I en tidligere tutorial, "Fletter datafiler med Statistica, del 1", introducerede vi brugen af Statistica til at flette regneark. Vi diskuterede sammenkædningsfletningstilstanden. I denne øvelse skal vi diskutere to andre tilstande:Brug af kasusnavne og variabelnavne. Denne øvelse har følgende sektioner:
- Brug af sagsnavne til at flette datafiler
- Brug af variabelnavne til at flette datafiler
- Konklusion
Brug af sagsnavne til at flette datafiler
Dernæst skal vi flette datafiler (regneark) ved at matche rækkerne (også kaldet sager ). Hvis rækkerne har de samme sagsnavne, bliver dataene i rækkerne fra de to datafiler flettet sammen. Eksempeldatafilerne, vi brugte i den foregående artikel, indeholder ikke et sagsnavn. Sagsnavnet er angivet i kolonnen 1, kolonnen før datakolonnerne. Brug de samme data som til sammenkædning af datafiler, tilføj sagsnavnene (log1 til log6 ) til rækker i wlslog1.sta regneark, som vist i figur 1.
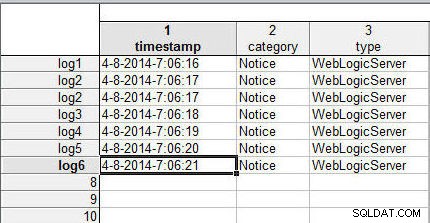
Figur 1: Regneark wlslog1
Tilføj på samme måde navne på store og små bogstaver (log1 til log6 ) til hver række i wlslog2.sta , som vist i figur 2.
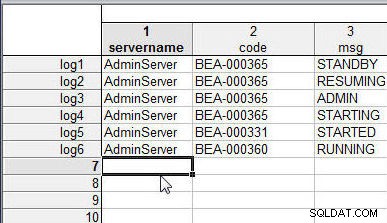
Figur 2: Regneark wlslog2
Vælg Data>Flet og i Fletningsindstillinger , vælg Tilstand som Match casenames , som vist i figur 3. Klik på OK .
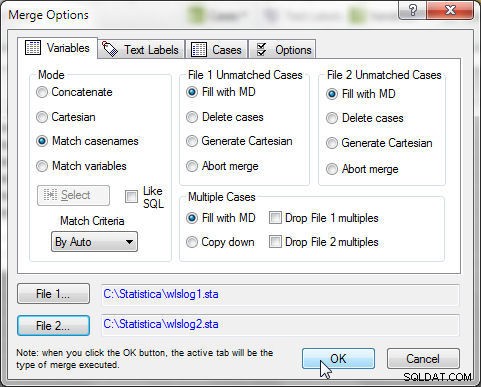
Figur 3: Sammenlægning af wlslog1 og wlslog2
Dataene i wlslog1.sta regnearket bliver flettet sammen med dataene i wlslog2.sta regneark, som vist i det resulterende regneark i figur 4.
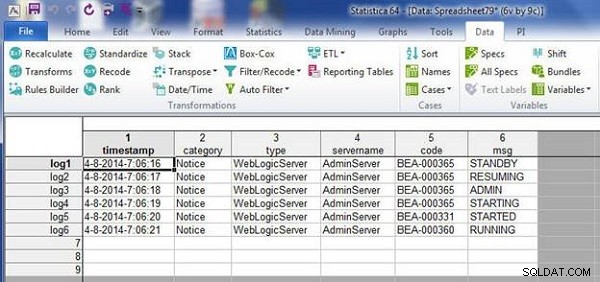
Figur 4: Sammenlagt fil
Ved fletning ved at matche sagsnavne skal hver af de datafiler, der skal flettes, indeholde sagsnavne, ellers vises fejlen vist i figur 5.
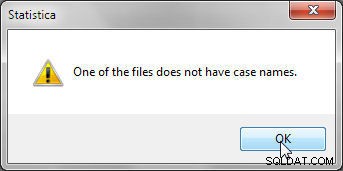
Figur 5: Sagsnavne er påkrævet ved fletning ved at matche sagsnavne
Et regneark kan have flere tilfælde (eller rækker) end det andet. Som et eksempel kan du tilføje en 7 række til wlslog1.sta (se figur 6). Klik på Flet for at flette regnearkene.
Figur 6: Flet sammen med en 7. række i wlslog1.sta
Flet ved at matche sagsnavne med wlslog2.sta , hvilket er det samme som før med 6 sager (rækker), som vist i figur 28. Regnearkene, der skal flettes, har umatchede sager (det ene regneark har flere sager end det andet). Umatchede sager slås sammen ved at udfylde manglende data som standard, hvilket betyder, at dataværdierne er tomme. Det resulterende regneark har tomme manglende data for umatchede tilfælde, som vist i figur 7.
Figur 7: Det resulterende regneark har tomme manglende data
Fletningsindstillinger giver nogle muligheder for Umatchede tilfælde andet end at udfylde med manglende data. For at demonstrere, brug et regneark, wlslog1.sta , med en ekstra række og også et dublet navn på store bogstaver (log2 ), som vist i figur 8.
Figur 8: Regneark med dublet sagsnavn
De umatchede sager kan slettes ved at vælge Slet sager i Fil 1 umatchede sager , som vist i figur 9. Flere tilfælde rettes ved at vælge "Drop File 1 multipler". Med Flettilstand som Match casenames , klik på OK .
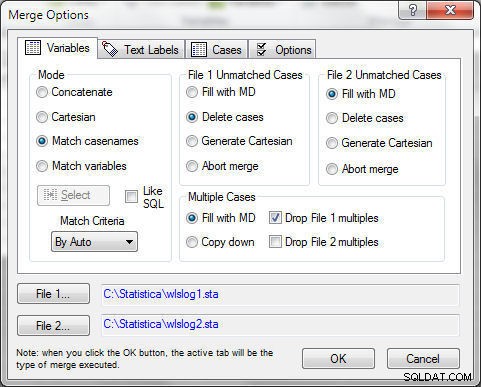
Figur 9: Fil 1 Umatchede sager>Slet sager
Det resulterende regneark har begge problemer løst. Den umatchede sag slettes, og den dublet-case slettes, som vist i figur 10.
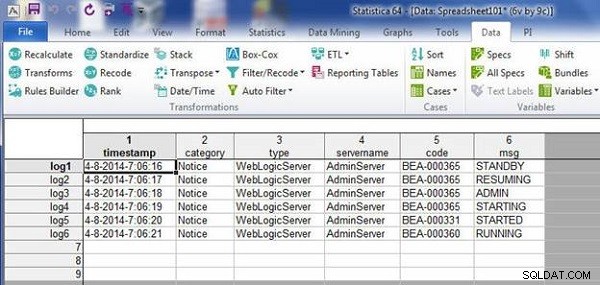
Figur 10: Resulterende regneark med uovertruffen store og små bogstaver slettet og dublet store bogstaver slettet
Brug af variabelnavne til at flette datafiler
Dernæst skal vi flette regneark ved at matche variabelnavne. Start med to regneark, wlslog1.sta og wlslog2.sta , hver med kolonnenavnene vist i figur 11.
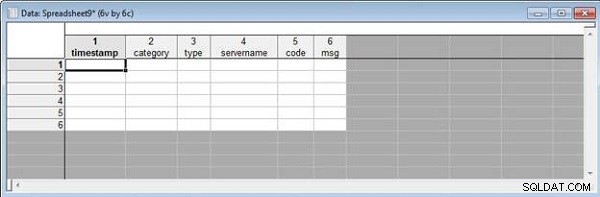
Figur 11: Kolonnenavne i wlslog1 og wlslog2
Tilføj følgende data til wlslog1.sta .
4-8-2014-7:06:16,Notice,WebLogicServer,AdminServer,BEA-000365, STANDBY 4-8-2014-7:06:17,Notice,WebLogicServer,AdminServer,BEA-000365, RESUMING 4-8-2014-7:06:18,Notice,WebLogicServer,AdminServer,BEA-000365, ADMIN
wlslog1.sta regneark er vist i figur 12.
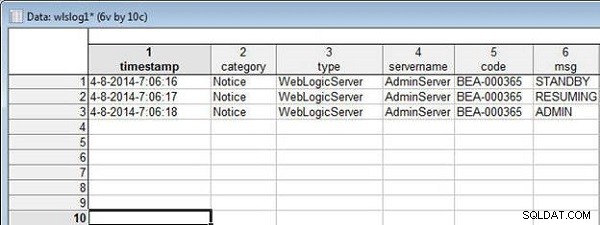
Figur 12: Regneark wlslog1.sta
Tilføj følgende data til wlslog2.sta .
4-8-2014-7:06:20,Notice,WebLogicServer,AdminServer,BEA-000331, STARTING 4-8-2014-7:06:21,Notice,WebLogicServer,AdminServer,BEA-000365, STARTED 4-8-2014-7:06:22,Notice,WebLogicServer,AdminServer,BEA-000360, RUNNING
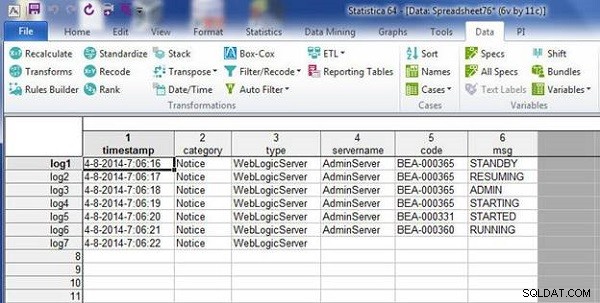
wlslog2.sta er vist i figur 13. Vælg Data>Flet som før.
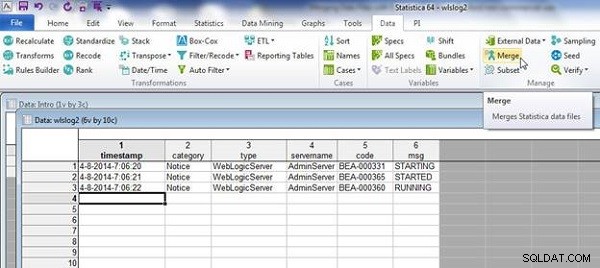
Figur 13: Regneark wlslog2.sta
I Fletningsindstillinger , vælg Tilstand som Matchvariabler , som vist i figur 14. Vælg Fil 1 som wlslog1.sta og Fil 2 som wlslog2.sta . Rækkefølgen er vigtig, fordi regnearket, der skal føjes til bunden af det andet, skal være Fil 2 . Behold Matchkriterierne som Automatisk , som automatisk vælger de mest passende flettekriterier. De andre muligheder for Matchkriterier er Med tekst , som sammenligner data ved at sammenligne tekst; og efter numerisk , som sammenligner data ved at sammenligne de numeriske værdier. Klik derefter på Vælg for at vælge de variabler, der skal matche.
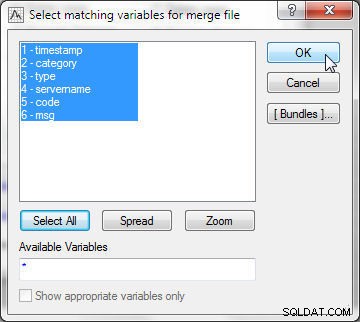
Figur 14: Merge Mode som Match Variables
Vælg først matchende variabler for den aktuelle fil (fil 1). Klik på Vælg alle og klik på OK, som vist i figur 15.
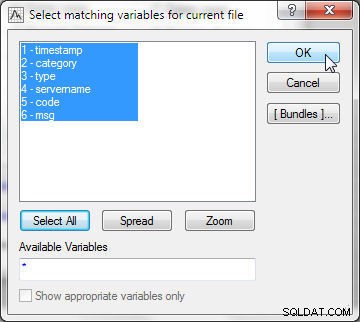
Figur 15: Valg af variabler i den aktuelle fil
På samme måde skal du vælge alle variabler til flettefil (fil 2) og klikke på OK (se figur 16).
Figur 16: Valg af variabler i flettefil
Klik på OK i Merge Options, som vist i figur 17.
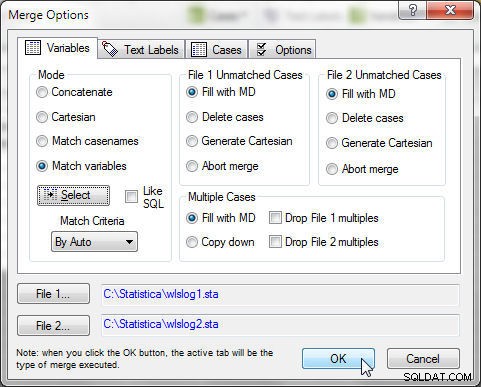
Figur 17: Sammenfletning med tilstand som matchvariable
De to regneark bliver flettet sammen ved at matche variabelnavne, som vist i figur 18.
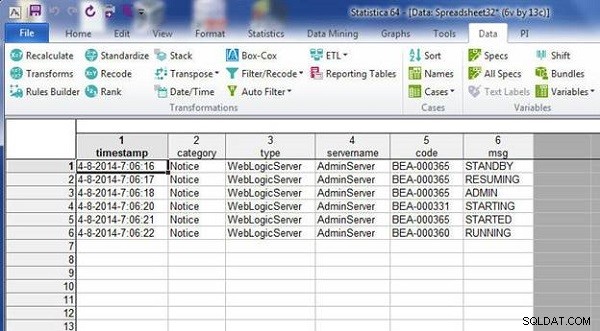
Figur 18: Resulterende regneark fra fletning ved at matche variabelnavne
Når regneark flettes ved at matche variabelnavne, sorteres dataværdierne numerisk og tekstuelt. Som et eksempel kan du flette to regneark med regnearket 1, vist i figur 19.
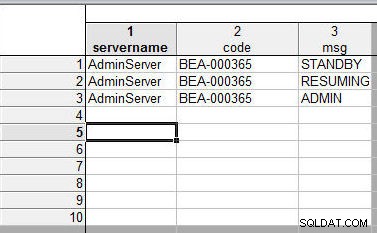
Figur 19: Første regneark, der skal flettes
Det 2. regneark er vist i figur 20. En tilføjet modifikation er, at variabelnavnet er blevet ændret en smule i fil 1:"ServerType" i stedet for "servernavn", "MessageCode" i stedet for "code", og "Message" i stedet for " besked”.
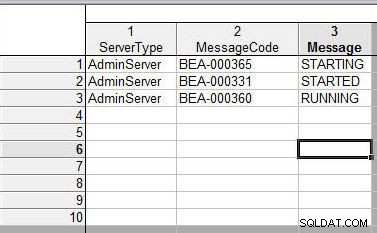
Figur 20: Andet regneark, der skal flettes
Klik på Vælg for at vælge de variabler, der skal bruges til matchning. I fil 1 skal du vælge alle variablerne (se figur 21).
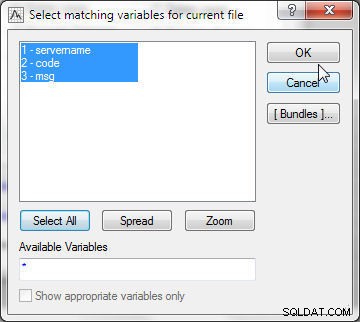
Figur 21: Valg af matchende variabler for den aktuelle fil
I fil 2 skal du også vælge alle variablerne, som vist i figur 22.
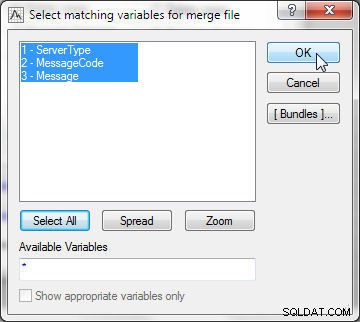
Figur 22: Valg af matchende variabler til fletningsfil
Flet de to regneark sammen som før. "Servernavnet" eller "ServerTypen" er det samme for alle rækker og bidrager ikke til sorteringen af data i det resulterende regneark. "Kode"- eller "MessageCode"-kolonnens dataværdier er sorteret som tekst ufølsomme; BEA-000331 er sorteret før BEA-000360, som er sorteret før BEA-000365. For den samme værdi for kode BEA-000365 er "msg" eller "Message" kolonnedataene sorteret efter tekst også—ADMIN->GENOPTAGELSE->STANDBY>STARTER—som vist i figur 23.
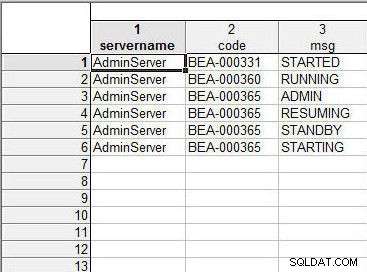
Figur 23: Resulterende regneark
Visse betingelser skal anvendes ved valg af variable. Mindst én variabel skal vælges til matchning, ellers genereres fejlen vist i figur 24.
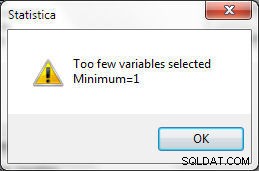
Figur 24: Der skal vælges mindst 1 variabel
Antallet af valgte variable skal være det samme i fil 1 og fil 2, ellers genereres fejlen vist i figur 25.
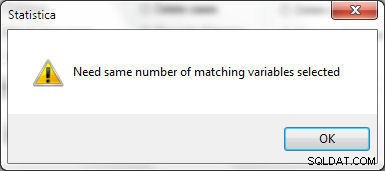
Figur 25: Samme antal variabler skal vælges i regneark for at flette
Datatypen for de valgte variable skal være den samme for de valgte variable. Som et eksempel skal variablerne "servernavn" og "ServerType" i henholdsvis fil 1 og fil 2 have samme datatype, ellers bliver fejlen vist i figur 26 genereret.
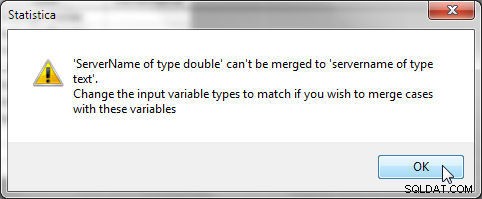
Figur 26: Variabeltyper skal være de samme, når de flettes ved at matche variabler
Konklusion
I dette selvstudie diskuterede vi fletning af datafiler (også kaldet regneark) i Statistica Platform ved hjælp af tilstande:Match sagsnavne og Match variabler.