Tidligere på måneden offentliggjorde jeg et tip om noget, vi sikkert alle ville ønske, vi ikke behøvede at gøre:sortere eller fjerne dubletter fra afgrænsede strenge, der typisk involverer brugerdefinerede funktioner (UDF'er). Nogle gange har du brug for at samle listen igen (uden dubletterne) i alfabetisk rækkefølge, og nogle gange skal du muligvis bevare den oprindelige rækkefølge (det kan for eksempel være listen over nøglekolonner i et dårligt indeks).
Til min løsning, som adresserer begge scenarier, brugte jeg en taltabel sammen med et par brugerdefinerede funktioner (UDF'er) - den ene til at opdele strengen, den anden til at samle den igen. Du kan se det tip her:
- Fjernelse af dubletter fra strenge i SQL Server
Selvfølgelig er der flere måder at løse dette problem på; Jeg gav kun én metode til at prøve, hvis du sidder fast med de strukturdata. Red-Gates @Phil_Factor fulgte op med et hurtigt indlæg, der viste hans tilgang, som undgår funktionerne og taltabellen og vælger i stedet for inline XML-manipulation. Han siger, at han foretrækker at have enkeltudsagnsforespørgsler og undgå både funktioner og række-for-række-behandling:
- Afduplikering af adskilte lister i SQL Server
Så postede en læser, Steve Mangiameli, en looping-løsning som en kommentar til tippet. Hans begrundelse var, at brugen af en taltabel forekom ham overdrevet.
Vi tre af os undlod alle at tage fat på et aspekt af dette, som normalt vil være ret vigtigt, hvis du udfører opgaven ofte nok eller på et hvilket som helst skalaniveau:ydeevne .
Test
Nysgerrig efter at se, hvor godt inline-XML og looping-tilgange ville fungere sammenlignet med min taltabelbaserede løsning, konstruerede jeg en fiktiv tabel til at udføre nogle tests; mit mål var 5.000 rækker med en gennemsnitlig strenglængde på mere end 250 tegn og mindst 10 elementer i hver streng. Med en meget kort cyklus af eksperimenter var jeg i stand til at opnå noget meget tæt på dette med følgende kode:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Dette producerede en tabel med eksempelrækker, der ser sådan ud (værdier afkortet):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Dataene som helhed havde følgende profil, som burde være god nok til at afdække eventuelle potentielle problemer med ydeevnen:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Bemærk, at jeg skiftede til varchar her fra nvarchar i den originale artikel, fordi prøverne Phil og Steve leverede antog varchar , strenge med maksimalt 255 eller 8000 tegn, enkelttegns-afgrænsninger osv. Jeg har lært min lektie på den hårde måde, at hvis du vil tage en persons funktion og inkludere den i præstationssammenligninger, ændrer du så lidt som muligt – ideelt set ingenting. I virkeligheden ville jeg altid bruge nvarchar og ikke antage noget om den længste streng muligt. I dette tilfælde vidste jeg, at jeg ikke mistede nogen data, fordi den længste streng kun er på 2.905 tegn, og i denne database har jeg ingen tabeller eller kolonner, der bruger Unicode-tegn.
Dernæst oprettede jeg mine funktioner (som kræver en taltabel). En læser fik øje på et problem i funktionen i mit tip, hvor jeg gik ud fra, at afgrænsningen altid ville være et enkelt tegn, og rettede det her. Jeg konverterede også næsten alt til varchar(8000) at udjævne vilkårene med hensyn til strengtyper og længder.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Dernæst oprettede jeg en enkelt, inline tabel-værdisat funktion, der kombinerede de to funktioner ovenfor, noget jeg nu ville ønske, jeg havde gjort i den originale artikel, for helt at undgå den skalære funktion. (Selvom det er sandt, at ikke alle skalarfunktioner er forfærdelige i skala, der er meget få undtagelser.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
Jeg oprettede også separate versioner af den inline TVF, der var dedikeret til hver af de to sorteringsvalg, for at undgå ustabiliteten i CASE udtryk, men det viste sig slet ikke at have nogen dramatisk indflydelse.
Så lavede jeg Steves to funktioner:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Derefter sætter jeg Phils direkte forespørgsler ind i min testrig (bemærk, at hans forespørgsler koder < som < for at beskytte dem mod XML-parsingsfejl, men de koder ikke > eller & – Jeg har tilføjet pladsholdere, hvis du skal beskytte dig mod strenge, der potentielt kan indeholde disse problematiske tegn):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
Testriggen var dybest set disse to forespørgsler, og også følgende funktionskald. Da jeg havde valideret, at de alle returnerede de samme data, blandede jeg scriptet med DATEDIFF output og loggede det til en tabel:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above Og så kørte jeg ydeevnetest på to forskellige systemer (en quad core med 8GB og en 8-core VM med 32GB) og i hvert tilfælde på både SQL Server 2012 og SQL Server 2016 CTP 3.2 (13.0.900.73).
Resultater
De resultater, jeg observerede, er opsummeret i det følgende diagram, som viser varigheden i millisekunder af hver type forespørgsel, gennemsnittet over alfabetisk og original rækkefølge, de fire server/version-kombinationer og en serie på 15 udførelser for hver permutation. Klik for at forstørre:
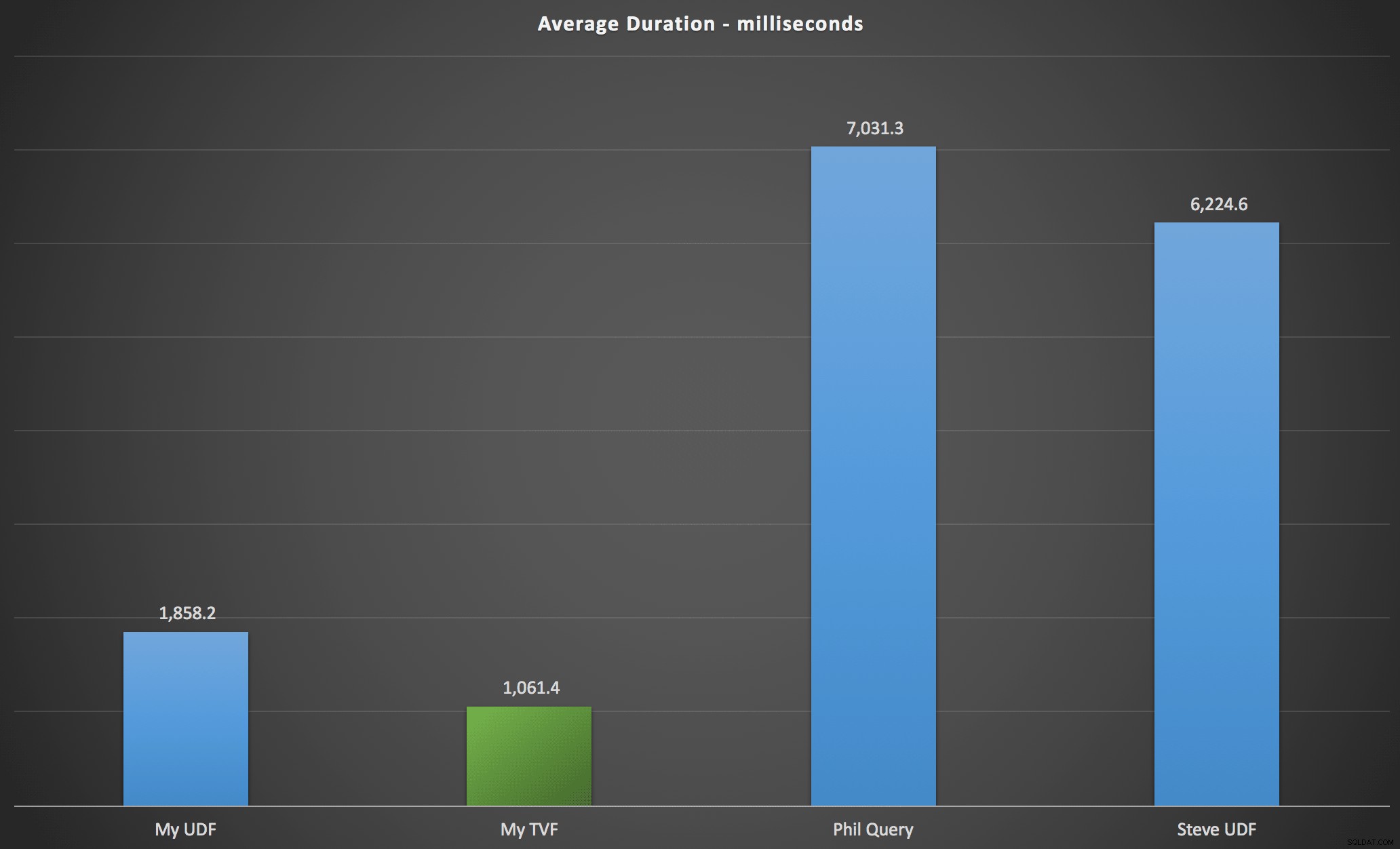
Dette viser, at taltabellen, selvom den blev anset for overkonstrueret, faktisk gav den mest effektive løsning (i hvert fald med hensyn til varighed). Dette var selvfølgelig bedre med den enkelte TVF, som jeg implementerede for nylig, end med de indlejrede funktioner fra den originale artikel, men begge løsninger kører rundt om de to alternativer.
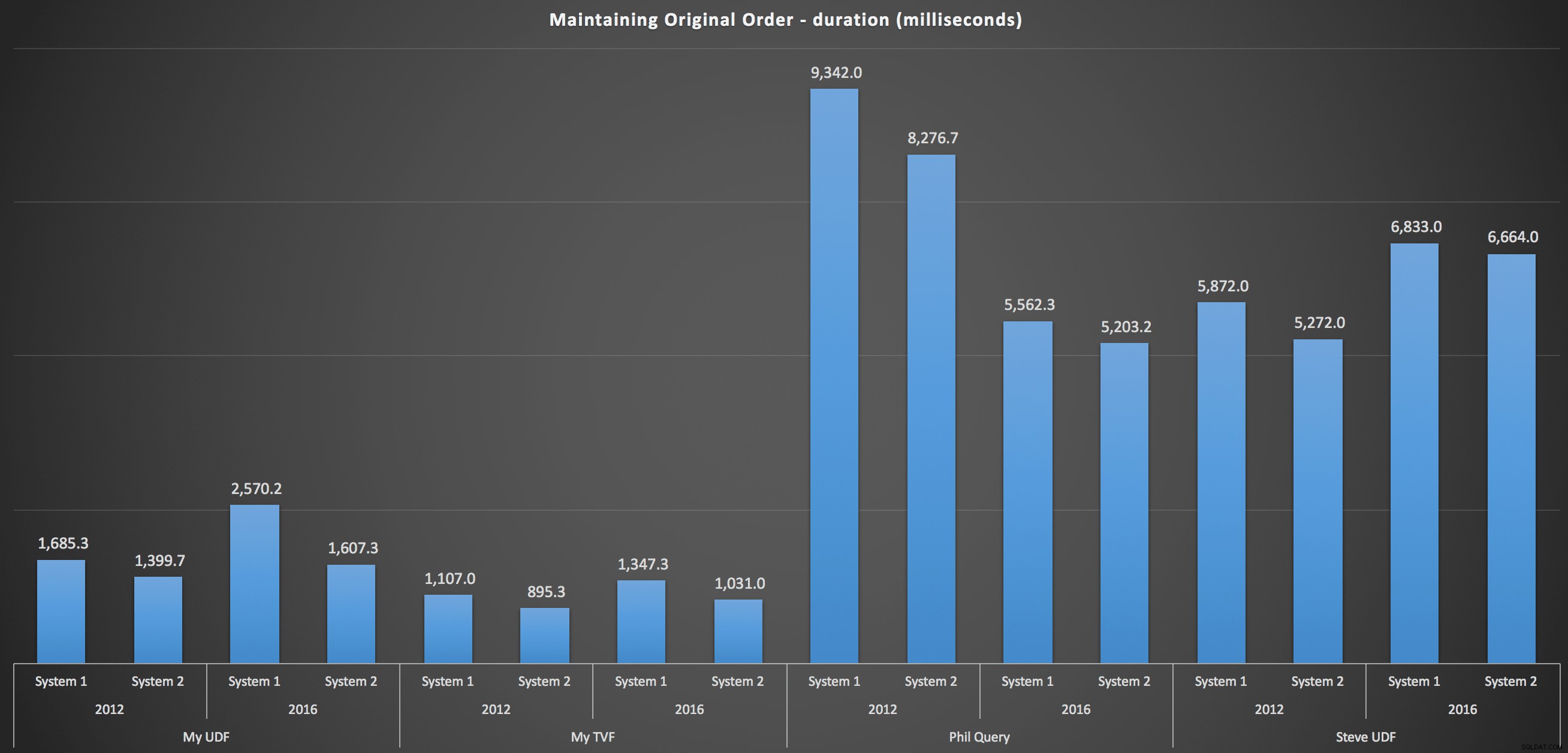
For at komme mere i detaljer, her er nedbrydningerne for hver maskine, version og forespørgselstype, for at opretholde den oprindelige rækkefølge:
…og for at samle listen igen i alfabetisk rækkefølge:
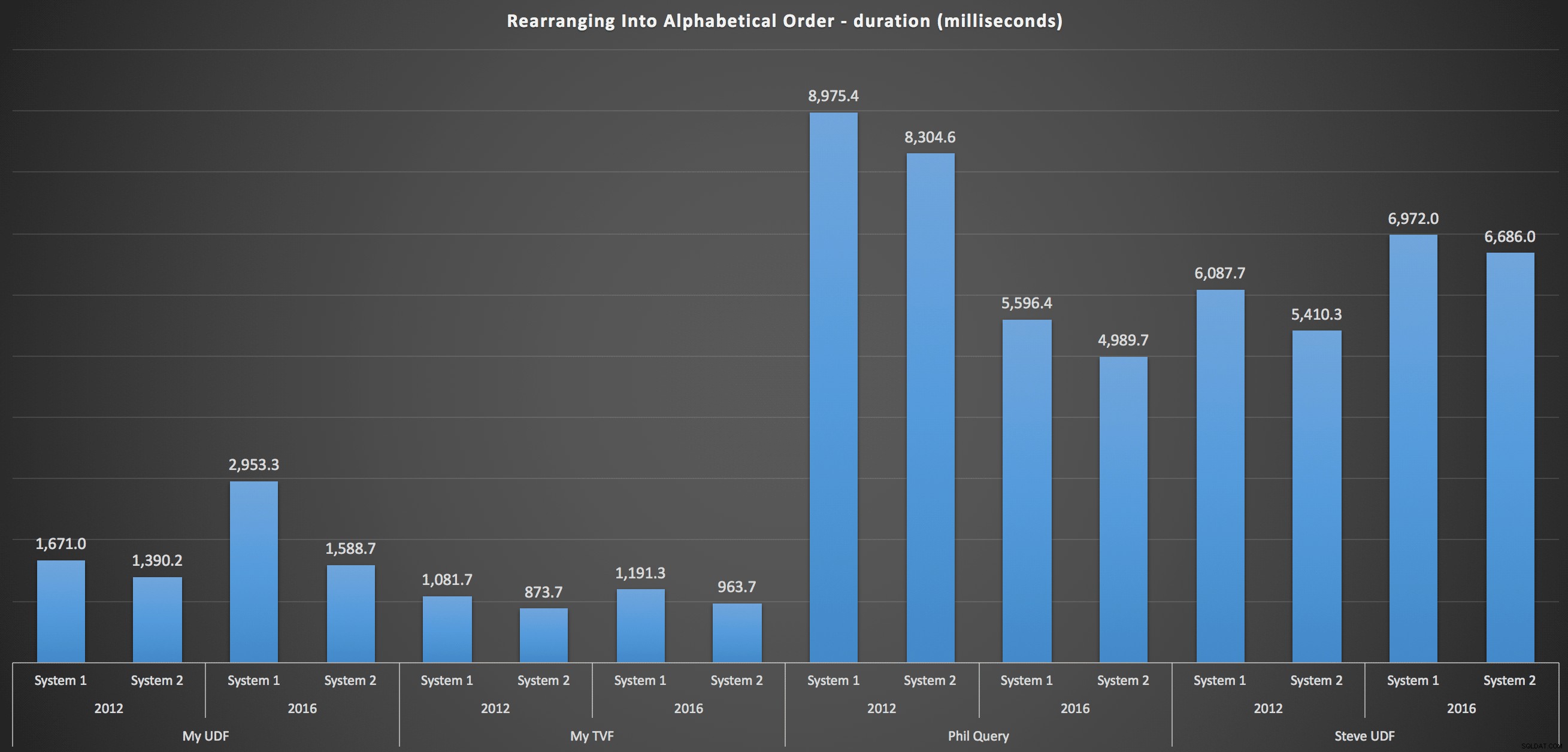
Disse viser, at sorteringsvalget havde ringe indflydelse på resultatet - begge diagrammer er stort set identiske. Og det giver mening, for givet inputdataens form er der ikke noget indeks, jeg kan forestille mig, der ville gøre sorteringen mere effektiv – det er en iterativ tilgang, uanset hvordan du opdeler det, eller hvordan du returnerer dataene. Men det er klart, at nogle iterative tilgange generelt kan være værre end andre, og det er ikke nødvendigvis brugen af en UDF (eller en taltabel), der gør dem på den måde.
Konklusion
Indtil vi har indbygget split- og sammenkædningsfunktionalitet i SQL Server, kommer vi til at bruge alle slags unintuitive metoder til at få arbejdet gjort, inklusive brugerdefinerede funktioner. Hvis du håndterer en enkelt streng ad gangen, vil du ikke se den store forskel. Men efterhånden som dine data skaleres op, vil det være umagen værd at teste forskellige tilgange (og jeg antyder på ingen måde, at metoderne ovenfor er de bedste, du finder – jeg kiggede f.eks. ikke engang på CLR, eller andre T-SQL-tilgange fra denne serie).