NULL-håndtering er et af de vanskeligere aspekter af datamodellering og datamanipulation med SQL. Lad os starte med det faktum, at et forsøg på at forklare præcis hvad en NULL er er ikke trivielt i sig selv. Selv blandt folk, der har et godt greb om relationsteori og SQL, vil du høre meget stærke meninger både for og imod at bruge NULL'er i din database. Kan du lide dem eller ej, som databasepraktiker er du ofte nødt til at håndtere dem, og i betragtning af at NULL'er tilføjer kompleksitet til din SQL-kodeskrivning, er det en god idé at prioritere at forstå dem godt. På denne måde kan du undgå unødvendige fejl og faldgruber.
Denne artikel er den første i en serie om NULL-kompleksiteter. Jeg starter med dækning af, hvad NULLs er, og hvordan de opfører sig i sammenligninger. Jeg dækker herefter NULL behandlingsinkonsekvenser i forskellige sprogelementer. Til sidst dækker jeg manglende standardfunktioner relateret til NULL-håndtering i T-SQL og foreslår alternativer, der er tilgængelige i T-SQL.
Det meste af dækningen er relevant for enhver platform, der implementerer en dialekt af SQL, men i nogle tilfælde nævner jeg aspekter, der er specifikke for T-SQL.
I mine eksempler vil jeg bruge en prøvedatabase kaldet TSQLV5. Du kan finde scriptet, der opretter og udfylder denne database her, og dets ER-diagram her.
NULL som en markør for en manglende værdi
Lad os starte med at forstå, hvad NULLs er. I SQL er en NULL en markør eller en pladsholder for en manglende værdi. Det er SQLs forsøg på at repræsentere en virkelighed i din database, hvor en bestemt attributværdi nogle gange er til stede og nogle gange mangler. Antag for eksempel, at du skal gemme medarbejderdata i en medarbejdertabel. Du har attributter til fornavn, mellemnavn og efternavn. Fornavn og efternavn attributter er obligatoriske, og derfor definerer du dem som ikke at tillade NULL. Attributten mellemnavn er valgfri, og derfor definerer du den som at tillade NULL.
Hvis du undrer dig over, hvad den relationelle model har at sige om manglende værdier, så troede modellens skaber Edgar F. Codd på dem. Faktisk skelnede han endda mellem to slags manglende værdier:Missing But Applicable (A-Values markør) og Missing But Inapplicable (I-Values markør). Hvis vi tager attributten mellemnavn som eksempel, i et tilfælde, hvor en medarbejder har et mellemnavn, men af hensyn til privatlivets fred vælger ikke at dele oplysningerne, vil du bruge A-værdi-markøren. I et tilfælde, hvor en medarbejder slet ikke har et mellemnavn, vil du bruge I-Values-markøren. Her kunne den selvsamme egenskab nogle gange være relevant og til stede, nogle gange Manglende men anvendelig og nogle gange Missing But Inapplicable. Andre tilfælde kunne være mere tydelige, idet de kun understøtter én slags manglende værdier. Antag for eksempel, at du har en ordretabel med en attribut kaldet shippeddate, der indeholder ordrens forsendelsesdato. En ordre, der blev afsendt, vil altid have en tilstedeværende og relevant afsendelsesdato. Det eneste tilfælde for ikke at have en kendt forsendelsesdato ville være for ordrer, der ikke var afsendt endnu. Så her skal enten en relevant shippeddate-værdi være til stede, eller også skal I-Values-markøren bruges.
Designerne af SQL valgte ikke at skelne mellem anvendelige og uanvendelige manglende værdier og forsynede os med NULL som en markør for enhver form for manglende værdi. For det meste var SQL designet til at antage, at NULL'er repræsenterer den manglende men anvendelige form for manglende værdi. Derfor, især når din brug af NULL er som en pladsholder for en uanvendelig værdi, er standard SQL NULL-håndtering muligvis ikke den, du opfatter som korrekt. Nogle gange bliver du nødt til at tilføje eksplicit NULL-håndteringslogik for at få den behandling, du anser for at være den rigtige for dig.
Som en bedste praksis, hvis du ved, at en attribut ikke skal tillade NULL'er, skal du sørge for at håndhæve den med en NOT NULL-begrænsning som en del af kolonnedefinitionen. Det er der et par vigtige grunde til. En grund er, at hvis du ikke håndhæver dette, på et eller andet tidspunkt, vil NULLs komme dertil. Det kan være resultatet af en fejl i applikationen eller import af dårlige data. Ved at bruge en begrænsning ved du, at NULLs aldrig kommer til bordet. En anden grund er, at optimeringsværktøjet evaluerer begrænsninger som NOT NULL for bedre optimering, undgår unødvendigt arbejde med at lede efter NULL'er og aktiverer visse transformationsregler.
Sammenligninger, der involverer NULL
Der er noget trickiness i SQLs evaluering af prædikater, når NULL'er er involveret. Jeg vil først dække sammenligninger, der involverer konstanter. Senere vil jeg dække sammenligninger, der involverer variabler, parametre og kolonner.
Når du bruger prædikater, der sammenligner operander i forespørgselselementer som WHERE, ON og HAVING, afhænger de mulige resultater af sammenligningen af, om nogen af operanderne kan være en NULL. Hvis du med sikkerhed ved, at ingen af operanderne kan være NULL, vil prædikatets udfald altid være enten SAND eller FALSK. Dette er det, der er kendt som toværdiprædikatlogik, eller kort sagt blot toværdilogik. Dette er f.eks. tilfældet, når du sammenligner en kolonne, der er defineret til ikke at tillade NULL'er, med en anden ikke-NULL operand.
Hvis nogen af operanderne i sammenligningen kan være en NULL, f.eks. en kolonne, der tillader NULL, ved at bruge både ligheds- (=) og uligheds- (<>,>, <,>=, <=, osv.) operatorer, er du nu prisgivet tre-værdi prædikatlogik. Hvis de to operander i en given sammenligning tilfældigvis er ikke-NULL-værdier, får du stadig enten TRUE eller FALSE som resultatet. Men hvis nogen af operanderne er NULL, får du en tredje logisk værdi kaldet UNKNOWN. Bemærk, at det er tilfældet, selv når man sammenligner to NULL'er. Behandlingen af SAND og FALSK af de fleste elementer i SQL er ret intuitiv. Behandlingen af UKENDT er ikke altid så intuitiv. Desuden håndterer forskellige elementer af SQL UNKNOWN-sagen forskelligt, som jeg vil forklare i detaljer senere i artiklen under "NULL-behandlingsinkonsistenser."
Antag som et eksempel, at du skal forespørge tabellen Sales.Orders i TSQLV5-eksempeldatabasen og returnere ordrer, der blev afsendt den 2. januar 2019. Du bruger følgende forespørgsel:
BRUG TSQLV5; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate ='20190102';
Det er klart, at filterprædikatet evalueres til TRUE for rækker, hvor afsendelsesdatoen er 2. januar 2019, og at disse rækker skal returneres. Det er også klart, at prædikatet evalueres til FALSK for rækker, hvor afsendelsesdatoen er til stede, men ikke er den 2. januar 2019, og at disse rækker bør kasseres. Men hvad med rækker med en NULL afsendelsesdato? Husk, at både lighedsbaserede prædikater og ulighedsbaserede prædikater returnerer UNKENDT, hvis nogen af operanderne er NULL. WHERE-filteret er designet til at kassere sådanne rækker. Du skal huske, at WHERE-filteret returnerer rækker, for hvilke filterprædikatet evalueres til TRUE, og kasserer rækker, hvor prædikatet evalueres til FALSE eller UNKNOWN.
Denne forespørgsel genererer følgende output:
orderid shippeddate------------ -----------10771 2019-01-0210794 2019-01-0210802 2019-01-02
Antag, at du skal returnere ordrer, der ikke blev afsendt den 2. januar 2019. For så vidt angår dig, formodes ordrer, der endnu ikke er afsendt, at være inkluderet i outputtet. Du bruger en forespørgsel, der ligner den sidste, og negerer kun prædikatet, som sådan:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT (shippeddate ='20190102');
Denne forespørgsel returnerer følgende output:
orderid shippeddate------------ -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06(806 rækker berørt)
Outputtet ekskluderer naturligvis rækkerne med afsendelsesdatoen 2. januar 2019, men ekskluderer også rækkerne med en NULL afsendelsesdato. Hvad der kunne være kontraintuitivt her er, hvad der sker, når du bruger NOT-operatoren til at negere et prædikat, der evalueres til UKENDT. Det er klart, IKKE SAND er FALSK, og IKKE SAND er SAND. IKKE UKENDT forbliver dog UKENDT. SQLs logik bag dette design er, at hvis du ikke ved, om en proposition er sand, ved du heller ikke, om propositionen ikke er sand. Det betyder, at når du bruger ligheds- og ulighedsoperatorer i filterprædikatet, returnerer hverken den positive eller den negative form af prædikatet rækkerne med NULL'erne.
Dette eksempel er ret simpelt. Der er vanskeligere sager, der involverer underforespørgsler. Der er en almindelig fejl, når du bruger NOT IN-prædikatet med en underforespørgsel, når underforespørgslen returnerer et NULL blandt de returnerede værdier. Forespørgslen returnerer altid et tomt resultat. Årsagen er, at den positive form af prædikatet (IN-delen) returnerer en TRUE, når den ydre værdi er fundet, og UKENDT, når den ikke findes på grund af sammenligningen med NULL. Så returnerer negationen af prædikatet med NOT-operatoren altid henholdsvis FALSK eller UKENDT - aldrig en SAND. Jeg dækker denne fejl i detaljer i T-SQL-fejl, faldgruber og bedste praksis – underforespørgsler, herunder foreslåede løsninger, optimeringsovervejelser og bedste praksis. Hvis du ikke allerede er bekendt med denne klassiske fejl, så sørg for at tjekke denne artikel, da fejlen er ret almindelig, og der er enkle foranstaltninger, du kan tage for at undgå den.
Tilbage til vores behov, hvad med at forsøge at returnere ordrer med en afsendelsesdato, der er anderledes end den 2. januar 2019, ved at bruge den anden end (<>) operatør:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate <> '20190102';
Desværre giver både ligheds- og ulighedsoperatorerne Ukendt, når nogen af operanderne er NULL, så denne forespørgsel genererer følgende output ligesom den forrige forespørgsel, eksklusive NULL'erne:
orderid shippeddate------------ -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06(806 rækker berørt)
For at isolere spørgsmålet om sammenligninger med NULL-værdier, der giver UNKENDT ved hjælp af lighed, ulighed og negation af de to slags operatorer, returnerer alle følgende forespørgsler et tomt resultatsæt:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT (shippeddate =NULL); SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate <> NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT (shippeddate <> NULL);
Ifølge SQL skal du ikke kontrollere, om noget er lig med en NULL eller anderledes end en NULL, snarere om noget er en NULL eller ikke er en NULL, ved at bruge de specielle operatorer IS NULL og IS NOT NULL, henholdsvis. Disse operatorer bruger logik med to værdier og returnerer altid enten SAND eller FALSK. Brug for eksempel IS NULL-operatøren til at returnere ikke-afsendte ordrer, som sådan:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate IS NULL;
Denne forespørgsel genererer følgende output:
orderid shippeddate------------ -----------11008 NULL11019 NULL11039 NULL...(21 rækker påvirket)
Brug IS NOT NULL-operatøren til at returnere afsendte ordrer, som sådan:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate IS NOT NULL;
Denne forespørgsel genererer følgende output:
orderid shippeddate------------ -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06(809 rækker berørt)
Brug følgende kode til at returnere ordrer, der blev afsendt på en anden dato end den 2. januar 2019, samt ikke-afsendte ordrer:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate <> '20190102' ELLER shippeddate ER NULL;
Denne forespørgsel genererer følgende output:
orderid shippeddate------------ -----------11008 NULL11019 NULL11039 NULL...10249 2017-07-1010252 2017-07-1110250 2017-07-12 ...11050 2019-05-0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06(827 rækker berørt)
I en senere del af serien dækker jeg standardfunktioner til NULL-behandling, som i øjeblikket mangler i T-SQL, inklusive DISTINCT-prædikatet , der har potentialet til at forenkle NULL-håndteringen en hel del.
Sammenligninger med variabler, parametre og kolonner
Det foregående afsnit fokuserede på prædikater, der sammenligner en kolonne med en konstant. I virkeligheden vil du dog for det meste sammenligne en kolonne med variabler/parametre eller med andre kolonner. Sådanne sammenligninger involverer yderligere kompleksitet.
Fra et NULL-håndteringssynspunkt behandles variabler og parametre ens. Jeg vil bruge variabler i mine eksempler, men de pointer, jeg gør om deres håndtering, er lige så relevante for parametre.
Overvej følgende grundlæggende forespørgsel (jeg kalder det forespørgsel 1), som filtrerer ordrer, der blev afsendt på en given dato:
DECLARE @dt AS DATE ='20190212'; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Jeg bruger en variabel i dette eksempel og initialiserer den med en eksempeldato, men dette kunne lige så godt have været en parameteriseret forespørgsel i en lagret procedure eller en brugerdefineret funktion.
Denne forespørgselskørsel genererer følgende output:
orderid shippeddate------------ -----------10865 2019-02-1210866 2019-02-1210876 2019-02-1210878 2019-02-1210879 2019- 02-12
Planen for forespørgsel 1 er vist i figur 1.
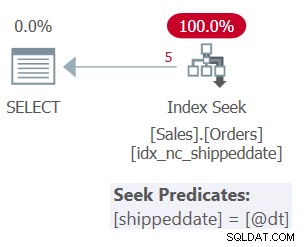 Figur 1:Plan for forespørgsel 1
Figur 1:Plan for forespørgsel 1
Tabellen har et dækkende indeks til at understøtte denne forespørgsel. Indekset kaldes idx_nc_shippeddate, og det er defineret med nøglelisten (shippeddate, orderid). Forespørgslens filterprædikat er udtrykt som et søgeargument (SARG) , hvilket betyder, at det gør det muligt for optimeringsværktøjet at overveje at anvende en søgeoperation i det understøttende indeks og gå direkte til rækken af kvalificerende rækker. Det, der gør filterprædikatet SARGable, er, at det bruger en operator, der repræsenterer et fortløbende område af kvalificerende rækker i indekset, og at det ikke anvender manipulation på den filtrerede kolonne. Den plan, du får, er den optimale plan for denne forespørgsel.
Men hvad nu hvis du vil tillade brugere at bede om ikke-afsendte ordrer? Sådanne ordrer har en NULL afsendelsesdato. Her er et forsøg på at sende en NULL som inputdato:
DECLARE @dt AS DATE =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Som du allerede ved, producerer et prædikat, der bruger en lighedsoperator, UKENDT, når nogen af operanderne er NULL. Følgelig returnerer denne forespørgsel et tomt resultat:
orderid shippeddate----------- -----------(0 rækker påvirket)
Selvom T-SQL understøtter en IS NULL-operator, understøtter den ikke en eksplicit IS
DECLARE @dt AS DATE =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE ISNULL(shippeddate, '99991231') =ISNULL(@dt, '99991231');
Denne forespørgsel genererer det korrekte output:
orderid shippeddate----------- -----------11008 NULL11019 NULL11039 NULL...11075 NULL11076 NULL11077 NULL(21 rækker påvirket)
Men planen for denne forespørgsel, som vist i figur 2, er ikke optimal.
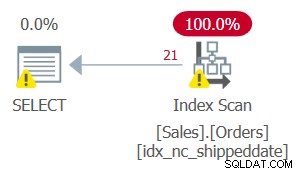 Figur 2:Plan for forespørgsel 2
Figur 2:Plan for forespørgsel 2
Da du anvendte manipulation på den filtrerede kolonne, betragtes filterprædikatet ikke længere som et SARG. Indekset dækker stadig, så det kan bruges; men i stedet for at anvende en søgning i indekset, der går direkte til rækken af kvalificerende rækker, scannes hele indeksbladet. Antag, at bordet havde 50.000.000 ordrer, hvor kun 1.000 var ikke-afsendte ordrer. Denne plan ville scanne alle 50.000.000 rækker i stedet for at lave en søgning, der går direkte til de kvalificerende 1.000 rækker.
En form for et filterprædikat, der både har den korrekte betydning, som vi er ude efter, og som betragtes som et søgeargument er (shippeddate =@dt OR (shippeddate ER NULL OG @dt ER NULL)). Her er en forespørgsel, der bruger dette SARGable prædikat (vi kalder det forespørgsel 3):
DECLARE @dt AS DATE =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE (shippeddate =@dt OR (shippeddate ER NULL OG @dt ER NULL));
Planen for denne forespørgsel er vist i figur 3.
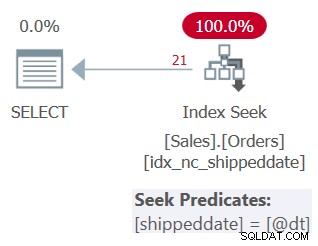 Figur 3:Plan for forespørgsel 3
Figur 3:Plan for forespørgsel 3
Som du kan se, anvender planen en søgning i støtteindekset. Seek-prædikatet siger shippeddate =@dt, men det er internt designet til at håndtere NULL-værdier ligesom ikke-NULL-værdier af hensyn til sammenligningen.
Denne løsning anses generelt for at være rimelig. Det er standard, optimalt og korrekt. Dens største ulempe er, at den er ordrig. Hvad hvis du havde flere filterprædikater baseret på NULL-kolonner? Du ville hurtigt ende med en lang og besværlig WHERE-klausul. Og det bliver meget værre, når du skal skrive et filterprædikat, der involverer en NULLable-kolonne, der leder efter rækker, hvor kolonnen er anderledes end inputparameteren. Prædikatet bliver så:(shippeddate <> @dt AND ((shippeddate IS NULL AND @dt IS NOT NULL) OR (shippeddate IS NOT NULL and @dt IS NULL))).
Man kan tydeligt se behovet for en mere elegant løsning, der både er kortfattet og optimal. Desværre tyr nogle til en ikke-standardløsning, hvor du slår ANSI_NULLS-sessionsindstillingen fra. Denne indstilling får SQL Server til at bruge ikke-standard håndtering af ligheds- (=) og anderledes end (<>)-operatorer med logik med to værdier i stedet for logik med tre værdier, og behandler NULL-værdier ligesom ikke-NULL-værdier til sammenligningsformål. Det er i hvert fald tilfældet, så længe en af operanderne er en parameter/variabel eller en bogstavelig.
Kør følgende kode for at slå ANSI_NULLS fra i sessionen:
INDSTILL ANSI_NULLS FRA;
Kør følgende forespørgsel ved hjælp af et simpelt lighedsbaseret prædikat:
DECLARE @dt AS DATE =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Denne forespørgsel returnerer de 21 ikke-afsendte ordrer. Du får den samme plan som vist tidligere i figur 3, der viser en søgning i indekset.
Kør følgende kode for at skifte tilbage til standardadfærd, hvor ANSI_NULLS er slået til:
SÆT ANSI_NULLS TIL;
Det frarådes på det kraftigste at stole på en sådan ustandardiseret adfærd. Dokumentationen angiver også, at understøttelse af denne mulighed vil blive fjernet i en fremtidig version af SQL Server. Desuden er mange ikke klar over, at denne mulighed kun er anvendelig, når mindst en af operanderne er en parameter/variabel eller en konstant, selvom dokumentationen er ret klar omkring det. Det gælder ikke, når man sammenligner to kolonner, f.eks. i en join.
Så hvordan håndterer du joins, der involverer NULL-sammenføjningskolonner, hvis du vil have et match, når de to sider er NULL'er? Som et eksempel kan du bruge følgende kode til at oprette og udfylde tabellerne T1 og T2:
DROP TABEL HVIS FINDER dbo.T1, dbo.T2;GO OPRET TABEL dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) IKKE NULL, BEGRÆNSNING UNQ_T1 UNIK CLUSTERED(k1, k1, k1, k1, , k3)); OPRET TABEL dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) IKKE NULL, BEGRÆNSNING UNQ_T2 UNIK KLUSTERET(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) VALUES (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C') ,(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) VALUES (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I') ,(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
Koden opretter dækkende indekser på begge tabeller for at understøtte en join baseret på joinnøglerne (k1, k2, k3) på begge sider.
Brug følgende kode til at opdatere kardinalitetsstatistikken ved at puste tallene op, så optimeringsværktøjet tror, at du har at gøre med større tabeller:
OPDATERING STATISTIK dbo.T1(UNQ_T1) MED RÆKKETAL =1000000;OPDATER STATISTIK dbo.T2(UNQ_T2) MED RÆKKEANTAL =1000000;
Brug følgende kode i et forsøg på at forbinde de to tabeller ved hjælp af simple lighedsbaserede prædikater:
VÆLG T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FRA dbo.T1 INDER JOIN dbo.T2 PÅ T1.k1 =T2.k1 OG T1.k2 =T2.k2 OG T1. k3 =T2.k3;
Ligesom med tidligere filtreringseksempler giver sammenligninger mellem NULL'er, der bruger en lighedsoperator, også her UNKENDT, hvilket resulterer i ikke-matches. Denne forespørgsel genererer et tomt output:
k1 K2 K3 val1 val2------------ ---------- ---------- ---------- ----------(0 rækker påvirket)
Brug af ISNULL eller COALESCE som i et tidligere filtreringseksempel, udskiftning af en NULL med en værdi, der normalt ikke kan vises i dataene på begge sider, resulterer i en korrekt forespørgsel (jeg vil referere til denne forespørgsel som forespørgsel 4):
VÆLG T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FRA dbo.T1 INNER JOIN dbo.T2 ON ISNULL(T1.k1, -2147483648) =ISNULL(T2.k1, -2147483648 ) AND ISNULL(T1.k2, -2147483648) =ISNULL(T2.k2, -2147483648) AND ISNULL(T1.k3, -2147483648) =ISNULL(T2.k3, -2147483648);
Denne forespørgsel genererer følgende output:
k1 K2 K3 val1 val2------------ ---------- ---------- ---------- - ----------0 NULL NULL C I0 NULL 1 F K
Men ligesom at manipulere en filtreret kolonne bryder filterprædikatets SARGability, forhindrer manipulation af en join-kolonne muligheden for at stole på indeksrækkefølge. Dette kan ses i planen for denne forespørgsel som vist i figur 4.
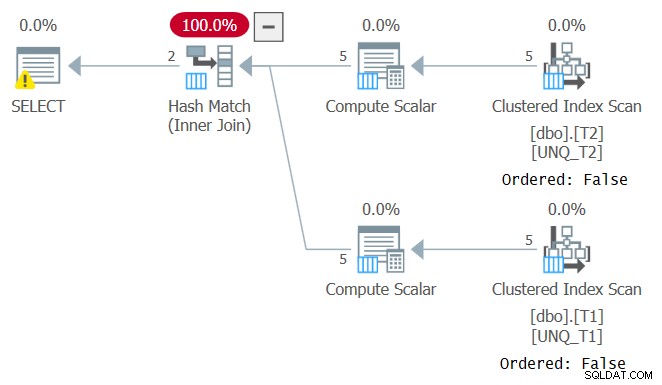 Figur 4:Plan for forespørgsel 4
Figur 4:Plan for forespørgsel 4
En optimal plan for denne forespørgsel er en, der anvender ordnede scanninger af de to dækkende indekser efterfulgt af en Merge Join-algoritme uden eksplicit sortering. Optimizeren valgte en anden plan, da den ikke kunne stole på indeksrækkefølge. Hvis du forsøger at tvinge en Merge Join-algoritme ved hjælp af INNER MERGE JOIN, vil planen stadig være afhængig af uordnede scanninger af indekserne efterfulgt af eksplicit sortering. Prøv det!
Selvfølgelig kan du bruge de lange prædikater svarende til SARGable-prædikaterne vist tidligere til filtreringsopgaver:
VÆLG T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FRA dbo.T1 INNER JOIN dbo.T2 ON (T1.k1 =T2.k1 OR (T1.k1 ER NULL OG T2. K1 ER NULL)) OG (T1.k2 =T2.k2 OR (T1.k2 ER NULL OG T2.K2 ER NULL)) OG (T1.k3 =T2.k3 ELLER (T1.k3 ER NULL OG T2.K3 ER) NULL));
Denne forespørgsel giver det ønskede resultat og gør det muligt for optimeringsværktøjet at stole på indeksrækkefølge. Vores håb er dog at finde en løsning, der er både optimal og kortfattet.
Der er en lidt kendt elegant og kortfattet teknik, som du kan bruge i både joins og filtre, både med det formål at identificere matches og til at identificere ikke-matches. Denne teknik blev opdaget og dokumenteret allerede for år siden, såsom i Paul Whites fremragende skrift Undocumented Query Plans:Equality Comparisons fra 2011. Men af en eller anden grund ser det ud til, at mange mennesker stadig er uvidende om det, og desværre ender med at bruge suboptimal, langvarig og ustandardiserede løsninger. Det fortjener bestemt mere eksponering og kærlighed.
Teknikken bygger på det faktum, at sætoperatorer som INTERSECT og EXCEPT bruger en distinktitetsbaseret sammenligningstilgang, når de sammenligner værdier, og ikke en ligheds- eller ulighedsbaseret sammenligningstilgang.
Betragt vores join-opgave som et eksempel. Hvis vi ikke behøvede at returnere andre kolonner end joinnøglerne, ville vi have brugt en simpel forespørgsel (jeg vil referere til den som forespørgsel 5) med en INTERSECT-operator, som sådan:
VÆLG k1, k2, k3 FRA dbo.T1INTERSECTSELECT k1, k2, k3 FRA dbo.T2;
Denne forespørgsel genererer følgende output:
k1 k2 k3------------ ----------- -----------0 NULL NULL0 NULL 1
Planen for denne forespørgsel er vist i figur 5, hvilket bekræfter, at optimeringsværktøjet var i stand til at stole på indeksordre og bruge en Merge Join-algoritme.
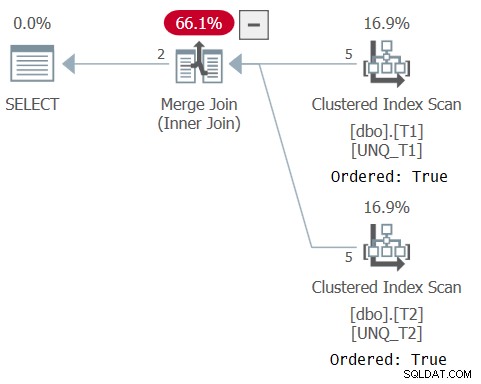 Figur 5:Plan for forespørgsel 5
Figur 5:Plan for forespørgsel 5
Som Paul bemærker i sin artikel, bruger XML-planen for sætoperatoren en implicit IS-sammenligningsoperator (CompareOp="IS" ) i modsætning til EQ-sammenligningsoperatoren, der bruges i en normal joinforbindelse (CompareOp="EQ" ). Problemet med en løsning, der udelukkende er afhængig af en sæt-operator, er, at den begrænser dig til kun at returnere de kolonner, du sammenligner. Det, vi virkelig har brug for, er en slags hybrid mellem en join- og en sætoperator, der giver dig mulighed for at sammenligne en delmængde af elementerne, mens du returnerer yderligere, som en join gør, og bruge distinctness-baseret sammenligning (IS), som en sætoperator gør. Dette er opnåeligt ved at bruge en join som den ydre konstruktion og et EKSISTERER prædikat i joinets ON-klausul baseret på en forespørgsel med en INTERSECT-operator, der sammenligner joinnøglerne fra de to sider, ligesom (jeg vil referere til denne løsning som Query 6):
VÆLG T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FRA dbo.T1 INNER JOIN dbo.T2 ON EKSISTERER(VÆLG T1.k1, T1.k2, T1.k3 Skær VÆLG T2. k1, T2.k2, T2.k3);
INTERSECT-operatøren opererer på to forespørgsler, der hver danner et sæt af en række baseret på sammenføjningstasterne fra hver side. Når de to rækker er ens, returnerer INTERSECT-forespørgslen én række; EXISTS-prædikatet returnerer TRUE, hvilket resulterer i et match. Når de to rækker ikke er ens, returnerer INTERSECT-forespørgslen et tomt sæt; EXISTS-prædikatet returnerer FALSK, hvilket resulterer i et ikke-match.
Denne løsning genererer det ønskede output:
k1 K2 K3 val1 val2------------ ---------- ---------- ---------- - ----------0 NULL NULL C I0 NULL 1 F K
Planen for denne forespørgsel er vist i figur 6, hvilket bekræfter, at optimeringsværktøjet var i stand til at stole på indeksrækkefølge.
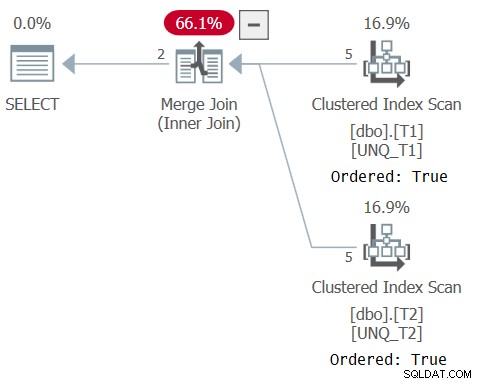 Figur 6:Plan for forespørgsel 6
Figur 6:Plan for forespørgsel 6
Du kan bruge en lignende konstruktion som et filterprædikat, der involverer en kolonne og en parameter/variabel til at søge efter match baseret på distinkthed, som sådan:
DECLARE @dt AS DATE =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Planen er den samme som den, der er vist tidligere i figur 3.
Du kan også negere prædikatet for at se efter ikke-matches, som sådan:
DECLARE @dt AS DATE ='20190212'; SELECT orderid, shippeddateFROM Sales.Orders WHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Denne forespørgsel genererer følgende output:
orderid shippeddate------------ -----------11008 NULL11019 NULL11039 NULL...10847 2019-02-1010856 2019-02-1010871 2019-02-1010867 2019-02-1110874 2019-02-1110870 2019-02-1310884 2019-02-1310840 2019-02-1610887 2019-02-16...(825)Alternativt kan du bruge et positivt prædikat, men erstatte INTERSECT med EXCEPT, sådan:
DECLARE @dt AS DATE ='20190212'; SELECT orderid, shippeddateFROM Sales.OrdersWHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);Bemærk, at planerne i de to tilfælde kan være forskellige, så sørg for at eksperimentere begge veje med store mængder data.
Konklusion
NULL'er tilføjer deres andel af kompleksitet til din SQL-kodeskrivning. Du vil altid tænke over potentialet for tilstedeværelsen af NULL'er i dataene, og sikre dig, at du bruger de rigtige forespørgselskonstruktioner, og tilføje den relevante logik til dine løsninger for at håndtere NULL'er korrekt. At ignorere dem er en sikker måde at ende med fejl i din kode. I denne måned fokuserede jeg på, hvad NULLs er, og hvordan de håndteres i sammenligninger, der involverer konstanter, variabler, parametre og kolonner. Næste måned fortsætter jeg dækningen ved at diskutere NULL-behandlingsinkonsekvenser i forskellige sprogelementer og manglende standardfunktioner til NULL-håndtering.