Indekserede visninger kan oprettes i enhver udgave af SQL Server, men der er en række adfærd, du skal være opmærksom på, hvis du vil få mest muligt ud af dem.
Automatisk statistik kræver et NOEXPAND-tip
SQL Server kan oprette statistik automatisk for at hjælpe med kardinalitetsestimat og omkostningsbaseret beslutningstagning under forespørgselsoptimering. Denne funktion fungerer med indekserede visninger såvel som basistabeller, men kun hvis visningen er eksplicit navngivet i forespørgslen og NOEXPAND tip er angivet. (Der er altid et statistikobjekt tilknyttet hvert indeks på en visning, det er den automatiske generering og vedligeholdelse af statistik, der ikke er forbundet med et indeks, vi taler om her.)
Hvis du er vant til at arbejde med ikke-Enterprise-udgaver af SQL Server, har du måske aldrig bemærket denne adfærd før. Lavere udgaver af SQL Server kræver NOEXPAND tip til at lave en forespørgselsplan, der får adgang til en indekseret visning. Når NOEXPAND er angivet, oprettes automatisk statistik på indekserede visninger nøjagtigt som det sker med almindelige tabeller.
Eksempel – Standard Edition med NOEXPAND
Ved at bruge SQL Server 2012 Standard Edition og Adventure Works-eksempeldatabasen opretter vi først en visning, der forbinder to salgstabeller og beregner den samlede ordremængde pr. kunde og produkt:
OPRET VISNING dbo.CustomerOrdersWITH SCHEMABINDING ASSELECT SOH.CustomerID, SOD.ProductID, OrderQty =SUM(SOD.OrderQty), NumRows =COUNT_BIG(*)FROM Sales.SalesOrderDetail AS SODJOIN Sales.SalesOrderONSOD.SalesOrderONSOD.SalesOrderON .SalesOrderIDGROUP BY SOH.CustomerID, SOD.ProductID;
For at denne visning skal understøtte statistik, er vi nødt til at materialisere den ved at tilføje et unikt klynget indeks. Kombinationen af kunde- og produkt-id er garanteret unik i visningen (per definition), så vi vil bruge det som nøglen. Vi kunne angive de to kolonner begge veje i indekset, men forudsat at vi forventer, at flere forespørgsler filtreres efter produkt, gør vi produkt-id til den førende kolonne. Denne handling opretter også indeksstatistik med et histogram bygget ud fra produkt-id-værdier.
OPRET UNIKT KLUSTERET INDEX cuq PÅ dbo.CustomerOrders (ProductID, CustomerID);
Vi bliver nu bedt om at skrive en forespørgsel, der viser det samlede antal ordrer pr. kunde for et bestemt produktsortiment. Vi forventer, at en eksekveringsplan, der bruger den indekserede visning, vil være en effektiv strategi, fordi den vil undgå en sammenføjning og operere på data, der allerede er delvist aggregeret. Da vi bruger SQL Server Standard Edition, skal vi specificere visningen eksplicit og bruge en NOEXPAND tip til at lave en forespørgselsplan, der får adgang til den indekserede visning:
VÆLG CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders AS CO WITH (NOEXPAND)WHERE CO.ProductID MELLEM 711 OG 718GROUP BY CO.CustomerID;
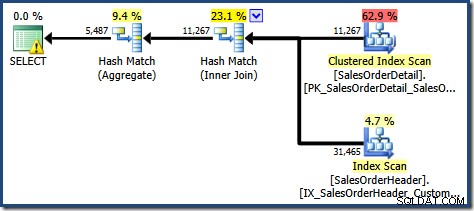
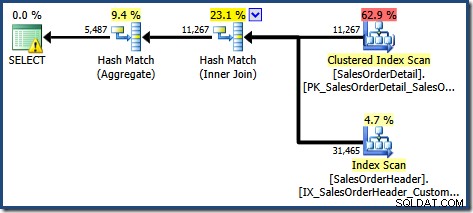
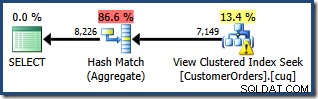
Den producerede udførelsesplan viser en søgning på den indekserede visning for at finde rækker for produkterne af interesse efterfulgt af en aggregering for at beregne den samlede mængde pr. kunde:
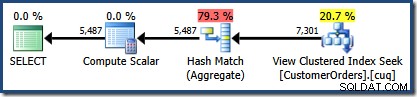
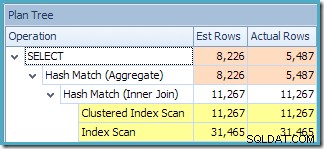
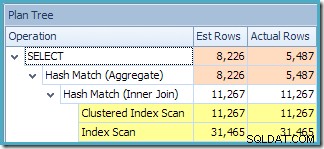
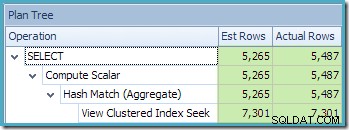
Plantræ-visningen af SQL Sentry Plan Explorer viser, at kardinalitetsestimat er nøjagtigt korrekt for den indekserede visningssøgning og meget god for resultatet af aggregatet:
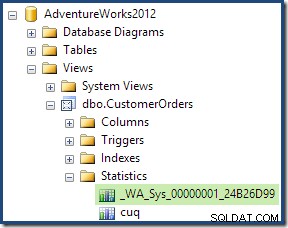
Som en del af kompilerings- og optimeringsprocessen for denne forespørgsel oprettede SQL Server et ekstra statistikobjekt i kolonnen Kunde-id i den indekserede visning. Denne statistik er bygget, fordi det forventede antal og fordelingen af kunde-id'er kan være vigtig, for eksempel ved valg af en aggregeringsstrategi. Vi kan se den nye statistik ved hjælp af Management Studio Object Explorer:
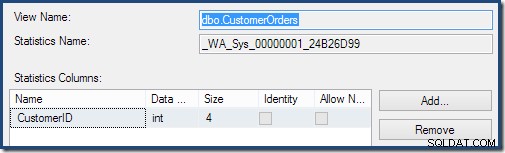
Dobbeltklik på statistikobjektet bekræfter, at det er bygget fra kolonnen Kunde-id på visningen (ikke en basistabel):
Indekserede visninger kan forbedre kardinalitetsestimat
Stadig ved at bruge Standard Edition, dropper og genskaber vi nu den indekserede visning (hvilket også dropper visningsstatistikken) og udfører forespørgslen igen, denne gang med NOEXPAND tip kommenteret:
VÆLG CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders AS CO -WITH (NOEXPAND)HERE CO.ProductID MELLEM 711 OG 718GROUP BY CO.CustomerID;
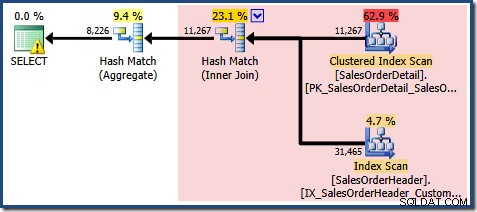
Som forventet ved brug af Standard Edition uden NOEXPAND , fungerer den resulterende forespørgselsplan på basistabellerne i stedet for visningen direkte:

Advarselstrekanten på rodoperatøren i planen ovenfor advarer os om et potentielt nyttigt indeks i tabellen Salgsordredetaljer, hvilket ikke er vigtigt for vores nuværende formål. Denne kompilering skaber ingen statistik på den indekserede visning. Den eneste statistik på visningen efter forespørgselskompilering er den, der er knyttet til det klyngede indeks:
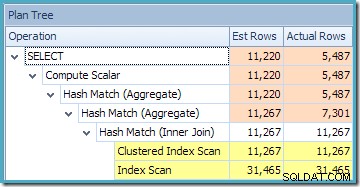
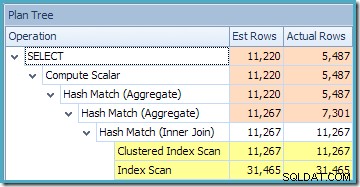
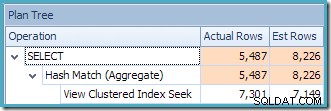
Plantræ-visningen for forespørgslen viser, at kardinalitetsestimat er korrekt for de to tabelscanninger og joinforbindelsen, men en del værre for de andre planoperatører:
Brug af den indekserede visning med en NOEXPAND tip resulterede i mere nøjagtige estimater for vores testforespørgsel, fordi oplysninger af bedre kvalitet var tilgængelige fra statistikker om visningen – især statistikken forbundet med visningsindekset.
Som en generel regel forringes nøjagtigheden af statistisk information ret hurtigt, når den passerer igennem og ændres af forespørgselsplanoperatører. Simple joins er ofte ikke så dårlige i denne henseende, men information om resultatet af en aggregering er ofte ikke bedre end et kvalificeret gæt. At forsyne forespørgselsoptimeringsværktøjet med mere nøjagtige oplysninger ved hjælp af statistik over indekserede visninger kan være en nyttig teknik til at øge planens kvalitet og robusthed.
En visning uden NOEXPAND kan give en dårligere plan
Forespørgselsplanen vist ovenfor (Standard Edition, uden NOEXPAND ) er faktisk mindre optimal, end hvis vi selv havde skrevet forespørgslen mod basistabellerne, i stedet for at lade forespørgselsoptimeringsværktøjet udvide visningen. Forespørgslen nedenfor udtrykker det samme logiske krav, men refererer ikke til visningen:
VÆLG SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD PÅ SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID MELLEM 711 OG 718GROUP. BY SID.Denne forespørgsel producerer følgende eksekveringsplan:
Denne plan indeholder en aggregeringsoperation mindre end før. Når visningsudvidelsen blev brugt, var forespørgselsoptimeringsværktøjet desværre ikke i stand til at fjerne en redundant aggregeringsoperation, hvilket resulterede i en mindre effektiv eksekveringsplan. Det endelige kardinalitetsestimat for den nye forespørgsel er også lidt bedre, end da den indekserede visning blev refereret uden
NOEXPAND:
Ikke desto mindre er de bedste estimater stadig dem, der produceres, når der refereres til den indekserede visning med
NOEXPAND(gentaget nedenfor for nemheds skyld):
Enterprise Edition og Vis Matching
På en Enterprise Edition-instans kan forespørgselsoptimeringsværktøjet muligvis bruge en indekseret visning, selvom forespørgslen ikke nævner visningen eksplicit. Hvis optimeringsværktøjet er i stand til at matche en del af forespørgselstræet til en indekseret visning, kan den vælge at gøre det, baseret på dens estimering af omkostningerne ved at bruge visningen eller ej. View-matching-logikken er rimelig smart, men den har grænser, som er ret nemme at ramme i praksis. Selv hvor visningsmatchning er vellykket, kan optimeringsværktøjet stadig blive vildledt af unøjagtige omkostningsestimater.
EXPAND VIEWS-forespørgselstip
Startende med de sjældnere af mulighederne, kan der være tilfælde, hvor en forespørgsel refererer til en indekseret visning, men en bedre plan ville opnås ved at få adgang til basistabellerne i stedet. Under disse omstændigheder giver forespørgselshintet
EXPAND VIEWSkan bruges:VÆLG CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders AS COWHERE CO.ProductID MELLEM 711 OG 718GROUP BY CO.CustomerIDOPTION (UDVID VISNINGER);På Enterprise Edition producerer denne forespørgsel den samme plan, som den ses på Standard Edition, når
NOEXPANDtip blev udeladt (inklusive den redundante aggregeringsoperation):
Som en sidebemærkning er
EXPAND VIEWStip er dårligt navngivet, efter min mening. SQL Server udvider altid visningsdefinitioner i en forespørgsel, medmindreNOEXPANDtip er angivet.EXPAND VIEWStip deaktiverer regler i optimeringsværktøjet, der kan matche dele af det udvidede træ tilbage til indekserede visninger. I mangel af nogen af hints udvider SQL Server først en visning til dens basistabeldefinition og overvejer senere at matche tilbage til indekserede visninger. Et bedre navn tilEXPAND VIEWStip kan have væretDISABLE INDEXED VIEW MATCHING, fordi det er det, det gør.
EXPAND VIEWStip bruges sandsynligvis oftest til at forhindre en forespørgsel mod basistabeller i at blive matchet til en indekseret visning:VÆLG SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD PÅ SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID MELLEM 711 OG 718OPGRUPPEN BY SOD.UDSÆTNINGSGRUPPE (UDVENDIGGRUPPEN);>Forespørgselstipet resulterer i den samme eksekveringsplan og estimater, som vi så, da vi brugte Standard Edition, og den samme forespørgsel, der kun er baseret på en tabel:
Enterprise View Matching og statistik
Selv i Enterprise Edition oprettes ikke-indeksvisningsstatistikker stadig kun, hvis
NOEXPANDhint er brugt. For at være helt klar over det, resulterer funktionen kun Enterprise-visningsmatchning aldrig i, at visningsstatistikker oprettes eller opdateres. Denne uintuitive adfærd er værd at undersøge lidt, da den kan have overraskende bivirkninger.Vi udfører nu vores grundlæggende forespørgsel i forhold til visningen af en Enterprise Edition-instans uden nogen antydninger:
VÆLG CO.CustomerID, SUM(CO.OrderQty)FRA dbo.CustomerOrders AS COWHERE CO.ProductID MELLEM 711 OG 718GROUP BY CO.CustomerID;
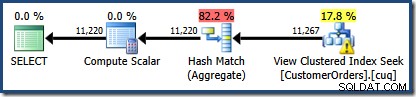
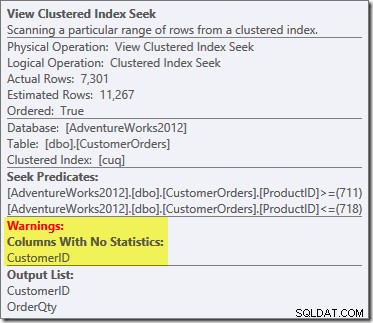
En ny ting er advarselstrekanten på View Clustered Index Seek. Værktøjstippet viser detaljerne:
Vi brugte ikke en
NOEXPANDtip, så statistik på kunde-id-kolonnen i den indekserede visning blev ikke automatisk oprettet. Statistikken om kunde-id er faktisk ikke særlig vigtig i dette forenklede eksempel, men det vil ikke altid være tilfældet.Nygerrige vurderinger af kardinalitet
Den anden ting af interesse er, at kardinalitetsestimaterne ser ud til at være værre end nogen anden sag, vi er stødt på hidtil, inklusive eksemplerne i standardudgaven.
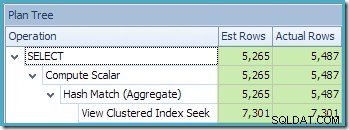
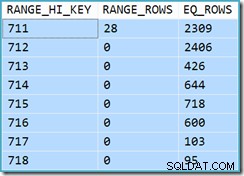
Det er i starten svært at se, hvor kardinalitetsestimatet for View Clustered Index Seek (11.267) kom fra. Vi forventer, at estimatet er baseret på produkt-id-histogramoplysninger fra de statistikker, der er knyttet til visningsklyngeindekset. Den relevante del af dette histogram er vist nedenfor:
DBCC SHOW_STATISTICS ('dbo.CustomerOrders', 'cuq') MED HISTOGRAM;
I betragtning af, at tabellen ikke er blevet ændret siden statistikken blev oprettet, ville vi forvente, at estimatet er en simpel sum af RANGE_ROWS og EQ_ROWS for produkt-id-værdier mellem 711 og 718 (bemærk, at estimatet skal udelukke de 28 RANGE_ROWS vist mod 711-indgangen da disse rækker findes under 711 nøgleværdien). Summen af de viste EQ_ROWS er 7.301. Dette er præcis antallet af rækker, der faktisk returneres af visningen - så hvor kom estimatet på 11.267 fra?
Svaret ligger i, hvordan visningsmatching fungerer i øjeblikket. Vores forespørgsel specificerede ikke
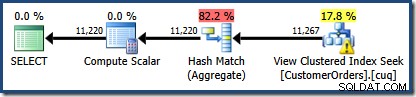
NOEXPANDtip, så indledende kardinalitetsestimater er baseret på det visningsudvidede forespørgselstræ. Dette er nemmest at se ved at se igen på den estimerede plan for den samme forespørgsel medEXPAND VIEWSspecificeret:
Det røde skraverede område repræsenterer den del af træet, der er erstattet af visningsmatchende aktivitet. Udgangskardinaliteten fra dette område er 11.267. Den uskyggede del med estimatet på 11.220 er upåvirket af visningsmatchning. Dette er præcis de estimater, vi søgte at forklare:
Visningsmatchning erstattede simpelthen det røde skraverede område med en logisk ækvivalent søgning på den indekserede visning. Den brugte ikke statistiske oplysninger fra visningen til at genberegne kardinalitetsestimatet.
Til en vis grad kan du sikkert forstå, hvorfor det kan fungere på denne måde:Generelt er der ringe grund til at forvente, at et estimat beregnet ud fra et sæt statistiske oplysninger er bedre end et andet. Der kunne argumenteres for, at indekserede visningsstatistikker er mere tilbøjelige til at være nøjagtige her sammenlignet med den post-sammenføjning afledte statistik i det røde skraverede område, men det kan være vanskeligt at generalisere det, eller at redegøre korrekt for, hvor hurtigt forskellige kilder til statistiske oplysninger kan blive forældede, efterhånden som de underliggende data ændres.
Man kan også argumentere for, at hvis vi var så sikre på, at den indekserede visningsinformation var bedre, ville vi have brugt en
NOEXPANDtip.Endnu flere nysgerrige vurderinger af kardinalitet
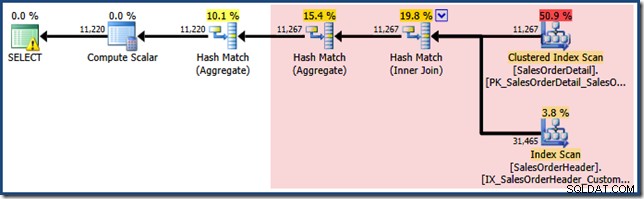
En endnu mere interessant situation opstår med Enterprise Edition, hvis vi skriver forespørgslen mod basistabellerne og stoler på automatiseret visningsmatchning:
VÆLG SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD PÅ SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID MELLEM 711 OG 718GROUP. BY SID.
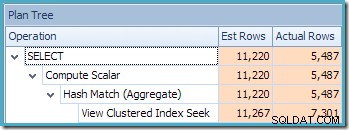
Den manglende statistikadvarsel er den samme som før og har samme forklaring. Den mere interessante funktion er, at vi nu har et lavere estimat for antallet af rækker produceret af View Clustered Index Seek (7.149) og et øget estimat for antallet af rækker, der returneres fra aggregeringen (8.226).
For at understrege pointen ser denne forespørgselsplan ud til at være baseret på ideen om, at 7.149 kilderækker kan aggregeres for at producere 8.226 rækker!
En del af forklaringen er den samme som før.
EXPAND VIEWSforespørgselsplan, der viser det røde område, som vil blive erstattet af visningsmatchning, er vist nedenfor:
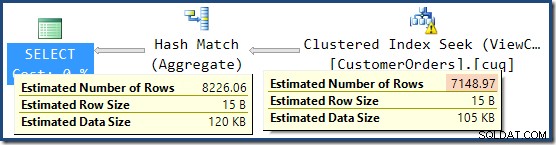
Dette forklarer, hvor det endelige estimat på 8.226 kommer fra, men hvad med estimatet på 7.149 rækker? Efter den logik, der er set tidligere, ser det ud til, at visningen burde vise et estimat på 11.267 rækker?
Svaret er, at estimatet på 7.149 er et gæt. Ja virkelig. Den indekserede visning indeholder i alt 79.433 rækker. Den magiske gætprocent for produkt-ID MELLEM prædikatet er 9 % – hvilket giver 0,09 * 79433 =7148,97 rækker. SSMS-forespørgselsplanen viser, at denne beregning er nøjagtigt korrekt, selv før afrunding:
I denne situation ser SQL Server-optimeringsværktøjet ud til at have foretrukket et gæt baseret på indekseret visningskardinalitet frem for post-join-kardinalitetsestimatet fra det erstattede undertræ. Nysgerrig.
Oversigt
Brug af
NOEXPANDtip garanterer, at en indekseret visning vil blive brugt i den endelige forespørgselsplan, og gør det muligt automatisk at oprette, vedligeholde og bruge ikke-indeksstatistikker af forespørgselsoptimeringsværktøjet. Brug afNOEXPANDsikrer også, at de oprindelige kardinalitetsestimater er baseret på indekserede visningsoplysninger i stedet for at være afledt fra basistabeller.Hvis
NOEXPANDikke er angivet, erstattes visningsreferencer altid med deres basistabeldefinitioner, før forespørgselskompileringen begynder (og derfor før den indledende kardinalitetsestimat). Kun i Enterprise SKU'er kan indekserede visninger erstattes tilbage i forespørgselstræet senere i optimeringsprocessen.
EXPAND VIEWSforespørgselstip forhindrer optimeringsværktøjet i at udføre Enterprise Edition-indekseret visningsmatchning. Dette gælder uanset om forespørgslen oprindeligt refererede til en indekseret visning eller ej. Når visningsmatchning udføres, kan et eksisterende kardinalitetsestimat blive erstattet med et gæt under nogle omstændigheder.Statistikker vist som manglende på en indekseret visning kan oprettes manuelt, men optimeringsværktøjet vil generelt ikke bruge dem til forespørgsler, der ikke bruger en
NOEXPANDtip.Brug af indekserede visninger kan forbedre kardinalitetsestimat, især hvis visningen indeholder sammenkædninger eller aggregeringer. Forespørgsler har den bedste chance for at drage fordel af mere nøjagtige visningsstatistikker, hvis
NOEXPANDer angivet.