[ Del 1 | Del 2 | Del 3 | Del 4 ]
MERGE sætning (introduceret i SQL Server 2008) giver os mulighed for at udføre en blanding af INSERT , UPDATE og DELETE operationer ved hjælp af en enkelt erklæring. Halloween-beskyttelsesproblemerne for MERGE er for det meste en kombination af kravene til de enkelte operationer, men der er nogle vigtige forskelle og et par interessante optimeringer, der kun gælder for MERGE .
Undgå Halloween-problemet med MERGE
Vi starter med at se igen på demo- og iscenesættelseseksemplet fra del to:
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
Som du måske husker, blev dette eksempel brugt til at vise, at en INSERT kræver Halloween-beskyttelse, når indsættelsesmåltabellen også refereres til i SELECT del af forespørgslen (EXISTS klausul i dette tilfælde). Den korrekte adfærd for INSERT sætningen ovenfor er at forsøge at tilføje begge 1234 værdier, og som følge heraf mislykkes med en PRIMARY KEY krænkelse. Uden faseadskillelse er INSERT ville fejlagtigt tilføje én værdi og fuldføre uden en fejl.
INSERT-udførelsesplanen
Ovenstående kode har én forskel fra den, der blev brugt i del to; et ikke-klynget indeks på Iscenesættelsestabellen er blevet tilføjet. INSERT eksekveringsplan stadig kræver dog Halloween-beskyttelse:
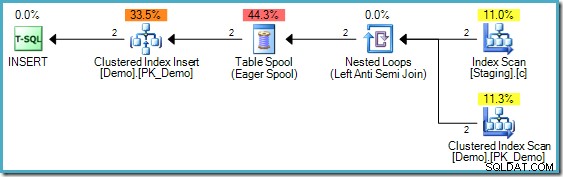
FLEDE-udførelsesplanen
Prøv nu den samme logiske indsættelse udtrykt ved hjælp af MERGE syntaks:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
Hvis du ikke er bekendt med syntaksen, er logikken der at sammenligne rækker i Staging- og Demo-tabellerne på SomeKey-værdien, og hvis der ikke findes en matchende række i måltabellen (Demo), indsætter vi en ny række. Dette har nøjagtig den samme semantik som den forrige INSERT...WHERE NOT EXISTS kode, selvfølgelig. Udførelsesplanen er dog en helt anden:
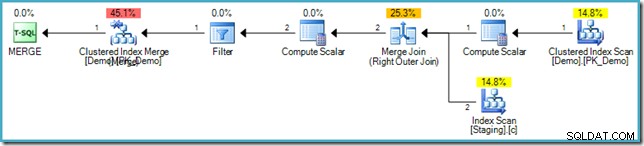
Læg mærke til manglen på en ivrig bordspole i denne plan. På trods af det producerer forespørgslen stadig den korrekte fejlmeddelelse. Det ser ud til, at SQL Server har fundet en måde at udføre MERGE på planlægge iterativt, mens du respekterer den logiske faseadskillelse, der kræves af SQL-standarden.
Optimeringen af huludfyldning
Under de rigtige omstændigheder kan SQL Server-optimeringsværktøjet genkende, at MERGE sætningen er hulfyldende , hvilket bare er en anden måde at sige, at sætningen kun tilføjer rækker, hvor der er et eksisterende hul i måltabellens nøgle.
For at denne optimering skal anvendes, skal de værdier, der bruges i WHEN NOT MATCHED BY TARGET klausul skal præcis matche ON del af USING klausul. Måltabellen skal også have en unik nøgle (et krav, der opfyldes af PRIMARY KEY i den foreliggende sag). Hvor disse krav er opfyldt, vises MERGE erklæring kræver ikke beskyttelse mod Halloween-problemet.
Selvfølgelig er MERGE sætning er logisk hverken mere eller mindre hulfyldning end den originale INSERT...WHERE NOT EXISTS syntaks. Forskellen er, at optimeringsværktøjet har fuldstændig kontrol over implementeringen af MERGE sætning, hvorimod INSERT syntaks ville kræve, at den ræsonnerede om den bredere semantik af forespørgslen. Et menneske kan nemt se, at INSERT er også huludfyldende, men optimizeren tænker ikke over tingene på samme måde, som vi gør.
For at illustrere den nøjagtige match krav, jeg nævnte, skal du overveje følgende forespørgselssyntaks, som ikke gør drage fordel af huludfyldningsoptimeringen. Resultatet er fuld Halloween-beskyttelse leveret af en ivrig bordspole:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

Den eneste forskel er multiplikationen med én i VALUES klausul – noget, der ikke ændrer logikken i forespørgslen, men som er nok til at forhindre, at huludfyldningsoptimeringen anvendes.
Udfyldning af hul med indlejrede løkker
I det foregående eksempel valgte optimeringsværktøjet at slutte sig til tabellerne ved hjælp af en Merge join. Huludfyldningsoptimeringen kan også anvendes, hvor der vælges en Nested Loops join, men dette kræver en ekstra unikhedsgaranti på kildetabellen og en indekssøgning på indersiden af samlingen. For at se dette i aktion kan vi rydde de eksisterende iscenesættelsesdata ud, tilføje entydighed til det ikke-klyngede indeks og prøve MERGE igen:
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); Den resulterende udførelsesplan bruger igen huludfyldningsoptimeringen for at undgå Halloween-beskyttelse ved at bruge en indlejret løkkesammenføjning og en indvendig sidesøgning ind i måltabellen:
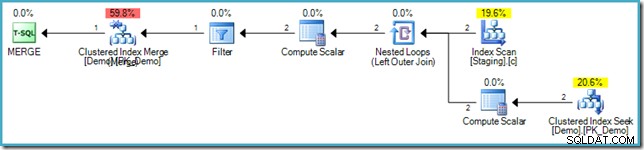
Undgå unødvendige indeksgennemgange
Hvor hulfyldningsoptimeringen gælder, kan motoren også anvende en yderligere optimering. Den kan huske den aktuelle indeksposition, mens den læser måltabellen (behandler én række ad gangen, husk) og genbrug den information, når du udfører indsættelsen, i stedet for at søge ned i b-træet for at finde indsætningsplaceringen. Begrundelsen er, at den aktuelle læseposition med stor sandsynlighed er på samme side, hvor den nye række skal indsættes. Det er meget hurtigt at kontrollere, at rækken faktisk hører hjemme på denne side, da det kun involverer at kontrollere de laveste og højeste nøgler, der i øjeblikket er gemt der.
Kombinationen af at eliminere Eager Table Spool og gemme en indeksnavigation pr. række kan give en betydelig fordel i OLTP-arbejdsbelastninger, forudsat at eksekveringsplanen hentes fra cachen. Kompileringsomkostningerne for MERGE sætninger er noget højere end for INSERT , UPDATE og DELETE , så planlæg genbrug er en vigtig overvejelse. Det er også nyttigt at sikre, at siderne har tilstrækkelig ledig plads til at rumme nye rækker, så man undgår sideopdelinger. Dette opnås typisk gennem normal indeksvedligeholdelse og tildeling af en passende FILLFACTOR .
Jeg nævner OLTP-arbejdsbelastninger, som typisk indeholder et stort antal relativt små ændringer, fordi MERGE optimeringer er muligvis ikke et godt valg, hvor et stort antal rækker behandles pr. sætning. Andre optimeringer såsom minimalt loggede INSERTs kan på nuværende tidspunkt ikke kombineres med hulfyldning. Som altid bør ydeevneegenskaberne benchmarkes for at sikre, at de forventede fordele realiseres.
Huludfyldningsoptimeringen for MERGE Indsæt kan kombineres med opdateringer og sletninger ved hjælp af yderligere MERGE klausuler; hver dataændringsoperation vurderes separat for Halloween-problemet.
Undgåelse af deltagelse
Den endelige optimering, vi vil se på, kan anvendes, hvor MERGE sætningen indeholder opdaterings- og sletningsoperationer samt en huludfyldningsindsats, og måltabellen har et unikt klynget indeks. Følgende eksempel viser en almindelig MERGE mønster, hvor umatchede rækker indsættes, og matchende rækker opdateres eller slettes afhængigt af en yderligere betingelse:
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
MERGE erklæring, der kræves for at foretage alle de nødvendige ændringer, er bemærkelsesværdigt kompakt:
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
Udførelsesplanen er ret overraskende:

Ingen Halloween-beskyttelse, ingen joinforbindelse mellem kilde- og måltabellerne, og det er ikke ofte, du vil se en Clustered Index Insert-operator efterfulgt af en Clustered Index Merge til den samme tabel. Dette er endnu en optimering rettet mod OLTP-arbejdsbelastninger med høj plangenbrug og passende indeksering.
Ideen er at læse en række fra kildetabellen og straks prøve at indsætte den i målet. Hvis der opstår en nøgleovertrædelse, undertrykkes fejlen, indsæt-operatøren udsender den modstridende række, den fandt, og denne række behandles derefter til en opdatering eller sletning ved at bruge fletplanoperatøren som normalt.
Hvis den originale indsættelse lykkes (uden en nøgleovertrædelse), fortsætter behandlingen med den næste række fra kilden (Flet-operatøren behandler kun opdateringer og sletninger). Denne optimering gavner primært MERGE forespørgsler, hvor de fleste kilderækker resulterer i en indsættelse. Igen, omhyggelig benchmarking er påkrævet for at sikre, at ydeevnen er bedre end at bruge separate udsagn.
Oversigt
MERGE statement giver flere unikke optimeringsmuligheder. Under de rigtige omstændigheder kan det undgå behovet for at tilføje eksplicit Halloween-beskyttelse sammenlignet med en tilsvarende INSERT operation, eller måske endda en kombination af INSERT , UPDATE og DELETE udsagn. Yderligere MERGE -specifikke optimeringer kan undgå gennemgangen af indeks b-træet, som normalt er nødvendig for at lokalisere indsættelsespositionen for en ny række, og kan også undgå behovet for at forbinde kilde- og måltabellerne fuldstændigt.
I den sidste del af denne serie vil vi se på, hvordan forespørgselsoptimeringsværktøjet begrunder behovet for Halloween-beskyttelse, og identificere nogle flere tricks, den kan bruge for at undgå behovet for at tilføje Ivrige bordspoler til udførelsesplaner, der ændrer data.
[ Del 1 | Del 2 | Del 3 | Del 4 ]