
Alt for ofte ser jeg folk, der klager over, hvordan deres transaktionslog overtog deres harddisk. Mange gange viser det sig, at de udførte en stor sletningsoperation, såsom rensning eller arkivering af data, i en stor transaktion.
Jeg ønskede at køre nogle tests for at vise virkningen, på både varighed og transaktionsloggen, af at udføre den samme dataoperation i bidder versus en enkelt transaktion. Jeg oprettede en database og udfyldte den med en stor tabel SalesOrderDetailEnlarged ,
Efter at have udfyldt tabellen sikkerhedskopierede jeg databasen, sikkerhedskopierede loggen og kørte en DBCC SHRINKFILE (skyd mig ikke), så indvirkningen på logfilen kunne etableres fra en baseline (ved udmærket at disse operationer *vil* få transaktionsloggen til at vokse).
Jeg brugte med vilje en mekanisk disk i modsætning til en SSD. Selvom vi måske begynder at se en mere populær trend med at flytte til SSD, er det endnu ikke sket i stor nok skala; i mange tilfælde er det stadig for dyrt at gøre det på store lagerenheder.
Testene
Så næste gang skulle jeg bestemme, hvad jeg ville teste for størst effekt. Da jeg i går var involveret i en diskussion med en kollega om sletning af data i bidder, valgte jeg sletninger. Og da det klyngede indeks på denne tabel er på SalesOrderID , det ville jeg ikke bruge – det ville være for nemt (og ville meget sjældent matche den måde, sletninger håndteres på i det virkelige liv). Så jeg besluttede i stedet at gå efter en række ProductID værdier, hvilket ville sikre, at jeg ville ramme et stort antal sider og kræve en masse logning. Jeg bestemte, hvilke produkter der skulle slettes ved følgende forespørgsel:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Dette gav følgende resultater:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Dette ville slette 456.960 rækker (ca. 10 % af tabellen), fordelt på mange ordrer. Dette er ikke en realistisk ændring i denne sammenhæng, da det vil rode med forudberegnede ordretotaler, og du kan ikke rigtig fjerne et produkt fra en ordre, der allerede er afsendt. Men ved at bruge en database, som vi alle kender og elsker, er det analogt med f.eks. at slette en bruger fra et forumside og også slette alle deres beskeder – et rigtigt scenarie, jeg har set i naturen.
Så en test ville være at udføre følgende, one-shot sletning:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Jeg ved, at dette vil kræve en massiv scanning og tage en enorm vejafgift på transaktionsloggen. Det er lidt af pointen. :-)
Mens det kørte, sammensatte jeg et andet script, der vil udføre denne sletning i bidder:25.000, 50.000, 75.000 og 100.000 rækker ad gangen. Hver chunk vil blive forpligtet i sin egen transaktion (så hvis du har brug for at stoppe scriptet, kan du det, og alle tidligere chunks vil allerede være committet, i stedet for at skulle starte forfra), og afhængigt af gendannelsesmodellen vil blive fulgt ved enten et CHECKPOINT eller en BACKUP LOG for at minimere den løbende indvirkning på transaktionsloggen. (Jeg vil også teste uden disse operationer.) Det vil se nogenlunde sådan ud (jeg kommer ikke til at bøvle med fejlhåndtering og andre finesser til denne test, men du bør ikke være lige så cavalier):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Efter hver test ville jeg selvfølgelig gendanne den originale sikkerhedskopi af databasen WITH REPLACE, RECOVERY , indstil gendannelsesmodellen i overensstemmelse hermed, og kør den næste test.
Resultaterne
Resultatet af den første test var overhovedet ikke særlig overraskende. At udføre sletningen i en enkelt erklæring tog det 42 sekunder i fuld og 43 sekunder i simple. I begge tilfælde øgede dette loggen til 579 MB.
Det næste sæt af tests havde et par overraskelser for mig. Den ene er, at selvom disse chunking-metoder reducerede indvirkningen på logfilen markant, var kun et par kombinationer tæt på, og ingen var faktisk hurtigere. En anden er, at chunking i fuld gendannelse (uden at udføre en log backup mellem trin) generelt fungerede bedre end tilsvarende operationer i simpel gendannelse. Her er resultaterne for varighed og logpåvirkning:
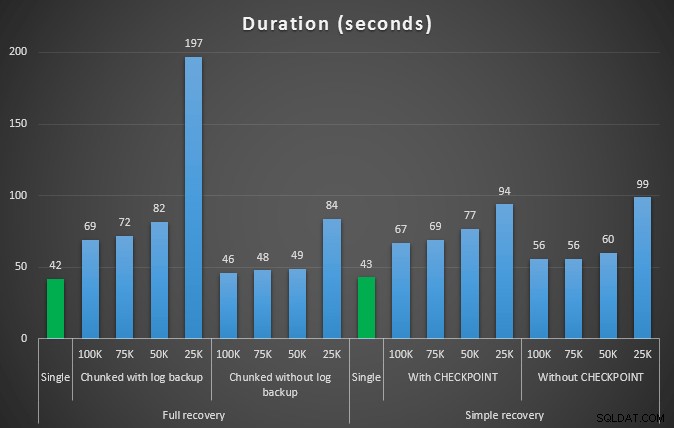
Varighed, i sekunder, af forskellige sletningsoperationer, der fjerner 457.000 rækker
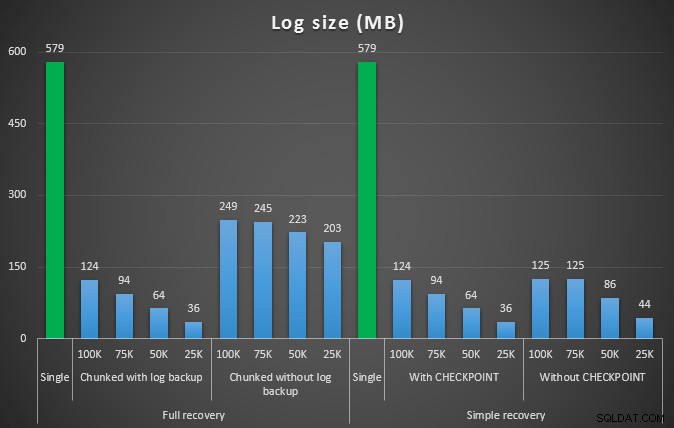
Logstørrelse, i MB, efter forskellige sletningsoperationer, der fjerner 457.000 rækker
Igen, mens logstørrelsen er væsentligt reduceret, øges varigheden generelt. Du kan bruge denne type skala til at afgøre, om det er vigtigere at reducere påvirkningen af diskplads eller at minimere tidsforbruget. For et lille hit i varighed (og trods alt køres de fleste af disse processer i baggrunden), kan du opnå betydelige besparelser (op til 94 % i disse tests) i logpladsbrug.
Bemærk, at jeg ikke prøvede nogen af disse tests med komprimering aktiveret (muligvis en fremtidig test!), og jeg forlod log autogrow-indstillingerne på de frygtelige standardindstillinger (10%) – dels af dovenskab og dels fordi mange miljøer derude har bevaret denne forfærdelige indstilling.
Men hvad hvis jeg har flere data?
Dernæst tænkte jeg, at jeg skulle teste dette på en lidt større database. Så jeg lavede endnu en database og lavede en ny, større kopi af dbo.SalesOrderDetailEnlarged . Omtrent ti gange større, faktisk. Denne gang i stedet for en primær nøgle på SalesOrderID, SalesorderDetailID , jeg har lige lavet det til et klynget indeks (for at tillade dubletter) og udfyldte det på denne måde:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); På grund af begrænsninger på diskplads, var jeg nødt til at flytte væk fra min bærbare computers VM til denne test (og valgte en 40-kernet boks med 128 GB RAM, der lige tilfældigvis sad næsten inaktiv :-)), og stadigvæk det var på ingen måde en hurtig proces. Population af tabellen og oprettelse af indeksene tog ~24 minutter.
Tabellen har 48,5 millioner rækker og fylder 7,9 GB i disk (4,9 GB i data og 2,9 GB i indeks).
Denne gang, min forespørgsel om at finde et godt sæt kandidater ProductID værdier, der skal slettes:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Givet følgende resultater:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Så vi vil slette 4.455.360 rækker, lidt under 10% af tabellen. Efter et lignende mønster til ovenstående test vil vi slette alt i ét skud, derefter i bidder af 500.000, 250.000 og 100.000 rækker.
Resultater:
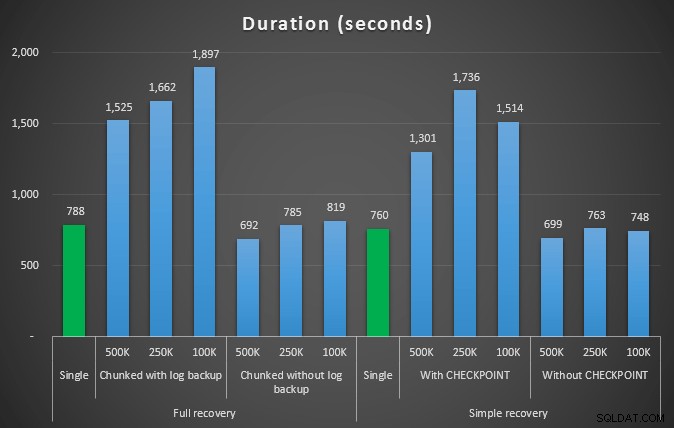 Varighed, i sekunder, af forskellige sletningsoperationer, der fjerner 4,5 mm rækker
Varighed, i sekunder, af forskellige sletningsoperationer, der fjerner 4,5 mm rækker
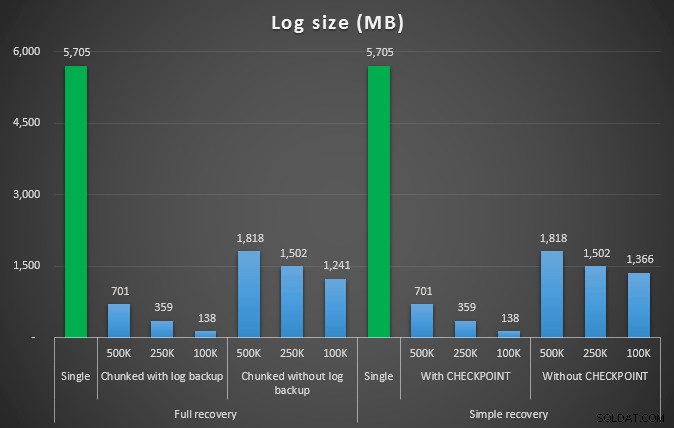 Logstørrelse, i MB, efter forskellige sletningsoperationer, der fjerner 4,5 mm rækker
Logstørrelse, i MB, efter forskellige sletningsoperationer, der fjerner 4,5 mm rækker
Så igen ser vi en betydelig reduktion i logfilstørrelsen (over 97% i tilfælde med den mindste chunk-størrelse på 100K); I denne skala ser vi dog nogle få tilfælde, hvor vi også udfører sletningen på kortere tid, selv med alle de autogrow-begivenheder, der må være opstået. Det lyder meget som win-win for mig!
Denne gang med en større log
Nu var jeg nysgerrig efter, hvordan disse forskellige sletninger ville sammenlignes med en logfil, der er forhåndsdimensioneret til at rumme så store operationer. Ved at holde mig til vores større database, udvidede jeg logfilen til 6 GB, sikkerhedskopierede den og kørte derefter testene igen:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Resultater, sammenligning af varighed med en fast logfil med det tilfælde, hvor filen skulle automatisk vokse kontinuerligt:
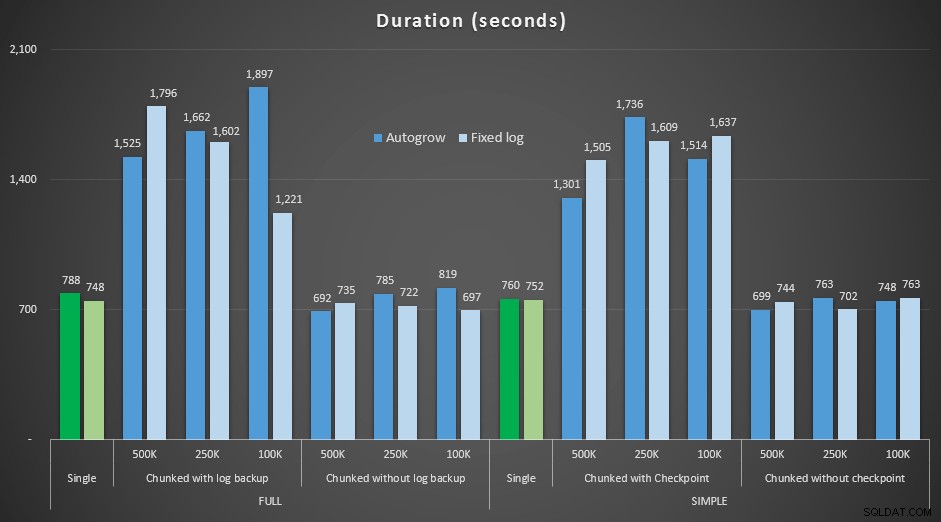
Varighed, i sekunder, af forskellige sletningsoperationer, der fjerner 4,5 mm rækker , der sammenligner fast logstørrelse og autogrow
Igen ser vi, at de metoder, der deler sletninger i batches, og *ikke* udfører en log backup eller et kontrolpunkt efter hvert trin, konkurrerer med den tilsvarende enkelt operation med hensyn til varighed. Faktisk kan du se, at de fleste faktisk præsterer på mindre samlet tid, med den ekstra bonus, at andre transaktioner vil kunne komme ind og ud mellem trinene. Hvilket er en god ting, medmindre du vil have denne sletningsoperation til at blokere alle ikke-relaterede transaktioner.
Konklusion
Det er klart, at der ikke er noget enkelt, korrekt svar på dette problem – der er en masse iboende "det afhænger af"-variabler. Det kan tage nogle eksperimenter at finde dit magiske tal, da der vil være en balance mellem den overhead, det tager at tage backup af loggen, og hvor meget arbejde og tid du sparer ved forskellige chunkstørrelser. Men hvis du planlægger at slette eller arkivere et stort antal rækker, er det ret sandsynligt, at du samlet set vil være bedre stillet ved at udføre ændringerne i bidder frem for i én, massiv transaktion – selvom varighedstallene synes at være at en mindre attraktiv drift. Det handler ikke kun om varighed – hvis du ikke har en tilstrækkelig forudtildelt logfil og ikke har plads til at rumme en så massiv transaktion, er det sandsynligvis meget bedre at minimere logfilvækst på bekostning af varighed, i så fald vil du gerne ignorere varighedsgraferne ovenfor og være opmærksom på logstørrelsesgraferne.
Hvis du har råd til pladsen, vil du måske stadig have en forudgående størrelse på din transaktionslog i overensstemmelse hermed. Afhængigt af scenariet endte det nogle gange med at bruge standard autogrow-indstillingerne lidt hurtigere i mine test end at bruge en fast logfil med masser af plads. Derudover kan det være svært at gætte præcis, hvor meget du skal bruge for at imødekomme en stor transaktion, du ikke har kørt endnu. Hvis du ikke kan teste et realistisk scenarie, så prøv dit bedste for at forestille dig dit worst case-scenarie – så fordoble det for en sikkerheds skyld. Kimberly Tripp (blog | @KimberlyLTripp) har nogle gode råd i dette indlæg:8 trin til bedre transaktionsloggennemstrømning – i denne sammenhæng, se specifikt på punkt #6. Uanset hvordan du beslutter dig for at beregne dine logpladskrav, hvis du alligevel ender med at få brug for pladsen, er det bedre at tage det på en kontrolleret måde i god tid, end at stoppe dine forretningsprocesser, mens de venter på en autogrow ( pyt med flere!).
En anden meget vigtig facet af dette, som jeg ikke målte eksplicit, er indvirkningen på samtidighed – en masse kortere transaktioner vil i teorien have mindre indflydelse på samtidige operationer. Mens en enkelt sletning tog lidt kortere tid end de længere, batchede operationer, holdt den alle sine låse i hele denne varighed, mens de chunked operationer ville gøre det muligt for andre transaktioner i kø at snige sig ind mellem hver transaktion. I et fremtidigt indlæg vil jeg prøve at se nærmere på denne påvirkning (og jeg har også planer om andre dybere analyser).