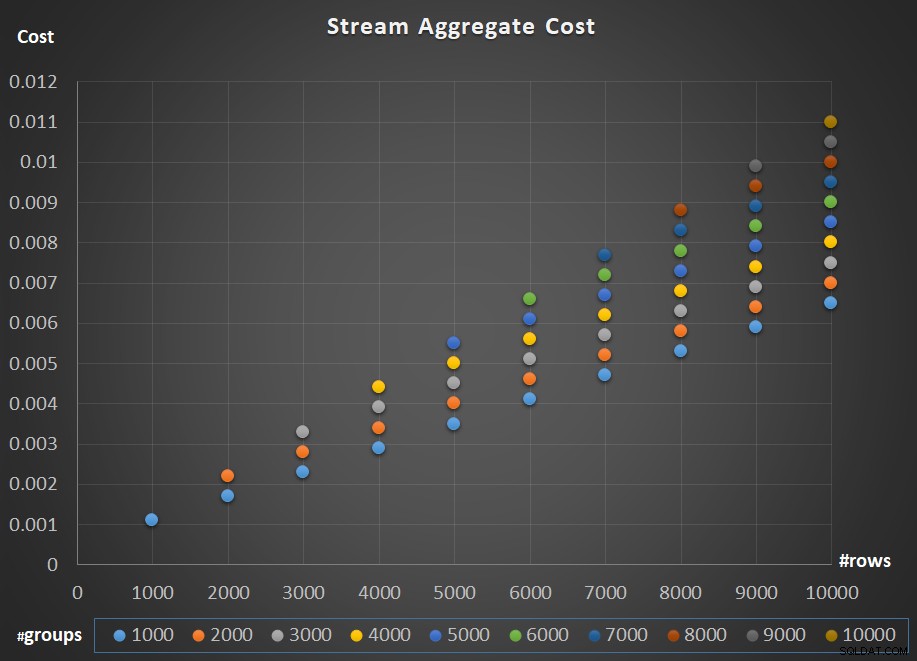
Figur 5:Skaleringsdiagram for Stream Aggregate-algoritme
Hvad angår operatørens skalering; det er lineært. I tilfælde, hvor antallet af grupper har tendens til at være proportionalt med antallet af rækker, stiger hele operatørens omkostninger med den samme faktor, som både antallet af rækker og grupper stiger. Det betyder, at en fordobling af antallet af både inputrækker og inputgrupper resulterer i en fordobling af hele operatørens omkostninger. For at se hvorfor, antag, at vi repræsenterer operatørens omkostninger som:
r * 0.0000006 + g * 0.0000005
Hvis du øger både antallet af rækker og antallet af grupper med samme faktor p, får du:
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
Så hvis prisen for Stream Aggregate-operatøren for et givet antal rækker og grupper er C, vil en forøgelse af både antallet af rækker og grupper med samme faktor p resultere i en operatøromkostning på pC. Se om du kan bekræfte dette ved at identificere eksempler i skemaet i figur 5.
I tilfælde, hvor antallet af grupper forbliver ret stabilt, selv når antallet af inputrækker vokser, får du stadig lineær skalering. Du betragter blot omkostningerne forbundet med antallet af grupper som en konstant. Det vil sige, hvis omkostningerne for operatøren for et givet antal rækker og grupper er C =G (omkostninger forbundet med antal grupper) plus R (omkostninger forbundet med antal rækker), hvilket kun øger antallet af rækker med en faktor på p resulterer i G + pR. I et sådant tilfælde er hele operatørens omkostninger naturligvis mindre end pc. Det vil sige, at en fordobling af antallet af rækker resulterer i mindre end en fordobling af hele operatørens omkostninger.
I praksis, når du grupperer data, er antallet af inputrækker væsentligt større end antallet af outputgrupper. Dette faktum, kombineret med det faktum, at den allokerede pris pr. række og pris pr. gruppe er næsten ens, bliver den del af operatørens omkostninger, der tilskrives antallet af grupper, ubetydelig. Som et eksempel, se planen for forespørgsel 1 vist tidligere i figur 1. I sådanne tilfælde er det sikkert bare at tænke på operatørens omkostninger som blot at skalere lineært med hensyn til antallet af inputrækker.
Særlige tilfælde
Der er særlige tilfælde, hvor Stream Aggregate-operatøren slet ikke har brug for at sortere dataene. Hvis du tænker over det, har Stream Aggregate-algoritmen et mere afslappet bestillingskrav fra input sammenlignet med, når du har brug for dataene bestilt til præsentationsformål, f.eks. når forespørgslen har en ydre præsentation ORDER BY-klausul. Stream Aggregate-algoritmen skal simpelthen have alle rækker fra den samme gruppe for at blive ordnet sammen. Tag inputsættet {5, 1, 5, 2, 1, 2}. Til præsentationsbestillingsformål skal dette sæt ordnes således:1, 1, 2, 2, 5, 5. Til aggregeringsformål ville Stream Aggregate-algoritmen stadig fungere godt, hvis dataene var arrangeret i følgende rækkefølge:5, 5, 1, 1, 2, 2. Med dette i tankerne, når du beregner et skalært aggregat (forespørgsel med en aggregatfunktion og ingen GROUP BY-sætning), eller grupperer dataene efter et tomt grupperingssæt, er der aldrig mere end én gruppe . Uanset rækkefølgen af inputrækkerne kan Stream Aggregate-algoritmen anvendes. Hash Aggregate-algoritmen hasheser dataene baseret på grupperingssættets udtryk som input, og både med skalære aggregater og med et tomt grupperingssæt er der ingen input at hash efter. Så både med skalære aggregater og med aggregater anvendt på et tomt grupperingssæt, bruger optimeringsværktøjet altid Stream Aggregate-algoritmen uden at kræve, at dataene skal forudbestilles. Det er i det mindste tilfældet i rækkeudførelsestilstand, da batchtilstand i øjeblikket (fra SQL Server 2017 CU4) kun er tilgængelig med Hash Aggregate-algoritmen. Jeg vil bruge følgende to forespørgsler til at demonstrere dette (kald dem forespørgsel 7 og forespørgsel 8):
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
Planerne for disse forespørgsler er vist i figur 6.
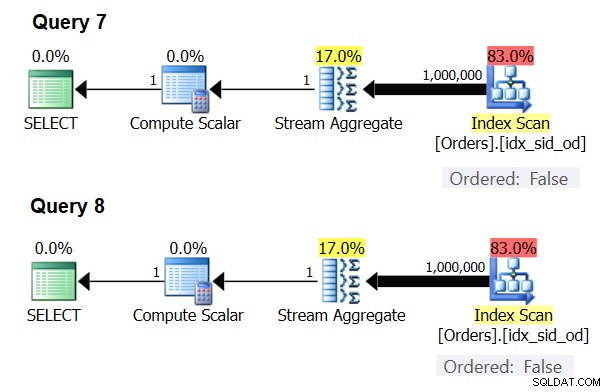
Figur 6:Planer for forespørgsel 7 og forespørgsel 8
Prøv at tvinge en Hash Aggregate-algoritme i begge tilfælde:
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
Optimeringsværktøjet ignorerer din anmodning og producerer de samme planer som vist i figur 6.
Hurtig quiz:hvad er forskellen mellem et skalært aggregat og et aggregat anvendt på et tomt grupperingssæt?
Svar:med et tomt inputsæt returnerer et skalært aggregat et resultat med én række, hvorimod et aggregat i en forespørgsel med et tomt grupperingssæt returnerer et tomt resultatsæt. Prøv det:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
Når du er færdig, skal du køre følgende kode til oprydning:
DROP INDEX idx_sid_od ON dbo.Orders;
Opsummering og udfordring
Omvendt udvikling af omkostningsformlen for Stream Aggregate-algoritmen er en barneleg. Jeg kunne lige have fortalt dig, at omkostningsformlen for en forudbestilt Stream Aggregate-algoritme er @numrows * 0,0000006 + @numgroups * 0,0000005 i stedet for en hel artikel for at forklare, hvordan du finder ud af dette. Pointen var dog at beskrive processen og principperne for reverse-engineering, inden man gik videre til de mere komplekse algoritmer og de tærskler, hvor den ene algoritme bliver mere optimal end de andre. Lærer dig at fiske i stedet for at give dig fisk. Jeg har lært så meget og opdaget ting, jeg ikke engang har tænkt over, mens jeg forsøgte at omdanne omkostningsformler for forskellige algoritmer.
Klar til at teste dine færdigheder? Din mission, hvis du vælger at acceptere den, er en smule sværere end at lave omvendt konstruktion af Stream Aggregate-operatøren. Reverse-engineer omkostningsformlen for en seriel sorteringsoperatør. Dette er vigtigt for vores forskning, da en Stream Aggregate-algoritme anvendt til en forespørgsel med et ikke-tomt grupperingssæt, hvor inputdataene ikke er forudbestilt, kræver eksplicit sortering. I et sådant tilfælde afhænger omkostningerne og skaleringen af den samlede operation af omkostningerne og skaleringen af sorterings- og strømaggregatoperatørerne tilsammen.
Hvis det lykkes dig at komme ordentligt tæt på med at forudsige omkostningerne til sorteringsoperatøren, kan du føle, at du har optjent retten til at tilføje "Reverse Engineer" til din signatur. Der er mange softwareingeniører derude; men du ser bestemt ikke mange reverse engineers! Bare sørg for at teste din formel både med små tal og med store; du kan blive overrasket over, hvad du finder.