I mit tidligere indlæg talte jeg om måder at generere en sekvens af sammenhængende tal fra 1 til 1.000. Nu vil jeg gerne tale om de næste skalaniveauer:generering af sæt med 50.000 og 1.000.000 numre.
Generering af et sæt på 50.000 numre
Da jeg startede denne serie, var jeg virkelig nysgerrig på, hvordan de forskellige tilgange ville skalere til større sæt tal. I den lave ende var jeg lidt forfærdet over at finde ud af, at min yndlingsmetode – ved hjælp af sys.all_objects – var ikke den mest effektive metode. Men hvordan ville disse forskellige teknikker skaleres til 50.000 rækker?
Taltabellen
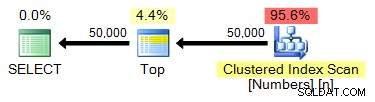
Da vi allerede har oprettet en Numbers-tabel med 1.000.000 rækker, forbliver denne forespørgsel stort set identisk:
VÆLG TOP (50000) n FRA dbo.Numre BESTIL EFTER n;
Plan:
spt_values
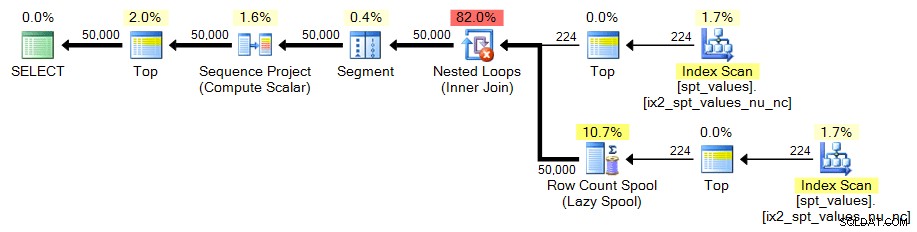
Da der kun er ~2.500 rækker i spt_values , skal vi være lidt mere kreative, hvis vi vil bruge det som kilden til vores sætgenerator. En måde at simulere en større tabel på er at CROSS JOIN det mod sig selv. Hvis vi gjorde det rå, ville vi ende med ~2.500 rækker i kvadrat (over 6 millioner). Behøver vi kun 50.000 rækker, har vi brug for omkring 224 rækker i kvadrat. Så vi kan gøre dette:
;WITH x AS ( SELECT TOP (224) number FROM [master]..spt_values)SELECT TOP (50000) n =ROW_NUMBER() OVER (ORDER BY x.number) FROM x CROSS JOIN x AS yORDER BY n;
Bemærk, at dette svarer til, men mere kortfattet end, denne variation:
SELECT TOP (50000) n =ROW_NUMBER() OVER (ORDER BY x.number) FRA (SELECT TOP (224) nummer FRA [master]..spt_values) AS xCROSS JOIN(SELECT TOP (224) nummer FRA [master] ]..spt_values) SOM yORDER BY n;
I begge tilfælde ser planen således ud:
sys.all_objects
Ligesom spt_values , sys.all_objects opfylder ikke helt vores krav på 50.000 rækker i sig selv, så vi bliver nødt til at udføre en lignende CROSS JOIN .
;;WITH x AS ( SELECT TOP (224) [object_id] FROM sys.all_objects)SELECT TOP (50000) n =ROW_NUMBER() OVER (ORDER BY x.[object_id]) FROM x CROSS JOIN x SOM y ORDRE AF n;
Plan:

Stablede CTE'er
Vi behøver kun at foretage en mindre justering af vores stablede CTE'er for at få præcis 50.000 rækker:
;WITH e1(n) AS( VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1) , -- 10e2(n) AS (VÆLG 1 FRA e1 CROSS JOIN e1 AS b), -- 10*10e3(n) AS (SELECT 1 FROM e2 CROSS JOIN e2 AS b), -- 100*100e4(n) AS (VÆLG 1 FRA e3 CROSS JOIN (VÆLG TOP 5 n FRA e1) AS b) -- 5*10000 SELECT n =ROW_NUMBER() OVER (ORDER BY n) FROM e4 ORDER BY n;
Plan:

Rekursive CTE'er
En endnu mindre væsentlig ændring er påkrævet for at få 50.000 rækker ud af vores rekursive CTE:skift WHERE klausul til 50.000 og ændre MAXRECURSION mulighed til nul.
;MED n(n) AS( VÆLG 1 UNION ALLE VÆLG n+1 FRA n HVOR n <50000)VÆLG n FRA n ORDEN VED nOPTION (MAXRECURSION 0);
Plan:
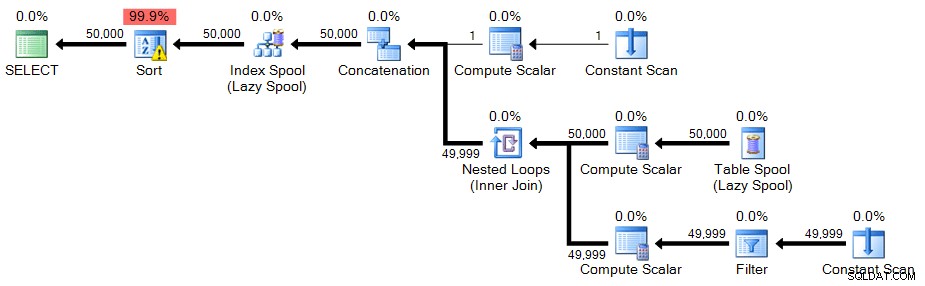
I dette tilfælde er der et advarselsikon på sorten - som det viser sig, på mit system, den slags, der skal til for at spilde til tempdb. Du kan muligvis ikke se et spild på dit system, men dette bør være en advarsel om de ressourcer, der kræves til denne teknik.
Ydeevne
Som med det sidste sæt af tests, vil vi sammenligne hver teknik, inklusive Numbers-tabellen med både en kold og varm cache og både komprimeret og ukomprimeret:
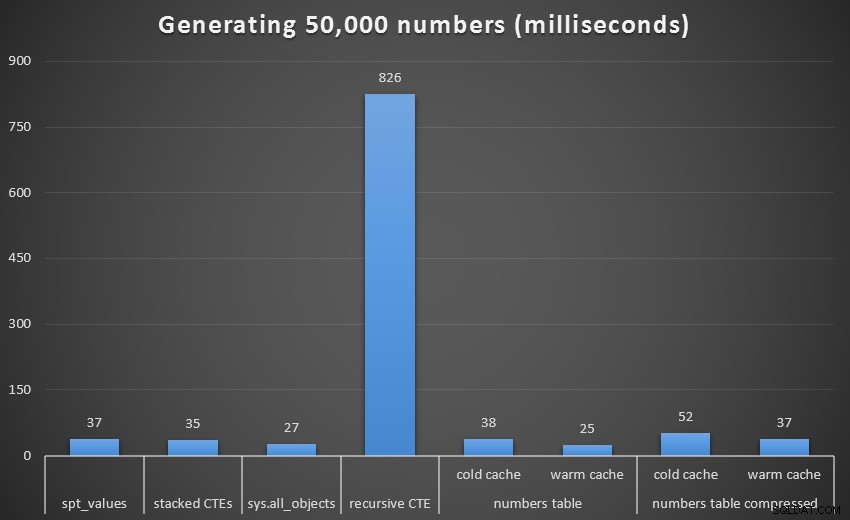
Køretid, i millisekunder, for at generere 50.000 sammenhængende tal
For at få et bedre syn, lad os fjerne den rekursive CTE, som var en total hund i denne test, og som skævvrider resultaterne:
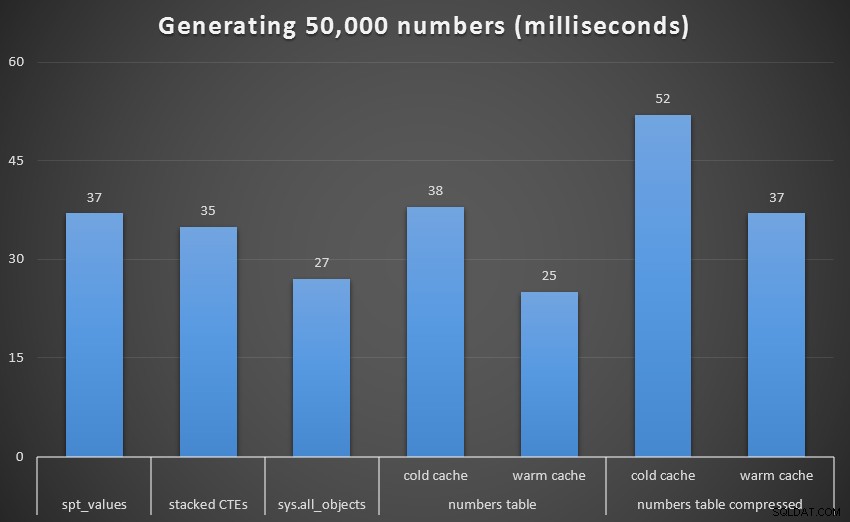
Køretid, i millisekunder, for at generere 50.000 sammenhængende tal (ekskl. CTE)
Ved 1.000 rækker var forskellen mellem komprimeret og ukomprimeret marginal, da forespørgslen kun behøvede at læse henholdsvis 8 og 9 sider. Ved 50.000 rækker udvides afstanden en smule:74 sider vs. 113. De samlede omkostninger ved at dekomprimere dataene ser dog ud til at opveje besparelserne i I/O. Så ved 50.000 rækker ser en ukomprimeret taltabel ud til at være den mest effektive metode til at udlede et sammenhængende sæt - selvom fordelen ganske vist er marginal.
Generering af et sæt på 1.000.000 numre
Selvom jeg ikke kan forestille mig ret mange tilfælde, hvor du har brug for et sammenhængende sæt tal, så stort, ville jeg inkludere det for fuldstændighedens skyld, og fordi jeg lavede nogle interessante observationer i denne skala.
Taltabellen
Ingen overraskelser her, vores forespørgsel er nu:
VÆLG TOP 1000000 n FRA dbo.Numre BESTIL EFTER n;
TOP er ikke strengt nødvendigt, men det er kun fordi vi ved, at vores taltabel og vores ønskede output har det samme antal rækker. Planen er stadig ret lig tidligere tests:
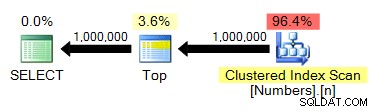
spt_values
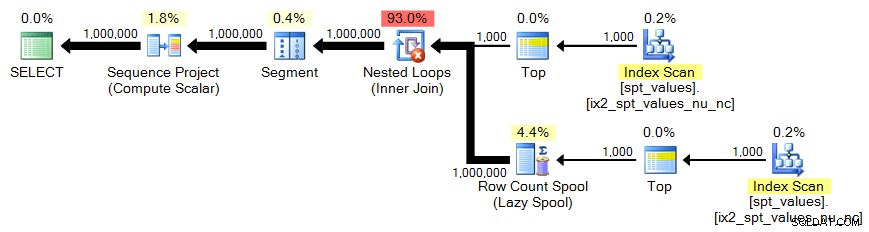
For at få en CROSS JOIN som giver 1.000.000 rækker, skal vi tage 1.000 rækker i kvadrat:
;MED x AS (VÆLG TOP (1000) nummer FRA [master]..spt_values)SELECT n =ROW_NUMBER() OVER (ORDER BY x.number) FROM x CROSS JOIN x AS y ORDER BY n;
Plan:
sys.all_objects
Igen har vi brug for krydsproduktet af 1.000 rækker:
;WITH x AS (SELECT TOP (1000) [object_id] FROM sys.all_objects)SELECT n =ROW_NUMBER() OVER (ORDER BY x.[object_id]) FROM x CROSS JOIN x AS y ORDER BY n;Plan:
Stablede CTE'er
Til den stablede CTE har vi bare brug for en lidt anderledes kombination af
CROSS JOINs for at komme til 1.000.000 rækker:;WITH e1(n) AS( VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1 UNION ALLE VÆLG 1) , -- 10e2(n) AS (VÆLG 1 FRA e1 CROSS JOIN e1 AS b), -- 10*10e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2 AS b), -- 10*100e4(n) AS (VÆLG 1 FRA e3 CROSS JOIN e3 AS b) -- 1000*1000 SELECT n =ROW_NUMBER() OVER (ORDER BY n) FROM e4 ORDER BY n;Plan:
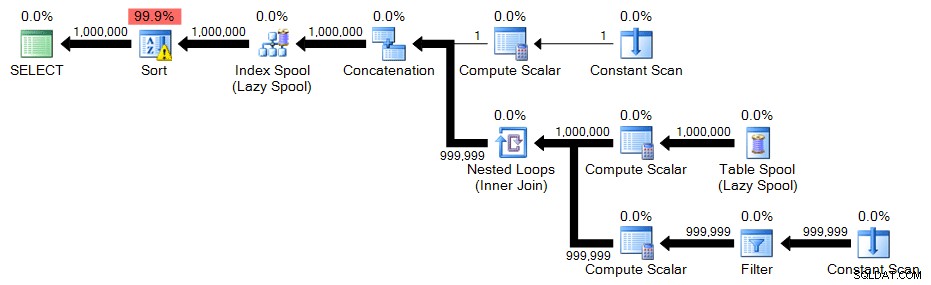
Ved denne rækkestørrelse kan du se, at den stablede CTE-løsning går parallelt. Så jeg kørte også en version med
MAXDOP 1for at få en lignende planform som før, og for at se om parallelisme virkelig hjælper:
Rekursiv CTE
Den rekursive CTE har igen kun en mindre ændring; kun
WHEREklausul skal ændres:;MED n(n) AS( VÆLG 1 UNION ALLE VÆLG n+1 FRA n HVOR n <1000000)VÆLG n FRA n ORDEN EFTER nOPTION (MAXRECURSION 0);Plan:
Ydeevne
Endnu en gang ser vi, at ydeevnen af den rekursive CTE er afgrundsdyb:
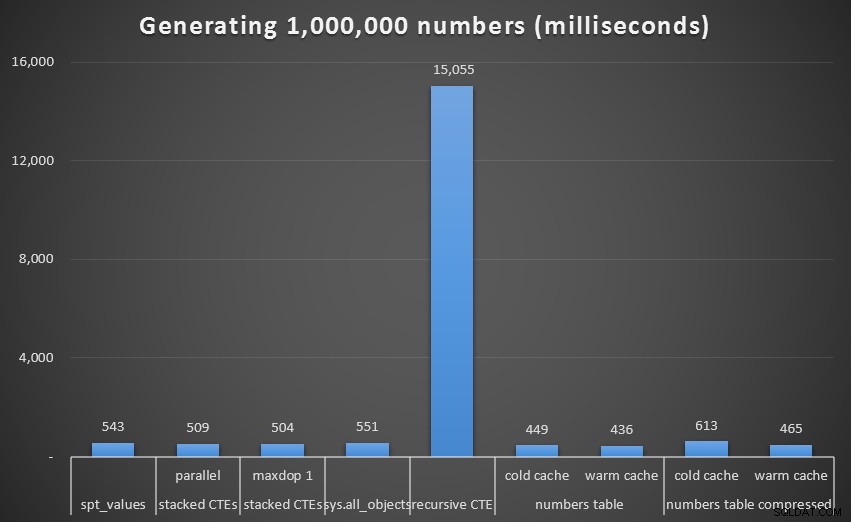
Kørselstid i millisekunder for at generere 1.000.000 sammenhængende talHvis du fjerner denne udligger fra grafen, får vi et bedre billede af ydeevne:
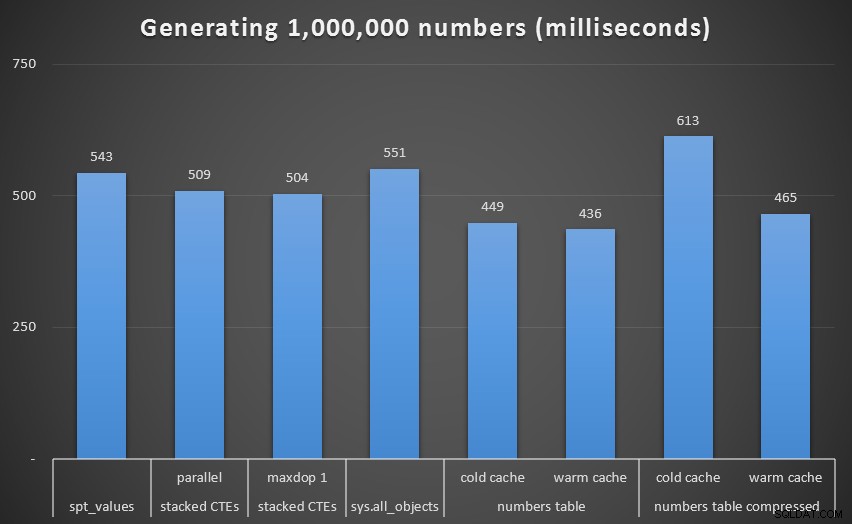
Køretid, i millisekunder, for at generere 1.000.000 sammenhængende recursive tal (ekskl. CTE)Selvom vi igen ser den ukomprimerede Numbers-tabel (i det mindste med en varm cache) som vinderen, er forskellen selv på denne skala ikke så bemærkelsesværdig.
Fortsættes...
Nu hvor vi grundigt har undersøgt en håndfuld tilgange til at generere en sekvens af tal, går vi videre til datoer. I det sidste indlæg i denne serie vil vi gennemgå opbygningen af et datointerval som et sæt, inklusive brugen af en kalendertabel og et par brugssager, hvor dette kan være praktisk.
[ Del 1 | Del 2 | Del 3 ]
Bilag :Rækketællinger
Du forsøger muligvis ikke at generere et nøjagtigt antal rækker; du vil måske i stedet bare have en ligetil måde at generere en masse rækker på. Det følgende er en liste over kombinationer af katalogvisninger, der vil give dig forskellige rækkeantal, hvis du blot
SELECTuden enWHEREklausul. Bemærk, at disse tal vil afhænge af, om du er ved en RTM eller en service pack (da nogle systemobjekter bliver tilføjet eller ændret), og også om du har en tom database.



| Kilde | Rækkeantal | ||
|---|---|---|---|
| SQL Server 2008 R2 | SQL Server 2012 | SQL Server 2014 | |
| master..spt_values | 2.508 | 2.515 | 2.519 |
| master..spt_values CROSS JOIN master..spt_values | 6.290.064 | 6.325.225 | 6.345.361 |
| sys.all_objects | 1.990 | 2.089 | 2.165 |
| sys.all_columns | 5.157 | 7.276 | 8.560 |
| sys.all_objects CROSS JOIN sys.all_objects | 3.960.100 | 4.363.921 | 4.687.225 |
| sys.all_objects CROSS JOIN sys.all_columns | 10.262.430 | 15.199.564 | 18.532.400 |
| sys.all_columns CROSS JOIN sys.all_columns | 26.594.649 | 52.940.176 | 73.273.600 |
Tabel 1:Rækketællinger for forskellige katalogvisningsforespørgsler