Efter at have blogget om, hvordan filtrerede indekser kunne være mere kraftfulde, og for nylig om, hvordan de kan gøres ubrugelige ved tvungen parameterisering, vender jeg tilbage til emnet for filtrerede indekser/parametrisering. En tilsyneladende for simpel løsning dukkede op på arbejdet for nylig, og jeg var nødt til at dele.
Tag følgende eksempel, hvor vi har en salgsdatabase, der indeholder en tabel over ordrer. Nogle gange vil vi bare have en liste (eller en optælling) af kun de ordrer, der endnu ikke skal afsendes - som over tid (forhåbentlig!) repræsenterer en mindre og mindre procentdel af den samlede tabel:
CREATE DATABASE Sales;
GO
USE Sales;
GO
-- simplified, obviously:
CREATE TABLE dbo.Orders
(
OrderID int IDENTITY(1,1) PRIMARY KEY,
OrderDate datetime NOT NULL,
filler char(500) NOT NULL DEFAULT '',
IsShipped bit NOT NULL DEFAULT 0
);
GO
-- let's put some data in there; 7,000 shipped orders, and 50 unshipped:
INSERT dbo.Orders(OrderDate, IsShipped)
-- random dates over two years
SELECT TOP (7000) DATEADD(DAY, ABS(object_id % 730), '20171101'), 1
FROM sys.all_columns
UNION ALL
-- random dates from this month
SELECT TOP (50) DATEADD(DAY, ABS(object_id % 30), '20191201'), 0
FROM sys.all_columns; Det kan give mening i dette scenarie at oprette et filtreret indeks som dette (hvilket gør hurtigt arbejde med alle forespørgsler, der forsøger at få fat på de ikke-afsendte ordrer):
CREATE INDEX ix_OrdersNotShipped ON dbo.Orders(IsShipped, OrderDate) WHERE IsShipped = 0;
Vi kan køre en hurtig forespørgsel som denne for at se, hvordan den bruger det filtrerede indeks:
SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0;
Udførelsesplanen er ret enkel, men der er en advarsel om UnmatchedIndex:
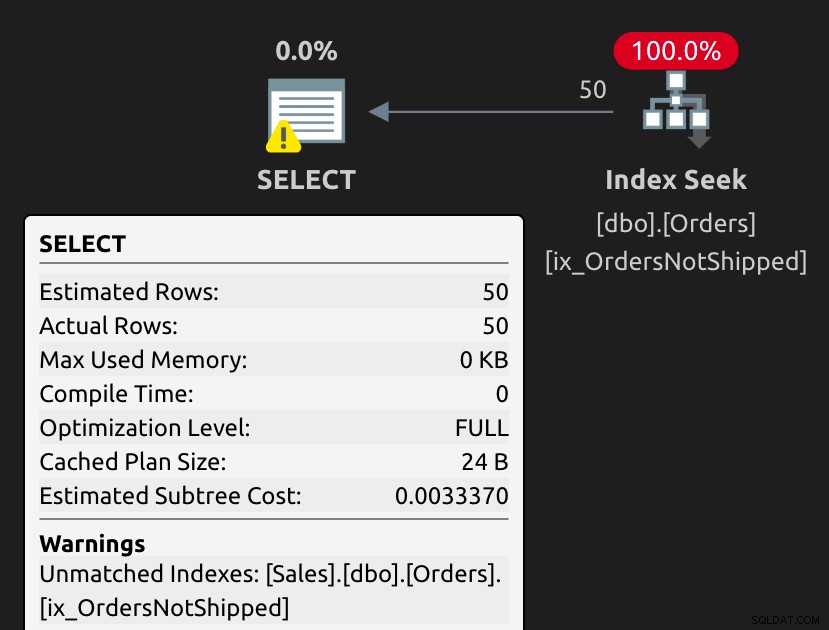
Navnet på advarslen er lidt misvisende - optimeringsværktøjet var i sidste ende i stand til at bruge indekset, men antyder, at det ville være "bedre" uden parametre (som vi ikke eksplicit brugte), selvom udsagnet ser ud som om det var parametriseret:

Hvis du virkelig vil, kan du fjerne advarslen uden forskel i den faktiske ydeevne (det ville bare være kosmetisk). En måde er at tilføje et nul-påvirkningsprædikat, såsom AND (1 > 0) :
SELECT wadd = OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0 AND (1 > 0);
En anden (sandsynligvis mere almindelig) er at tilføje OPTION (RECOMPILE) :
SELECT wrecomp = OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0 OPTION (RECOMPILE);
Begge disse muligheder giver den samme plan (en søgning uden advarsler):
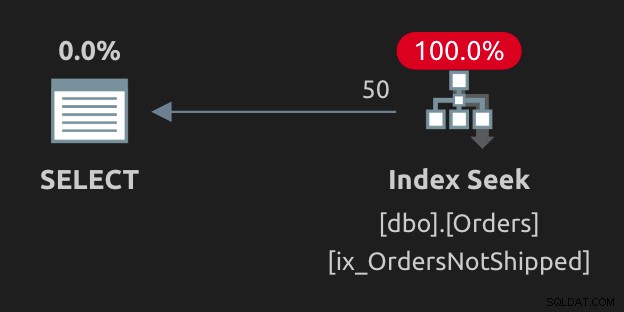
Så langt så godt; vores filtrerede indeks bliver brugt (som forventet). Det er selvfølgelig ikke de eneste tricks; se kommentarerne nedenfor for andre, som læsere allerede har indsendt.
Så komplikationen
Fordi databasen er underlagt et stort antal ad hoc-forespørgsler, aktiverer nogen tvungen parameterisering og forsøger at reducere kompilering og eliminere lav- og engangsplaner fra at forurene planens cache:
ALTER DATABASE Sales SET PARAMETERIZATION FORCED;
Nu kan vores oprindelige forespørgsel ikke bruge det filtrerede indeks; den er tvunget til at scanne det klyngede indeks:
SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0;
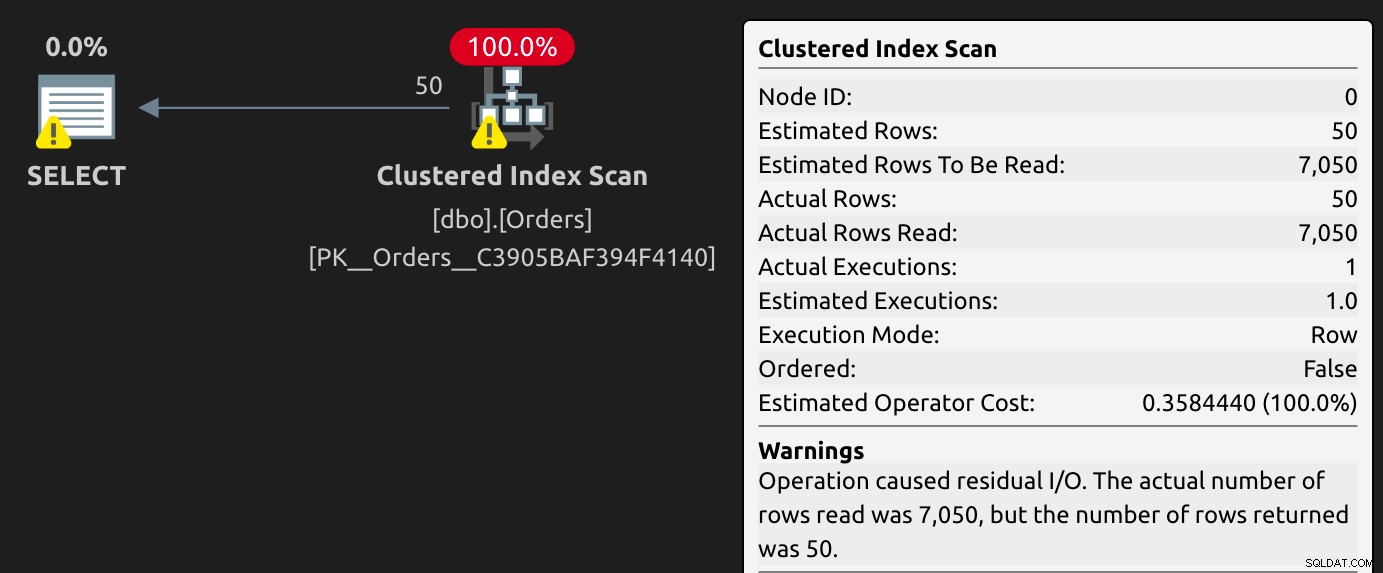
Advarslen om umatchede indekser vender tilbage, og vi får nye advarsler om resterende I/O. Bemærk, at sætningen er parametriseret, men den ser lidt anderledes ud:

Dette er ved design, da hele formålet med tvungen parametrering er at parametrere forespørgsler som denne. Men det besejrer formålet med vores filtrerede indeks, da det er beregnet til at understøtte en enkelt værdi i prædikatet, ikke en parameter, der kan ændre sig.
Tomfoolery
Vores "trick"-forespørgsel, der bruger det ekstra prædikat, er heller ikke i stand til at bruge det filtrerede indeks og ender med en lidt mere kompliceret plan at starte op:
SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0 AND (1 > 0);
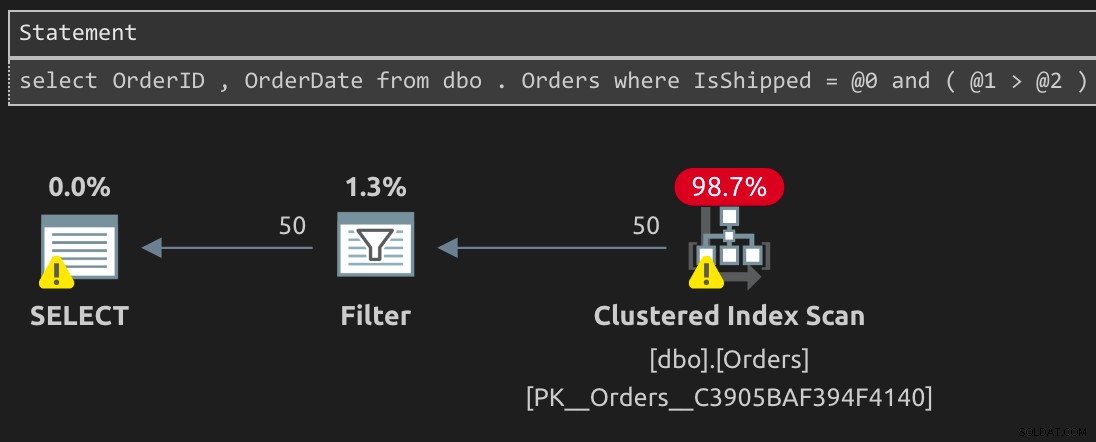
MULIGHED (GENKOMPIL)
Den typiske reaktion i dette tilfælde, ligesom med at fjerne advarslen tidligere, er at tilføje OPTION (RECOMPILE) til redegørelsen. Dette virker og gør det muligt at vælge det filtrerede indeks for en effektiv søgning...
SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0 OPTION (RECOMPILE);
…men tilføjer OPTION (RECOMPILE) og at tage dette ekstra kompileringshit mod hver udførelse af forespørgslen vil ikke altid være acceptabelt i højvolumenmiljøer (især hvis de allerede er CPU-bundne).
Tip
Nogen foreslog eksplicit at antyde det filtrerede indeks for at undgå omkostningerne ved genkompilering. Generelt er dette ret skørt, fordi det er afhængigt af, at indekset overlever koden; Jeg plejer at bruge dette som en sidste udvej. I dette tilfælde er det alligevel ikke gyldigt. Når parameteriseringsregler forhindrer optimeringsværktøjet i at vælge det filtrerede indeks automatisk, forhindrer de dig også i at vælge det manuelt. Samme problem med en generisk FORCESEEK tip:
SELECT OrderID, OrderDate FROM dbo.Orders WITH (INDEX (ix_OrdersNotShipped)) WHERE IsShipped = 0; SELECT OrderID, OrderDate FROM dbo.Orders WITH (FORCESEEK) WHERE IsShipped = 0;
Begge giver denne fejl:
Msg 8622, Level 16, State 1Forespørgselsprocessor kunne ikke producere en forespørgselsplan på grund af de tip, der er defineret i denne forespørgsel. Genindsend forespørgslen uden at angive nogen tip og uden at bruge SET FORCEPLAN.
Og dette giver mening, fordi der ikke er nogen måde at vide, at den ukendte værdi for IsShipped parameter vil matche det filtrerede indeks (eller understøtte en søgeoperation på ethvert indeks).
Dynamisk SQL?
Jeg foreslog, at du kunne bruge dynamisk SQL til i det mindste kun at betale det rekompileringshit, når du ved, at du vil ramme det mindre indeks:
DECLARE @IsShipped bit = 0;
DECLARE @sql nvarchar(max) = N'SELECT dynsql = OrderID, OrderDate FROM dbo.Orders'
+ CASE WHEN @IsShipped IS NOT NULL THEN N' WHERE IsShipped = @IsShipped'
ELSE N'' END
+ CASE WHEN @IsShipped = 0 THEN N' OPTION (RECOMPILE)' ELSE N'' END;
EXEC sys.sp_executesql @sql, N'@IsShipped bit', @IsShipped;
Dette fører til den samme effektive plan som ovenfor. Hvis du ændrede variablen til @IsShipped = 1 , så får du den dyrere clustered index-scanning, du kan forvente:
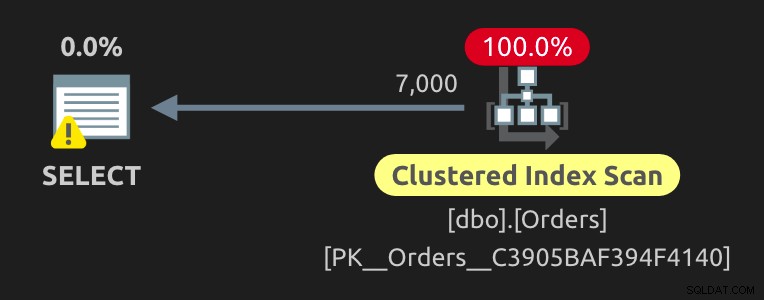
Men ingen kan lide at bruge dynamisk SQL i et edge-tilfælde som dette - det gør kode sværere at læse og vedligeholde, og selvom denne kode var ude i applikationen, er det stadig yderligere logik, der skulle tilføjes der, hvilket gør det mindre end ønskeligt .
Noget enklere
Vi talte kort om at implementere en planguide, hvilket bestemt ikke er enklere, men så foreslog en kollega, at du kunne narre optimizeren ved at "skjule" den parametriserede sætning inde i en lagret procedure, visning eller inline-tabel-vurderet funktion. Det var så enkelt, at jeg ikke troede, det ville virke.
Men så prøvede jeg det:
CREATE PROCEDURE dbo.GetUnshippedOrders AS BEGIN SET NOCOUNT ON; SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0; END GO CREATE VIEW dbo.vUnshippedOrders AS SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0; GO CREATE FUNCTION dbo.fnUnshippedOrders() RETURNS TABLE AS RETURN (SELECT OrderID, OrderDate FROM dbo.Orders WHERE IsShipped = 0); GO
Alle tre af disse forespørgsler udfører den effektive søgning mod det filtrerede indeks:
EXEC dbo.GetUnshippedOrders; GO SELECT OrderID, OrderDate FROM dbo.vUnshippedOrders; GO SELECT OrderID, OrderDate FROM dbo.fnUnshippedOrders();
Konklusion
Jeg var overrasket over, at dette var så effektivt. Det kræver selvfølgelig, at du ændrer applikationen; hvis du ikke kan ændre appkoden til at kalde en lagret procedure eller henvise til visningen eller funktionen (eller endda tilføje OPTION (RECOMPILE) ), bliver du nødt til at blive ved med at lede efter andre muligheder. Men hvis du kan ændre applikationskoden, kan det måske bare være vejen at gå at proppe prædikatet i et andet modul.