Extraction Transformation Load (ETL) er rygraden i ethvert datavarehus. I datavarehusets verden administreres data af ETL-processen, som består af tre processer, Extraction-Pull/Acquire data fra kilder, Transformation-change data i det påkrævede format og Load-push data til destinationen generelt til et data warehouse eller et datamarked.
Lær SSIS og start din gratis prøveperiode i dag!
SQL Server Integration Services (SSIS) er værktøjet i ETL-familien, der er nyttigt til at udvikle og administrere et virksomhedsdatavarehus. Et datavarehus arbejder ved sin egen karakterisering på en enorm mængde data, og ydeevne er en stor udfordring, når man administrerer en enorm mængde data for enhver arkitekt eller DBA.
Overvejelser om ETL-forbedring
I dag vil jeg diskutere, hvor nemt du kan forbedre ETL-ydelse eller designe et højtydende ETL-system ved hjælp af SSIS. For en bedre forståelse vil jeg opdele ti metoder i to forskellige kategorier; først, SSIS-pakkedesigntidsovervejelser og for det andet konfiguration af forskellige egenskabsværdier for komponenter, der er tilgængelige i SSIS-pakken.
SSIS-pakkedesign-tidsovervejelser
#1 Udtræk data parallelt:SSIS giver mulighed for at trække data parallelt ved hjælp af sekvensbeholdere i kontrolflow. Du kan designe en pakke på en sådan måde, at den kan trække data fra ikke-afhængige tabeller eller filer parallelt, hvilket vil hjælpe med at reducere den samlede ETL-udførelsestid.
#2 Udtræk påkrævede data:Træk kun det nødvendige sæt data fra enhver tabel eller fil. Du skal undgå tendensen til at trække alt tilgængeligt på kilden for nu, som du vil bruge i fremtiden; det spiser netværksbåndbredde, bruger systemressourcer (I/O og CPU), kræver ekstra lagerplads, og det forringer ETL-systemets overordnede ydeevne.
Hvis dit ETL-system er virkelig dynamisk af natur, og dine krav ofte ændrer sig, ville det være bedre at overveje andre designtilgange, såsom Meta Data-drevet ETL osv. frem for at designe til at trække alt ind på én gang.
#3 Undgå brugen af asynkrone transformationskomponenter:SSIS er et rigt værktøj med et sæt transformationskomponenter til at opnå komplekse opgaver under ETL-udførelse, men det koster dig samtidig meget, hvis disse komponenter ikke bliver brugt korrekt.
To kategorier af transformationskomponenter er tilgængelige i SSIS:Synkron og Asynkron .
Synkrone transformationer er de komponenter, der behandler hver række og skubber ned til den næste komponent/destination, det bruger allokeret bufferhukommelse og kræver ikke yderligere hukommelse, da det er direkte forhold mellem input/output datarække, som passer fuldstændig ind i allokeret hukommelse. Komponenter som opslag, afledte kolonner og datakonvertering osv. falder ind under denne kategori.
Asynkrone transformationer er de komponenter, der først lagrer data i bufferhukommelsen og derefter behandler operationer som Sorter og Aggregate. Yderligere bufferhukommelse er påkrævet for at fuldføre opgaven, og indtil bufferhukommelsen er tilgængelig holder den alle data i hukommelsen og blokerer transaktionen, også kendt som blokerende transformation. For at fuldføre opgaven vil SSIS-motoren (dataflow-pipeline-motor) allokere ekstra bufferhukommelse, hvilket igen er en overhead til ETL-systemet. Komponenter som Sorter, Aggregate, Merge, Join osv. falder ind under denne kategori.
Samlet set bør du undgå asynkrone transformationer, men alligevel, hvis du kommer i en situation, hvor du ikke har noget andet valg, skal du være opmærksom på, hvordan du håndterer de tilgængelige ejendomsværdier for disse komponenter. Jeg vil diskutere dem senere i denne artikel.
#4 Optimal brug af hændelse i hændelseshandlere:for at spore pakkeudførelsesfremskridt eller tage andre passende handlinger på en specifik hændelse, leverer SSIS et sæt hændelser. Begivenheder er meget nyttige, men overdreven brug af begivenheder vil koste ekstra overhead på ETL-udførelse.
Her skal du validere alle karaktertræk, før du aktiverer en begivenhed i SSIS-pakken.
#5 Skal være opmærksom på destinationstabelskemaet, når du arbejder på en enorm mængde data. Du skal tænke dig om to gange, når du skal trække en enorm mængde data fra kilden og skubbe den ind i et datavarehus eller datamarked. Du kan se ydeevneproblemer, når du forsøger at skubbe enorme data ind i destinationen med en kombination af indsæt, opdatering og sletning (DML), da der kan være en chance for, at destinationstabellen vil have klyngede eller ikke-klyngede indekser, hvilket kan forårsage en masse data-shuffling i hukommelsen på grund af DML-operationer.
Hvis ETL har præstationsproblemer på grund af en enorm mængde DML-operationer på en tabel, der har et indeks, skal du foretage passende ændringer i ETL-designet, som at droppe eksisterende klyngede indekser i præ-udførelsesfasen og genskabe alle indekser i efterudførelsesfasen. Du kan finde andre bedre alternativer til at løse problemet baseret på din situation.
Konfigurer komponentegenskaber
#6 Styr parallel udførelse af en opgave ved at konfigurere MaxConcurrentExecutables og EngineThreads ejendom. SSIS-pakke- og dataflowopgaver har en egenskab til at kontrollere parallel udførelse af en opgave:MaxConcurrentExecutables er egenskaben på pakkeniveau og har en standardværdi på -1 , hvilket betyder, at det maksimale antal opgaver, der kan udføres, er lig med det samlede antal processorer på maskinen plus to;
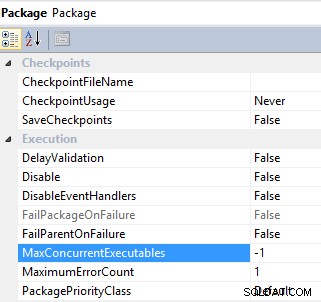
Pakke
EngineThreads er en egenskab på dataflowopgaveniveau og har en standardværdi på 10, som angiver det samlede antal tråde, der kan oprettes til udførelse af dataflowopgaven.
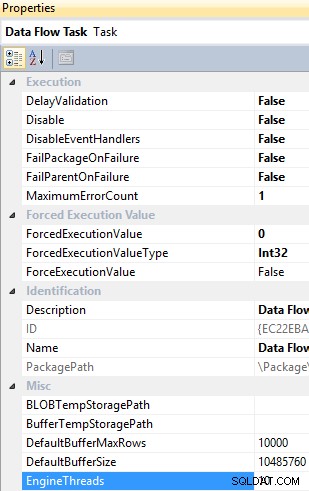
Dataflowopgave
Du kan ændre standardværdierne for disse egenskaber i henhold til ETL-behov og tilgængelighed af ressourcer.
#7 Konfigurer indstillingen for dataadgangstilstand i OLEDB-destination. I SSIS-dataflowopgaven kan vi finde OLEDB-destinationen, som giver et par muligheder for at skubbe data ind i destinationstabellen under Dataadgangstilstanden; først "Tabel eller visning", som indsætter en række ad gangen; for det andet muligheden "Tabel eller vis hurtig indlæsning", som internt bruger bulk insert-sætningen til at sende data til destinationstabellen, hvilket altid giver bedre ydeevne sammenlignet med andre muligheder. Når du vælger "hurtig indlæsning"-indstillingen, giver det dig mere kontrol til at administrere destinationstabellens adfærd under en data-push-operation, såsom Behold identitet, Behold nuller, Tabellås og Tjek-begrænsninger.
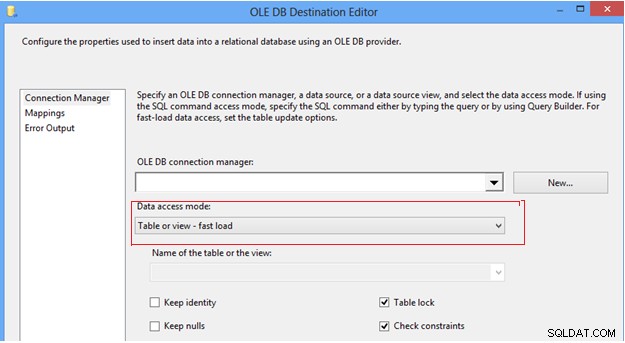
OLE DB-destinationseditor
Det anbefales stærkt, at du bruger muligheden for hurtig indlæsning til at skubbe data ind i destinationstabellen for at forbedre ETL-ydeevnen.
#8, Konfigurer rækker pr. batch og maksimal indsætningsstørrelse i OLEDB-destination. Disse to indstillinger er vigtige for at kontrollere ydeevnen af tempdb og transaktionslog, fordi den med de givne standardværdier for disse egenskaber vil skubbe data ind i destinationstabellen under én batch og én transaktion. Det vil kræve overdreven brug af tembdb og transaktionslog, hvilket bliver til et ETL-ydeevneproblem på grund af for stort forbrug af hukommelse og disklager.
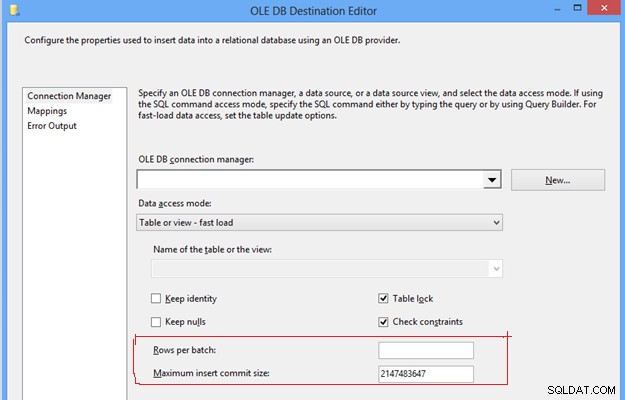
OLE DB-destinationseditor
For at forbedre ETL-ydeevnen kan du sætte en positiv heltalværdi i begge egenskaberne baseret på forventet datavolumen, hvilket vil hjælpe med at opdele en hel masse data i flere batches, og data i en batch kan igen forpligte sig til destinationstabellen afhængigt af angivne værdi. Det vil undgå overdreven brug af tempdb og transaktionslog, hvilket vil hjælpe med at forbedre ETL-ydeevnen.
#9 Brug af SQL Server-destination i en dataflowopgave. Når du vil skubbe data ind i en lokal SQL Server-database, anbefales det stærkt at bruge SQL Server-destination, da det giver mange fordele for at overvinde andre muligheders begrænsninger, hvilket hjælper dig med at forbedre ETL-ydeevnen. For eksempel bruger den funktionen til masseindsættelse, der er indbygget i SQL Server, men den giver dig mulighed for at anvende transformation, før data indlæses i destinationstabellen. Udover det giver det dig mulighed for at aktivere/deaktivere triggeren, der skal udløses, når data indlæses, hvilket også hjælper med at reducere ETL-overhead.
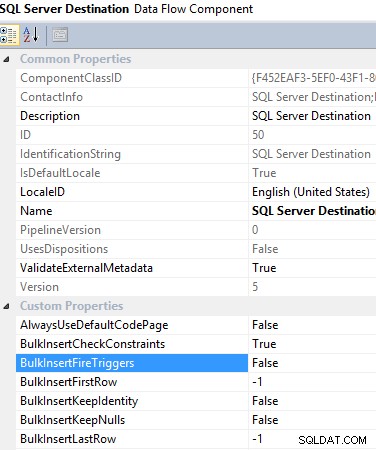
SQL-serverdestinationsdataflowkomponent
#10 Undgå implicit typecast. Når data kommer fra en flad fil, behandler forbindelsesadministratoren for flad fil alle kolonner som en streng (DS_STR) datatype, inklusive numeriske kolonner. Som du ved, bruger SSIS bufferhukommelse til at gemme hele sættet af data og anvender den nødvendige transformation, før data skubbes ind i destinationstabellen. Nu, når alle kolonner er strengdatatyper, vil det kræve mere plads i bufferen, hvilket vil reducere ETL-ydeevnen.
For at forbedre ETL-ydeevnen bør du konvertere alle de numeriske kolonner til den passende datatype og undgå implicit konvertering, hvilket vil hjælpe SSIS-motoren med at rumme flere rækker i en enkelt buffer.
Oversigt over ETL-ydeevneforbedringer
I denne artikel undersøgte vi, hvor nemt ETL-ydeevne kan kontrolleres på ethvert tidspunkt. Dette er 10 almindelige måder at forbedre ETL-ydeevne på. Der kan være flere metoder baseret på forskellige scenarier, hvorigennem ydeevnen kan forbedres.
Overordnet set kan du ved hjælp af kategorisering identificere, hvordan du skal håndtere situationen. Hvis du er i designfasen af et datavarehus, skal du muligvis koncentrere dig om begge kategorier, men hvis du understøtter et gammelt system, skal du først arbejde tæt på den anden kategori.