Spark begyndte livet i 2009 som et projekt inden for AMPLab ved University of California, Berkeley. Mere specifikt blev det født ud af nødvendigheden af at bevise begrebet Mesos, som også blev skabt i AMPLab. Spark blev først diskuteret i Mesos hvidbog med titlen Mesos:A Platform for Fine-Grained Resource Sharing in the Data Center, især skrevet af Benjamin Hindman og Matei Zaharia.
Det opstod som en hurtig og bekvem løsning til at udføre kompleks analyse af data i stor skala. Spark udviklede sig som en ny behandlingsramme for big data, der adresserer mange af manglerne i MapReduce-modellen. Det understøtter dataanalyse i stor skala, og dataene kan være fra forskellige kilder som realtid, batchbehandling i forskellige formater som billeder, tekster, grafer og mange flere. Ud over dens Apache Spark-kerne giver den også nogle nyttige samlinger af biblioteker til big data-analyse.
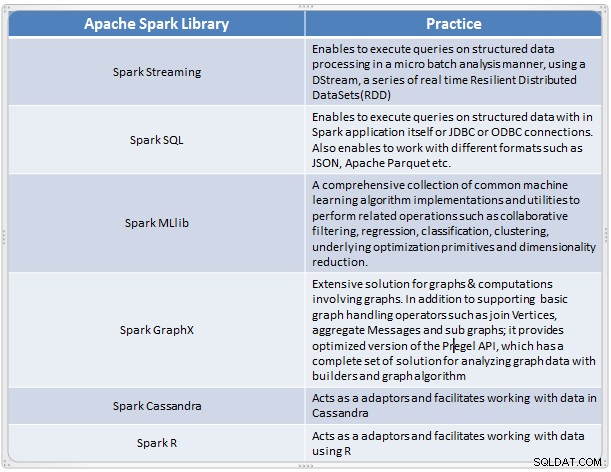
Oversigt over Spark-komponenter
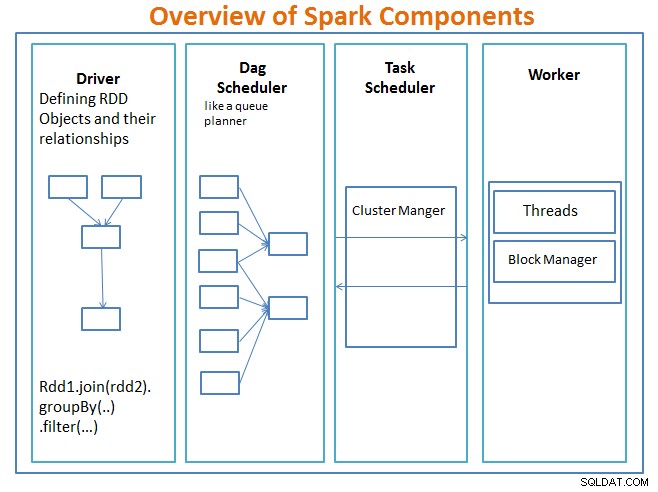
chaufføren er koden, der inkluderer hovedfunktionen og definerer de modstandsdygtige distribuerede datasæt (RDD'er) og deres transformationer. RDD'er er de vigtigste datastrukturer, som vil blive brugt i vores Spark-programmer.
Parallelle operationer på RDD'erne sendes til DAG-planlæggeren , som vil optimere koden og nå frem til en effektiv DAG, der repræsenterer databehandlingstrinnene i applikationen.
Resulterende DAG sendes til klyngeadministratoren og klyngelederen har information om arbejderne, tildelte tråde og placeringen af datablokke og er ansvarlig for at tildele specifikke behandlingsopgaver til arbejdere. Det håndterer også tilbagebetalingen i sagen, hvis arbejdersvigt. Klyngelederen kan være YARN, Mesos, Sparks klyngeleder.
arbejderen modtager arbejdsenheder og data, der skal administreres, og arbejderen udfører sin specifikke opgave uden kendskab til hele DAG, og dens resultater sendes tilbage til driverapplikationerne.
Spark er ligesom andre big data-værktøjer kraftfuld, dygtig og velegnet til at tackle en række dataudfordringer. Spark er, ligesom andre big data-teknologier, ikke nødvendigvis det bedste valg til enhver databehandlingsopgave.
I del 2 – vi vil diskutere det grundlæggende i Spark-koncepter som Resilient Distributed Datasets, Shared Variables, SparkContext, Transformations, Action , og fordele ved at bruge Spark sammen med eksempler og hvornår du skal bruge Spark.
Reference:
Lær Spark in a Day af Acodemy &Hadoop Applications Architectures.