Introduktion
En ivrig indeksspole læser alle rækker fra dens underordnede operatør til en indekseret arbejdstabel, før den begynder at returnere rækker til dens overordnede operatør. I nogle henseender er en ivrig indeksspole det ultimative manglende indeksforslag , men det er ikke rapporteret som sådan.
Omkostningsvurdering
Indsættelse af rækker i et indekseret arbejdsbord er relativt billigt, men ikke gratis. Optimizeren skal overveje, at det involverede arbejde sparer mere, end det koster. For at det skal fungere i spolens favør, skal planen estimeres til at forbruge rækker fra spolen mere end én gang. Ellers kan den lige så godt springe spolen over og bare udføre den underliggende operation den ene gang.
- For at få adgang til mere end én gang, skal spolen vises på indersiden af en indlejret sløjfeforbindelsesoperatør.
- Hver iteration af sløjfen bør søge til en bestemt indeksspoolnøgleværdi, som leveres af den ydre side af sløjfen.
Det betyder, at tilslutningen skal være en ansøgning , ikke en indlejret sløjfer join . For forskellen mellem de to, se venligst min artikel Anvend versus Nested Loops Join.
Bemærkelsesværdige funktioner
Mens en ivrig indeksspole kun vises på indersiden af en indlejret løkke anvend , det er ikke en "performance spole". En ivrig indeksspool kan ikke deaktiveres med sporingsflag 8690 eller NO_PERFORMANCE_SPOOL forespørgselstip.
Rækker, der er indsat i indeksspolen, er normalt ikke forhåndssorteret i indeksnøglerækkefølge, hvilket kan resultere i indekssideopdelinger. Udokumenteret sporingsflag 9260 kan bruges til at generere en Sortering operatør før indeksspolen for at undgå dette. Ulempen er, at de ekstra sorteringsomkostninger kan afholde optimizeren fra overhovedet at vælge spolemuligheden.
SQL Server understøtter ikke parallelle indsættelser til et b-træindeks. Det betyder, at alt under en parallel ivrig indeksspole kører på en enkelt tråd. Operatørerne under spolen er stadig (vildledende) markeret med parallelitetsikonet. Én tråd er valgt at skrive til spolen. De andre tråde venter på EXECSYNC mens det er færdigt. Når spoolen er udfyldt, kan den læses fra ved parallelle tråde.
Indeksspoler fortæller ikke optimeringsværktøjet, at de understøtter output sorteret efter spolens indeksnøgler. Hvis der kræves sorteret output fra spolen, kan du muligvis se en unødvendig Sortering operatør. Ivrige indeksspoler bør alligevel ofte erstattes af et permanent indeks, så dette er en mindre bekymring meget af tiden.
Der er fem optimeringsregler, der kan generere en Eager Index Spool mulighed (internt kendt som et on-the-fly indeks ). Vi vil se nærmere på tre af disse for at forstå, hvor ivrige indeksspoler kommer fra.
SelToIndexOnTheFly
Dette er den mest almindelige. Den matcher en eller flere relationelle valg (alias filtre eller prædikater) lige over en dataadgangsoperatør. SelToIndexOnTheFly regel erstatter prædikaterne med et søgeprædikat på en ivrig indeksspole.
Demo
Et AdventureWorks eksempel på databasen er vist nedenfor:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
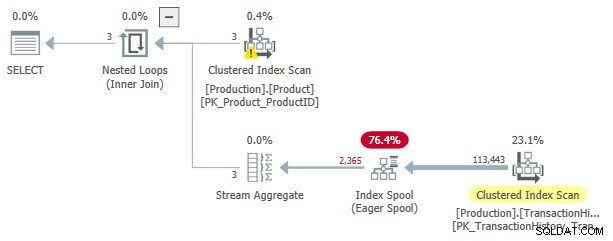
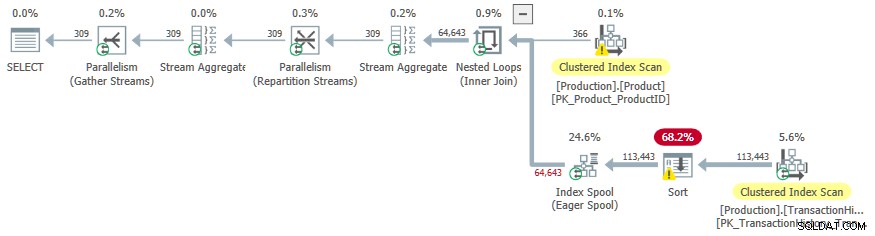
Denne udførelsesplan har en anslået pris på 3.0881 enheder. Nogle interessepunkter:
- Den Indbyggede Loops Inner Join operatør er en anvend , med
ProductIDogSafetyStockLevelfraProducttabel som ydre referencer . - På den første gentagelse af ansøgningen, Ivrig indeksspole er fuldt udfyldt fra Clustered Index Scan af
TransactionHistorytabel. - Spolens arbejdsbord har et klynget indeks indtastet på
(ProductID, Quantity). - Rækker, der matcher prædikaterne
TH.ProductID = P.ProductIDogTH.Quantity < P.SafetyStockLevelbesvares af spolen ved hjælp af dens indeks. Dette gælder for hver iteration af ansøgningen, inklusive den første. TransactionHistorytabel scannes kun én gang.
Sorteret input til spoolen
Det er muligt at gennemtvinge sorteret input til den ivrige indeksspole, men dette påvirker estimerede omkostninger, som nævnt i indledningen. I eksemplet ovenfor producerer aktivering af flaget for udokumenteret sporing en plan uden en spool:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
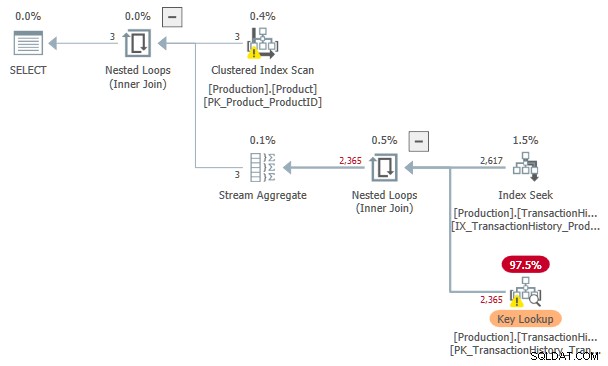
De anslåede omkostninger ved denne indekssøgning og Nøgleopslag planen er 3.11631 enheder. Dette er mere end prisen for planen med en indeksspole alene, men mindre end planen med en indeksspole og sorteret input.
For at se en plan med sorteret input til spolen, skal vi øge det forventede antal loop-iterationer. Dette giver spolen en chance for at tilbagebetale de ekstra omkostninger ved Sorteringen . En måde at udvide antallet af rækker, der forventes fra Product tabellen er at lave Name prædikat mindre restriktiv:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); Dette giver os en udførelsesplan med sorteret input til spoolen:
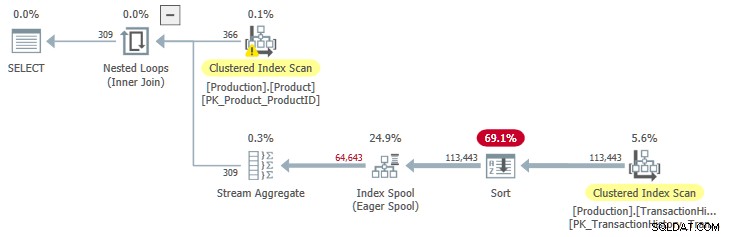
JoinToIndexOnTheFly
Denne regel transformerer en indre joinforbindelse til en ansøgning , med en ivrig indeksspole på indersiden. Mindst et af joinprædikaterne skal være en ulighed for at denne regel kan matches.
Dette er en meget mere specialiseret regel end SelToIndexOnTheFly , men ideen er meget den samme. I dette tilfælde er selektionen (prædikatet), der transformeres til en indeksspoolsøgning, forbundet med joinforbindelsen. Transformationen fra join til anvend gør det muligt at flytte sammenføjningsprædikatet fra selve sammenføjningen til indersiden af appliceringen.
Demo
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
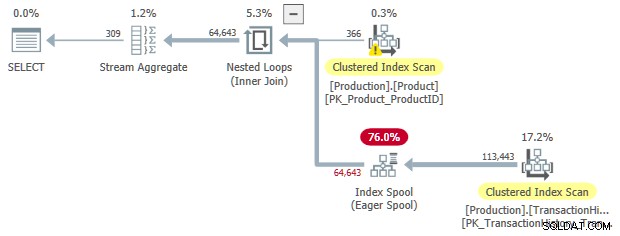
Som før kan vi anmode om sorteret input til spoolen:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
Denne gang har de ekstra omkostninger til sortering tilskyndet optimizeren til at vælge en parallel plan.
En uvelkommen bivirkning er Sorteringen operatørspild til tempdb . Den samlede tilgængelige hukommelsesbevilling til sortering er tilstrækkelig, men den er jævnt fordelt mellem parallelle tråde (som sædvanligt). Som nævnt i introduktionen understøtter SQL Server ikke parallelle indsættelser til et b-træ-indeks, så operatørerne under den ivrige indeksspool kører på en enkelt tråd. Denne enkelte tråd får kun en brøkdel af hukommelsesbevillingen, så Sorteringen spild til tempdb .
Denne bivirkning er måske en af grundene til, at sporingsflaget er udokumenteret og ikke understøttet.
SelSTVFToIdxOnFly
Denne regel gør det samme som SelToIndexOnTheFly , men for en streaming-tabelvurderet funktion (sTVF) rækkekilde. Disse sTVF'er bruges i vid udstrækning internt til blandt andet at implementere DMV'er og DMF'er. De vises i moderne udførelsesplaner som Tabelværdifunktion operatører (oprindeligt som fjerntablescanninger ).
Tidligere kunne mange af disse sTVF'er ikke acceptere korrelerede parametre fra en apply. De kunne acceptere bogstaver, variabler og modulparametre, bare ikke anvende ydre referencer. Der er stadig advarsler om dette i dokumentationen, men de er noget forældede nu.
Pointen er i hvert fald, at det nogle gange ikke er muligt for SQL Server at bestå en ansøgning ydre reference som en parameter til en sTVF. I den situation kan det give mening at materialisere en del af sTVF-resultatet i en ivrig indeksspole. Den nuværende regel giver den mulighed.
Demo
Det næste kodeeksempel viser en DMV-forespørgsel, der er konverteret fra en joinforbindelse til en apply . Ydre referencer sendes som parametre til den anden DMV:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
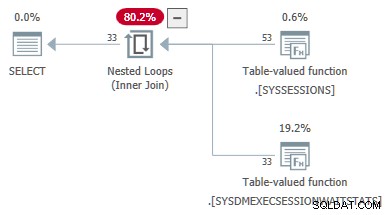
Planegenskaberne for ventestatistikken TVF viser inputparametrene. Den anden parameterværdi er angivet som en ydre reference fra sessionerne DMV:
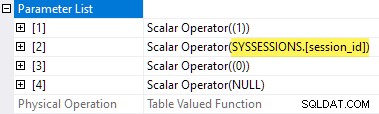
Det er en skam, at sys.dm_exec_session_wait_stats er en visning, ikke en funktion, fordi det forhindrer os i at skrive en anvend direkte.
Omskrivningen nedenfor er nok til at besejre den interne konvertering:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
Med session_id prædikater, der nu ikke bruges som parametre, SelSTVFToIdxOnFly regel er gratis at konvertere dem til en ivrig indeksspole:
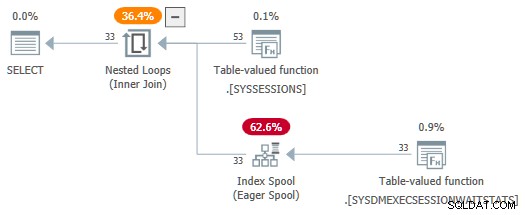
Jeg vil ikke efterlade dig med det indtryk, at vanskelige omskrivninger er nødvendige for at få en ivrig indeksspole over en DMV-kilde - det giver bare en lettere demo. Hvis du tilfældigvis støder på en forespørgsel med DMV joins, der producerer en plan med en ivrig spole, ved du i det mindste, hvordan det kom dertil.
Du kan ikke oprette indekser på DMV'er, så du skal muligvis bruge en hash eller flette join, hvis eksekveringsplanen ikke fungerer godt nok.
Rekursive CTE'er
De resterende to regler er SelIterToIdxOnFly og JoinIterToIdxOnFly . De er direkte modstykker til SelToIndexOnTheFly og JoinToIndexOnTheFly for rekursive CTE-datakilder. Disse er ekstremt sjældne efter min erfaring, så jeg vil ikke levere demoer til dem. (Bare så Iter en del af regelnavnet giver mening:Det kommer fra det faktum, at SQL Server implementerer halerekursion som indlejret iteration.)
Når der refereres til en rekursiv CTE flere gange på indersiden af en, gælder en anden regel (SpoolOnIterator ) kan cache resultatet af CTE:
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; Udførelsesplanen indeholder en sjælden Ivrig rækketællingsspole :
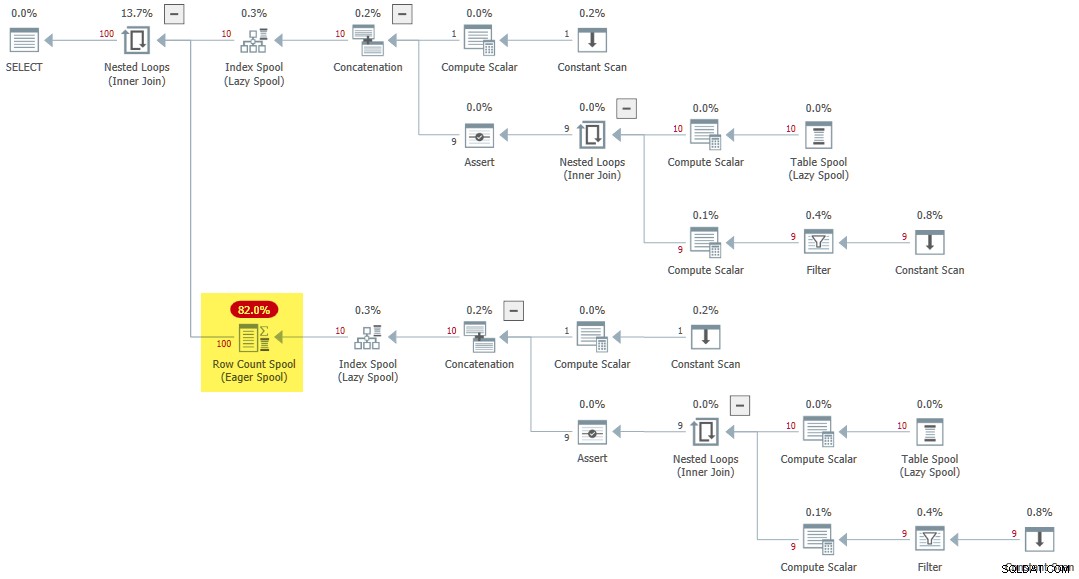
Sidste tanker
Ivrige indeksspoler er ofte et tegn på, at der mangler et nyttigt permanent indeks i databaseskemaet. Dette er ikke altid tilfældet, som de streaming-tabel-vurderede funktionseksempler viser.