For enhver ny database, der er oprettet i SQL Server, er standardværdien for indstillingen Auto Update Statistics aktiveret . Jeg formoder, at de fleste DBA'er lader indstillingen være aktiveret, da den giver optimeringsværktøjet mulighed for automatisk at opdatere statistik, når de er ugyldige, og det anbefales generelt at lade det være aktiveret. Statistikker opdateres også, når indekser genopbygges, og selvom det ikke er ualmindeligt, at statistikker styres godt via muligheden for automatisk opdatering af statistik og gennem indeksombygninger, kan en DBA fra tid til anden finde det nødvendigt at oprette et almindeligt job for at opdatere en statistik, eller sæt af statistikker.
Brugerdefineret styring af statistik involverer ofte kommandoen UPDATE STATISTICS, som virker ret godartet. Det kan køres for al statistik for en tabel eller indekseret visning, eller for en specifik statistik. Standardprøven kan bruges, en specifik prøvefrekvens eller antal rækker, der skal prøves, kan angives, eller du kan bruge den samme prøveværdi, som blev brugt tidligere. Hvis statistikker er opdateret for en tabel eller indekseret visning, kan du vælge at opdatere al statistik, kun indeksstatistikker eller kun kolonnestatistikker. Og endelig kan du deaktivere muligheden for automatisk opdatering af statistik for en statistik.
For de fleste DBA'er kan den største overvejelse være hvornår for at køre UPDATE STATISTICS-sætningen. Men DBA'er bestemmer også, bevidst eller ej, prøvestørrelsen for opdateringen. Den valgte prøvestørrelse kan påvirke ydeevnen af den faktiske opdatering såvel som ydelsen af forespørgsler.
Forståelse af virkningerne af prøvestørrelse
Standardprøvestørrelsen for UPDATE STATISTICS kommer fra en ikke-lineær algoritme, og prøvestørrelsen falder, efterhånden som tabelstørrelsen bliver større, som Joe Sack viste i sit indlæg, Auto-Update Stats Default Sampling Test. I nogle tilfælde er stikprøvestørrelsen muligvis ikke stor nok til at fange nok interessant information, eller den rigtige oplysninger til statistikhistogrammet, som bemærket af Conor Cunningham i hans indlæg om Statistics Sample Rates. Hvis standardeksemplet ikke skaber et godt histogram, kan DBA'er vælge at opdatere statistik med en højere samplingshastighed op til en FULLSCAN (scanning af alle rækker i tabellen eller indekseret visning). Men som Conor nævnte i sit indlæg, koster det at scanne flere rækker, og DBA er udfordret med at beslutte, om man skal køre en FULLSCAN for at forsøge at skabe det "bedst mulige" histogram eller prøve en mindre procentdel for at minimere præstationspåvirkningen af opdateringen.
For at prøve at forstå, på hvilket tidspunkt en prøve tager længere tid end en FULLSCAN, kørte jeg følgende udsagn mod kopier af SalesOrderDetail-tabellen, der blev forstørret ved hjælp af Jonathan Kehayias' script:
| udsagns-id | OPDATERING STATISTIK-erklæring |
|---|---|
| 1 | OPDATERING STATISTIK [Salg].[SalesOrderDetailEnlarged] MED FULLSCAN; |
| 2 | OPDATERING STATISTIK [Salg].[SalesOrderDetailEnlarged]; |
| 3 | OPDATERING STATISTIK [Salg].[SalesOrderDetailEnlarged] MED PRØVE 10 PROCENT; |
| 4 | OPDATERING STATISTIK [Salg].[SalesOrderDetailEnlarged] MED PRØVE 25 PROCENT; |
| 5 | OPDATERING STATISTIK [Salg].[SalesOrderDetailEnlarged] MED PRØVE 50 PROCENT; |
| 6 | OPDATERING STATISTIK [Salg].[SalesOrderDetailEnlarged] MED PRØVE 75 PROCENT; |
Jeg havde tre kopier af SalesOrderDetailEnlarged-tabellen med følgende egenskaber*:
| Rækkeantal | Sideantal | MAXDOP | Maksimal hukommelse | Opbevaring | Maskin |
|---|---|---|---|---|---|
| 23.899.449 | 363.284 | 4 | 8 GB | SSD_1 | Bærbar |
| 607.312.902 | 7.757.200 | 16 | 54 GB | SSD_2 | Testserver |
| 607.312.902 | 7.757.200 | 16 | 54 GB | 15K | Testserver |
*Yderligere detaljer om hardwaren er i slutningen af dette indlæg.
Alle kopier af tabellen havde følgende statistik, og ingen af de tre indeksstatistikker havde inkluderet kolonner:
| Statistik | Type | Kolonner i nøgle |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Indeks | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Indeks | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Indeks | Produkt-id |
| user_CarrierTrackingNumber | Kolonne | CarrierTrackingNumber |
Jeg kørte ovenstående UPDATE STATISTICS-udsagn fire gange hver mod SalesOrderDetailEnlarged-tabellen på min bærbare computer og to gange hver mod SalesOrderDetailEnlarged-tabellerne på TestServeren. Udsagn blev kørt i tilfældig rækkefølge hver gang, og procedurecache og buffercache blev ryddet før hver opdateringssætning. Varigheden og tempdb-brugen for hvert sæt af udsagn (gennemsnit) er i graferne nedenfor:
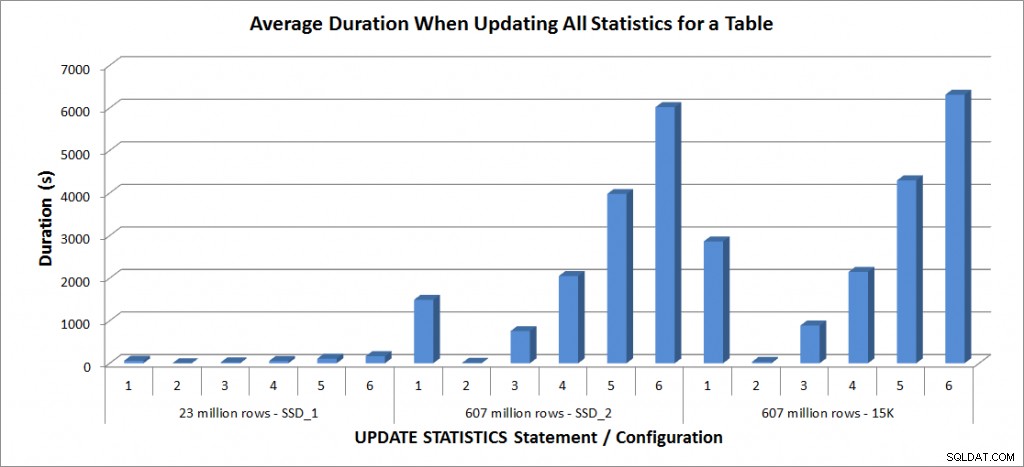
Gennemsnitlig varighed – Opdater alle statistikker for SalesOrderDetailEnlarged
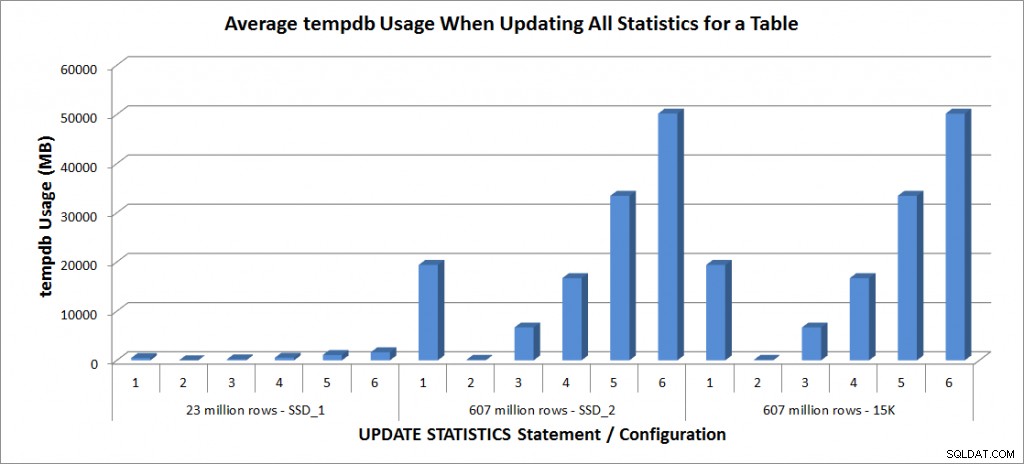
tempdb-brug – Opdater alle statistikker for SalesOrderDetailEnlarged
Varigheden for tabellen med 23 millioner rækker var alle mindre end tre minutter og er beskrevet mere detaljeret i næste afsnit. For tabellen på SSD_2-diskene tog FULLSCAN-sætningen 1492 sekunder (næsten 25 minutter), og opdateringen med en prøve på 25 % tog 2051 sekunder (over 34 minutter). I modsætning hertil tog FULLSCAN-sætningen på 15K-diskene 2864 sekunder (over 47 minutter), og opdateringen med en prøve på 25 % tog 2147 sekunder (næsten 36 minutter) – mindre end FULLSCAN-tiden. Opdateringen med en prøve på 50 % tog dog 4296 sekunder (over 71 minutter).
Tempdb-brugen er meget mere konsekvent, viser en konstant stigning, efterhånden som prøvestørrelsen øges, og bruger mere tempdb-plads end en FULLSCAN et sted mellem 25 % og 50 %. Hvad der er bemærkelsesværdigt her, er, at OPDATERING STATISTIK gør brug tempdb, hvilket er vigtigt at huske, når du dimensionerer tempdb til et SQL Server-miljø. Tempdb-brug er nævnt i UPDATE STATISTICS BOL-posten:
UPDATE STATISTICS kan bruge tempdb til at sortere stikprøven af rækker til bygningsstatistik."
Og effekten er dokumenteret i Linchi Sheas indlæg, Performance impact:tempdb and update statistics. Det er dog ikke altid noget, der nævnes under tempdb-størrelsesdiskussioner. Hvis du har store tabeller og udfører opdateringer med FULLSCAN eller høje prøveværdier, skal du være opmærksom på tempdb-brugen.
Ydeevne af selektive opdateringer
Jeg besluttede derefter at teste UPDATE STATISTICS-udsagnene for de andre statistikker på bordet, men begrænsede mine tests til kopien af tabellen med 23 millioner rækker. Ovenstående seks variationer af UPDATE STATISTICS-sætningen blev gentaget fire gange hver for følgende individuelle statistikker og derefter sammenlignet med opdateringen for hele tabellen:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Alle test blev kørt med den førnævnte konfiguration på min bærbare computer, og resultaterne er i grafen nedenfor:
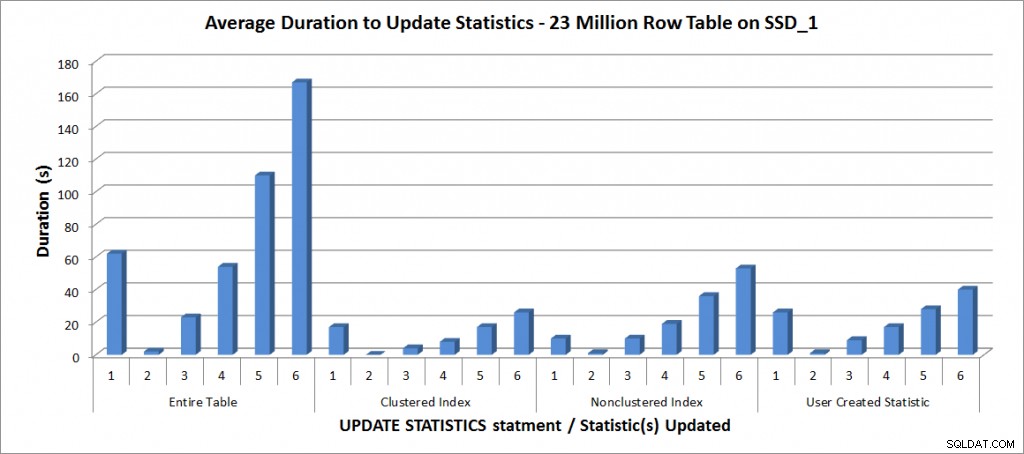
Gennemsnitlig varighed for OPDATERING STATISTIK – Alle statistikker vs. udvalgte em>
Som forventet tog opdateringerne af en individuel statistik kortere tid end ved opdatering af al statistik for tabellen. Den værdi, hvorved den samplede opdatering tog længere tid end en FULLSCAN varierede:
| OPDATERING erklæring | FULLSCAN varighed (s) | Første OPDATERING, der tog længere tid |
|---|---|---|
| Hele tabellen | 62 | 50 % – 110 sekunder |
| Clustered Index | 17 | 75 % – 26 sekunder |
| Ikke-klyngede indeks | 10 | 25 % – 19 sekunder |
| Brugeroprettet statistik | 26 | 50 % – 28 sekunder |
Konklusion
Baseret på disse data og FULLSCAN-dataene fra de 607 millioner rækketabeller er der ingen specifik vendepunkt, hvor en samplet opdatering tager længere tid end en FULLSCAN; dette punkt afhænger af tabellens størrelse og de tilgængelige ressourcer. Men dataene er stadig umagen værd, da de viser, at der er et punkt, hvor en samplet værdi kan tage længere tid at fange end en FULLSCAN. Det handler igen om at kende dine data. Dette er afgørende for ikke kun at forstå, om en tabel har brug for tilpasset styring af statistik, men også for at forstå den ideelle stikprøvestørrelse for at skabe et nyttigt histogram og også optimere ressourceforbruget.
Specifikationer
Laptop-specifikationer:Dell M6500, 1 Intel i7 (2,13GHz 4 kerner og HT er aktiveret, så 8 logiske kerner), 32 GB hukommelse, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), databasefiler gemt på en 265 GB Samsung SSD PM810Testserverspecifikationer:Dell R720, 2 Intel E5-2670 (2,6GHz 8 kerner og HT er aktiveret, så 16 logiske kerner pr. socket), 64 GB hukommelse, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), databasefiler til en tabel er placeret på to 640 GB Fusion-io Duo MLC-kort, databasefiler til den anden tabel er på ni 15K RPM-diske i et RAID5-array