SQL Server 2014 bragte mange nye funktioner, som DBA'er og udviklere så frem til at teste og bruge i deres miljøer, såsom det opdaterbare clustered Columnstore-indeks, Delayed Durability og Buffer Pool Extensions. En funktion, der ikke ofte diskuteres, er inkrementelle statistikker. Medmindre du bruger partitionering, er dette ikke en funktion, du kan implementere. Men hvis du har opdelte tabeller i din database, kan inkrementelle statistikker have været noget, du ivrigt havde forventet.
Bemærk:Benjamin Nevarez dækkede nogle grundlæggende ting relateret til inkrementel statistik i hans indlæg fra februar 2014, SQL Server 2014 Incremental Statistics. Og selvom ikke meget har ændret sig i, hvordan denne funktion fungerer siden hans indlæg og udgivelsen i april 2014, så det ud til at være et godt tidspunkt at grave ind i, hvordan aktivering af inkrementelle statistikker kan hjælpe med vedligeholdelsesydelsen.
Inkrementelle statistikker kaldes nogle gange statistikker på partitionsniveau, og det skyldes, at SQL Server for første gang automatisk kan oprette statistikker, der er specifikke for en partition. En af de tidligere udfordringer med partitionering var, at selvom du kunne have 1 til n partitioner for en tabel, var der kun én (1) statistik, som repræsenterede datafordelingen på tværs af alle disse partitioner. Du kan oprette filtreret statistik for den opdelte tabel – én statistik for hver partition – for at give forespørgselsoptimeringsværktøjet bedre information om distributionen af data. Men dette var en manuel proces og krævede et script for automatisk at oprette dem for hver ny partition.
I SQL Server 2014 bruger du STATISTICS_INCREMENTAL mulighed for at få SQL Server til at oprette disse statistikker på partitionsniveau automatisk. Disse statistikker bruges dog ikke, som du måske tror.
Jeg nævnte tidligere, at du før 2014 kunne oprette filtreret statistik for at give optimeringsværktøjet bedre information om partitionerne. Disse inkrementelle statistikker? De bruges i øjeblikket ikke af optimeringsværktøjet. Forespørgselsoptimeringsværktøjet bruger stadig bare hovedhistogrammet, der repræsenterer hele tabellen. (Kommer et opslag, som vil demonstrere dette!)
Så hvad er meningen med inkrementel statistik? Hvis du antager, at kun data i den seneste partition ændres, så opdaterer du ideelt set kun statistik for den partition. Du kan gøre dette nu med inkrementelle statistikker - og det, der sker, er, at information derefter flettes tilbage til hovedhistogrammet. Histogrammet for hele tabellen opdateres uden at skulle læse hele tabellen igennem for at opdatere statistik, og dette kan hjælpe med udførelsen af dine vedligeholdelsesopgaver.
Opsætning
Vi starter med at oprette en partitionsfunktion og et skema og derefter en ny tabel, som vi vil partitionere. Bemærk, at jeg har oprettet en filgruppe for hver partitionsfunktion, som du kan i et produktionsmiljø. Du kan oprette partitionsskemaet på den samme filgruppe (f.eks. PRIMARY ), hvis du ikke nemt kan droppe din testdatabase. Hver filgruppe er også et par GB i størrelse, da vi vil tilføje næsten 400 millioner rækker.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Før vi tilføjer dataene, opretter vi det klyngede indeks og bemærker, at syntaksen inkluderer WITH (STATISTICS_INCREMENTAL = ON) mulighed:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Det, der er interessant at bemærke her, er, at hvis du ser på ALTER TABLE indtastning i MSDN, inkluderer den ikke denne mulighed. Du finder det kun i ALTER INDEX indgang... men det virker. Hvis du vil følge dokumentationen til punkt og prikke, skal du køre:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Når det klyngede indeks er blevet oprettet for partitionsskemaet, indlæser vi vores data og kontrollerer derefter, hvor mange rækker der findes pr. partition (bemærk, at dette tager over 7 minutter på min bærbare computer vil du måske tilføje færre rækker afhængigt af hvor meget lagerplads (og tid) du har til rådighed):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
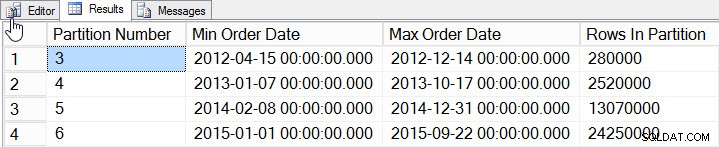 Data pr. partition
Data pr. partition
Vi har tilføjet data for 2012 til 2015, med betydeligt flere data i 2014 og 2015. Lad os se, hvordan vores statistik ser ud:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
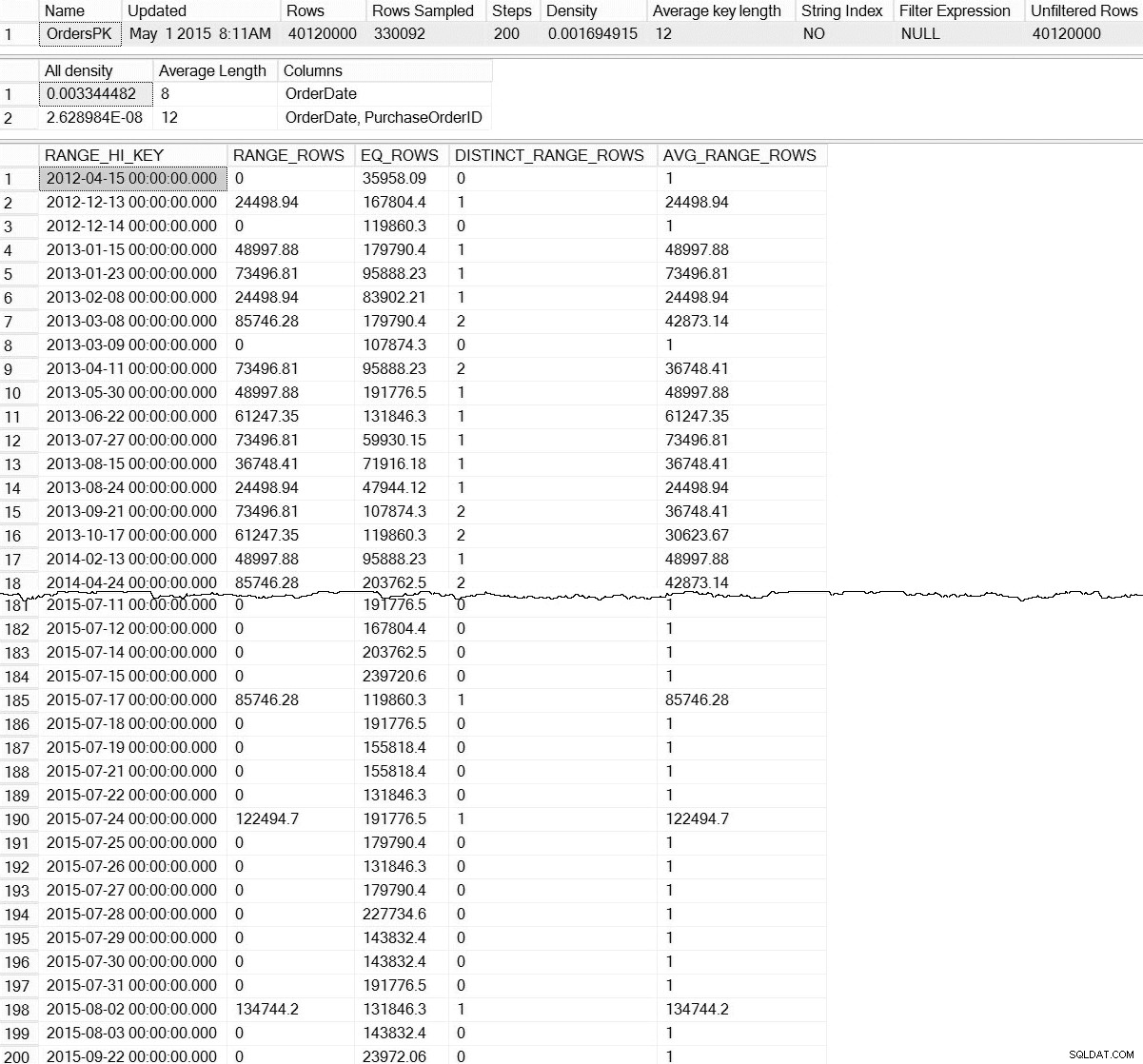 DBCC SHOW_STATISTICS output for dbo.Orders (klik for at forstørre)
DBCC SHOW_STATISTICS output for dbo.Orders (klik for at forstørre)
Med standard DBCC SHOW_STATISTICS kommando, har vi ingen information om statistik på partitionsniveau. Frygt ej; vi er ikke fuldstændig dømt – der er en udokumenteret dynamisk styringsfunktion, sys.dm_db_stats_properties_internal . Husk, at udokumenteret betyder, at den ikke er understøttet (der er ingen MSDN-indgang for DMF), og at den kan ændres til enhver tid uden nogen advarsel fra Microsoft. Når det er sagt, er det en anstændig start for at få en idé om, hvad der eksisterer for vores inkrementelle statistik:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Histogramoplysninger fra dm_db_stats_properties_internal (klik for at forstørre)
Histogramoplysninger fra dm_db_stats_properties_internal (klik for at forstørre)
Det her er meget mere interessant. Her kan vi se bevis på, at der findes statistikker på partitionsniveau (og mere). Fordi denne DMF ikke er dokumenteret, er vi nødt til at fortolke noget. For i dag vil vi fokusere på de første syv rækker i outputtet, hvor den første række repræsenterer histogrammet for hele tabellen (bemærk rows værdi på 40 millioner), og de efterfølgende rækker repræsenterer histogrammerne for hver partition. Desværre er partition_number værdien i dette histogram stemmer ikke overens med partitionsnummeret fra sys.dm_db_index_physical_stats til højre-baseret partitionering (det korrelerer korrekt for venstre-baseret partitionering). Bemærk også, at dette output også inkluderer last_updated og modification_counter kolonner, som er nyttige ved fejlfinding, og det kan bruges til at udvikle vedligeholdelsesscripts, der intelligent opdaterer statistik baseret på alders- eller rækkeændringer.
Minimering af nødvendig vedligeholdelse
Den primære værdi af inkrementel statistik på dette tidspunkt er evnen til at opdatere statistik for en partition og få dem til at flette ind i histogrammet på tabelniveau uden at skulle opdatere statistikken for hele tabellen (og derfor læse hele tabellen igennem). For at se dette i aktion, lad os først opdatere statistikker for den partition, der indeholder 2015-dataene, partition 5, og vi registrerer den tid, det tager og tager et øjebliksbillede af sys.dm_io_virtual_file_stats DMF før og efter for at se, hvor meget I/O der forekommer:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Output:
SQL Server-udførelsestider:CPU-tid =203 ms, forløbet tid =240 ms.
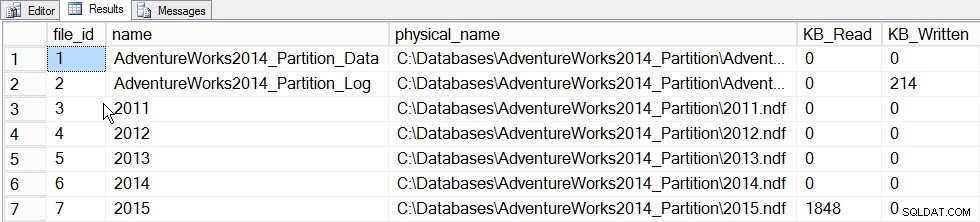 File_stats-data efter opdatering af én partition
File_stats-data efter opdatering af én partition
Hvis vi ser på sys.dm_db_stats_properties_internal output, ser vi at last_updated ændret for både 2015-histogrammet og histogrammet på tabelniveau (samt et par andre noder, som er til senere undersøgelse):
 Opdaterede histogramoplysninger fra dm_db_stats_properties_internal
Opdaterede histogramoplysninger fra dm_db_stats_properties_internal
Nu opdaterer vi statistik med en FULLSCAN for tabellen, og vi tager et øjebliksbillede af file_stats før og efter igen:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Output:
SQL Server-udførelsestider:CPU-tid =12720 ms, forløbet tid =13646 ms
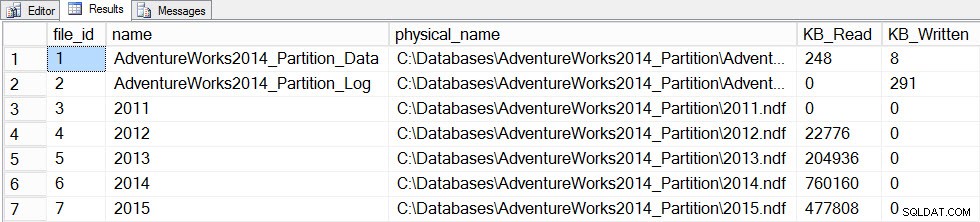 Filestats data efter opdatering med en fuldscanning
Filestats data efter opdatering med en fuldscanning
Opdateringen tog betydeligt længere tid (13 sekunder mod et par hundrede millisekunder) og genererede meget mere I/O. Hvis vi tjekker sys.dm_db_stats_properties_internal igen, vi finder, at last_updated ændret for alle histogrammer:
 Histogramoplysninger fra dm_db_stats_properties_internal efter en fuldscanning
Histogramoplysninger fra dm_db_stats_properties_internal efter en fuldscanning
Oversigt
Selvom inkrementelle statistikker endnu ikke bruges af forespørgselsoptimeringsværktøjet til at give oplysninger om hver partition, giver de en ydeevnefordel, når du administrerer statistik for partitionerede tabeller. Hvis statistik kun skal opdateres for udvalgte partitioner, kan kun disse opdateres. Den nye information flettes derefter ind i histogrammet på tabelniveau, hvilket giver optimeringsværktøjet mere aktuel information uden omkostningerne ved at læse hele tabellen. Fremadrettet håber vi, at disse statistikker på partitionsniveau vil bruges af optimeringsværktøjet. Følg med...