Skalerbarhed er et systems egenskab til at håndtere en voksende mængde krav ved at tilføje ressourcer. Årsagerne til denne mængde krav kan være midlertidige, for eksempel hvis du lancerer en rabat på et udsalg, eller permanent, for en stigning i kunder eller medarbejdere. Under alle omstændigheder bør du være i stand til at tilføje eller fjerne ressourcer for at styre disse ændringer på krav eller øget trafik.
Der er forskellige tilgange til at skalere din database. I denne blog vil vi se på, hvad disse tilgange er, og hvordan du skalerer din PostgreSQL-database ved hjælp af Connection Poolers og Load Balancers.
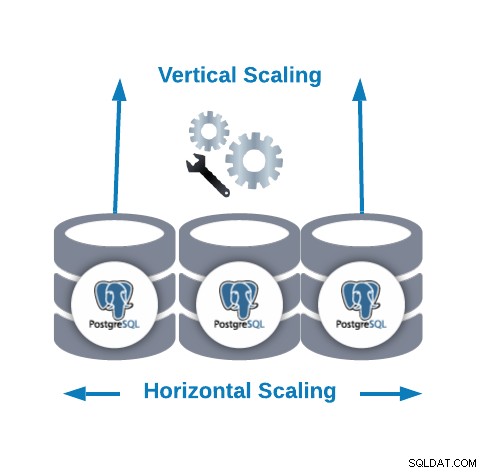
Horisontal og lodret skalering
Der er to hovedmåder at skalere din database på.
- Horisontal skalering (udskalering):Det udføres ved at tilføje flere databasenoder, der skaber eller øger en databaseklynge. Det kan hjælpe dig med at forbedre læseydelsen og balancere trafikken mellem noderne.
- Lodret skalering (opskalering):Det udføres ved at tilføje flere hardwareressourcer (CPU, hukommelse, disk) til en eksisterende databasenode. Det kan være nødvendigt at ændre nogle konfigurationsparametre for at tillade PostgreSQL at bruge en ny eller bedre hardwareressource.
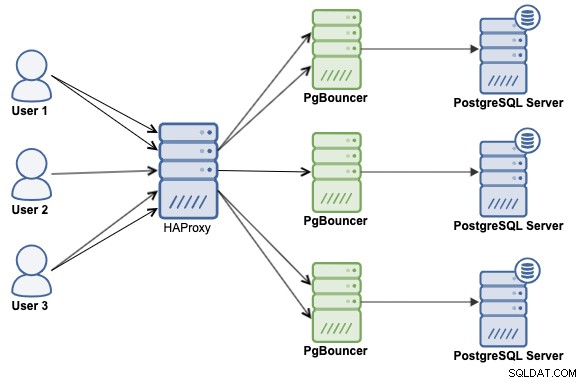
Connection Poolers og Load Balancers
I både horisontal og lodret skalering kan det være nyttigt at tilføje et eksternt værktøj for at reducere belastningen på din database, hvilket vil forbedre ydeevnen. Måske er det ikke nok, men det er et godt udgangspunkt. Til dette er det en god idé at implementere en forbindelsespooler og en load balancer. Jeg sagde "og", fordi de er designet til forskellige roller.
En forbindelsespooling er en metode til at skabe en pulje af forbindelser og genbruge dem og undgå at åbne nye forbindelser til databasen hele tiden, hvilket vil øge ydeevnen af dine applikationer betydeligt. PgBouncer er en populær forbindelsespooler designet til PostgreSQL.
Brug af en Load Balancer er en måde at have høj tilgængelighed i din databasetopologi, og det er også nyttigt at øge ydeevnen ved at balancere trafikken mellem de tilgængelige noder. Til dette er HAProxy en god mulighed for PostgreSQL, da det er en open source-proxy, der kan bruges til at implementere høj tilgængelighed, belastningsbalancering og proxy for TCP- og HTTP-baserede applikationer.
Sådan implementeres en kombination af HAProxy, PgBouncer og PostgreSQL
En kombination af begge teknologier, HAProxy og PgBouncer, er sandsynligvis den bedste måde at skalere og forbedre ydeevnen i dit PostgreSQL-miljø. Så vi vil se, hvordan man implementerer det ved hjælp af følgende arkitektur:
Vi antager, at du har ClusterControl installeret, hvis ikke, kan du gå til det officielle websted, eller endda henvise til den officielle dokumentation for at installere det.
Først skal du implementere din PostgreSQL-klynge med HAProxy foran sig. Til dette skal du følge trinene i dette blogindlæg for at implementere både PostgreSQL og HAProxy ved hjælp af ClusterControl.
På dette tidspunkt vil du have noget som dette:
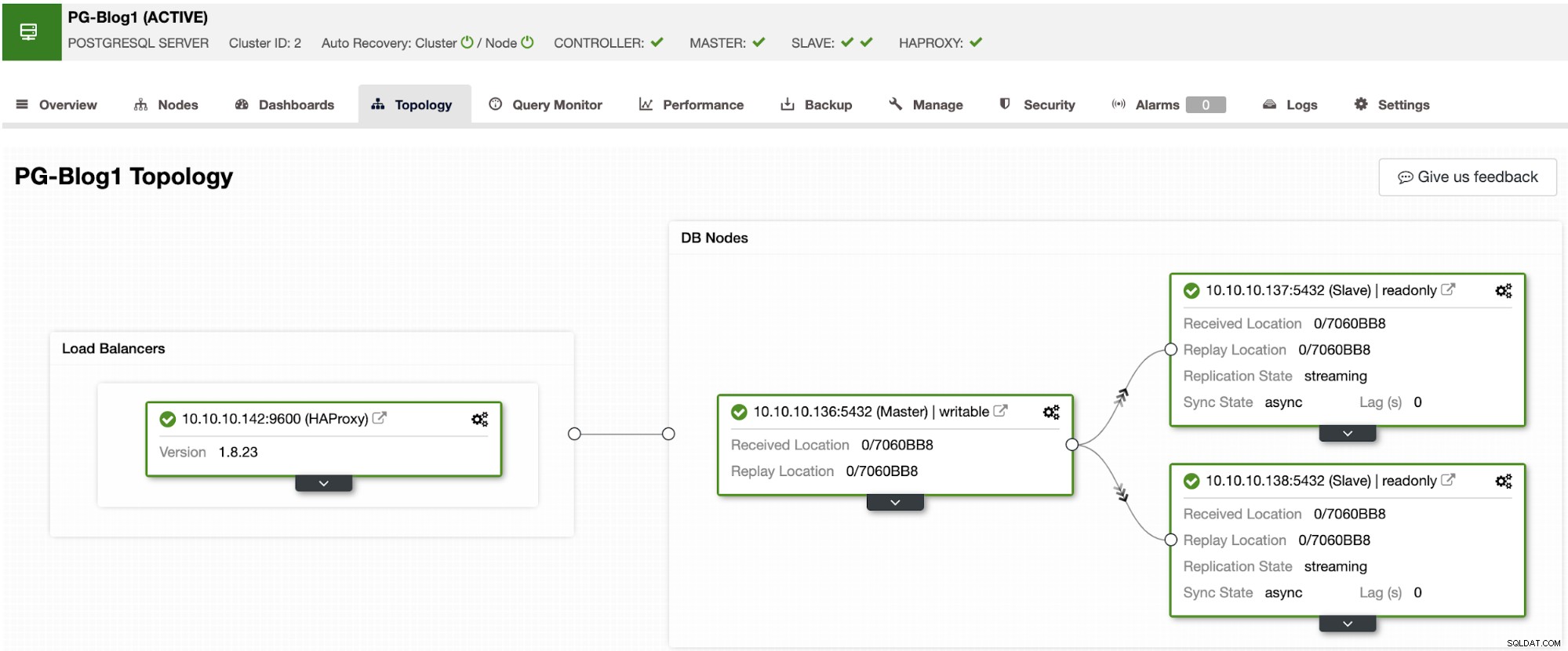
Nu kan du installere PgBouncer på hver databasenode eller på en ekstern maskine .
For at få PgBouncer-softwaren kan du gå til PgBouncer-downloadsektionen eller bruge RPM- eller DEB-lagrene. Til dette eksempel vil vi bruge CentOS 8 og installere det fra det officielle PostgreSQL-lager.
Først skal du downloade og installere det tilsvarende lager fra PostgreSQL-webstedet (hvis du ikke har det på plads endnu):
$ wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
$ rpm -Uvh pgdg-redhat-repo-latest.noarch.rpmInstaller derefter PgBouncer-pakken:
$ yum install pgbouncerNår det er gennemført, vil du have en ny konfigurationsfil placeret i /etc/pgbouncer/pgbouncer.ini. Som standard konfigurationsfil kan du bruge følgende eksempel:
$ cat /etc/pgbouncer/pgbouncer.ini
[databases]
world = host=127.0.0.1 port=5432 dbname=world
[pgbouncer]
logfile = /var/log/pgbouncer/pgbouncer.log
pidfile = /var/run/pgbouncer/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
admin_users = admindbOg godkendelsesfilen:
$ cat /etc/pgbouncer/userlist.txt
"admindb" "root123"Dette er blot et grundlæggende eksempel. For at få alle de tilgængelige parametre kan du tjekke den officielle dokumentation.
Så i dette tilfælde har jeg installeret PgBouncer i den samme databaseknude, lyttende på alle IP-adresser, og den forbinder til en PostgreSQL-database kaldet "verden". Jeg administrerer også de tilladte brugere i filen userlist.txt med en almindelig tekstadgangskode, der kan krypteres, hvis det er nødvendigt.
For at starte PgBouncer-tjenesten skal du blot køre følgende kommando:
$ pgbouncer -d /etc/pgbouncer/pgbouncer.iniKør nu følgende kommando ved hjælp af dine lokale oplysninger (port, vært, brugernavn og databasenavn) for at få adgang til PostgreSQL-databasen:
$ psql -p 6432 -h 127.0.0.1 -U admindb world
Password for user admindb:
psql (12.4)
Type "help" for help.
world=#Dette er en grundlæggende topologi. Du kan forbedre det, for eksempel ved at tilføje to eller flere load balancer-noder for at undgå et enkelt fejlpunkt og bruge et eller andet værktøj som "Keepalived", for at sikre tilgængeligheden. Det kan også gøres ved hjælp af ClusterControl.
For mere information om PgBouncer og hvordan man bruger det, kan du se dette blogindlæg.
Konklusion
Hvis du har brug for at skalere din PostgreSQL-klynge, er tilføjelse af HAProxy og PgBouncer en god måde at udskalere og opskalere på samme tid, da du kan tilføje flere varme standby-knudepunkter for at balancere trafikken og du vil forbedre ydeevnen ved at genbruge åbne forbindelser.
ClusterControl tilbyder en lang række funktioner, lige fra overvågning, alarmering, automatisk failover, backup, punkt-i-tidsgendannelse, sikkerhedskopieringsbekræftelse til skalering af læste replikaer. Dette kan hjælpe dig med at skalere din PostgreSQL-database på en vandret eller lodret måde fra en venlig og intuitiv brugergrænseflade.