Vi er alle blevet forkælet af søgemaskiners evne til at "omgå" ting som stavefejl, staveforskelle i navne eller enhver anden situation, hvor søgeordet kan matche på sider, hvis forfattere måske foretrækker at bruge en anden stavemåde af et ord. Tilføjelse af sådanne funktioner til vores egne databasedrevne applikationer kan på samme måde berige og forbedre vores applikationer, og mens kommercielle relationelle databasestyringssystemer (RDBMS) tilbyder deres egne fuldt udviklede skræddersyede løsninger til dette problem, kan licensomkostningerne for disse værktøjer være uden for rækkevidde til mindre udviklere eller små softwareudviklingsfirmaer.
Man kan argumentere for, at dette kunne gøres ved hjælp af en stavekontrol i stedet for. En stavekontrol er dog typisk til ingen nytte, når man matcher en korrekt, men alternativ stavning af et navn eller et andet ord. Matching efter lyd udfylder dette funktionelle hul. Det er emnet for dagens programmeringsvejledning:hvordan man forespørger på lyde med Python ved hjælp af metafoner.
Hvad er Soundex?
Soundex blev udviklet i begyndelsen af det 20. århundrede som et middel for den amerikanske folketælling til at matche navne baseret på, hvordan de lyder. Det blev derefter brugt af forskellige telefonselskaber til at matche kundenavne. Den bliver fortsat brugt til fonetisk datamatchning den dag i dag, på trods af at den er begrænset til amerikansk engelsk stavemåder og udtaler. Det er også begrænset til engelske bogstaver. De fleste RDBMS, såsom SQL Server og Oracle, implementerer sammen med MySQL og dens varianter en Soundex-funktion, og på trods af dens begrænsninger bliver den fortsat brugt til at matche mange ikke-engelske ord.
Hvad er en dobbeltmetafon?
Metafonen Algoritmen blev udviklet i 1990, og den overvinder nogle af Soundex' begrænsninger. I 2000, en forbedret opfølger, Double Metaphone , blev udviklet. Dobbelt metafon returnerer en primær og sekundær værdi, som svarer til to måder, et enkelt ord kan udtales på. Til denne dag er denne algoritme stadig en af de bedre open source fonetiske algoritmer. Metaphone 3 blev udgivet i 2009 som en forbedring af Double Metaphone, men dette er et kommercielt produkt.
Desværre implementerer mange af de fremtrædende RDBMS nævnt ovenfor ikke Double Metaphone, og de fleste fremtrædende scriptsprog giver ikke en understøttet implementering af Double Metaphone. Python leverer dog et modul, der implementerer Double Metaphone.
Eksemplerne præsenteret i denne Python-programmeringsvejledning bruger MariaDB version 10.5.12 og Python 3.9.2, begge kører på Kali/Debian Linux.
Sådan tilføjer du dobbelt metafon til Python
Som ethvert Python-modul kan pip-værktøjet bruges til at installere Double Metaphone. Syntaksen afhænger af din Python-installation. En typisk dobbelt metafoninstallation ser ud som følgende eksempel:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Bemærk, at den ekstra store brug er bevidst. Følgende kode er et eksempel på, hvordan man bruger Double Metaphone i Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
Ovenstående Python-script giver følgende output, når det køres i dit integrerede udviklingsmiljø (IDE) eller kodeeditor:
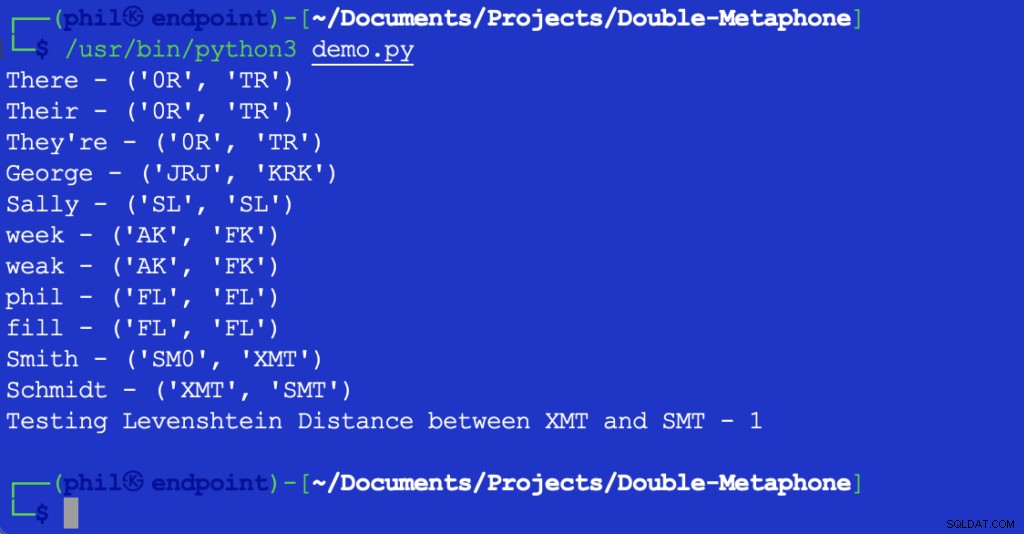
Figur 1 – Output af demoscript
Som det kan ses her, har hvert ord både en primær og sekundær fonetisk værdi. Ord, der matcher både primære eller sekundære værdier, siges at være fonetiske match. Ord, der deler mindst én fonetisk værdi, eller som deler de første par tegn i en hvilken som helst fonetisk værdi, siges at være fonetisk tæt på hinanden.
De fleste viste bogstaver svarer til deres engelske udtale. X kan svare til KS , SH eller C . 0 svarer til den th lyd i den eller der . Vokaler matches kun i begyndelsen af et ord. På grund af det utallige antal forskelle i regionale accenter, er det ikke muligt at sige, at ord kan være et objektivt nøjagtigt match, selvom de har de samme fonetiske værdier.
Sammenligning af fonetiske værdier med Python
Der er talrige onlineressourcer, der kan beskrive den fulde funktion af Double Metaphone-algoritmen; dette er dog ikke nødvendigt for at bruge det, fordi vi er mere interesserede i at sammenligne de beregnede værdier, mere end vi er interesserede i at beregne værdierne. Som nævnt tidligere, hvis der er mindst én værdi til fælles mellem to ord, kan det siges, at disse værdier er fonetiske match , og fonetiske værdier, der er lignende er fonetisk tætte .
Det er nemt at sammenligne absolutte værdier, men hvordan kan strenge bestemmes til at være ens? Selvom der ikke er nogen tekniske begrænsninger, der forhindrer dig i at sammenligne strenge med flere ord, er disse sammenligninger normalt upålidelige. Hold dig til at sammenligne enkelte ord.
Hvad er Levenshtein-afstande?
Levenshtein-distancen mellem to strenge er antallet af enkelte tegn, der skal ændres i én streng for at få den til at matche den anden streng. Et par strenge, der har en lavere Levenshtein-afstand, minder mere om hinanden end et par strenge, der har en højere Levenshtein-afstand. Levenshtein Distance ligner Hamming Distance , men sidstnævnte er begrænset til strenge af samme længde, da dobbeltmetafonens fonetiske værdier kan variere i længde, giver det mere mening at sammenligne disse ved at bruge Levenshtein-afstanden.
Python Levenshtein Distance Library
Python kan udvides til at understøtte Levenshtein-afstandsberegninger via et Python-modul:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Bemærk, at som med installationen af DoubleMetaphone ovenfor syntaksen for opkaldet til pip kan variere. Python-Levenshtein-modulet giver langt mere funktionalitet end blot beregninger af Levenshtein-afstand.
Koden nedenfor viser en test for Levenshtein Afstandsberegning i Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
Udførelse af dette script giver følgende output:
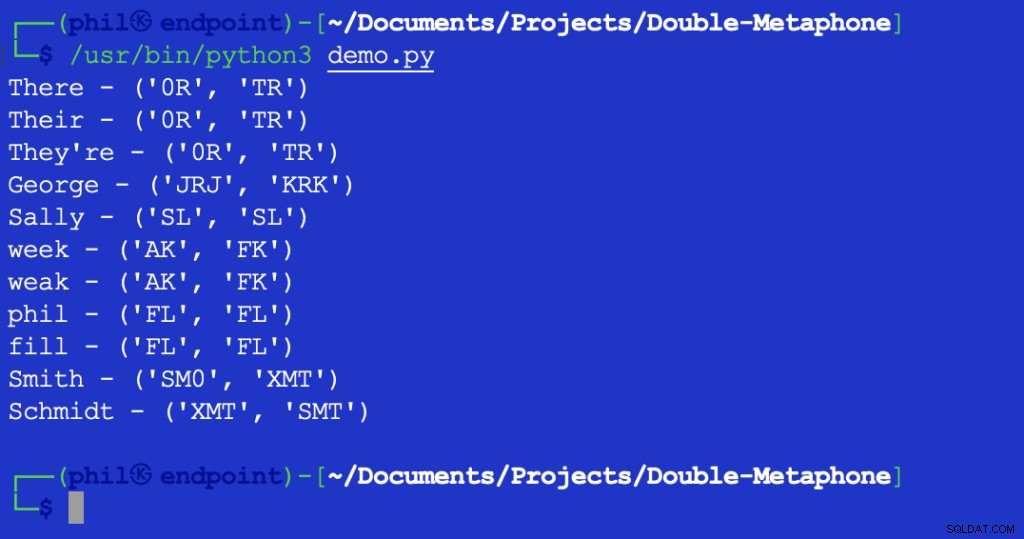
Figur 2 – Output af Levenshtein Distance test
Den returnerede værdi af 1 angiver, at der er ét tegn mellem XMT og SMT det er forskelligt. I dette tilfælde er det det første tegn i begge strenge.
Sammenligning af dobbeltmetafoner i Python
Det følgende er ikke alle-og-ende-alt af fonetiske sammenligninger. Det er simpelthen en af mange måder at udføre sådan en sammenligning på. For effektivt at sammenligne den fonetiske nærhed af to givne strenge, så skal hver dobbelt metafon fonetisk værdi af en streng sammenlignes med den tilsvarende dobbelt metafon fonetiske værdi af en anden streng. Da begge fonetiske værdier af en given streng vægtes lige meget, vil gennemsnittet af disse sammenligningsværdier give en rimelig god tilnærmelse af fonetisk nærhed:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Hvor:
- DM1(1) :Første dobbelte metafonværdi af streng 1,
- DM1(2) :Anden dobbelt metafonværdi af streng 1
- DM2(1) :Første dobbelte metafonværdi af streng 2
- DM2(2) :Anden dobbelt metafonværdi af streng 2
- PN :Fonetisk nærhed, hvor lavere værdier er nærmere end højere værdier. En nulværdi indikerer fonetisk lighed. Den højeste værdi for dette er antallet af bogstaver i den korteste streng.
Denne formel opdeles i tilfælde som Schmidt (XMT, SMT) og Smith (SM0, XMT) hvor den første fonetiske værdi af den første streng matcher den anden fonetiske værdi af den anden streng. I sådanne situationer vil både Schmidt og Smith kan anses for at være fonetisk ens på grund af den fælles værdi. Koden for nærhedsfunktionen bør kun anvende formlen ovenfor, når alle fire fonetiske værdier er forskellige. Formlen har også svagheder, når man sammenligner strenge af forskellig længde.
Bemærk, der er ingen enestående effektiv måde at sammenligne strenge af forskellig længde på, selvom beregning af Levenshtein-afstanden mellem to strenge faktorer i forskelle i strenglængde. En mulig løsning ville være at sammenligne begge strenge op til længden af den korteste af de to strenge.
Nedenfor er et eksempel på et kodestykke, der implementerer koden ovenfor, sammen med nogle testeksempler:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
Eksemplet på Python-koden giver følgende output:
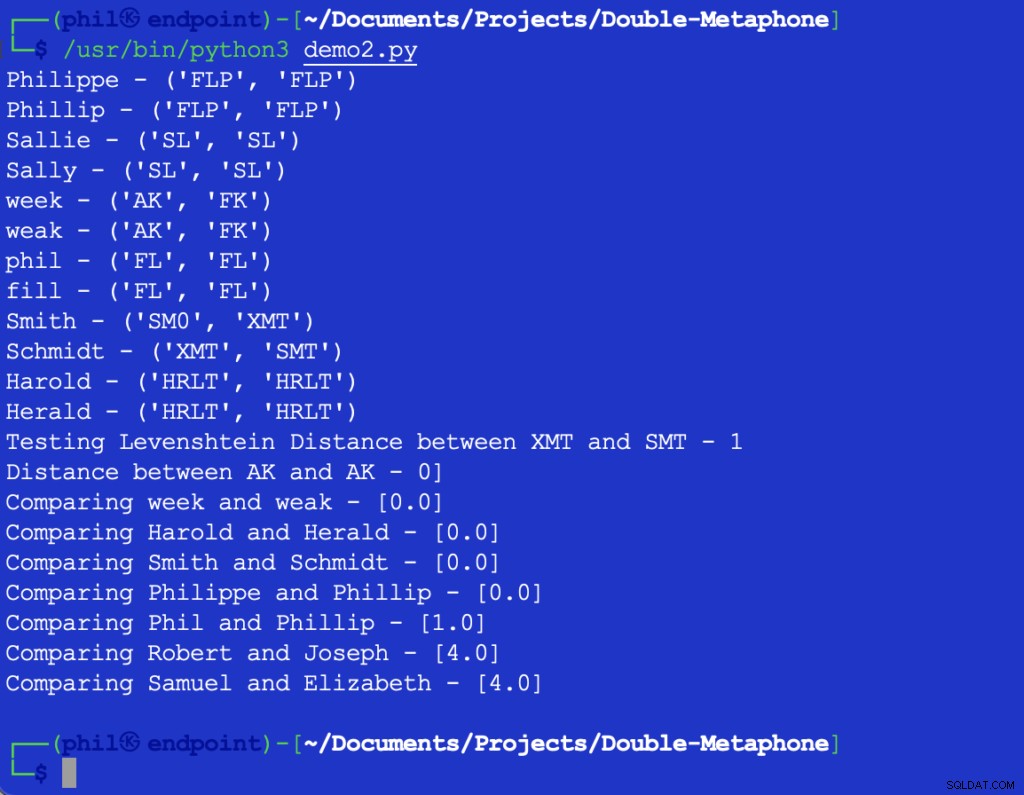
Figur 3 – Output af nærhedsalgoritmen
Prøvesættet bekræfter den generelle tendens, at jo større forskelle i ord er, jo højere output af Nærhed funktion.
Database-integration i Python
Ovenstående kode bryder den funktionelle kløft mellem en given RDBMS og en Double Metaphone implementering. Oven i dette ved at implementere Nærhed funktion i Python, bliver det nemt at erstatte, hvis en anden sammenligningsalgoritme foretrækkes.
Overvej følgende MySQL/MariaDB-tabel:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
I de fleste databasedrevne applikationer komponerer middlewaren SQL-sætninger til styring af dataene, herunder indsættelse af dem. Følgende kode vil indsætte nogle eksempelnavne i denne tabel, men i praksis kan enhver kode fra en web- eller desktopapplikation, som indsamler sådanne data, gøre det samme.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
Kørsel af denne kode udskriver ikke noget, men det udfylder testtabellen i databasen til den næste liste, der skal bruges. Forespørgsel i tabellen direkte i MySQL-klienten kan bekræfte, at koden ovenfor virkede:
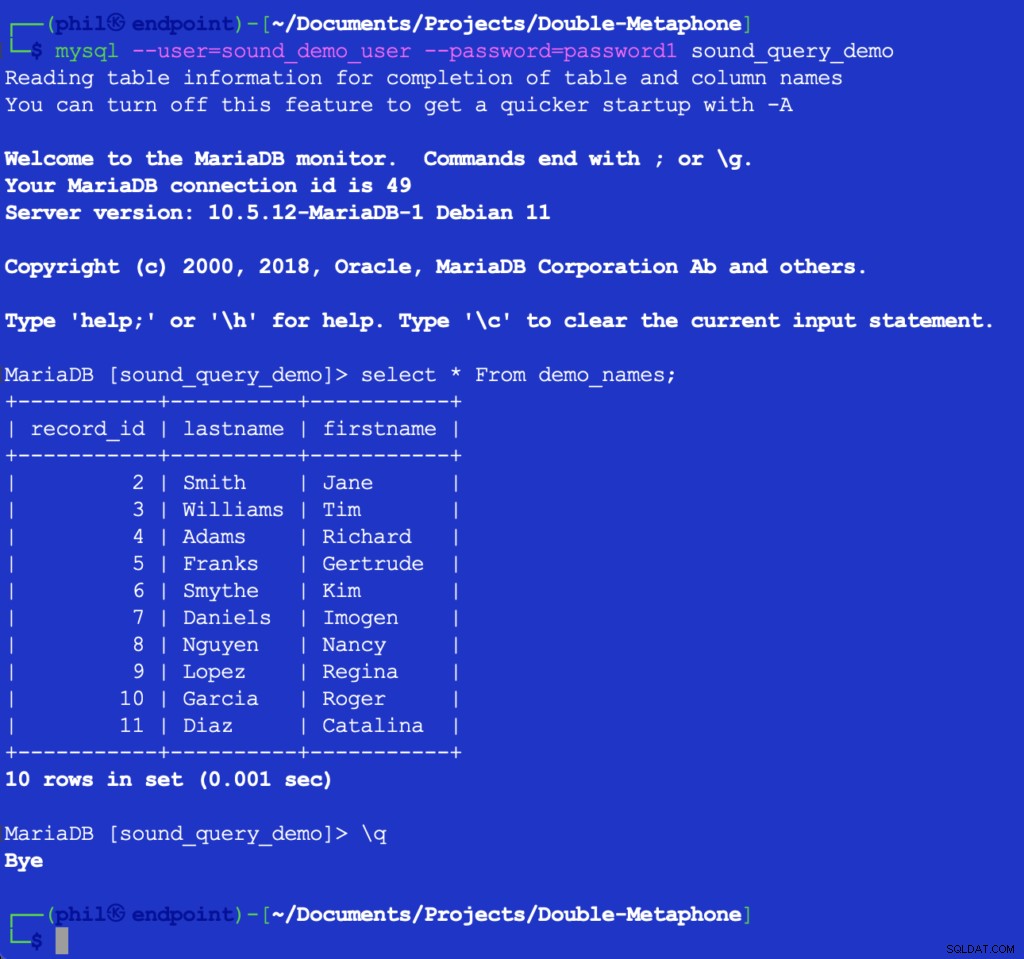
Figur 4- De indsatte tabeldata
Koden nedenfor vil føre nogle sammenligningsdata ind i tabeldataene ovenfor og udføre en nærhedssammenligning mod dem:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
Ved at køre denne kode får vi outputtet nedenfor:
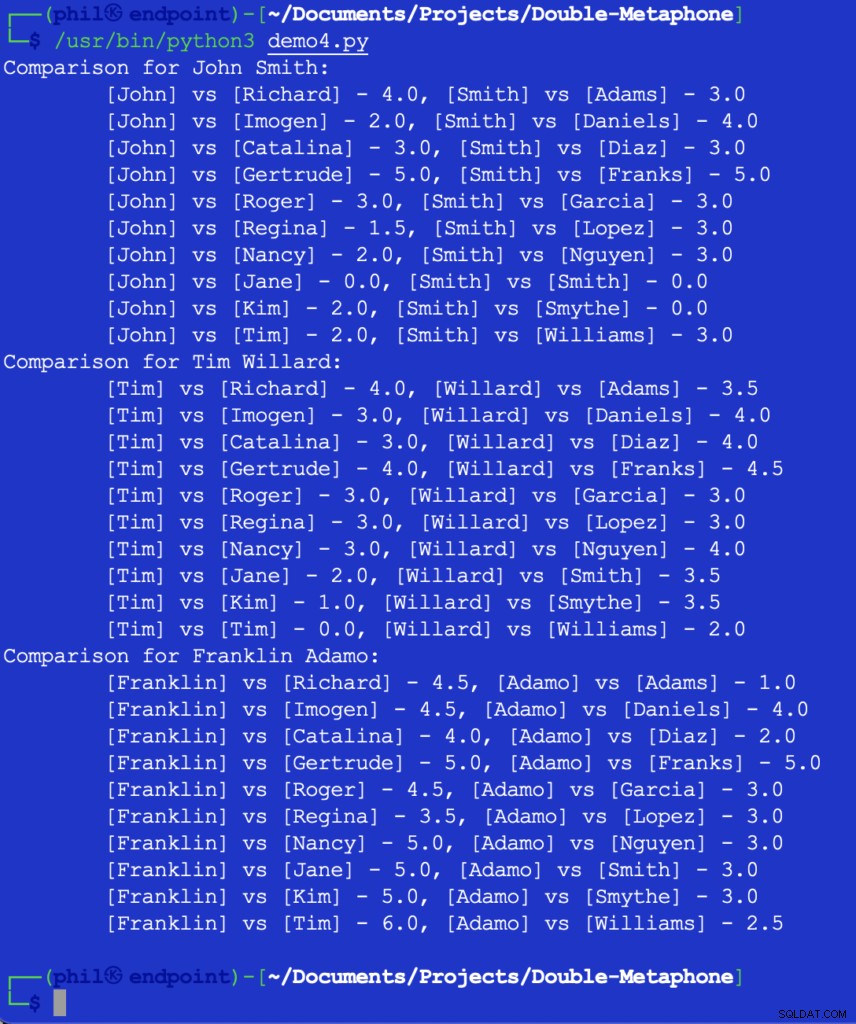
Figur 5 – Resultater af nærhedssammenligningen
På dette tidspunkt vil det være op til udvikleren at beslutte, hvad tærsklen vil være for, hvad der udgør en nyttig sammenligning. Nogle af tallene ovenfor kan virke uventede eller overraskende, men en mulig tilføjelse til koden kan være et HVIS sætning for at bortfiltrere enhver sammenligningsværdi, der er større end 2 .
Det kan være værd at bemærke, at selve de fonetiske værdier ikke er gemt i databasen. Dette skyldes, at de er beregnet som en del af Python-koden, og der er ikke et reelt behov for at gemme disse nogen steder, da de kasseres, når programmet afsluttes, dog kan en udvikler finde værdi i at gemme disse i databasen og derefter implementere sammenligningen funktion i databasen en lagret procedure. Men den største ulempe ved dette er tab af kodeportabilitet.
Sidste tanker om at forespørge data efter lyd med Python
Sammenligning af data efter lyd ser ikke ud til at få den "kærlighed" eller opmærksomhed, som sammenligning af data ved billedanalyse kan få, men hvis en applikation skal håndtere flere enslydende varianter af ord på flere sprog, kan det være meget nyttigt. værktøj. Et nyttigt træk ved denne type analyse er, at en udvikler ikke behøver at være en lingvistik eller fonetisk ekspert for at kunne bruge disse værktøjer. Udvikleren har også stor fleksibilitet til at definere, hvordan sådanne data kan sammenlignes; sammenligningerne kan justeres baseret på applikationen eller forretningslogikkens behov.
Forhåbentlig vil dette studieområde få mere opmærksomhed i forskningssfæren, og der vil være flere dygtige og robuste analyseværktøjer fremover.